初级项目_网络爬虫
一、概述
项目源码链接:Gintoki-jpg/Web_Crawler: 简单利用python进行数据获取、数据处理和数据分析 (github.com);
1.项目分析
项目需求概括为以下几点:
(1)抓取北京邮电大学、西安电子科技大学、电子科技大学,自 2021 年 10 月 1 日以来的就业帖子,将爬取信息包含规定的字段储存在 3 个不同的 csv 文件中;
(2)对三个数据文件进行数据预处理,为后续数据分析的数据做好准备,将预处理完成的三个文件分别存入三个新建的 csv 文件;
(3)要求新建一个 csv 文件对上面三个预处理完成的文件进行合并,需要去重并归纳自行)使用 pandas 数据分析库,对以上四个文件的数据进行分析,分别得到如最受北邮学生关注的招聘 TOP20 此类的数据信息;
2.基本思路
首先针对数据获取,我对三个学校的就业网站都使用的是 selenium 模拟浏览器行为对数据进行爬取,采取了模拟浏览器向服务器发送 post 请求的方式,获得了含有所需信息的json 数据,并处理、储存数据。而实际上西电的网站是静态网页,所以使用 selenium 可能会导致爬取速度上并没有使用 scrapy 框架+bs4 快。获取并储存数据到三个基本数据文件 BEIYOU_1、XIDIAN_1、CHENGDIAN_1,接下来使用 pandas 库对数据进行预处理。其基本要求即将字符串格式的数字类型转换为整形并使用填充、删除等方式规范文本数据格式,最后将日期转化为标准日期格式。创建第四个文件 CAT_A 时我将前三个文件的数据进行汇总,并着重分析“用人单位”这一项数据的属性,分别提取了几十个高频出现的词汇并对其进行归类,如将带有“研究所”、“研究院”词汇的招聘公司归类为“研究机构”这一雇主类型。最后,编写程序对上述 csv 文件进行分析,主要思想就是按照“浏览次数”或者“职位数量”对数据进行降序排序并取前面数据,得到受欢迎的 TOP 排行榜。针对最后一个最关注 ICT 行业的招聘主题排行,我将其转化为最受欢迎的互联网科技企业的招聘主题 TOP 榜,之所以能够这样处理是因为我在前面对雇主类型“互联网科技企业”进行归类时已经包含了ICT 行业的相关内容,故只需要取各个学校的“互联网科技企业”TOP10 再次依据“浏览次数”和“职位数量”双重降序取前 10 得到最关注 ICT 行业的招聘主题 TOP10。
二、项目设计
1.模型设计
1.1 分类原则
通过观察并分析,在分析了近百个招聘公司以及查阅了公司基本信息之后,我能够大致凭借公司的名称对其所属行业进行分类。如具有“网络科技”字样的公司属于“互联网科技企业”。由于能力有限以及对相关行业的判断不能特别准确,所以我在下面做的划分可能会出现偏差以及涵盖不全,在接下来我还将寻找更好的解决办法,提高自己对于数据处理以及模型构建的能力。
下面是我对招聘信息进行的雇主类型的分类:
研究机构——研究院、研究所、实验室
金融企业——证券、基金、投资、期货、基金会、房地产、银行、控股、资产、保险、
税务
医疗科技企业——医疗、医药、生物、药、医院、医
工业科技企业——工业、化工、工程、化学、材料、航天、动力、光电、设备、电力、
电器、半导体、电气、电机、电路、设计、系统、机械、工厂、机电、中铁、装备、智造
社会企业——人力、工作局
高新技术企业——电源、新技术、能源
互联网科技企业——科技(先医疗,再科技,范围大的放在后面)、技术、电子、信息、
网络、计算、工程师、数据、数码、软件、机器人、数科、开发、信号、通信
教育单位类——学校、学院、大学、中心
人文知识企业——文化、知识
专业技术服务企业——检测、管理、咨询、建设、管道
媒体——传媒、传播、广告
政府企业——委员会
生活类企业——乳业、事务所、物流、汽车、饮料、物业、五金、食品…
1.2 分类方法
首先将 DataFrame 的“用人单位”列改名为“雇主类型”(因为我们不需要“用人单位”这个字段,而需要根据“用人单位”分类得到“雇主类型”)。接着为了检验“雇主类型”列的数据是否含有相应字段并对其进行处理,我们首先将“雇主类型”列转化为列表便于遍历。接着使用 if…elif…else 结构逐个对列表元素进行匹配,假如匹配成功则将 DataFrame 的原数据进行修改,假如公司名称均不含上述字段,则将其“雇主类型”归类为“其他”。
2.系统设计
因为我使用的anaconda的jupyter notebook编辑器进行代码的编写所以并没有分文件进行编写,而是分代码块编写,下面我将分代码块介绍程序设计的原理
导入需要使用的库

2.1 数据爬取
2.1.1 爬取北邮就业网站
首先使用 driver 打开网址

接着创建 csv 文件保存爬取数据,我们将需要的字段“招聘主题”、“用人单位”、“发布日期”、“浏览次数”、“职位数量”作为首行,并创建空字典 dict 暂存将要爬取的数据

准备工作完成之后,下面编写 worm1()爬虫程序
首先对北邮就业网站首页进行分析,我们可以获取“招聘主题”、“用人单位”、“发布日期”和“职位数量”的数据,但是“浏览次数”需要我们点击具体招聘帖子获取。当我们获取了“发布时间”后需要进行比较,以判断该帖子是否是“2021-10-1”日期后发布的
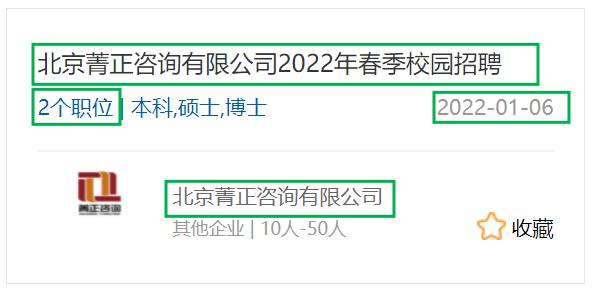
接下来我们点击某一个招聘帖子进入招聘页面,发现此时浏览器的页面跳转为招聘页面(这点与西电不同将在后面介绍)。我们获取完“浏览次数”信息后需要返回,此时只能点击上面的“招聘信息”返回到首页(注意是首页而不是之前进入的页面)
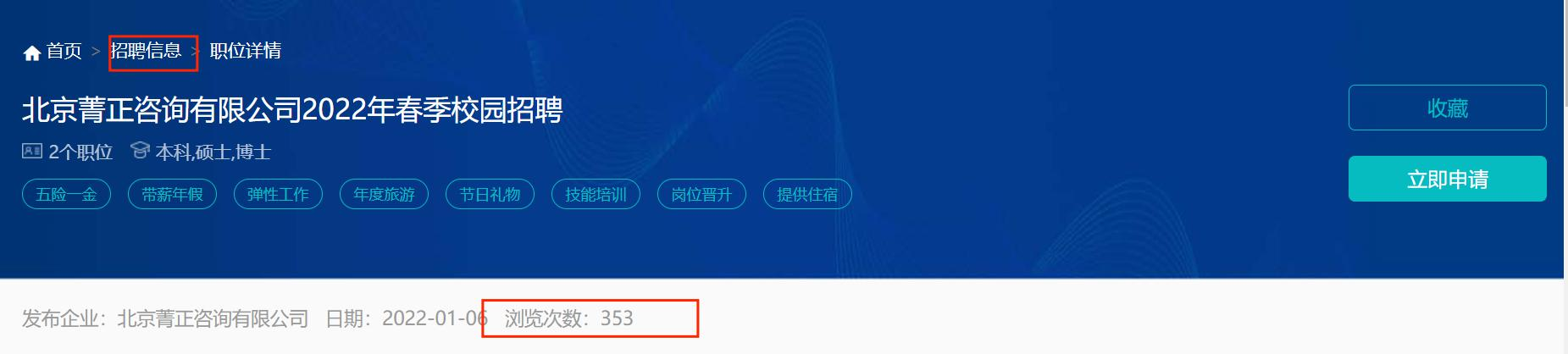
现在假如我们现在是在第二页,那么我们获取了第二页第一个的“浏览次数”后要获取第二页第二个其他招聘信息就需要先返回首页,然后翻页,然后重复上述操作。这里是翻页操作的代码(包含了获取完 15 条帖子自动点击“下一页”按钮进入下一页)

2.1.2 爬取成电就业网站
由于三个网站的爬取使用的都是 selenium 模拟爬取,所以前面的准备操作与北邮相同,此处不做赘述

进入成电的就业网站,我们可以直接获取到“招聘信息”、“用人单位”、“发布日期”的基本信息,而“浏览次数”默认置零。在获取了“发布日期”后,同样要比较判断是否为规定爬取日期之前的帖子,否则程序终止

观察发现一页有 20 条招聘信息,爬取完毕后点击“下一页”按钮继续爬取

2.1.3 爬取西电就业网站

接着分析西电的网站,能够直接获取的信息是“招聘信息”、“发布日期”、“用人单位”。同北邮一样,我们需要点击招聘帖子才能得到“浏览次数”的信息
点击进入详情页面后我们发现浏览器是新建了一个页面打开,于是在获取完需要的信息后关闭这个页面即可(并不需要像北邮一样点击回退按钮)
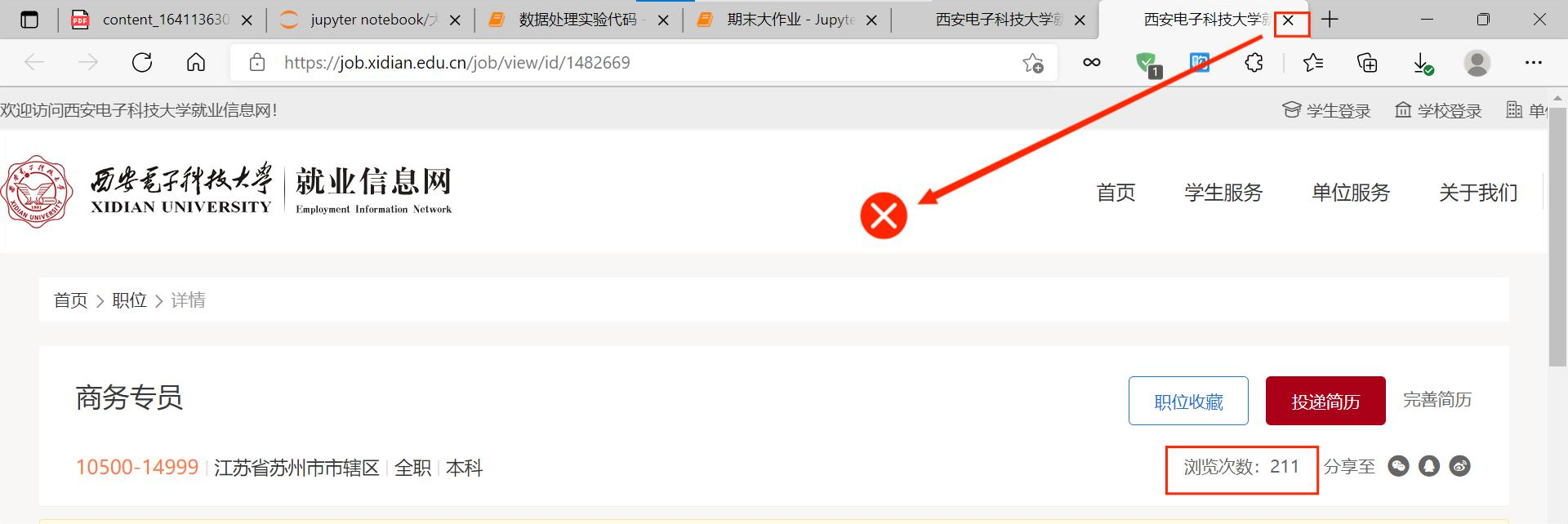
要实行该操作需要用到句柄转换,由于 selenium 模拟浏览器控制的实际上是句柄对应的页面,并不是我们认为的我们看到的页面,所以需要用到下面这段代码——将句柄转换后关闭新打开的页面,再转换句柄至原来的页面获取其他招聘帖子的信息

2.2 数据预处理
因为成电和西电的数据字段相同,所以我们编写的代码相同。北邮只是多了一个对“职位数量”的处理
首先使用 pandas 的.read_csv()方法对爬取得到的数据进行读取并保存在 DataFrame 中
下面处理日期我们使用 pandas 内置的格式化方法

接着是将空值 Nan 填充为 0,同样使用内置方法

接下来是针对北邮特有的“职位数量”进行处理,因为某些招聘信息中不包括“职位数量”,而用的是“无职位数量信息”字段代替,所以我们将该字段作为判断条件,若匹配则将对应的“职位数量”替换为 1,否则直接转化为整型即可

处理完上述信息后,我们需要自己创建一个序号的列替换隐式索引,因为之前的隐式索引序号并不美观,并且没有列名,并不方便索引

因为这个文件是包含了前面三个文件的信息,所以我们在读取方式上有一点不同,此处采用了将其置于列表中逐条读取的方法

首先是去重,这里使用内置函数处理

接着是对“雇主类型”的分类,这里我们采用简单直接的 for 循环对每个数据进行对比,判断其是否匹配并决定将其“雇主类型”归类为哪一个。下面仅展示部分代码

2.3 数据分析
依据“浏览次数”对“招聘主题”进行降序排序并筛选前 20 个数据分别得到最受北邮学生关注的招聘 TOP20、最受西电学生关注的招聘 TOP20、最受成电学生关注的招聘 TOP20

依据“雇主类型”求和的次数得到 TOP10,首先我们要将“用人单位”转化为“雇主类型”(参考前面的暴力代码),接着使用.value_counts()方法进行计数降序得到最受北邮学生关注的雇主类型 TOP10、最受西电学生关注的雇主类型 TOP10、最受成电学生关注的雇主类型 TOP10

北邮招聘职位总数、招聘职位数量 TOP10 (简单按帖子主题就行,不需要解析企业名称)、招聘职位所属雇主类型 TOP10——其处理方式就是用内置函数

最后我们要得到最关注 ICT 行业的招聘主题 TOP10,因为要根据三个学校的总额和排名并且使用“浏览次数”和“职位数量”双重排序,我们不妨转化思路,先将三个学校关注 ICT行业的招聘主题 TOP10 即根据双重排序得到的三个学校各自的“互联网科技企业”TOP10,接着将这 30 个数据再进行排序比较得到最终结果
