Python3_网络爬虫
本来是想把这个内容一起写在Python开发工具那一章的,无奈爬虫的知识体量实在太大了所以单独写一篇博客记录学习过程参考自书籍《Python3——网络爬虫开发实战》(非常感谢大佬写的书,写的真的很好很好)
2022/7/21 20:56 关于爬虫的学习可能得暂且告一段落了,因为之后的课程深度和前面几节基本不搭边,而且涉及的网络知识和电脑知识已经超过了现在我能掌握的水平,之后可能还会回过头来继续学习的,现阶段对于爬虫的掌握程度是:能够掌握基本的爬虫原理,知道具体有什么步骤,高级用法并不是很熟练;
2022/8/13 15:57 今天又稍微看了一下到第九章的代理,但是感觉这之后的内容的确是进阶的内容(普通的爬虫基本用不到这部分的知识点),然后因为本来平时使用的也少所以就决定暂时把爬虫这部分的内容放一放了;
环境配置
学习的第一步就是配置环境,这里简单做一下按照书上的教程进行环境安装的时候出现的一些问题以及解决办法(没有特殊备注的默认按照书上的教程不会出现问题)
2022/7/4
python3安装:这里我们直接使用miniconda搭建了一个新的spider环境,安装python==3.7.3
requests安装
selenimu安装
Chrome浏览器以及ChromeDriver安装
PhantomJS浏览器的下载与安装,解决方案参考(18条消息) module ‘selenium.webdriver‘ has no attribute ‘PhantomJS‘_走到哪,爬到哪的博客-CSDN博客
aiohttp安装
lxml安装
Beautiful Soup 安装
pyquery安装
tesseroct安装,在安装1.3.4 tesserocr的时候直接使用其安装包安装并下载语言拓展会导致被墙从而下载失败,所以最终选择了网上的方法(18条消息) tesseract-ocr在安装过程中出现Download error以及anaconda下安装tesserocr库_y180813的博客-CSDN博客,根据网上的方法在spider环境下面安装完成之后根据书上的测试方法一切都正常,注意我们文件的安装目录是在C:\Users\a7386\AppData\Local\Tesseract-OCR;还有就是安装错误之后第二次我选择的默认安装位置但是还是安装出错。然后我就跑去把C盘的Programx86文件夹下的一个相关文件夹删除了,不知道会不会有什么影响
Mysql安装:参考尚硅谷视频教程
MongoDB安装与配置:根据教程(18条消息) MongoDB的下载与安装_头秃怎么办的博客-CSDN博客_mongodb怎么下载
Redis的安装依据博客Redis下载与安装(Windows)_wx5da4624409480的技术博客_51CTO博客
Redis可视化工具安装依据博客(18条消息) Redis可视化连接工具RedisDesktopManager的下载与安装_乞力马扎罗の黎明的博客-CSDN博客_redis连接工具下载
Ruby安装教程(18条消息) 2. Ruby下载安装_开猿节流的博客-CSDN博客_ruby下载
PyMySQL安装
PyMongo安装
redis-py安装
Ruby安装:教程参考(18条消息) 2. Ruby下载安装_开猿节流的博客-CSDN博客_ruby下载
RedisDump安装
Flask安装
Tornado安装
Charles安装:破解以及安装参考(18条消息) 抓包工具Charles下载安装使用_Lucky52hz的博客-CSDN博客_charles下载
Charles安装及使用教程 - 圆圆测试日记 - 博客园 (cnblogs.com)
配置参考书上教程
mitproxy安装,启动过程中报错,解决方法:(18条消息) ImportError: cannot import name ‘soft_unicode‘ from ‘markupsafe‘_qq_36969407的博客-CSDN博客
手机证书配置过程查看(18条消息) Android手机安装.pem证书文件_太书红叶的博客-CSDN博客_安卓手机如何打开.pem文件,pem存放于手机Andriod目录下
2022/7/5
使用npm全局安装appium
Andriod Studio只是按照链接下载了,并没有安装,因为涉及到科学上网,同时我们使用Appium只需要Andriod SDK即可(18条消息) Android Studio 下载 与 安装 详细步骤_蚩尤后裔的博客-CSDN博客_android stuidio下载

Andriod SDK下载参考Android SDK的下载与安装 - 菜鸟学飞ing - 博客园 (cnblogs.com)
在安装Andriod SDK之前必须先配置JDK环境(18条消息) JDK下载与安装教程_墨笙弘一的博客-CSDN博客_jdk安装教程,否则会在开启SDK Manager的时候直接闪退(如果安装JDK任然闪退参考(18条消息) SDK Manager.exe打不开 闪退 的解决方法 win11下搭建android sdk_一丨丿丶乙7的博客-CSDN博客_android sdk打不开)
要说明一点——安装appium的环境是让我觉得最难受的,因为涉及到JAVA和Andriod等知识盲区,而且还要FQ之类的,可能安装过程有错误但是只能硬着头皮先装好,之后出问题了再修改即可;
++++++++下面是爬虫框架的安装++++++++
安装pyspider的时候爆红但是最终还是成功安装
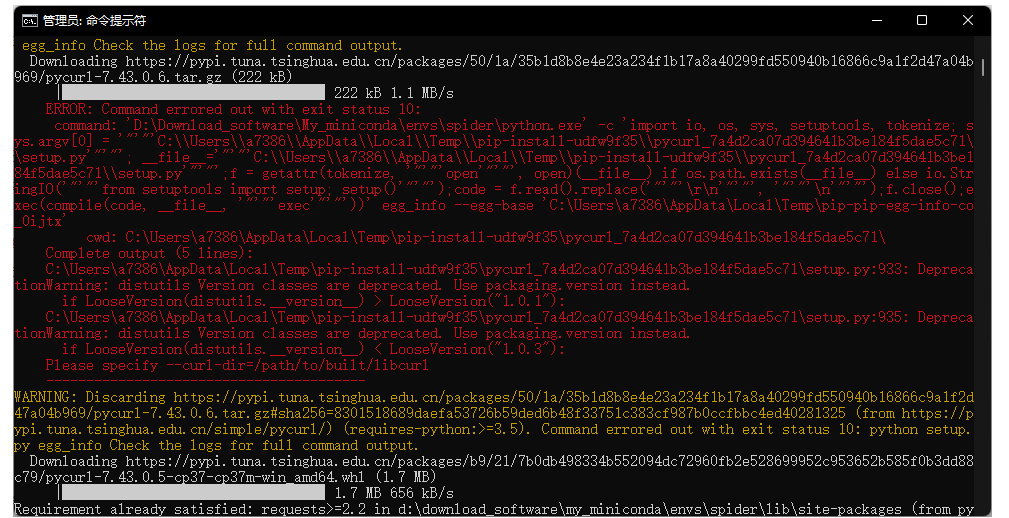
但是使用命令pyspider all的时候报错,这个报错搞了我一个小时,解决方法分很多步(pyspider这个库真的不稳定),最重要的一步Windows一定要关闭防火墙(控制面板关闭)
【转】pyspider运行卡死在result_worker starting 的解决办法 - 走看看 (zoukankan.com)
安装Scrapy直接使用conda即可安装完毕
安装scrapy-splash可能需要额外花费时间
+++++首先是splash服务的安装+++++
首先我们需要安装docker
安装Docker需要更新WSL参考安装Docker Desktop报错WSL 2 installation is incomplete. - 简书 (jianshu.com)
Docker配置参考(18条消息) Dockerapp安装与使用_宠乖仪的博客-CSDN博客
安装完成后使用Docker安装Splash参考(18条消息) Splash安装和使用_宠乖仪的博客-CSDN博客_splash安装
+++++接着是Scrapy-Splash的安装+++++
直接pip即可
Scrapy-Redis的安装
关于之后的Scrapyd的安装以及配件是Linux下,所以这里就直接略过
2022/7/5 19:20
至此,爬虫相关环境安装完毕,准备开始学习
2022/7/6
尝试安装jupyter notebook的时候安装成功但是报错了一小部分,原因是某些库的版本不兼容
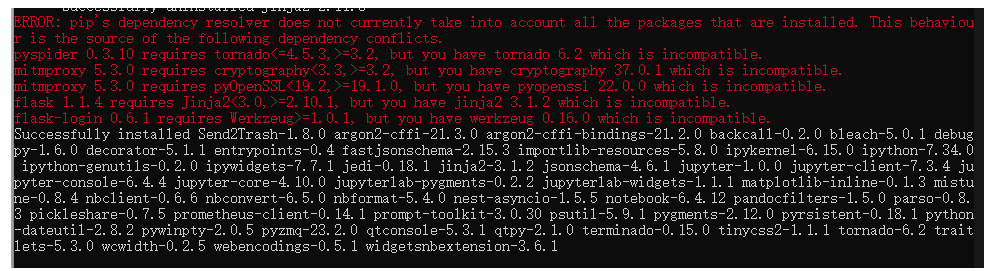
先正常使用,之后遇见问题再解决
爬虫基础(一)
21世纪,大数据成为最重要的经济资源之一,如何获取这些宝贵的资源成为一个问题,网络爬虫作为一种高效的信息采集利器,可以快速、准确的采集到需要的资源数据。
写爬虫之前我们需要了解一些基础知识(比方说我们之前配置环境安装的那么多库有什么用,专业术语又代表什么)
1.HTTP基本原理
1.1 URI和URL
我们在计网中只学习了URL(统一资源定位符),URI称为统一资源标志符;、
URL常见格式:<协议>://<主机>:<端口>/<路径>
<主机>就是存放资源的主机在因特网上的域名或IP地址
URL是URI的子集,URI还包括一个子类称为URN(统一资源名称);
URN可以只命名资源而不定位资源的位置,但是URN使用的非常少,几乎所有的URI都是URL;
1.2 HTTP和HTTPS
HTTP(超文本传输协议)用于网络传输超文本数据到本地浏览器,能保证高效、准确地传送超文本文档;
HTTPS(安全版HTTP)在HTTP下加入SSL层;
1.3 请求报文
请求由客户端发送给服务器,可分为大致四个部分:请求方法、请求URL、请求头和请求体
a)请求方法
假如使用GET方式请求登录,用户输入的·用户名和密码都会暴露在URL中造成密码泄露;
当文件过大时也采用POST的方式;

常见请求方法如下

b)请求头
请求头是请求的重要组成部分,大多数时候需要我们设定请求头,常见的头部信息如下

1.4 响应报文
响应是由服务端返回给客户端的,主要分为三部分:响应状态码、响应头和响应体
a)响应状态码
表示服务器的响应状态,下面给出了常见的错误代码和错误原因


b)响应头
包含了服务器对客户端请求的应答信息,下面展示常用的头信息

c)响应体
响应的正文数据都在响应体中,请求网页则响应体中是网页的HTML代码,请求图片则响应体中是图片的二进制数据;
响应体是响应最重要的内容,也是爬虫需要解析的内容;
爬虫主要通过响应体得到网页的源代码、JSON数据等,然后从中提取有用内容;
2.爬虫基本原理
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序;
爬虫第一步就是获取网页,也就是向网站服务器构造并发送一个请求,得到响应体中网页的源代码并将其解析出来,我们可以通过
urllib、requests库来实现获取网页,注意使用这两个库只能请求静态页面,要实现动态JS渲染界面的请求就需要借助Selenium、Splash来模拟;获取网页源代码后,需要分析网页源代码并从中提取出我们需要的数据,这里可以使用
正则表达式这种最万能但是也最麻烦的方法,也可以根据网页节点的属性、CSS选择器或者XPath来提取网页信息比如Beatiful Soup、pyquery、lxml库提取有效信息后我们需要将信息进行保存,有多种形式,可以简单的保存为TXT文本或者JSON文本,也可以保存到数据库如MySQL、MongoDB或者Redis,甚至可以借助SFTP保存至远程服务器;
基本库(二)
python为我们提供了功能非常强大的一系列库,如可以使我们无需关注如何构造请求报文、请求如何在网络中传输等问题,不必深入到底层去了解请求是如何传输和通信的;
下面介绍我们已安装或python内置的基本爬虫库;
1.urllib库
urllib库是python内置的HTTP请求库,因为是内置所以无需额外安装,主要包含以下四个模块:

1.1 request模块
(1)urlopen()方法

最基本的urlopen()使用方法如下
1 | |
(2)Request类
使用urlopen()方法可以完成最简单的请求和网页抓取,但是这几个简单的参数并不足以构建一个完整的请求,假如请求中需要加入Headers等信息需要使用Request类来构建;
Request类的构造函数如下

其中第一个参数url是必选参数,其他是可选参数;
下面我们使用一个实例展示如何传入多个参数构建请求对象,并将该对象作为参数传入urlopen()方法爬取网页
1 | |
(3)Handler类
我们通过上面构造Request类的对象的方法实现了构造请求,但是对于更高级的如Cookies、代理等该如何处理呢?
我们需要使用Handler工具类,它是一个强大的工具箱,可以利用不同的处理器处理登录验证、Cookies、代理设置;
urllib.request模块里的BaseHandler类是其他所有Handler的父类,提供了最基本的方法,各种Handler子类继承BaseHandler并拓展其功能,常见的Handler子类如下

通常我们都会将构建好的Handler和build_opener()方法来构造一个新的Opener,实现如验证、代理、Cookies等高级问题;
验证问题
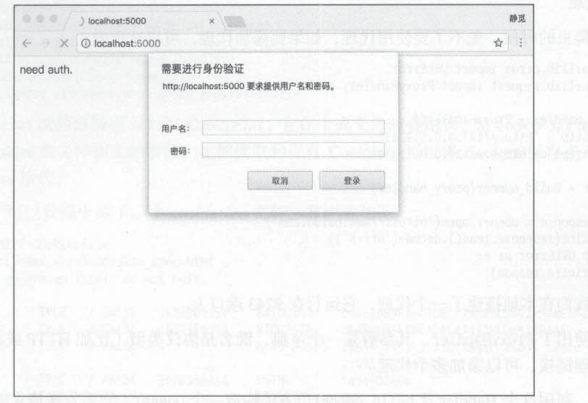
模板代码如下:
1 | |
代理问题
首先熟悉一下代理相关知识点,常见的代理使用方法主要有以下几种

代理的作用如下

爬虫需要添加代理可以使用如下代码
1 | |
Cookies问题
在介绍如何处理Cookies之前我们先简单介绍一下Cookies
Cookies常常和会话成对出现,众所周知HTTP是无状态的,会话和Cookies用于保持HTTP的连接状态(记住用户的登录状态);
会话在服务端,也就是网站的服务器,用来保存用户的会话信息;
Cookies 在客户端,有了 Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的响应
因此在爬虫中,有时候处理需要登录才能访问的页面时,我们一般会直接将登录成功后获取的 Cookies 放在请求头里面直接请求,而不必重新模拟登录(模拟登录可以使用selenium等或者用post提交登录信息)
获取网站的Cookies如下
1 | |
我们如何从文件中读取并使用生成的Coolies文件呢?参考如下代码
1 | |
1.2 error模块
urllib的error模块定义了由request模块产生的异常,假如在某些情况下(如网络状况不好)出现问题则request模块会抛出error模块中定义的异常;
合理使用error模块,通过捕获异常可以做出更准确的异常判断,使程序更加稳健;
(1)URLError类
URLError 类来自 urllib 库的 error 模块,它继承自 OSError 类,是 error 异常模块的基类,由 request 模块产生的异常都可以通过捕获这个类来处理;
它具有一个属性 reason,即返回错误的原因;
1 | |
(2)HTTPError类
HTTPError类是 URLError 的子类,专门用来处理 HTTP 请求错误,比如认证请求失败等。它有如下 3 个属性。
code:返回 HTTP 状态码,比如 404 表示网页不存在,500 表示服务器内部错误等;
reason:同父类一样,用于返回错误的原因;
headers:返回请求头;
因为HTTPError类是URLError类的子类,所以可以先获取子类异常,否则获取URL异常
1 | |
1.3 parse模块
urllib库的parse 模块,定义了处理 URL 的标准接口,比如实现 URL 各部分的抽取、合并以及链接转换;
(1)urlparse()方法
urlparse()方法的标准API如下
1 | |
- urlstring参数是必选项也就是待解析的URL;
- scheme:它是默认的协议(比如 http 或 https 等)。假如这个链接没有带协议信息,会将这个作为默认的协议(比如我们传入的urlstring参数为’www.baidu.com/index.html;user?id=5#comment'会根据我们所给的scheme默认添加进去);
- allow_fragments:即是否忽略 fragment。如果它被设置为 False,fragment 部分就会被忽略,它会被解析为 path、parameters 或者 query 的一部分
该方法可以实现 URL 的识别和分段
1 | |
URL链接标准格式
1 | |
比如说
1 | |
- :// 前面的就是 scheme,代表协议
http - 第一个 / 符号前面便是 netloc,即域名www.baidu.com
- path,即访问路径
index.html - 分号后面是 params,代表参数
user - 问号?后面是查询条件 query,一般用作 GET 类型的 URL
- 井号 #后面是锚点,用于直接定位页面内部的下拉位置
comment
(2)urlunparse()方法
urlparse()方法对应的是urlunparse()方法,其参数个数必须为6,用于构造URL
1 | |
(3)urlsplit()方法
这个方法和 urlparse 方法非常相似,只不过它不再单独解析 params 这一部分,只返回 5 个结果。urlparse()例子中的 params 会合并到 path 中;
(4)urlunsplit()方法
urlsplit()方法对应的是urlunsplit()方法,其参数个数必须为4,用于构造URL;
(5)urljoin()方法
有了 urlunparse() 和 urlunsplit() 方法,我们可以完成链接的合并,不过前提必须要有特定长度的对象,链接的每一部分都要清晰分开。
生成URL链接还有另一个方法,那就是 urljoin 方法。我们可以提供一个 base_url(基础链接)作为第一个参数,将新的链接作为第二个参数,该方法会分析 base_url 的 scheme、netloc 和 path 这 3 个内容并对新链接缺失的部分进行补充,最后返回结果。
base_url 需要提供三项内容 scheme、netloc 和 path;
- 如果这 3 项在新的链接里不存在,就予以补充;
- 如果新的链接存在,就使用新的链接的部分,此时 base_url 中的 params、query 和 fragment 是不起作用的
1 | |
(6)quote()方法
该方法可以将参数内容转化为 URL 编码的格式(对于我们爬取特定内容很有用)。URL 中带有中文参数时,有时可能会导致乱码的问题,此时用这个方法可以将中文字符转化为 URL 编码,示例如下:
1 | |
这里我们声明了一个中文的搜索文字,然后用 quote 方法对其进行 URL 编码,最后得到的结果如下:
1 | |
(7)unquote()方法
有了 quote 方法,当然还有 unquote 方法,它可以进行 URL 解码,示例如下:
1 | |
这是上面得到的 URL 编码后的结果,这里利用 unquote 方法还原,结果如下:
1 | |
可以看到,利用 unquote 方法可以方便地实现解码。
之后是几个不常见的模块这里不再赘述
1.4 robotparser模块
利用 urllib 的 robotparser 模块,我们可以实现网站 Robots 协议的分析;
Robots 协议也称作爬虫协议、机器人协议,它的全名叫作网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取;
Robots 协议通常保存为一个叫作 robots.txt 的文本文件,一般放在网站的根目录下;
- 当搜索爬虫访问一个站点时,它首先会检查这个站点根目录下是否存在 robots.txt 文件,如果存在,搜索爬虫会根据其中定义的爬取范围来爬取;
- 如果没有找到这个文件,搜索爬虫便会访问所有可直接访问的页面。
一般robots.txt文件的格式如下
1 | |
(1)RobotFileParser类
RobotFileParse类的常用方法如下
- set_url :用来设置 robots.txt 文件的链接。如果在创建 RobotFileParser 对象时传入了链接,那么就不需要再使用这个方法设置了
1 | |
read:读取 robots.txt 文件并进行分析。注意,这个方法执行一个读取和分析操作,如果不调用这个方法,接下来的判断都会为 False,所以一定记得调用这个方法。这个方法不会返回任何内容,但是执行了读取操作。
parse:用来解析 robots.txt 文件,传入的参数是 robots.txt 某些行的内容,它会按照 robots.txt 的语法规则来分析这些内容。
can_fetch:该方法传入两个参数,第一个是 User-agent,第二个是要抓取的 URL。返回的内容是该搜索引擎是否可以抓取这个 URL,返回结果是 True 或 False。
mtime:返回的是上次抓取和分析 robots.txt 的时间,这对于长时间分析和抓取的搜索爬虫是很有必要的,你可能需要定期检查来抓取最新的 robots.txt。
modified:它同样对长时间分析和抓取的搜索爬虫很有帮助,将当前时间设置为上次抓取和分析 robots.txt 的时间。
直接上代码
1 | |
2.requests库
前面介绍的urllib库因为是内置的,多少有些功能不够完善,在解决验证和Cookies时需要非常麻烦的行为,这里我们引入功能更加强大的requests库,可以轻松解决验证、代理等问题;
2.1 GET请求
HTTP 中最常见的请求之一就是 GET 请求,下面首先来详细了解一下利用 requests 库构建 GET 请求的方法;
首先是简单的直接构造一个GET请求,传入的参数是URL
1 | |
(1)附加信息
对于 GET 请求,如果要附加额外的信息,一般使用字典存储要添加的信息数据,然后借助params参数即可将请求的链接自动构造成http://httpbin.org/get?age=22&name=germey
1 | |
接着书上给我们讲解了一些例子,分别是
- 爬取知乎网站返回HTML文档,使用正则表达式进行解析提取有用内容;
- 爬取Github网站的icon图标(返回二进制数据),使用open方法以二进制写形式打开,将图标保存在文件中——这启发我们音频、视频也可以这样爬取并保存;
注意,如果网站返回的是二进制数据,千万别用简单粗暴的print(r.text)将其转换为str类型来输出,这将得到一堆乱码;
(2)添加headers
针对某些网站(如知乎),如果不添加headers头信息的某些信息(如User-Agent 字段信息,也就是浏览器标识信息)直接爬取会被知乎给禁止,
除了User-Agent,我们可以在headers中添加其他合法字段信息
1 | |
2.2 POST请求
使用requests库实现POST请求同样非常简单(前面我们介绍urllib库没有明确区分GET请求和POST请求,两者的区别在最前面1.3 请求报文中介绍过)
1 | |
2.3 高级用法
前面的GET请求和POST请求都是比较简单的requests库的用法,还不足以体现其优越性,下面介绍一些requests库的高级用法(因为requests库没有明显区分什么模块,所以我们没有像介绍iurllib一样的结构去介绍)
(1)文件上传
requests 可以模拟提交一些数据。假如有的网站需要上传文件,我们也可以用它来实现:
1 | |
(2)Cookies
前面我们使用 urllib 处理过 Cookies,写法比较复杂,而有了 requests,获取和设置 Cookies 只需一步即可完成;
先介绍获取Cookies的方法:
1 | |
使用Cookies来维持某个网站的登陆状态也非常简单:
- 首先登录该网站,找到Headers里面的Cookies将其复制下来;

- 接着直接在Headers里面设置刚刚复制的Cookies即可
1 | |
(3)会话
在 requests 中,使用get()或post()发送请求相当于建立不同的会话,也就是说使用两次GET或者POST请求相当于用了两个浏览器打开了网站,这两个页面是不相关无联系的;
设想这样一个场景,第一个请求利用 post() 方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,于是又用了一次 get() 方法去请求个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,这将导致获取个人信息失败(因为get()那个页面实际上并没有登录成功)
解决方法1:在两次请求时设置一样的 cookies;
解决方法2:解决方法1因为每次爬取网页都需要附带发送登录成功的Cookies以通过服务器识别,所以显得可能会比较复杂;我们思考能否维持该会话,这样就不需要我们重新登录或者用Cookies伪装;
疑问:既然有会话维持这么高级的功能,那Cookies的功能应该被取代…?有没有一种可能是因为urllib中只有手动添加Cookies这种低级方法所以才在requests中保留了Cookies的用法;
1 | |
利用 Session,可以做到模拟同一个会话而不用担心 Cookies 的问题。它通常用于模拟登录成功之后再进行下一步的操作;
Session 在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面;
(4)SSL证书验证
关于这个用法就属于非常高级的领域了,这里我们暂时先不研究(毕竟证书那一块我都还没接触过);
(5)代理设置
前面也说过,对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的 IP,导致一定时间段内无法访问。那么,为了防止这种情况发生,我们需要设置代理来解决这个问题,这就需要用到 proxies 参数。
1 | |
除了基本的 HTTP 代理外,requests 还支持 SOCKS 协议的代理。
首先,需要安装 socks 这个库:
1 | |
然后就可以使用 SOCKS 协议代理了,示例如下:
1 | |
(6)超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错(比如请求github经常会超时);
为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没有得到响应,那就抛出异常,可以结合异常处理函数进行下一步处理(而不是一直傻等着程序报错说超时了)。这需要用到 timeout 参数。这个时间的计算是发出请求到服务器返回响应的时间;
1 | |
如果想永久等待,可以直接将 timeout 设置为 None,或者不设置直接留空,因为默认是 None。这样的话,如果服务器还在运行,但是响应特别慢,那就慢慢等吧,它永远不会返回超时错误的。其用法如下:
1 | |
(7)身份认证
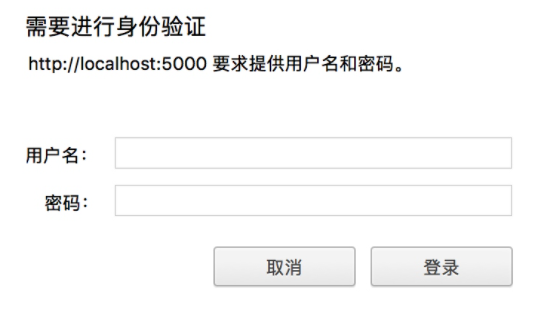
遇到这种认证问题,requests自带认证功能
1 | |
如果用户名和密码正确的话,请求时就会自动认证成功,会返回 200 状态码;如果认证失败,则返回 401 状态码
(8)Prepared Request
前面介绍 urllib 的Request类时,将各个参数通过一个 Request 对象来表示,这样发送请求的时候直接将对象作为参数传入即可;
在 requests 里同样可以做到,这个数据结构就叫 Prepared Request(需要由Session 的 prepare_request 方法转换为Prepared Request 对象)
1 | |
这里我们引入了 Request,然后用 url、data 和 headers 参数构造了一个 Request 对象,这时需要再调用 Session 的 prepare_request 方法将其转换为一个 Prepared Request 对象,然后调用 send 方法发送即可;
3.正则表达式
正则表达式是处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证都不在话下。对于爬虫来说,有了它,从 HTML 里提取想要的信息就非常方便了。
常用匹配规则:
| 模 式 | 描 述 |
|---|---|
| \w | 匹配字母、数字及下划线 |
| \W | 匹配不是字母、数字及下划线的字符 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字的字符 |
| \A | 匹配字符串开头 |
| \Z | 匹配字符串结尾,如果存在换行,只匹配到换行前的结束字符串 |
| \z | 匹配字符串结尾,如果存在换行,同时还会匹配换行符 |
| \G | 匹配最后匹配完成的位置 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 匹配任意字符,除了换行符,当 re.DOTALL 标记被指定时,则可以匹配包括换行符的任意字符 |
| […] | 用来表示一组字符,单独列出,比如 [amk] 匹配 a、m 或 k |
| [^…] | 不在 [] 中的字符,比如 [^abc] 匹配除了 a、b、c 之外的字符 |
| * | 匹配 0 个或多个表达式 |
| + | 匹配 1 个或多个表达式 |
| ? | 匹配 0 个或 1 个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配 n 个前面的表达式 |
| {n, m} | 匹配 n 到 m 次由前面正则表达式定义的片段,贪婪方式 |
| a | b |
| ( ) | 匹配括号内的表达式,也表示一个组 |
Python 的 re 库提供了整个正则表达式的实现,利用这个库,可以在 Python 中使用正则表达式
3.1 match()方法
功能:向它传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否匹配字符串;match 方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 None
1 | |
- 如果我们只是想要提取匹配字符串中的某些内容,可以在进行匹配的时候在正则表达式中为想要提取的子字符串添加括号,之后输出按照group(1)、group(2)的顺序依次输出匹配的分组;
- 假如字符串中出现换行符(HTML中经常出现),则需要额外添加修饰符才能成功匹配
1 | |
常用修饰符如下
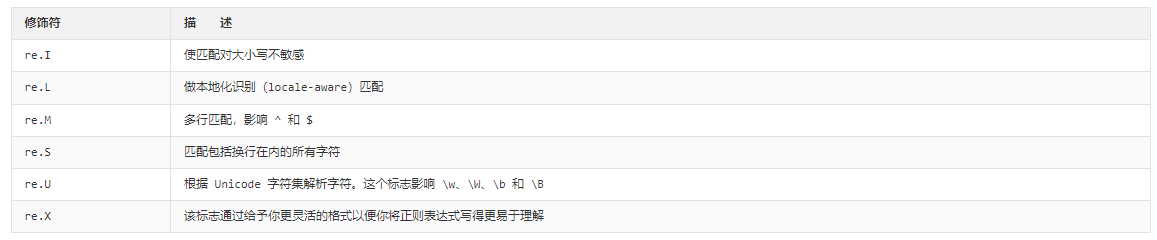
3.2 search()方法
match 方法是从字符串的开头开始匹配的,一旦开头不匹配,那么整个匹配就失败了——match 方法更适合用来检测某个字符串是否符合某个正则表达式的规则;
search方法在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果。也就是说,正则表达式可以是字符串的一部分,在匹配时,search 方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完了还没有找到,就返回 None;
3.3 findall()方法
search 方法的用法,它可以返回匹配正则表达式的第一个内容,但是如果想要获取匹配正则表达式的所有内容,这时就要借助 findall 方法了。该方法会搜索整个字符串,然后返回匹配正则表达式的所有内容
返回的列表中的每个元素都是元组类型,我们用对应的索引依次取出即可
3.4 sub()方法
正则表达式除了可以用来匹配信息外,还可以用来修改文本,比如将文本中的所有数字都去掉
1 | |
sub()方法对于HTML文档的提取也有一定作用,我们可以事先使用sub()方法替换掉HTML文档中的无用内容,然后使用findall()方法等进行匹配提取
3.5 compile()方法
compile方法可以将正则表达式编译成一个正则表达式对象,便于之后复用(复用的时候直接调用对象名而不用重新书写正则表达式了);
1 | |
compile 还可以传入修饰符,例如 re.S 等修饰符,这样在 search、findall 等方法中就不需要额外传了;
解析库(三)
前面介绍的使用正则表达式对网页信息进行解析非常的麻烦,而且也记不住…适用于非常牛的选手使用,下面我们介绍一些借助Python库的方法来解析网页信息;
对于网页HTML的节点来说,它可以定义id、class或其他属性。而且节点之间还有层次关系,在网页HTML中可以通过XPath(XML路径语言,XML是HTML的元语言)或CSS选择器(HTML中的选择器)来定位一个或多个节点。那么反过来,在页面解析时,利用XPath或CSS选择器来提取某个节点,然后再调用相应方法获取它的正文内容或者属性,不就可以提取我们想要的任意信息了吗?
1.lxml库
- lxml是一个Python库,使用它可以轻松处理XML和HTML文件,还可以用于web爬取。主要优点是易于使用,在解析大型文档时速度非常快,归档的也非常好,并且提供了简单的转换方法来将数据转换为Python数据类型,从而使文件操作更容易。
- XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。它最初是用来搜寻 XML 文档的,但是它同样适用于 HTML 文档的搜索;
通过 Python 的 lxml 库,利用 XPath选择器 进行 HTML 的解析抽取相应的信息;
1.1 初始化
在进行解析之前我们需要先引入需要解析的文本文件;
- 使用字符串变量(通常是上一步得到的HTML代码)
1 | |
- 使用HTML代码文件
1 | |
./test.html文件中的内容如下
1 | |
XPath学习教程可以参考10天快速学会【爬虫】 +【 数据分析】实战_哔哩哔哩_bilibili
XPath使用规范可以参考XPath 教程 (w3school.com.cn)
1.2 匹配规则
常用规则如下
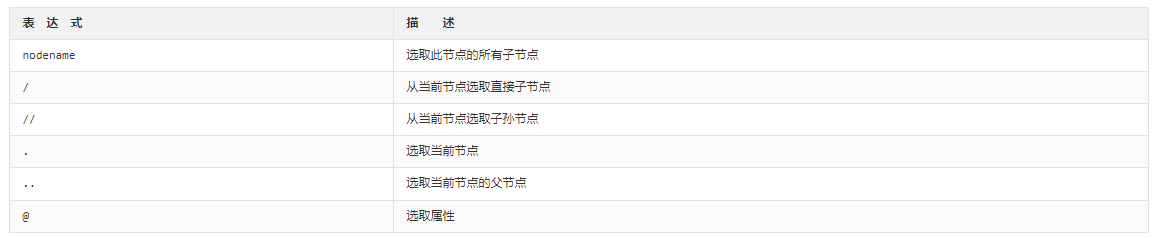
(1)获取所有节点
一般会用 // 开头的 XPath 规则来选取所有符合要求的节点(注意输出都是列表,每个元素都是Element类型,其后跟节点名称);
- 选取所有节点
1 | |
- 选取所有li节点
1 | |
(2)获取子节点
通过 / 或 // 即可查找元素的子节点或子孙节点,/ 用于获取直接子节点,// 用于获取子孙节点;
- 选择 li 节点的
所有直接 a 子节点
1 | |
- 获取 ul 节点下的
所有子孙 a 节点
1 | |
(3)获取父节点
通过..实现选中父节点,也可以通过 parent:: 来获取父节点
- 选中 href 属性为 link4.html 的 a 节点,然后再获取其父节点,然后再获取其 class 属性
1 | |
1 | |
(4)属性匹配
可以用 @符号进行属性过滤
- 选取 class 为 item-0 的 li 节点
1 | |
假如class有两个属性值item-0和item-1,则需要使用contains方法
1 | |
还有一种情况是我们需要多个属性来确定一个节点,使用and操作符
1 | |
1.3 获取文本和属性
我们通过上面的方法可以成功获取到节点,接着我们介绍如何获取节点中的文本和属性;
用 XPath 中的 text 方法获取节点中的文本;
- 获取某些特定子孙节点下的所有文本
1 | |
- 获取所有子孙节点内部的所有文本
1 | |
如果要想获取子孙节点内部的所有文本,可以直接用 // 加 text 方法的方式,这样可以保证获取到最全面的文本信息,但是可能会夹杂一些换行符等特殊字符;
如果想获取某些特定子孙节点下的所有文本,可以先选取到特定的子孙节点,然后再调用 text 方法方法获取其内部文本,这样可以保证获取的结果是整洁的;
获取属性只需要使用@符号即可
1 | |
2.Beautiful Soup库
Beautiful Soup借助网页的结构和属性等特性来解析网页。有了它,我们不用再去写一些复杂的正则表达式,只需要简单的几条语句,就可以完成网页中某个元素的提取。
BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据(Beautiful Soup库已经成为和lxml一样出色的Python解析库),Beautiful Soup实际上是依赖于其他解析库的解析器

综上所述,lxml解析器是首选,所以下面我们都是基于依赖于lxml的Beautiful Soup进行解析;
BS常用提供了三种选择器:
- 节点选择器
- 方法选择器
- CSS选择器
2.1 初始化
- 使用字符串变量,通常是上一步得到的HTML代码
1 | |
- 使用HTML代码文件
1 | |
2.2 节点选择器
直接调用节点的名称就可以选择节点元素,再调用 string 属性就可以得到节点内的文本了,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析;
1 | |
当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略;
经过选择器选择后的结果都是 bs4.element.Tag 类型。Tag 具有一些属性,比如 string 属性,调用该属性,可以得到节点的文本内容;
1 | |
- 获取节点名称
1 | |
- 获取节点属性
1 | |
因为节点选择其返回的是节点类型这种特殊类型,所以可以在返回值的基础上继续调用选择器选择节点,也就衍生出了嵌套选择、关联选择等
2.3 方法选择器
(1)find_all()
find_all,顾名思义,就是查询所有符合条件的元素,可以给它传入一些属性或文本来得到符合条件的元素
1 | |
(2)find()
除了 find_all 方法,还有 find 方法,只不过 find 方法返回的是单个元素,也就是第一个匹配的元素,而 find_all 返回的是所有匹配的元素组成的列表;
- 返回结果不再是列表形式,而是第一个匹配的节点元素,类型依然是 Tag 类型
2.4 CSS选择器
使用 CSS 选择器,只需要调用 select 方法,传入相应的 CSS 选择器即可(这个在前端开发中有介绍过),返回的节点类型依然是Tag类型;
(CSS选择器查看笔记CSS · 语雀 (yuque.com)即可)
3.pyquery库
Beautiful Soup的CSS选择器使用起来并不是很方便,下面介绍一个新的解析库——pyquery
3.1 初始化
- 字符串初始化
1 | |
- URL初始化
初始化的参数不仅可以以字符串的形式传递,还可以传入网页的 URL,此时只需要指定参数为 url 即可
1 | |
- 文件初始化
1 | |
因为Pyquery涉及的参数也都是CSS选择器,所以这里就跳过不再赘述;
文件存储(四)
文件存储形式多种多样,比如可以保存成 TXT 纯文本形式,也可以保存为 JSON 格式、CSV 格式等(之后会介绍数据库存储)
1.TXT文件存储
将数据保存到 TXT 文本的操作非常简单,而且 TXT 文本几乎兼容任何平台,但是这有个缺点,那就是不利于检索。所以如果对检索和数据结构要求不高,追求方便第一的话,可以采用 TXT 文本存储;
1 | |
首先,用 requests 提取知乎的 “发现” 页面,然后将热门话题的问题、回答者、答案全文提取出来,然后利用 Python 提供的 open 方法打开一个文本文件,获取一个文件操作对象,这里赋值为 file,接着利用 file 对象的 write 方法将提取的内容写入文件,最后调用 close 方法将其关闭,这样抓取的内容即可成功写入文本中了
上面的实例中,open 方法的第二个参数设置成了 a,这样在每次写入文本时不会清空源文件,而是在文件末尾写入新的内容,这是一种文件打开方式。关于文件的打开方式,其实还有其他几种,这里简要介绍一下。
- r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
- rb:以二进制只读方式打开一个文件。文件指针将会放在文件的开头。
- r+:以读写方式打开一个文件。文件指针将会放在文件的开头。
- rb+:以二进制读写方式打开一个文件。文件指针将会放在文件的开头。
- w:以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。
- a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
- ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。
- a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件来读写。
- ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件用于读写。
2.JSON文件存储
JSON,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式;
2.1 对象和数组
JavaScript 语言中,一切都是对象。因此,任何支持的类型的数据都可以通过 JSON 来表示,例如字符串、数字、对象、数组等,而JSON是通过对象和数组的组合来表示数据,所以下面简单介绍一下JS中的对象和数组类型;
对象:它在 JavaScript 中是使用花括号 {} 包裹起来的内容,数据结构为 {key1:value1, key2:value2, …} 的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。获取键值时有两种方式,一种是中括号加键名,另一种是通过 get 方法传入键名。这里推荐使用 get 方法,这样如果键名不存在,则不会报错,会返回 None。另外,get 方法还可以传入第二个参数(即默认值),如果传入第二个参数(即默认值),那么在不存在的情况下返回该默认值;
数组:数组在 JavaScript 中是方括号 [] 包裹起来的内容,数据结构为 [“java”, “javascript”, “vb”, …] 的索引结构。在 JavaScript 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
一个 JSON 对象可以写为如下形式:
1 | |
2.2 处理JSON文本
我们可以调用 JSON 库的 loads 方法将 JSON 文本字符串转为 JSON 对象,可以通过 dumps() 方法将 JSON 对象转为文本字符串;
如果从 JSON 文本中读取内容,例如这里有一个 data.json 文本文件,其内容是之前定义过的 JSON 字符串(一定注意JSON文本文件中保存的依然是字符串!!!),我们可以先将文本文件内容读出,然后再利用 loads 方法转化
1 | |
千万注意 JSON 字符串的表示需要用双引号而非单引号
对于保存JSON文本有两种方法:
- 一种是先转换为文本字符串再调用文件的write()方法写入文本,保存为txt格式;
1 | |
- 另一种是直接保存为JSON格式的文件,可以增加参数indent表示缩进字符个数使格式清晰
1 | |
当写入文本中有中文时,需要指定参数 ensure_ascii 为 False,另外还要规定文件输出的编码
1 | |
3.CSV文件存储
CSV,全称为 Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,它包含了文本、数值、公式和格式等内容,而 CSV 中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候用 CSV 来保存数据是比较方便的
3.1 写入CSV文件
1 | |
写入的文本默认以逗号分隔,调用一次 writerow 方法即可写入一行数据
- 如果想修改列与列之间的分隔符,可以传入 delimiter 参数
1 | |
- 可以调用 writerows 方法同时写入多行,此时参数需要为二维列表
1 | |
- 在 csv 库中也提供了字典的写入方式
1 | |
如果要写入中文内容的话,可能会遇到字符编码的问题,此时需要给 open 参数指定编码格式
如果使用Pandas等库,可以调用 DataFrame 对象的 to_csv 方法来将数据写入 CSV 文件中
3.2 读取CSV文件
1 | |
- 如果 CSV 文件中包含中文的话,还需要指定文件编码
- 如果接触过 pandas 的话,可以利用 read_csv 方法将数据从 CSV 中读取出来
数据库存储(五)
1.关系型数据库
(这一章的内容也就是结合了嵌入式SQL的知识点和MySQL基本语句的使用,可以在之后强化学习的时候再仔细看)
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作某个实体的集合,而实体之间存在联系,这就需要表与表之间的关联关系来体现,如主键外键的关联关系。多个表组成一个数据库,也就是关系型数据库;
常用的关系型数据库主要有MySQL、Oracle;
Python3主要使用 PyMySQL 操作 MySQL 数据库;
2.非关系型数据库
NoSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。NoSQL 是基于键值对的,而且不需要经过 SQL 层的解析,数据之间没有耦合性,性能非常高。
非关系型数据库又可细分如下:
键值存储数据库:代表有 Redis、Voldemort 和 Oracle BDB 等;
列存储数据库:代表有 Cassandra、HBase 和 Riak 等;
文档型数据库:代表有 CouchDB 和 MongoDB 等;
图形数据库:代表有 Neo4J、InfoGrid 和 Infinite Graph 等;
对于爬虫的数据存储来说,一条数据可能存在某些字段提取失败而缺失的情况,而且数据可能随时调整。另外,数据之间还存在嵌套关系。如果使用关系型数据库存储,一是需要提前建表,二是如果存在数据嵌套关系的话,需要进行序列化操作才可以存储,这非常不方便。如果用了非关系型数据库,就可以避免一些麻烦,更简单高效;
常用的非关系型数据库主要有MongoDB、Redis;
Ajax技术(六)
利用前面的知识点我们基本上能够爬取一些简单的网页了,但是当我们遇到动态网页的时候还是使用前面介绍的方法就会出很大问题,例如当我们使用requests抓取页面信息的时候,抓取的结果和在浏览器上看到的不一样。浏览器中显示正常的页面数据,但是抓取的却是没有具体数据或者说只是首界面的源码。这是因为requests获取的都是原始的HTML文档,而浏览器中的页面则是经过JavaScript处理数据后生成的结果,这些数据的来源有多种,可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。
对于第一种情况,现在很多Web页面的原始HTML页面不会包含任何数据,数据通过Ajax统一加载出来再呈现出来,这样Web就可以做到前后端的分离,而且降低了服务器直接渲染页面带来的压力,但是这样就不太方便咱们直接无脑抓取网页信息,咱们需要使用requests来模拟Ajax请求;
Ajax笔记参考Ajax · 语雀 (yuque.com)(这个笔记含量有点水,只介绍了怎么使用AJAX并没有讲AJAX的原理,爬虫需要涉及的前端底层原理还是挺多的)
Ajax,全称为 Asynchronous JavaScript and XML,即异步 JavaScript 和 XML。它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了;
1.Ajax工作原理
发送 Ajax 请求到网页更新的这个过程可以简单分为以下 3 步:
- 发送请求
- 解析内容
- 渲染网页
1.1 发送请求
我们知道 JavaScript 可以实现页面的各种交互功能,Ajax 也可以实现页面的各种交互功能,因为它也是由 JavaScript 实现的,实际上执行了如下代码:
1 | |
这是 JavaScript 对 Ajax 最底层的实现,这里请求的发送变成 JavaScript 来完成(而不是Python,因为咱们现在讲的是Ajax的底层原理,和Python没有关系),由于设置了监听,所以当服务器返回响应时,onreadystatechange 对应的方法便会被触发,然后在这个方法里面解析响应内容即可。
1.2 解析内容
得到响应之后,onreadystatechange 属性对应的方法便会被触发,此时利用 xmlhttp 的 responseText 属性便可取到响应内容。这类似于 Python 中利用 requests 向服务器发起请求,然后得到响应的过程。那么返回内容可能是 HTML,可能是 JSON,接下来只需要在方法中用 JavaScript 进一步处理即可。
1.3 渲染网页
JavaScript 有改变网页内容的能力,解析完响应内容之后,就可以调用 JavaScript 来针对解析完的内容对网页进行下一步处理了。
上例中,document.getElementById("myDiv").innerHTML=xmlhttp.responseText 便将 ID 为 myDiv 的节点内部的 HTML 代码更改为服务器返回的内容,这样 myDiv 元素内部便会呈现出服务器返回的新数据,网页的部分内容看上去就更新了(这样的操作也被称作 DOM 操作,即对 Document 网页文档进行操作,如更改、删除等)。
总结:上述三个步骤其实都是由 JavaScript 完成的(Ajax只是一种技术,用的语言还是JS),它完成了整个请求、解析和渲染的过程。例如微博的下拉刷新,本质上就是 JavaScript 向服务器发送了一个 Ajax 请求,然后获取新的微博数据,将其解析,并将其渲染在网页中。
2.Ajax分析
我们可以通过过滤选项卡得到在页面加载过程中浏览器与服务器之间发送请求和接收响应的所有Ajax记录,当页面出现Ajax刷新的时候开发者工具中也会相继出现Ajax请求,随意点开一个条目,都可以清楚地看到其 Request URL、Request Headers、Response Headers、Response Body 等内容,此时想要模拟请求和提取就非常简单了;
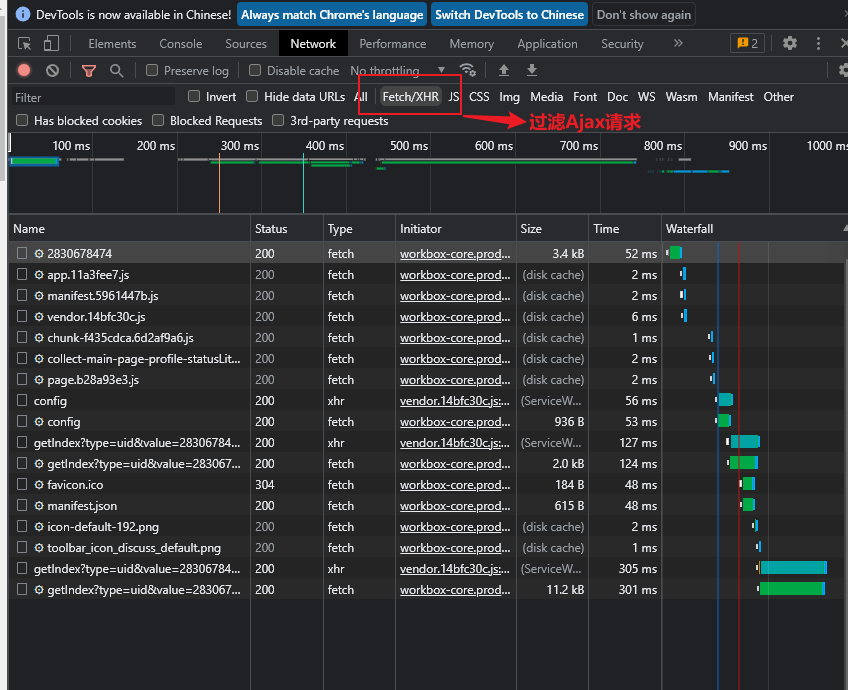
2.1 分析请求
Ajax 有其特殊的请求类型Type,它叫作 xhr,这里我们选择其中一个Ajax请求(当然我们直接选择使用上面的过滤器更好),点击该请求分析它的参数信息;
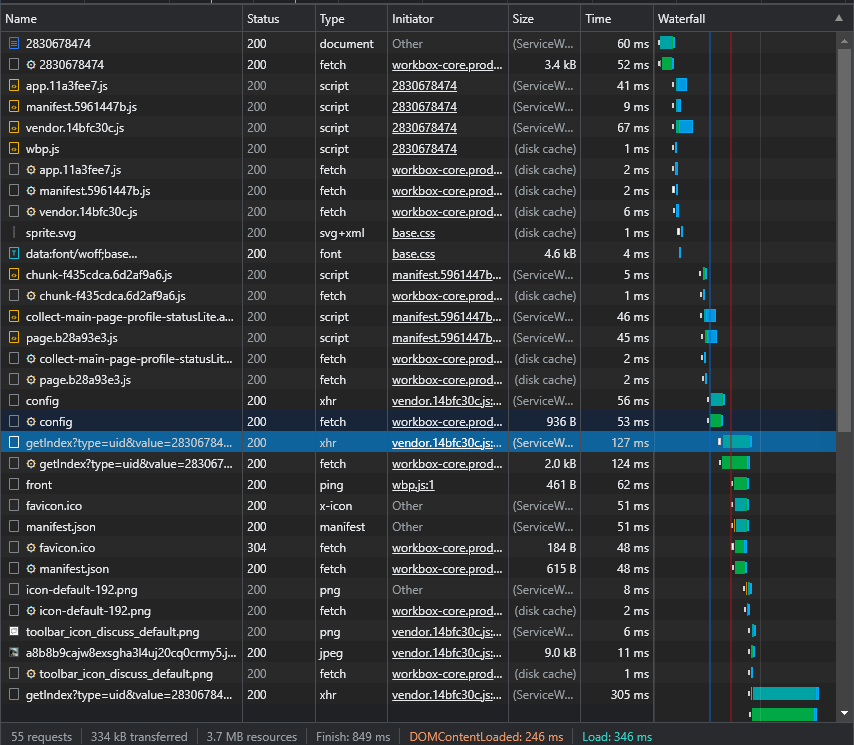
Request Headers 中有一个信息为 X-Requested-With:XMLHttpRequest,这就标记了此请求是 Ajax 请求;
- 这是一个Get请求,请求连接在Request URL后;

2.2 分析响应
Preview中是经过Chrome自动解析过的JSON格式的相应内容,是用来渲染网页所使用的数据;
Response中是真实的返回数据;
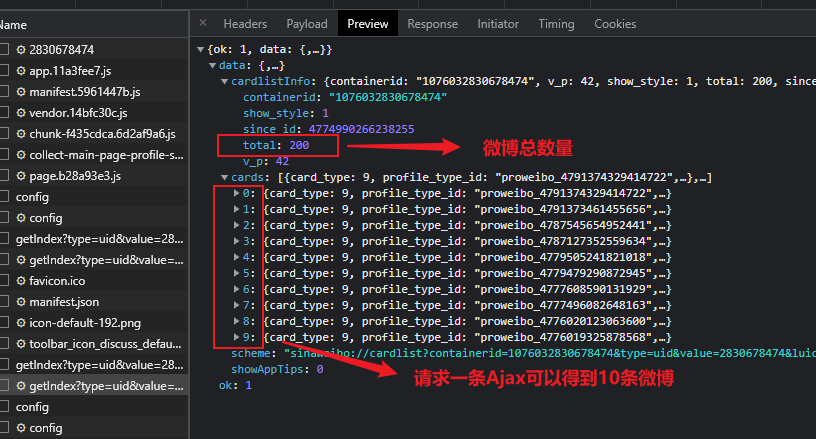
请求一个接口,就可以得到 10 条微博,而且请求时只需要改变 page 参数即可 —— 因此只需要简单做一个循环,就可以获取由Ajax技术返回的所有微博;
关于如何处理Ajax的数据爬取,本质上是非常简单的,只需要仔细分析请求和响应中的特征字段然后利用循环或者一些函数模拟发送Ajax请求即可爬取完整的内容,故此处就不再展示相关python代码;
动态页面(七)
上面所说的Ajax技术属于一种JS动态渲染技术,通过直接分析Ajax请求和响应可以借助之前的requests或者urllib实现数据的爬取;
However,JS的动态渲染可不止Ajax这一种技术,况且有些网页的Ajax的接口含有很多加密参数难以人工分析找出规律;
为了解决爬取动态页面出现的问题,可以直接使用模拟浏览器运行的方式来实现,这样就可以做到在浏览器中看到是什么样,抓取的源码就是什么样,也就是可见即可爬。这样我们就不用再去管网页内部的JavaScript用了什么算法宣染页面,不用管网页后台的Ajax接口到底有哪些参数;
Python提供了大量模拟浏览器运行的库:Selenium、Splash等;
1.Selenium的使用
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
1.1 声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。另外,也支持无界面浏览器 PhantomJS;
- 初始化格式
1 | |
初始化完成后我们需要调用browser对象,让它执行各个动作模拟浏览器操作;
1.2 访问页面
用 get() 方法来请求网页,参数传入链接 URL 即可
1 | |
1.3 查找节点
当我们需要完成向某个输入框输入文字的操作需要定位输入框在哪里,可以使用Selenium提供的一系列查找节点的方法
(1)单个节点
可以通过ID选择器、CSS选择器或XPath来定位页面的单个节点
- 方法
1 | |
- 举例
1 | |
(2)多个节点
- 方法
1 | |
- 举例
1 | |
1.4 操作节点
网页中的节点我们可以认为是任何可以看到的东西,比如按钮、输入框、标题等(本质上节点是HTML中的概念);
Selenium除了可以获取到节点外,还可以模拟浏览器执行一些操作节点的行为比如:输入输入框中的文字、清除输入框中的文字、点击按钮
1 | |
1.5 动作链
上面介绍的交互动作都是针对节点进行(对文本框我们输入、清楚,对按钮我们可以点击),但是有一些特殊的动作(鼠标悬停等待出现复选框再点击元素),这些动作需要使用动作链的方式来执行(本质上就是一些复杂动作函数的调用);
资料参考:selenium动作链 - pywjh - 博客园 (cnblogs.com)
1 | |
首先将要执行的事件加入ActionChains对象的队列,队列后面调用perform()方法,队列中的事件动作才会依次执行;
ActionChains方法列表
1 | |
1.6 执行JS
Selenium的API可能并未提供某些操作,此时我们可以调用Selenium的JavaScript接口execute_script(),用JavaScript的方式来实现API未提供的那些功能
1 | |
1.7 延时等待
Selenium 中,get() 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来,主要有两种等待方式:隐式等待和显式等待
1 | |
1 | |
更多显式等待条件如下
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出,传入定位元组,如 (By.ID, ‘p’) |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it frame | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现 Alert |
隐式等待和显式等待的主要区别如下:
- 显示等待只
单独针对某个元素,设置一个等待时间如5秒,每隔0.5秒检查一次是否出现。如果在5秒之前任何时候出现该元素,则继续向下,超过5秒尚未出现则抛异常。显示等待与隐式等待相对,显式等待必须在每个要等待的元乘前面进行声明。当打开一个新页面,执行第一个元素操作的时候或当某一步操作会引发页面的加载,并旦加载的内容包含了下一步需要操作的元素。综上也就是当某个元素有加载过程的时候,都需要加上显示等待; - 隐式等待是全局的
针对所有元素,设置等待时间如10秒,如果10秒内页面所有的元素都出现,则继续向下,否则抛异常。可以理解为在10秒以内,不停刷新看元素是否加载出来。隐式等待只需要声明一次,一般在打开浏览器后进行声明。声明之后对整个drvier的生命周期都有效,后面不用重复声明。隐式等待存在一个问题,那就是程序会一直等待整个页面加载完成,也就是一般情况下浏览器标签栏小图标不转,才会开始执行下一步,但有时候需要的元素其实早就加载完成了,但是因为个别JS相关加载的特别慢,所有仍得等到页面全部完成才能执行下一步; - 隐式等待和显式等待同时拥有的时候,优先权交给显式等待
最后还有一种强制等待,也就是使得整个脚本暂停一段时间,不到万不得已最好别用
1 | |
关于Selenium,还有其他许多功能如前进后退、处理Cookies、选项卡管理等操作,这里就不再赘述,感兴趣可以查阅资料;
2.Splash的使用
Splash 是一个 JavaScript 渲染服务,是一个带有 HTTP API 的轻量级浏览器,同时它对接了 Python 中的 Twisted 和 QT 库。利用它,我们同样可以实现动态渲染页面的抓取。
在学习Splashzhi前我们其实应该了解Docker相关知识点(不需要太深入,知道是什么有什么用就差不多了),推荐教程【狂神说Java】Docker最新超详细版教程通俗易懂_哔哩哔哩_bilibili(尚硅谷的可能过于详细了…不适合速通),还需要注意的一点是教程基本上都使用的是Linux系统,但实际上我已经在Windows上成功安装好Docker了,可以正常学习;
Splash通过Lua脚本来控制页面的加载过程(Lua语法参看 http://www.runoob.com/lua/lua-basic-syntax.html),其加载过程完全模拟浏览器,最终可以返回各种格式的结果,至于为什么有了Selenium还要使用Splash可以参考https://blog.csdn.net/weixin_40743639/article/details/122833394
官方教程Splash - A javascript rendering service — Splash 3.5 documentation
2.1 启动Splash服务
首先我们需要在服务-手动打开Docker的服务
接着我们需要打开Docker的应用程序
最后我们只需要在命令行输入
1 | |
成功启动Splash
打开 http://localhost:8050/ 即可看到其 Web 页面
2.2 splash对象属性
Lua脚本的基本格式大致如下
1 | |
定义的方法名为mian(这是固定不变的),Splash会默认调用main方法;
main方法中的第一个参数是splash,这个对象类似于Selenium中的WebDriver对象,可调用它的属性和方法来控制加载过程;
2.2.1 args
该属性可以获取加载时配置的参数,比如 URL,Splash 也支持使用main方法的第二个参数直接作为 args
- 如果为 GET 请求,它还可以获取 GET 请求参数;
- 如果为 POST 请求,它可以获取表单提交的数据;
1 | |
2.2.2 js_enabled
这个属性是 Splash 的 JavaScript 执行开关,可以将其配置为 true 或 false 来控制是否执行 JavaScript 代码,默认为 true(一般来说我们不用设置此属性开关,默认开启即可,否则调用 evaljs 方法执行 JavaScript 代码会出现错误);
2.2.3 resource_timeout
此属性可以设置加载的超时时间,单位是秒。如果设置为 0 或 nil(类似 Python 中的 None),代表不检测超时;将超时时间设置为 0.1 秒。如果在 0.1 秒之内没有得到响应,就会抛出异常;
1 | |
此属性适合在网页加载速度较慢的情况下设置。如果超过了某个时间无响应,则直接抛出异常并忽略即可;
2.2.4 images_enabled
此属性可以设置图片是否加载,默认情况下是加载的。禁用该属性后,可以节省网络流量并提高网页加载速度。但是需要注意的是,禁用图片加载可能会影响 JavaScript 渲染。因为禁用图片之后,它的外层 DOM 节点的高度会受影响,进而影响 DOM 节点的位置。因此,如果 JavaScript 对图片节点有操作的话,其执行就会受到影响。
另外值得注意的是,Splash 使用了缓存。如果一开始加载出来了网页图片,然后禁用了图片加载,再重新加载页面,之前加载好的图片可能还会显示出来,这时直接重启 Splash 即可。
1 | |
这样返回的页面截图就不会带有任何图片,加载速度也会快很多;
2.2.5 plugins_enabled
此属性可以控制浏览器插件(如 Flash 插件)是否开启。默认情况下,此属性是 false,表示不开启
1 | |
2.2.6 scroll_position
通过设置此属性,可以控制页面上下或左右滚动
1 | |
如果要让页面左右滚动,可以传入 x 参数
1 | |
- 举例
这是向下滚动400像素值
这是默认不滚动
2.3 splash对象方法
注意,lua中访问属性是(.),调用方法是(:)
2.3.1 go
该方法用来请求某个链接,而且它可以模拟 GET 和 POST 请求,同时支持传入请求头、表单等数据
1 | |
2.3.2 wait
此方法可以控制页面等待时间
1 | |
2.3.3 jsfunc
此方法可以直接调用 JavaScript 定义的方法,但是所调用的方法需要用双中括号包围,这相当于实现了 JavaScript 方法到 Lua 脚本的转换
1 | |
2.3.4 evaljs
此方法可以执行 JavaScript 代码(注意是代码而不仅仅只是JS函数)并返回最后一条 JavaScript 语句的返回结果
- 语法
1 | |
- 举例
1 | |
2.3.5 runjs
此方法可以执行 JavaScript 代码,它与 evaljs 方法的功能类似,但是更偏向于执行某些动作或声明某些方法
1 | |
…(更多的我就不列举了,《Python3——网络爬虫开发实战》这本书讲的很详细)
2.4 Splash API
回归主题,我们需要使用Python语句来编写爬虫,而不是之家在Splash页面上写lua脚本,所以需要使用一系列Splash提供给Python的API,Splash 给我们提供了一些 HTTP API 接口,我们只需要请求这些接口并传递相应的参数(wait、width、height等)即可获取页面渲染后的结果
2.4.1 render.html
此接口用于获取 JavaScript 渲染的页面的 HTML 代码,接口地址就是 Splash 的运行地址加此接口名称,例如:http://localhost:8050/render.html
2.4.2 render.png
此接口可以获取网页截图,返回的是PNG格式的图片二进制数据(render.jpeg和 render.png 类似,不过它返回的是 JPEG 格式的图片二进制数据)
1 | |
得到的网页截图如下,为什么呢??我们使用Splash抓取淘宝的时候也是这种情况(估计是淘宝有反爬机制)
2.4.3 render.har
接口用于获取页面加载的 HAR 数据,返回结果非常多,是一个 Json 格式的数据,里面包含了页面加载过程中的 HAR 数据
2.4.4 render.json
此接口包含了前面接口的所有功能,返回结果是 Json 格式,可以通过传入不同参数控制其返回结果。比如,传入 html=1,返回结果即会增加源代码数据;传入 png=1,返回结果即会增加页面 PNG 截图数据;传入 har=1,则会获得页面 HAR 数据
2.4.5 quote()方法
urllib.parse 模块里的 quote() 方法可以将lua脚本进行 URL 转码,实现Python与lua脚本的交互(这个功能最强大,这个可以直接转码所有的lua脚本,也就能完成所有可以使用lua脚本写的功能)
1 | |
验证码(八)
验证码实际上就属于网站的一种反爬措施:验证码最初是几个数字组合的简单的图形验证码,后来加入了英文字母和混淆曲线,有的网站还可能看到中文字符的验证码,这使得识别愈发困难,直到现在甚至出现了行为验证码(点击与文字描述完全符合的图片,全部正确验证通过);
1.图形验证码
这种验证码最早出现,现在也很常见,一般由 4 位字母或者数字组成

解决方法:使用OCR技术识别图形验证码(需要借助PIL库以及tesserocr库)
1 | |
当然,很多图像并不仅仅只是单纯的字符,还有一些干扰线条,我们使用转灰度+二值化的手段处理,至于为什么这么做可以参考灰度与二值化处理 - 知乎 (zhihu.com)
2.滑动验证码
滑动验证码属于极验验证技术中的一部分,简介可参考极验验证_百度百科 (baidu.com)大致流程主要是,点击按钮进行智能验证,如果验证不通过,则弹出滑动验证的窗口,拖动滑块拼合图像进行验证,之后三个加密参数会生成,通过表单提交到后台,后台还会进行一次验证;
极验验证第一次的智能按钮大致规则为同一个会话,一段时间内第二次点击会直接通过验证,若智能识别不通过,则会弹出滑动验证窗口;

针对极验验证的第二次验证,主要分为识别缺口位置(利用缺口边缘算法或者同时对比两张图像,找出相同位置RGB像素值超过阈值的点)和模拟滑动滑块(人类的移动轨迹一般是先加速再减速)
- 这里我们要注意一个误区,原本的图像本身是没有缺口的,只有当我们点击滑块的时候才会出现缺口;
- 寻找缺口的时候从右边开始找,因为滑块本身一般是处在左边,原图与验证图会有两处不同的地方;
- 模拟滑动滑块可以利用物理学中的加速度公式,将运动轨迹分为几个阶段避免全程匀速运动

3.点触验证码
点触验证码的交互形式有很多,但是基本原理都类似

思路:无论是使用文字识别还是图像识别都是很困难的(你稍微模拟一下机器识别文字和图像同时还附带干扰就知道难度),所以这里崔作者选择的是借助外部API(超级鹰)???
主要步骤就是将验证图片提交给平台,平台会返回识别结果在图片中的坐标位置,然后我们再解析坐标并使用Selenium模拟点击;
总结:用作者的话来说就是,如果遇到难题提我们自己无法解决可以求助在线打码平台,不要和这些问题死磕…
4.宫格验证码
这种宫格验证码,仔细分析的话其实是可以找到规律的:此验证码的四个宫格一定是有连线经过的,每一条连线上都会相应的指示箭头,连线的形状多样,包括 C 型、Z 型、X 型等,且同一种类型的连线轨迹相同,只是连线方向不同;
最暴力的方法就是把所有可能的结果的图片保存下来依次比对…只要两张图完全一致则按照匹配成功的结果使用Selenium模拟鼠标滑动轨迹完成匹配;
代理详解(九)
某些网站采取的反爬措施是令服务器检测某个IP在单位时间内的请求次数,如果超过某个阈值则直接拒绝提供服务(这称之为封IP),利用代理可以伪装爬虫IP使服务器无法识别出本机IP;
(因为网上很多免费的代理并不是很好用,且我也不想购买付费的代理,所以这一章就只会记录一些比较重要的知识点)
1.代理的设置
应该有这样一个概念:在请求库中设置代理,如果不设置则默认不使用代理;前面介绍过多种请求库如urllib、requests、Selenium,这些请求库都可以设置代理,如为urllib设置代理(其实在前面的章节中简单的介绍过)
1 | |
关于requests库以及Selenium库如何设置代理这里不再赘述,这些设置代理的基本方法在后面会用于搭建代理池;
2.代理池
无论代理是免费的还是付费的都不代表一定能够使用(此代理IP正在被使用或者是代理服务器故障),代理池的作用就是提前做出筛选,将不可用的代理删除保留可用代理;
2.1 代理池的目标
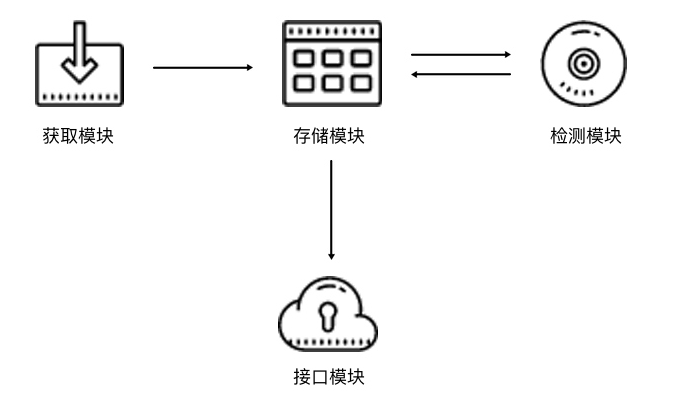
一个高效的代理池应当具备四个基本模块:
存储模块:负责存储抓取下来的代理。因为要保证代理不重复,标识代理的可用情况,还要动态实时处理每个代理,所以一种比较高效和方便的存储代理的方式就是使用 Redis 的 Sorted Set(有序集合);
获取模块:定时在各大代理网站抓取代理。代理可以是免费公开代理也可以是付费代理,
代理的形式都是 IP 加端口,此模块尽量从不同来源获取,尽量抓取高匿代理,抓取成功之后将可用代理保存到数据库中;检测模块:定时检测数据库中的代理。这里需要设置一个检测链接,最好是爬取哪个网站就检测哪个网站,这样更加有针对性,如果要做一个通用型的代理,可以设置百度等链接来检测。另外,我们需要标识每一个代理的状态,如设置分数标识,100 分代表可用,分数越少代表越不可用。检测一次,如果代理可用,我们可以将分数标识立即设置为 100 满分,也可以在原基础上加 1 分;如果代理不可用,可以将分数标识减 1 分,当分数减到一定阈值后,代理就直接从数据库移除。通过这样的标识分数,我们就可以辨别代理的可用情况,选用的时候会更有针对性;
接口模块:提供对外服务的接口。我们可以直接连接数据库来取对应的代理,但是这样就需要知道数据库的连接信息,并且要配置连接,而比较安全和方便的方式就是提供一个 Web API 接口,我们通过访问接口即可拿到可用代理。另外,由于可用代理可能有多个,那么我们可以设置一个随机返回某个可用代理的接口,这样就能保证每个可用代理都可以取到,实现负载均衡;
2.2 代理池的架构
代理池的四个模块决定了代理池的架构如下:
存储模块使用 Redis 的有序集合,用来做代理的去重和状态标识,同时它也是中心模块和基础模块,将其他模块串联起来;
获取模块定时从代理网站获取代理,将获取的代理传递给存储模块,并保存到数据库;
检测模块定时通过存储模块获取所有代理,并对代理进行检测,根据不同的检测结果对代理设置不同的标识;
接口模块通过 Web API 提供服务接口,接口通过连接数据库并以 Web 形式返回可用的代理;
至于如何使用代码实现一个代理池,这里不再赘述,详情参考Python3WebSpider (github.com)
3.ADSL拨号代理
上述介绍的代理池可以在一定程度上解决无效代理的问题,但是代理池整体效率偏低且公共代理IP很容易被封(多人同时使用某个IP),所以有人提出了另一种办法 —— 购买专用代理或手动搭建代理服务器,因为在进行爬取数据的时候需要使用的代理不止一个,所以搭建多个代理可能就需要多个服务器,这显然不现实,这里使用ADSL拨号解决;
《计算机网络》中简单介绍过ADSL(非对称数字用户环路),ADSL通过拨号的方式上网,需要输入ADSL账号和密码,使用ADSL拨号上网时每次拨号都会更换一个IP,假如我们将 ADSL服务器作为代理服务器,则只需要每隔一段时间的重新拨号一次更换一个IP即可,无需其他服务器;