Python工具
本片博客主要介绍常用的Python开发工具,如Numpy、Pandas、爬虫等,这些工具在我们学习的时候大概知道是什么就行,实际使用还是需要借助互联网查询其内置的函数或用法之类(爬虫的内容见下一篇博客);
简单教程可参考菜鸟教程 - 学的不仅是技术,更是梦想! (runoob.com),详细教程可参考http://c.biancheng.net/
关于Numpy、Pandas、Matplotlib数据分析三件套我们之前学过,整体也不难,所以这里介绍的非常简短,感兴趣可以网上搜教程自学;
数据分析(一)
1.Numpy库
Numpy主要用于计算处理一维或多维数组,Numpy提供了大量数学函数来进行数组运算;
Numpy还提供了多种数据结构,这些数据结构能够非常契合的应用在数组和矩阵的运算上;
1.1 创建数组
使用Numpy之前需要导入
1 | |
创建数组的方式有三种
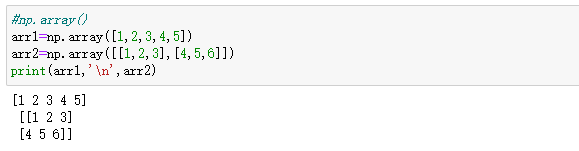
-np.array()
-plt()
-np的routines函数创建
注:数组的数据类型必须是一样的,假如不一样则按照字符串>float>int的优先级隐式转换

1.2 数组属性
-shape#形状
-ndim#维度
-size#元素个数
-dtype#数组元素类型
注意:arr1.dtype显示的是arr1数组中的元素的类型,并非数组arr1的类型
1.3 索引和切片
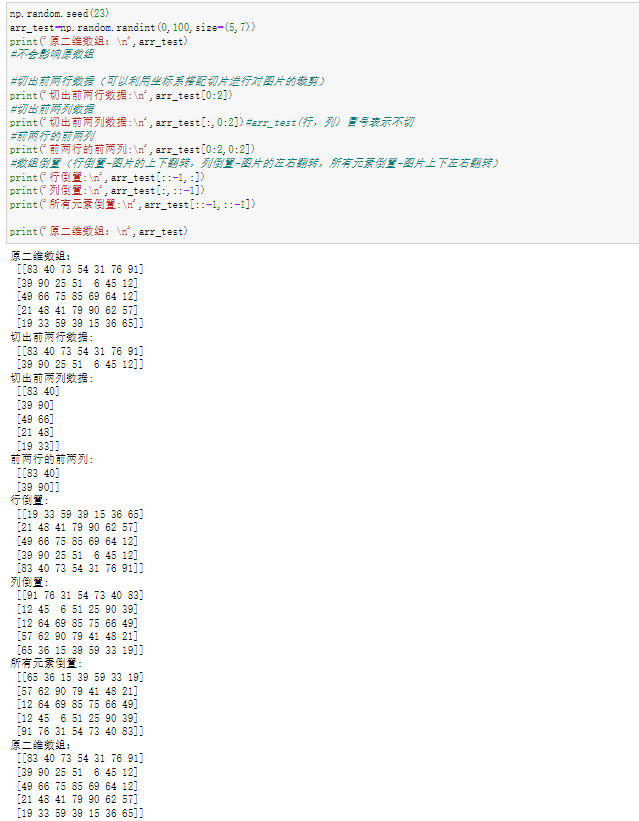
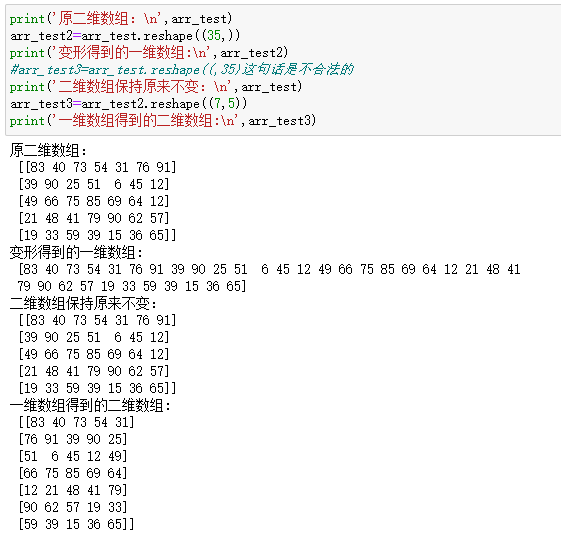
1.4 数组变形
使用reshape可以实现一维到二维或者二维到一维的变形
注:一定要注意变形前后的数组大小必须相同,不能多一个元素或者少一个元素
1.5 数组级联
将多个numpy数组进行横向或者纵向的拼接
axis轴向的理解:
- 0:列
- 1:行
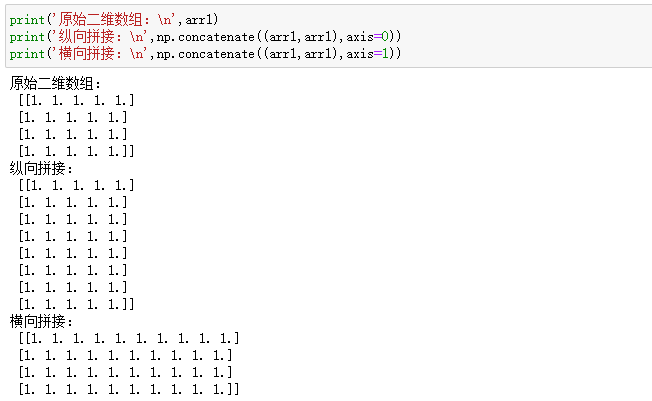
1.6 数值运算
-常用聚合操作 sum,max,min,mean
-常用的数学函数
NumPy提供了标准的三角函数:sin0.cos0、 tan0
numpy.around(a,decimals)#函数返回指定数字的四舍五入值
- a:数组 decimals:舍入的小数位数。默认值为0。如果为负,整数将四舍五入到小数点左侧的位置
numpy.std(arr)#求标准差

2.Pandas库
Q:为什么要学习Pandas?
A:
-numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢?
-numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
Pandas 库基于 Python NumPy 库开发而来,因此,它可以与 Python 的科学计算库配合使用。Pandas 提供了两种数据结构,分别是 Series(一维数组结构)与 DataFrame(二维数组结构),这两种数据结构极大地增强的了 Pandas 的数据分析能力。
3.Matplotlib库
教程参考Matplotlib教程(非常详细) (biancheng.net)
图像处理(二)
教程参考Pillow(PIL)入门教程(非常详细) (biancheng.net)
1.Pillow库
Pillow 提供了非常强大的图像处理功能,它能够很轻松地完成一些图像处理任务,与 Python 的其他图像处理库相比(OpenCV、Scikit-image 等),Pillow 库简单易用,OpenCV 和 Scikit-image 的功能更为丰富,所以使用起来也更为复杂,主要应用于机器视觉、图像分析等领域;
- Scikit-image:一款基于 scipy 科学计算的图像处理软件包,以数组的形式对图像进行处理;
- OpenCV:其实是一个 C++ 图像处理库,不过它提供了 Python 语言的接口;
1 | |
1.1 创建Image对象
1 | |
1 | |
1.2 Image对象属性
1 | |
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1920x1080 at 0x1838E53F6A0>
宽是1920高是1080
图像的大小size: (1920, 1080)
1 | |
图像的格式: JPEG
1 | |
图像是否为只读: 0
1 | |
1 | |
图像模式信息: RGB
1.3 图片格式转换
1 | |
1 | |
说实话这个也没啥难度,等真正要用的时候再学其实都可以,现在学了也用不着,就是简单的的调用一些属性和函数罢了;
Web框架(三)
1.Django框架
Django 是用 Python 开发的一个免费开源的 Web 框架,几乎囊括了 Web 应用的方方面面,可以用于快速搭建高性能、优雅的网站,Django 提供了许多网站后台开发经常用到的模块,使开发者能够专注于业务部分;
当然了Python中的Web框架不止Django一种,还有可以快速建站的Flask,支持高并发处理的Tornado,这三者是当前最流行的Python Web框架;
深度学习框架(四)
关于tensorflow版本的问题,参考 初学者是选择Tensorflow2.x还是1.x? 2.x与1.x的主要区别?,现在默认安装的基本上都是2.x,但是网上大量的资料、代码都还是1.x的形式(因为tf的大部分教程都是在19年那个时间段,刚好是tf1最火的时候),如果要安装低版本的tensorflow使用如下命令
1 | |
网上有一些建议是在2.x的版本下使用一些命令兼容1.x的代码,但是经过实测发现治标不治本,而且就算兼容了看得到的代码,但是因为调用了外部库所以那些库中的版本我们是没办法兼容的,所以最好的方式就是在1.x的环境下运行1.x的代码,在2.x的环境下运行2.x的代码,实在嫌麻烦就用pytorch;
现在要学习tf都选择的是学习tensorflow2.x,因为2.x是在2019年推出(在这个时间点之前的关于tensorflow的学习资料全是1.x的,注意辨别),同时舍去了大量1.x中的复杂概念如session、graph等;最重要的一点是1.x已经快停止更新了(这就好比你非得去学习python2.x一样,没有太大实用意义,但是现在网上大量的参考资料还是使用的1.x的书写方式,所以对于1.x还是要有一定了解);因为tensorflow在网上系统的参考资料也不是特别多,所以简单罗列了一些使用的参考,其他的比较细节的知识点推荐直接Google自查;(当然无论tensorflow是哪个版本,python使用的3.x版本这是毋庸置疑的)
最后强调,尽管可以在2.x中使用一些诸如compat.v1的方式兼容1.x,个人认为这不是一种良好的习惯,1.x中很多概念在2.x中不存在,这会导致一些问题,最推荐的方式还是直接安装一个1.x环境单独使用;
小结:tensorflow1.x的基本语法和概念必须理解,因为现在网上大量tf的教程都还是1.x的,tensorflow2.x适合长期学习;
参考资料:
- texsorflow1.x(很详细但是很乱):介绍TensorFlow_w3cschool
- tensorflow1.x(较简洁但是有条理):3.1 TensorFlow 基础 - csmhwu (gitbook.io)
- tensorflow2.x:《Tensorflow深度学习》 - 龙龙老师
1.tensorflow1.x
tf2.x安装参考:安装 — 动手学深度学习 2.0.0 documentation (d2l.ai),附带安装了一些其他包;
tf1.x安装参考:
- (15条消息) anaconda安装tensorflow1版本_糖尛果的博客-CSDN博客;
- (15条消息) windows下anaconda安装tensorflow1.x版本问题汇总_tensorflow1版本_s@dragon的博客-CSDN博客;
人工智能的发展主要经历三个阶段:
- 推理期:人们试图通过总结、归纳出一些逻辑规则,并将逻辑规则以计算机程序的方式实现,来开发出智能系统。但是这种显式的规则往往过于简单,并且很难表达复杂、抽象的概念和规则;
- 专家系统,机器学习;
- 神经网络,深度神经网络;
深度学习特指基于深层神经网络实现的模型或算法;
常用的深度学习算法使用的工具如下:
Theano是最早的深度学习框架之一,由Yoshua Bengio 和Ian Goodfellow等人开发,是一个基于Python语言、定位底层运算的计算库,Theano同时支持GPU和CPU运算。由于Theano开发效率较低,模型编译时间较长,同时开发人员转投TensorFlow等原因,Theano目前已经停止维护;
Torch是一个非常优秀的科学计算库,基于较冷门的编程语言Lua开发。Torch灵活性较高,容易实现自定义网络层,这也是PyTorch继承获得的优良基因。但是由于Lua语言使用人群较少,Torch一直未能获得主流应用。
TensorFlow是Google 于2015年发布的深度学习框架,最初版本只支持符号式编程。得益于发布时间较早,以及Google在深度学习领域的影响力,TensorFlow很快成为最流行的深度学习框架。但是由于TensorFlow接口设计频繁变动,功能设计重复冗余,符号式编程开发和调试非常困难等问题,TensorFlow 1.x版本一度被业界诉病。2019年,Google推出TensorFlow 2正式版本,将以动态图优先模式运行,从而能够避免TensorFlow 1.x版本的诸多缺陷,已获得业界的广泛认可;
Keras是一个基于Theano和TensorFlow等框架提供的底层运算而实现的高层框架,提供了大量快速训练、测试网络的高层接口。对于常见应用来说,使用Keras开发效率非常高。但是由于没有底层实现,需要对底层框架进行抽象,运行效率不高,灵活性一般;
PyTorch是Facebook基于原Torch框架推出的采用Python作为主要开发语言的深度学习框架。PyTorch借鉴了Chainer的设计风格,采用命令式编程,使得搭建网络和调试网络非常方便。尽管PyTorch在2017年才发布,但是由于精良紧凑的接口设计,PyTorch在学术界获得了广泛好评。在PyTorch 1.0版本后,原来的PyTorch与Caffe2进行了合并,弥补了PyTorch在工业部署方面的不足。总的来说,PyTorch是一个非常优秀的深度学习框架;
Scikit-learn是一个完整的面向机器学习算法的计算库,内建了常见的传统机器学习算法支持,文档和案例也较为丰富,但是Scikit-learn并不是专门面向神经网络而设计的,不支持GPU加速,对神经网络相关层的实现也较欠缺;
目前来看,TensorFlow和PyTorch框架是业界使用最为广泛的两个深度学习框架,TensorFlow在工业界拥有完备的解决方案和用户基础,PyTorch得益于其精简灵活的接口设计,可以快速搭建和调试网络模型,在学术界获得好评如潮。TensorFlow2发布后,弥补了TensorFlow在上手难度方面的不足,使得用户既能轻松上手TensorFlow框架,又能无缝部署网络模型至工业系统;
这里特别介绍TensorFlow与Keras之间的联系与区别。Keras可以理解为一套高层API的设计规范,Keras本身对这套规范有官方的实现,在TensorFlow中也实现了这套规范,称为tf.keras模块,并且 tf.keras将作为TensorFlow 2版本的唯一高层接口,避免出现接口重复冗余的问题。如无特别说明,本书中Keras均指代tf.keras。
1.1 什么是tensorflow
简单来说就是以tensor和flow为最基础的要素,tensor代表了data,flow代表了流动也就是对数据的计算、流动和映射:
- Tensor直译为张量,张量是对矢量和矩阵更高维度的泛化(即多维数组);
- Flow直译为流,表示其计算模型是
数据流图,Tensorflow使用数据流图将计算表示为独立指令之间的依赖关系,每一个计算都是数据流图上的节点,节点之间的边描述了计算之间的关系;
tensorflow是一个开源的机器学习平台,我们可以借助其灵活的架构,将其轻松地将计算工作部署到多种平台(CPU、GPU、TPU)和设备(桌面设备、服务器集群、移动设备、边缘设备等)上;
1.2 tensorflow1.x概述
- 使用图 (graph) 来表示计算任务.
- 在被称之为
会话 (Session)的上下文 (context) 中执行图. - 使用 tensor 表示数据.
- 通过
变量 (Variable)维护状态. - 使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
简单来说TensorFlow 就是一个编程系统, 使用图来表示计算任务.图中的节点被称之为 op (operation 的缩写). 一个 op 获得 0 个或多个Tensor, 执行计算, 产生 0 个或多个 Tensor. 每个 Tensor 是一个类型化的多维数组. 例如, 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels].
一个 TensorFlow 图描述了计算的过程. 为了进行计算, 图必须在 会话 里被启动. 会话 将图的 op 分发到诸如 CPU 或 GPU 之类的 设备 上, 同时提供执行 op 的方法. 这些方法执行后, 将产生的 tensor 返回:
- 在 Python 语言中, 返回的 tensor 是 numpy
ndarray对象; - 在 C 和 C++ 语言中, 返回的 tensor 是
tensorflow::Tensor实例;
TensorFlow 程序通常被组织成一个构建阶段和一个执行阶段:
- 在构建阶段, op 的执行步骤 被描述成一个图.
- 在执行阶段, 使用会话执行执行图中的 op.
例如, 通常在构建阶段创建一个图来表示和训练神经网络,然后在执行阶段反复执行图中的训练 op.
下面以简单的2.0+4.0的加法运算为例子,说明1.x的程序构成
1 | |
上述过程仅仅只是创建计算图的阶段,简单理解就是通过符号建立c=a+b,但是此时因为a和b还没有被赋值且需要运行公式的输出端子c才能获得c的数值结果
1 | |
可见使用1.x进行简单的加法运算都如此复杂,更别说神经网络的搭建,这种先搭建计算图后运行的编程方式被称作符号式编程;
我们类比一下2.x的代码,同样是计算2.0+4.0
1 | |
这种同时创建计算图c=a+b和数值结果6.0=2.0+4.0的方式被称作命令式编程,也称为动态图模式;
TensorFlow 2 和 PyTorch 都是采用动态图(优先)模式开发,调试方便,所见即所得。一般来说,动态图模式开发效率高,但是运行效率可能不如静态图模式。TensorFlow 2 也支持通过 tf.function 将动态图优先模式的代码转化为静态图模式,实现开发和运行效率的双赢。
1.2.1 张量
Tensorflow中的所有数据都通过张量的形式来表示,张量从功能上来说可以理解为多维数组
- 零阶张量表示为标量(表现为高维空间中的一个点,由多个标量描述的概念构成向量);
- 一阶张量为向量,也就是一维数组(表现为高维空间中的一条有向线段);
- n阶张量为一个n维数组;
需要注意的是tensor实际并不保存真正的数字,保存的只是计算过程;
张量的属性主要有(以张量Tensor(“Add:0”,shape=(),dtype=float32)为例):
Name:Name的一般形式为“node:src_output”,node表示节点名称,src_output 来自节点的第几个输出;
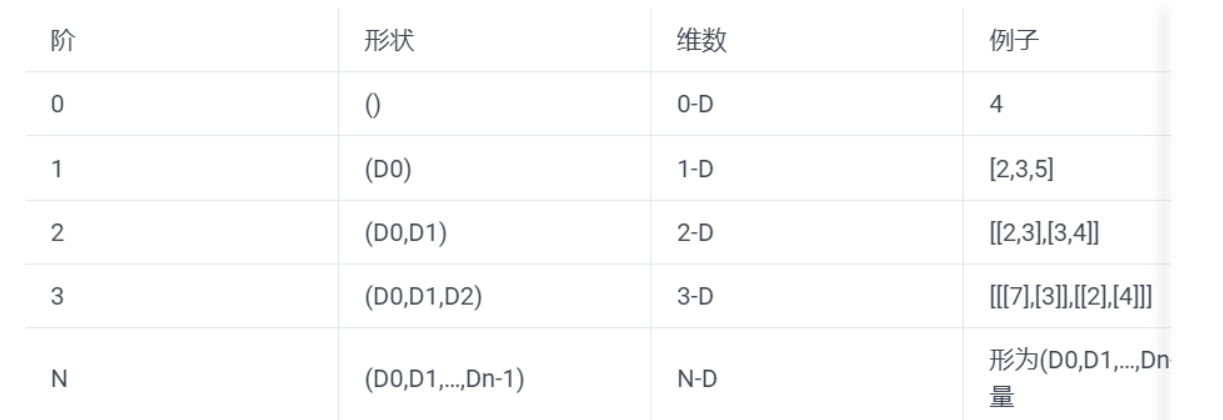
Shape:属性的第二项是维度,张量的维度可以用三个术语来描述:阶(Rank)、形状(Shape)、维数(Dimension Number)。一般表示形式如下
Type:每一个张量会有一个唯一的类型,TensorFlow在进行运算的时候会对参与运算的所有张量进行类型的检查,发现类型不匹配时会报错.TensorFlow支持14种不同的类型:
实数:tf.float32, tf.float64
整数:tf.int8, tf.int16, tf.int32, tf.int64, tf.uint8
布尔:tf.bool
复数:tf.complex64, tf.complex128
默认类型:不带小数点的数会被默认为int32,带小数点的会被默认为float32。
Q:为什么以前学习物理的时候标量的定义是只有大小没有方向的矢量?这里又认为它只是一个点?
A:因为物理中标量不等同于此处的标量,尽管名字相同但是两者的意义完全不同(巧合的是物理中的矢量和数学中的向量又是类似的);
1.2.2 数据流图
数据流图是一个有向图,由以下内容构成:
- 一组节点,每个节点都代表一个操作、一种运算;
- 一组有向边,每条边代表节点之间的关系(数据传递和控制依赖),tensorflow有两种边:
- 常规边(实线):代表数据依赖关系。一个节点的运算输出成为另一个节点的输入,两个节点之间有tensor流动(值传递);
- 特殊边(虚线):不携带值,表示两个节点之间的控制相关性。比如,happens-before关系,源节点必须在目的节点执行前完成执行;
1.2.3 Operation
数据流图中的节点就是操作operation,一次加法是一个操作,一次乘法是一次操作,构建变量的初始值也是一个操作;
每个操作都有属性,它在构建图的时候会被确定,操作也可以和计算设备绑定,指定操作在某个设备上执行。操作之间存在顺序关系,这些操作之间的依赖就是“边”。如果操作A的输入是操作B执行的结果,那么这个操作A就依赖于操作B。
1.2.4 Session
session拥有并管理tensorflow运行时所有的物理资源(如GPU和网络连接等),因此当所有计算完成后需要关闭session帮助系统回收资源,否则容易发生资源泄露;下面我们介绍三种常见的会话模式避免资源的泄露;
session_1
1 | |
明确调用Session.close()函数来关闭会话并释放资源,但是当程序异常推出时,该函数可能不被执行从而导致资源泄露,不推荐该方法;
session_2
1 | |
使用try…except…finally…语句可以确保一定能够关闭会话使得本次运行中使用的所有资源都被释放;
session_3
1 | |
会话模式3使用Python的上下文管理器来管理这个会话,保证在程序执行完后,推出上下文便可关闭会话和释放资源;
1.2.5 常量和变量
常量指在运行过程中不会改变的值,在TensorFlow中无需进行初始化操作。
创建语句:
1 | |
常量在TensorFlow中一般被用于设置训练步数、训练步长和训练轮数等超参数,此类参数在程序执行过程中一般不需要被改变,所以一般被设置为常量。
变量是指在运行过程中会改变的值,在TensorFlow中需要进行初始化操作。
创建语句:
1 | |
TensorFlow中定义的每个变量都要进行初始化,不然会报错;
初始化变量有两种方式
1 | |
当然无论是哪种形式的初始化,初始化函数都需要调用session执行,下面我们展示一段代码,定义并初始化变量
1 | |
tensorflow中的变量在定义和初始化之后一般不需要手动赋值,默认情况下系统根据算法模型在训练过程中自动调整变量对应的数值(当然常量不存在这样的情况);
TensorFlow中的变量可以通过设置trainable参数来确定在训练的时候是否更新其值,比如我们将训练轮数设置为变量并决定在程序执行过程中不改变它的值(这里不是很明确到底是和常量一样永远不能改变还是说只是不会被系统自动更新但是可以被手动更新)
1 | |
除了自动更新以外,还可以手动更新
1 | |
因为tensorflow的变量必须在定义的同时初始化,但是某些变量只有在真正运行程序的时候由外部输入(如训练数据),此时就需要使用占位符;
占位符,是TensorFlow中特有的一种数据结构,类似动态变量,函数的参数、或者C语言或者Python语言中格式化输出时的“%”占位符;
TensorFlow中的占位符虽然定义完之后不需要对其值进行初始化,但是需要确定其数据的Type和Shape。占位符的函数接口如下:
1 | |
如果构建了一个包含placeholder操作的计算图,那么在程序执行当在session中调用run方法时,placeholder占用的变量必须通过feed_dict参数传递进去,否则会报错;
多个操作可以通过一次Feed完成执行
1 | |
会话运行完成之后,如果我们想查看会话运行的结果,就需要使用fetch来实现,feed、fetch一般搭配起来使用
1 | |
说一下为什么不非常详细的介绍tensorflow1.x的内容,一个原因是参考资料确实不多,另一个原因就是因为tensorflow1.x只是为了能够在我们copy代码的时候看得懂,实际上现在运用的比较多的代码都是使用的tensorflow2.x,所以接下来我们会将中心放在tensorflow2.x上,主要按照龙龙老师的tensorflow深度学习来进行;
2.tensorflow2.x
跳转:Tensorflow - Tintoki_blog (gintoki-jpg.github.io);
3.Pytorch
跳转:PyTorch - Tintoki_blog (gintoki-jpg.github.io);
其他工具(五)
1.miniconda管理器
miniconda是一个Anaconda的压缩版本,主要用于管理python虚拟环境,我们罗列常用命令(命令参考: https://blog.csdn.net/hxxjxw/article/details/99200660)
-查看常用conda命令:conda help
-查看conda版本:用户根目录下使用 conda –version ;
-查看所有的conda环境:用户根目录下直接使用 conda info –env 即可;
-激活某个conda环境:用户根目录下直接使用 conda activate [conda环境名] ;
-查看某个环境下安装的所有包:激活conda环境后使用 pip list ;
-关闭某个conda环境:使用 conda deactivate 退出;
-新建conda环境(name为d2l,python版本为3.8,-y参数能直接跳过安装的确认过程):使用 conda create –name d2l python=3.8 -y
-安装需要的包(如版本为2.8.0的tensorflow):激活对应环境后,使用命令 pip install tensorflow==2.8.0
-进入jupyter:激活对应环境后,使用cd进入磁盘某个目录,接着使用 jupyter notebook进入notebook
常见配置:
- sklearn和skicit-learn不是同一个包,前者已经停用注意不要装错;
- conda配置pytorch参考:在anaconda下安装pytorch + python3.8+GPU/CPU版本 详细教程-物联沃-IOTWORD物联网;
- 在jupyter notebook中配置pytorch内核:(4条消息) jupyter notebook和pycharm中配置pytorch环境,及jupyter notebook内核创建_jupyter配置pytorch_小萝北hh的博客-CSDN博客;
2.pycharm集成开发环境
简单在pycharm中配置conda虚拟环境参考:(10条消息) 如何在pycharm中配置anaconda的虚拟环境_pycharm怎么配置anaconda环境_肆十二的博客-CSDN博客;
pycharm如何定制参数(即在pycharm中和终端一样命令行调试程序):(4条消息) 关于使用命令行参数的Python程序如何在pycharm中调试:_pycharm在edit run configuration 里parameter部分输入cmd指令_weixin_44457930的博客-CSDN博客;
3.白嫖GPU(Kaggle)
因为当前使用的电脑芯片是AMD的无法支持GPU深度学习,所以一直以来都使用的是CPU进行深度学习,奈何速度真的太慢了,所以考虑使用云端白嫖的GPU进行训练;
参考资料:
- 白嫖汇总:白嫖GPU,我们是认真的!_51CTO博客_白嫖 gpu;
- Kaggle GPU教程:
- Google colab教程:
- colab+VS Code:【Colab】最强薅羊毛 | 使用Vscode搭配colab使用+防断_哔哩哔哩_bilibili;
多余的kaggle没什么好细讲的,看了视频之后自己多用用就熟悉了;
3.1 导入项目
Kaggle如何运行自己的python项目(比如在pycharm中开发的项目)?需要先明白一点就是Kaggle不支持修改数据集里面的内容,这意味着上传的可运行的代码一定需要是正确无误的、路径正确的,因此推荐的一种方式是先在pycharm中检查代码(有条件的话可以运行代码),这样可以节省之后修改的时间(当然Kaggle一些独特的特性比如之前遇到的找不到iport_module('model.TextRNN')(这在pycharm是完全正确的)这种就只能按照Kaggle的特性来修改代码了)
导入并运行项目主要有三种方法:
- 将自己的项目和数据集作为压缩包上传,将input中的文件导入working中:(15条消息) 免费gpu:kaggle本地项目上传使用说明_kaggle怎么上传自己的文件_grniopgt的博客-CSDN博客;
1 | |
- 除了上述直接把文件全部导入working工作目录下,也可以更改当前工作目录为input,好处是无需前面那些繁琐的操作,缺点是不能在input中创建新的文件和文件夹(因为input是只读目录)
1 | |
- 还有一种最简捷的方法,就是将整个input的项目转移到working中(这种方式的话待会运行train.py文件需要注意是否进入了Obj_det子目录,切换方法看上面)
1 | |
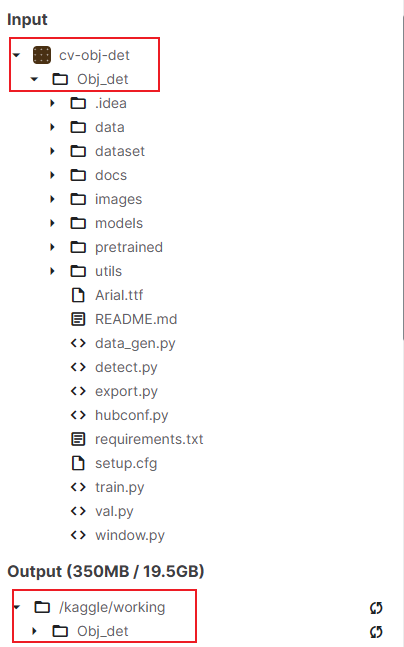
使用如下命令运行py文件(强调最好先在pycharm中跑一遍,因为Kaggle不能在线修改很麻烦)
1 | |
3.2 常用命令
Kaggle:(15条消息) 命令-conda-markdown-kaggle常用命令-WebStorm-pycharm_LXMXHJ的博客-CSDN博客;
因为Kaggle涉及工作目录的切换,所以需要一些python os库的常识:Python中os库 - 几何0814 - 博客园 (cnblogs.com);
4.Copilot
参考链接:
- 视频:https://www.bilibili.com/video/BV11D4y1e7Y4/?spm_id_from=333.1007.top_right_bar_window_history.content.click;
- 简介文档:Github Copilot 的使用方法和快捷键 | 教程 | Tinkink;
- 官方文档:GitHub Copilot 快速入门 - GitHub 文档;
Copilot可以认为是一个写代码助手,可以根据注释以及上下文生成代码片段,最近Copilot X也开放申请通道了,可以在Github中查看其介绍;
这里主要介绍一下如何在Pycharm中安装并使用Copilot,因为这是一个收费软件,而通过Github pro申请之后可以免费使用,所以需要先申请Github pro,参考(15条消息) Github Pro申请_落难Coder的博客-CSDN博客,当然在申请过程中几乎会被reject,主要原因一个是Github的profile name需要修改为姓名拼音,个人简介也标注自己的学校相关,另一点是提交的证明(我使用的是学信网的截图)需要是英文版(这里使用搜狗翻译对截图进行翻译),最后实在不行就换手机尝试(我换手机尝试一次就成功了);
拥有了Github pro之后就可以在Pycharm中的插件中下载Github Copilot,点击login按照操作即可完成登录(这一步一开始尝试了很多次都没有成功,按照网上设置代理也没有用,后来把插件删除之后重装就OK了),然后就可以使用Copilot了(使用的过程中最好一直打开全局);
5.Copilot Labs
参考视频:GitHub Copilot Labs插件的最佳使用场景是什么??_哔哩哔哩_bilibili;
这个工具具有许多实验性质的功能,如解释选中的代码,转换代码语言等,现在(2023/5/6)这个插件只能在VScode上使用,可以参照视频讲解探索其用法;
6.GPU云服务器
参考链接:实验室一块GPU都没有怎么做深度学习? - 知乎 (zhihu.com);
Q:为什么选择云服务器?白嫖的GPU不香么?
A:现在比较好用的Google clab或者Kaggle都是notebook形式的(clab好像可以使用VScode online,但是还是不够方便)。这两个免费的notebook编辑器都存在缺陷(路径配置、无法在线修改代码或依赖版本过高/冲突等问题,无法自行DIY),因此最终选择租借使用一个云GPU服务器。在这个过程中也可以加强自己动手能力(顺便将之前学Linux的服务器的知识点复习一下),一举两得。
总结一下就是,免费的东西确实很香,但是往往会付出时间代价,是否花费大量时间去使用免费的资源取决于你的时间投入与回报比例。
只有pycharm专业版能够使用SSH远程开发功能,所以使用之前先把社区版卸载了下载专业版(反正学生认证可以免费使用);
这里主要讲一下,如果电脑没有GPU或者GPU不是英伟达或者是GPU性能太差了,应当如何解决以应对深度学习任务。
在自己电脑上跑深度学习称为本地学习,缺少的是计算资源GPU。但是计算资源其实是一个抽象的概念,这意味着它可以是本地的,也可以其他地方获得的,
使用云计算资源来跑深度学习,只需要把数据和环境在云环境中配置一下,其他操作与在本地操作相同,仅仅需要一个带有浏览器或能够远程登陆的设备就可以跑深度学习。
此处使用的是AutoDL平台,帮助文档查看AutoDL帮助文档,pycharm配置参考Pycharm连接远程GPU服务器跑深度学习_哔哩哔哩_bilibili;
- 关于GPU的选择,可以参考如下建议

其他没什么好介绍的,这种东西就是自己多用用熟悉之后就OK了(前期不要把帮助文档看的特别仔细,还不如拿这个时间来多操作两把,AutoDL的那些按钮啥的都点点,反正试错成本也不高,后面遇到问题了再看帮助文档)。
最后,给出一些使用建议:
- 代码习惯,文件路径最好都写相对路径,这样更符合规范同时也尽可能的避免路径问题;
- 关于不同的项目,可以使用同一个Interpreter,但是需要注意在工具栏把SSH的映射路径修改了,避免文件夹重合
- 服务器端的映射路径不要无脑的选择temp文件夹,因为很可能你都不知道系统把文件给你放在哪个不知名的目录下了,推荐自己创建一个在服务器上找的到的文件夹;
- 可以事先传数据集到服务器上面,pycharm项目中就不要保留数据集(否则因为配置了自动上传,项目第一次打开会重新上传覆盖原有数据集,这样会导致项目启动时间很长),还有一种方式就是关闭自动上传,则在pycharm中进行的所有操作都需要在工具栏进行手动部署(推荐);
- pycharm在远端开发中就只是充当一个编辑器的作用,不要直接右键运行当前文件,使用终端命令行的方式运行代码(因为使用的是Ubuntu的镜像,因此需要数量掌握一些Linux基本指令AutoDL帮助文档);
- 如果通过SSH登录后执行训练程序(比如使用pycharm,Xshell,仅仅作调试使用),请使用screen或tmux开守护进程,确保程序不受SSH连接中断影响程序执行,参考AutoDL帮助文档(更推荐的方式是使用pycharm进行调试,使用jupyter lab的shell运行,长时间运行的时候最好使用命令该命令可以保证训练完成后关闭实例节约资源(运行完毕后jupyterlab会关闭,终端的输出如果不进行重定向的话就会消失));
1
python train.py && /usr/bin/shutdown - 只要jupyterlab不出现重启,jupyterlab的终端就会一直运行,无论是本地主机断网还是关机,因此长时间跑代码推荐使用jupyterlab。使用jupyterlab长时间跑代码的过程中强烈建议对日志重定向,防止断网后中间的日志消失(另一方面,如果手动把终端关闭了重新打开,虽然程序还是在跑但是终端就啥也没有了)
1
2# 日志重定向到train.log文件。即在python运行命令后加上:> train.log 2>&1,重定向后原有的终端不会输出日志,而是将日志存储在train.log中
python xxx.py > train.log 2>&11
2# 实时查看日志(在新的终端中输入该命令)
tail -f train.log - 使用Jupyer Lab只能上传文件而不能上传文件夹,使用FileZilla可以拖拽上传文件或文件夹,参考AutoDL帮助文档,需要注意上传的位置,不要无脑拖拽,最好上传到root目录下自己创建的文件夹中(注意上传文件或者初始创建镜像的时候可以使用无卡模式,将文件上传完毕之后可能面对GPU被占用,此时只需要保存刚才创建的镜像(该镜像已包含上传的文件),用该镜像创建一个新的实例即可)
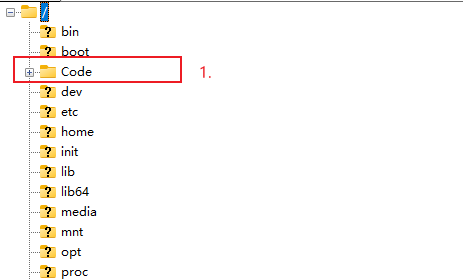
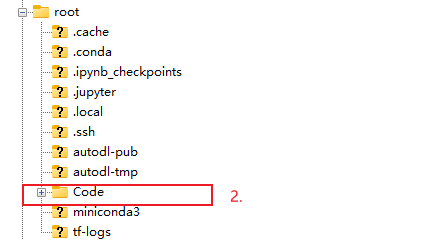
上面这个例子展示了两个自己创建的Code文件夹,并且其中的内容都一样,但是在jupyter lab中是找不到第一个Code的,因为jupyter lab的工作目录位于/root而非系统根目录/(数据盘、网盘、公共数据目录也在/root目录下),所以创建的文件夹必须位于root目录下才能被jupyter lab找到;
常见问题及解决方法(五)
Q_1:使用conda命令激活环境或会提示一堆看不懂的文字,关闭环境的时候也会报错,如下图
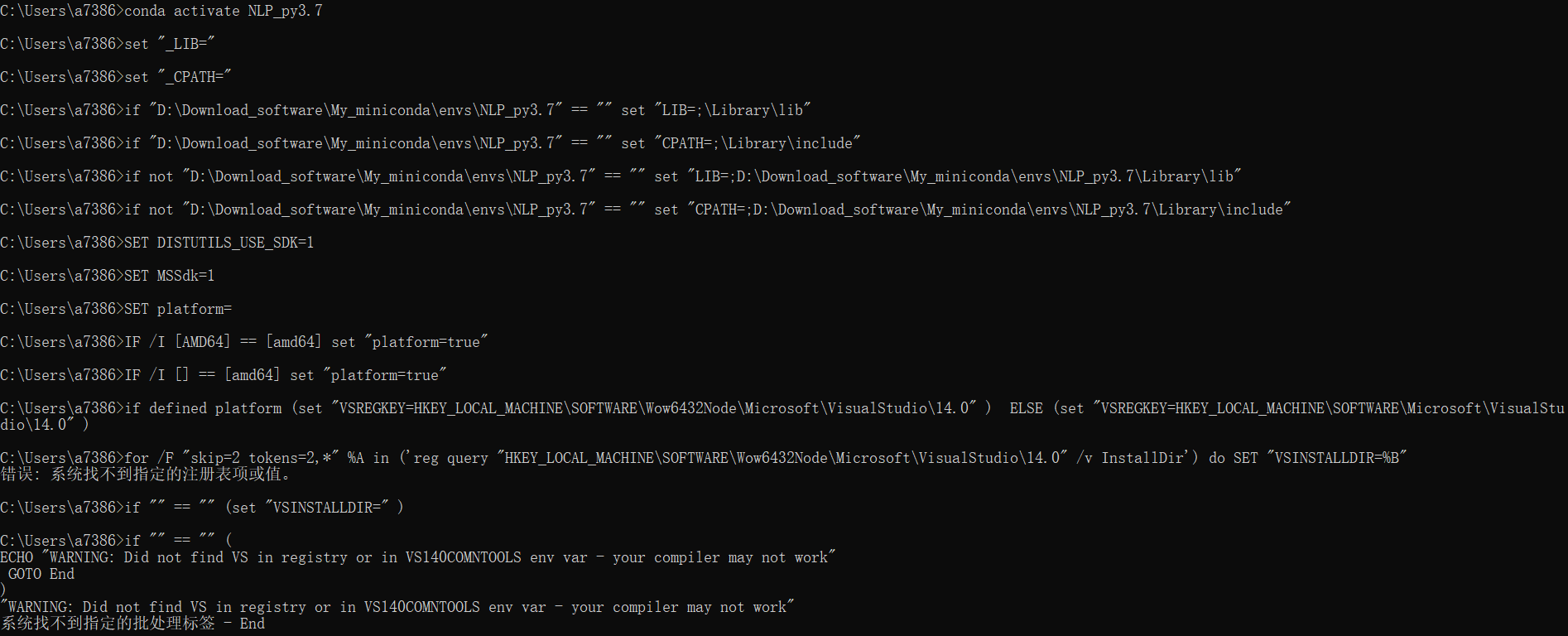
最离谱的是只有在激活NLP_py3.7这个环境的时候才会这样,其他虚拟环境一切正常,经过思考认为可能是由于今天上午在装一个库(python-compile库)的时候中途显示安装失败同时报了一些如注册表错误此类的信息,所以很有可能是其相关原因,但因为并不影响正常使用所以并未进行详细的探究;
- 解决参考:
- 未尝试:jupyter notebook爬坑记 - 知乎 (zhihu.com);
- 采用:因为只涉及这一个虚拟环境,所以大可直接不使用这个虚拟环境,删除之后重装即可;
- 问题跟进:
- 本来以为没啥问题,结果今天在调用NLP_py3.7这个环境用pytorch训练模型的时候居然直接训练抛出错误
操作系统无法运行 %1。 Error loading "D:\Download_software\My_miniconda\envs\,网上说更新pytorch也尝试了但还是不行,因此直接使用pytorch_3.7这个环境用于训练,把NLP_py3.7这个报错环境直接删除;
- 本来以为没啥问题,结果今天在调用NLP_py3.7这个环境用pytorch训练模型的时候居然直接训练抛出错误
Q_2:Kaggle中TF报错,即代码版本不匹配(常常发生在2.x使用1.x的代码);
A:参考(15条消息) module ‘tensorflow‘ has no attribute ‘placeholder‘_m0_54264218的博客-CSDN博客手动修改;However,简单的将2的代码改为1是可以的,但是难点就在于很多内置函数2根本没有,这就没法改了,参考Kaggle如何使用1.x的tf(15条消息) 用kaggle深度学习 踩坑_kaggle修改tensorflow版本_joesgod的博客-CSDN博客;
我个人是选择了直接对Kaggle中的tf降级:(15条消息) 在Kaggle上训练PointNet_laikh6的博客-CSDN博客,并没有发生文章中所说无法调用CPU的情况;
本来还有一种想法是在Kaggle中安装虚拟环境,在虚拟环境中安装tf1,但是Kaggle内核每次重启的时候都会丢失所有操作,包括安装的虚拟环境,同时Kaggle自带的shell是不支持conda命令的,结合这两点原因,选取了直接对Kaggle的tf进行降级的操作;
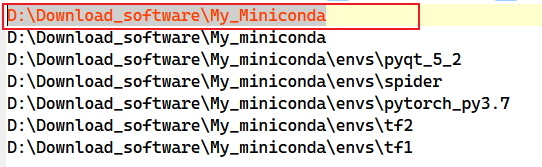
Q_3:conda导航器出现两个相同的路径?
A:参考去除显示重复的conda环境_anaconda环境里有两个相同环境_GTFQAQ的博客-CSDN博客解决,即直接删除environments.txt文件中的重复路径即可
Q_4:Pycharm中的terminal和interpreter的环境不同?
A:参考(4条消息) 解决Pycharm中terminal控制台环境与项目环境不一致问题_向阳花开0926的博客-CSDN博客,实际上就是把原本使用的powershell改成cmd,原因不是很清楚,但是非常有效。
需要注意的是,在VSCode中的终端虚拟环境的修改相对来说没那么智能(一次只能修改一个虚拟环境),因此建议不要使用VSCode自带的终端运行代码(真的想修改的话参考(3条消息) 手把手教你VScode终端自动激活anaconda的python虚拟环境_vscode anaconda虚拟环境_Icy Hunter的博客-CSDN博客);
Q_5:我想要下载一些数据集或者软件,直接在浏览器上面下载非常慢,应当如何解决?
A:这里推荐迅雷!非常好用(只要你多长个心眼别乱点合理使用完全没问题)。
Q_6:在Pycharm中我想要在子级中直接导入父级中的py文件,为什么一直给说找不到?
A:一个最简单暴力的方式就是将整个项目文件设置为Source Root(具体原因是啥我也不清楚,可以自行去Google上搜搜)
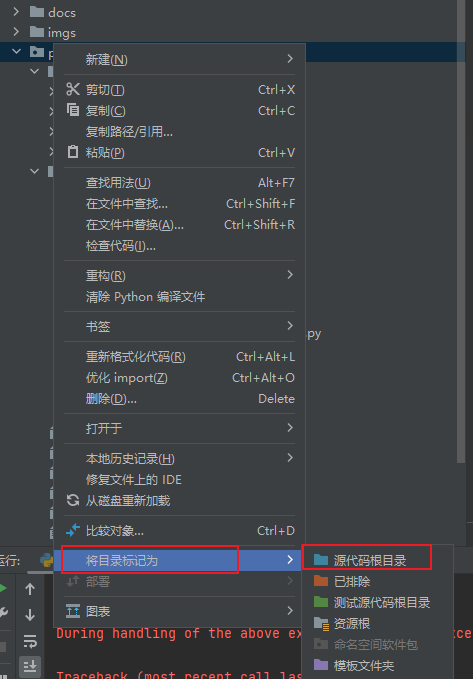
然后直接使用类似绝对路径的方式导入py文件中的函数(这种方式不管是同级还是子级一切都可以导入,而且这种方式的另一个好处就是无脑照着绝对路径写下来就行,绝对不会错)
1 | |
Q_7:使用pip安装某个包的时候连续报错

A:实际上是由于第一个错误引起的第二个错误,解决的话先解决第二个再解决第一个,先到对应目录下删除~开头的文件(这个问题就是因为下载中断导致)
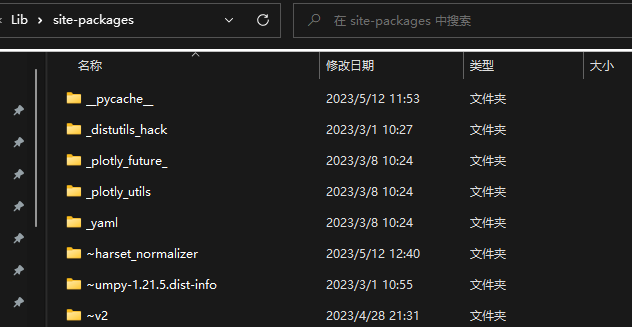
然后更新pip
1 | |
最后在使用pip的时候,最后加上--user即可