绪论
实验题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求实现如下功能:
(1)可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号;
(2)可以识别并跳过源程序中的注释;
(3)可以统计源程序中的语句行数、各类单词的个数、以及字符总数,并输出统计结果;
(4)检查源程序中存在的词法错误,并报告错误所在的位置;
(5)对源程序中出现的错误进行适当的回复,使词法分析可以继续进行,对源程序进行一次扫描,即可检查并报告源程序中存在的所有词法错误;
实现要求:可以选择以下两种方案中的一种实现:
方法1:采用编程语言,手工编写词法分析程序;
方法2:基于LEX,自动生成词法分析程序;
实验报告:按照实验报告要求,对实现的词法分析器进行说明;
实验环境:源码的作者使用的是64位的Linux环境,但是实测验证发现64位的Windows11同样可以执行,为了实验的方便,我们采用直接在Windows环境下进行开发测试(虚拟机的Linux环境真的太难弄了,每次切换文件啥的真的会疯掉…)
以下是我们在开发过程中的过程图
关于参考资料,我来说说我的看法:
源码2本身存在问题,而且给出来的exe程序也有问题,我们直接pass了,然后因为网上关于这方面的介绍特别少,所以只剩下源码1可以选择;
源码1分为C++实现和LEX实现,因为LEX实现过于不同常人所以直接pass,经过测试C++实现的代码也非常简洁,只有五个,并且build生成的exe可以正确的完美的完成老师的要求,所以接下来直接看源码慢慢啃就OK了(可以结合书或者网上资料一起啃),源码1的参考链接gkkeys/alex: The Agile Lexical Analyzer for C (github.com) ;(分析方法,先把各个功能函数的功能记录下来,完整的过一遍流程之后再详细理解每一个功能函数的意义)
源码1的目录结构:
def文件夹是一些集合定义,实际编译过程中有很大作用,但都是一些枚举,可以放在最后看;
flex文件夹是LEX编译程序生成的词法分析程序,因为咱们不采用这种方式所以这个也pass掉;
graph文件夹中写Readme文档所用的图片;
test文件夹中是我们会用到的测试程序,分为没有词法错误的程序test1.c和有词法错误的程序test2.c
其余五个文件就是核心文件:
├── alex.cpp 主程序
好了,介绍完基本的结构之后我们可以开始正式开发一个基于C++的C语言词法分析器了;
一、词法分析程序的实现 1.理论知识 参考编译原理 - Tintoki_blog (gintoki-jpg.github.io)
其实这部分读不懂也没关系,只需要好好阅读代码即可;
2.数据结构设计 C语言中的Token类主要有以下几种Type类型:
Keyword: 关键词。C中的保留字;
Identifier: 标识符。变量名或函数名;
Numerical_Constant: 数值常量;
Char_Constant: 字符常量。如'a'、'b';
String_Literal: 字符串常量。如"abc";
Punctuator: 运算符;
Error: 错误类型Token;
我们的词法分析程序定义了两个类:
Lexer类:Lexer类作为词法分析器类主要负责词法分析;
Token类:Token类负责将词法分析识别的字符串整合成token形式输出;
下面是我们关于这两个类的设计,包含了相关的属性以及方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Token {private :unsigned tokenLine; unsigned tokenColumn; public :Token ();Token (string type_, unsigned line, unsigned column, string str);Token ();string getType () const ; void setType (string type_) void setToken (string token) void setError (string error) friend ostream &operator <<(ostream &os, const Token &token);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Lexer {private :unsigned countChar; unsigned countLine; unsigned countColumn; void getIdentifierKeyword (Token &token) void getNumericalConstant (Token &token) void getCharConstant (Token &token) void getStringConstant (Token &token) void getPunctuator (Token &token,char &ch,bool &res) #define TOKEN_TYPE(TYP) unsigned count_##TYP; #include "def/TOKEN_TYPE.def" #undef TOKEN_TYPE public :Lexer (); Lexer (string fileName); Lexer (); bool lexer () char getChar () char peekChar () void printResult ()
需要注意的是我们在Token类中重载了输出操作符<<,目的是为了在print结果的时候直接使用cout<<token的形式进行输出,当然不进行重载使用普通的cout分别对Token类的属性进行cout也是可以的;
程序整体的数据结构设计非常简单,就只有以上两个,难点在于接下来将会介绍的函数封装部分,涉及大量自动机的使用;
3.函数封装 3.1 功能函数 在词法分析的过程中会频繁使用到一些重复的判断逻辑,我们将这些逻辑封装为单个的函数方便调用
1 2 3 4 bool isAlpha (const char ch) return isalpha (ch) || ch == '_' ;
1 2 3 4 bool isAlphaDigit (const char ch) return isalpha (ch) || isdigit (ch) || ch == '_' ;
1 2 3 4 bool ise (const char ch) return ch == 'e' || ch == 'E' ;
1 2 3 4 bool isws (const char ch) return ch == ' ' || ch == '\t' || ch == '\v' || ch == '\f' || ch == '\n' || ch <= 0 ;
3.2 Token类方法 Token的类方法实现都非常简答,要么就是直接赋值要么就是直接return某个值,这里我们直接给出示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 string Token::getType () const return tokenType;void Token::setType (string tokentype) this ->tokenType = tokentype;void Token::setToken (string token) this ->tokenString = token;void Token::setError (string error) this ->tokenError = error;
需要注意的是前面提到的输出运算符重载,为了效果明显我们为Error的语句加了高亮;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ostream &operator <<(ostream &os, const Token &token)if (token.tokenType != "Error" )"Type: " <<token.tokenType<<endl<<"Location: " <<token.tokenLine << ':' << token.tokenColumn << endl <<"Value: " << token.tokenString << endl;else "\033[31mError: \033[32m" << token.tokenError <<endl<<"\033[1m" <<"Loacation: " << token.tokenLine << ":" << token.tokenColumn <<endl<<"\033[39m" <<"Value: " << token.tokenString << "\033[0m" <<endl;return os;
3.3 Lexer类方法 Lexer类中最主要的几个方法分别是:
void getIdentifierKeyword(Token &token); //get标识符/关键字
void getNumericalConstant(Token &token); //get数值常量
void getCharConstant(Token &token); //get字符常量
void getStringConstant(Token &token); //get字符串常量
void getPunctuator(Token &token,char &ch,bool &res); //get运算符
bool lexer(); //词法分析辅助
前面5个函数都是为了最后的lexer词法分析函数辅助,我们分别介绍;
3.3.1 getIdentifierKeyword 首先是获取标识符、关键字的函数(我们暂时不讨论如何区分标识符/关键字和字符串常量)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void Lexer::getIdentifierKeyword (Token &token) setType ("Identifier" );getChar ();while (1 )char ch = peekChar ();if (isAlpha (ch))getChar ();else break ;#define KEYWORD(TOK) \ if (stringBuffer == #TOK) \ token.setType("Keyword" ), count_Keyword++; #include "def/KEYWORD.def" #undef KEYWORD if (token.getType () == "Identifier" )setToken (stringBuffer);
这里借助def文件夹中实现定义的KEYWORD.def文件,定义了一个功能函数用于判断究竟是标识符还是关键字,分别为其设置type以及计数;
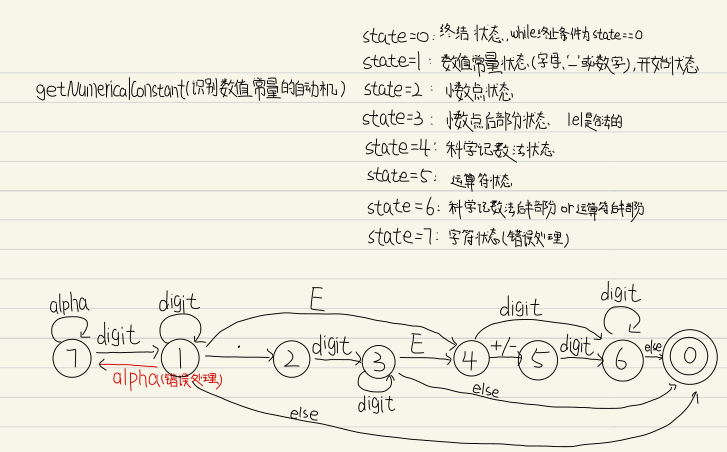
3.3.2 getNumericalConstant 下面是获取数值常量的函数,我们这里指的数值常量就是C语言编程中使用的诸如 1、1.4、1.5e等合法数值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 void Lexer::getNumericalConstant (Token &token) setType ("Numerical_Constant" );getChar ();unsigned state = 1 ;char ch;while (state!=0 ){switch (state)case 0 :break ;case 1 :peekChar ();if (isdigit (ch))1 ;getChar ();else if (ch == '.' )2 ;getChar ();else if (ise (ch))4 ;getChar ();else if (isAlpha (ch))setType ("Error" );setError ("illegal name" );7 ;getChar ();else 0 ;break ;case 2 :peekChar ();if (isdigit (ch))3 ;getChar ();else 0 ;break ;case 3 :peekChar ();if (isdigit (ch))3 ;getChar ();else if (ise (ch))4 ;getChar ();else 0 ;break ;case 4 :peekChar ();if (isdigit (ch))6 ;getChar ();else if (ch == '+' || ch == '-' )5 ;getChar ();else 0 ;break ;case 5 :peekChar ();if (isdigit (ch))6 ;getChar ();else 0 ;break ;case 6 :peekChar ();if (isdigit (ch))6 ;getChar ();else 0 ;break ;case 7 :peekChar ();if (isAlpha (ch))7 ;getChar ();else 0 ;default :break ;setToken (stringBuffer);if (token.getType () == "Numerical_Constant" )
我们给出对应的自动机(事实上代码逻辑很简单,重点就是如何构造一个合法且严谨的自动机)
事实上一开始我们并没有设置状态7,这就导致在出错的时候无法将一个完整的错误字符串提取(也就是错误处理不到位),结果就是剩下的部分会作为新的token出现在结果中,这绝对不是我们想要的;
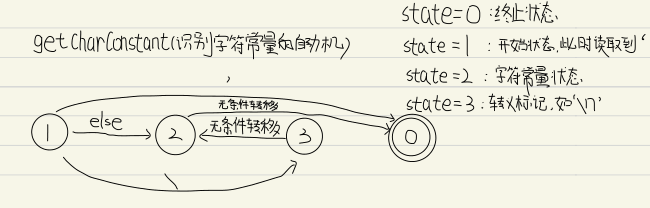
3.3.3 getCharConstant 字符常量是指单引号包含的单个字符,形如’a’、’b’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 void Lexer::getCharConstant (Token &token) setType ("Char_Constant" );getChar ();unsigned state = 1 ;char ch;while (state!=0 )switch (state)case 1 :peekChar ();if (ch == '\\' )3 ;getChar ();else if (ch == '\'' )0 ;getChar ();else 2 ;getChar ();break ;case 2 :peekChar ();if (ch == '\'' )0 ;getChar ();else 0 ;break ;case 3 :2 ;getChar ();break ;default :break ;setToken (stringBuffer);if (token.getType () == "Char_Constant" )
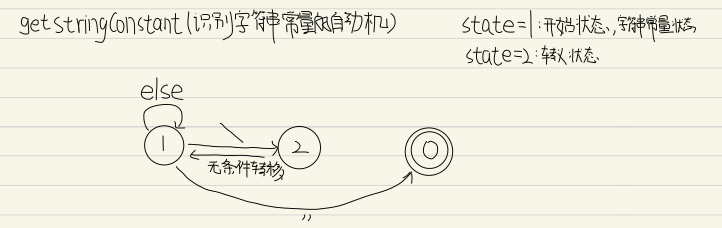
对应的自动机如下
之所以2状态无论读取到什么都要转移就是因为字符常量只允许’’之间存在至多一个char,当然’’空字符也是能够被合法接受的;
3.3.4 getStringConstant 字符串常量的定义是双引号””包含的一系列字符,形如”a”、”abc”、”3.14159”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 void Lexer::getStringConstant (Token &token) setType ("String_Literal" );getChar ();unsigned state = 1 ;char ch;while (state!=0 )switch (state)case 1 :peekChar ();if (ch == '\\' )2 ;getChar ();else if (ch == '\"' )0 ;getChar ();else if (ch == '\n' )setType ("Error" );setError ("unclosed string" );0 ;else 1 ;getChar ();break ;case 2 :1 ;getChar ();break ;default :break ;setToken (stringBuffer);if (token.getType () == "String_Literal" )
对应的自动机如下
没错,字符串常量的识别如此简单,这是因为字符串常量中除了转义字符就是普通字符,因此只要不遇到最后的结束双引号就不会进入接受状态;
3.3.5 getPunctuator 识别运算符和前面不太一样,这里不能直接就用一个自动机来识别所有的运算符(C中的运算符不少,而且会面临超前读取的问题,自动机不是最佳选择);
对于需要特殊处理的运算符如”+=”、”++”这种我们使用case分支特殊处理(本质上就是继续向后判断一个char是否为特殊运算符)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 case '.' :peekChar ();if (ch == '.' )getChar ();if ((ch = peekChar ()) == '.' )getChar ();else true ;setType ("Error" );break ;case '>' :peekChar ();if (ch == '>' )getChar ();peekChar ();if (ch == '=' )getChar ();else if (ch == '=' )getChar ();break ;case '<' :peekChar ();if (ch == '<' )getChar ();if ((ch = peekChar ()) == '=' )getChar ();else if (ch == '=' )getChar ();break ;case '+' :peekChar ();if (ch == '=' || ch == '+' )getChar ();break ;case '-' :peekChar ();if (ch == '=' || ch == '-' || ch == '>' )getChar ();break ;case '&' :peekChar ();if (ch == '=' || ch == '&' )getChar ();break ;case '|' :peekChar ();if (ch == '=' || ch == '|' )getChar ();break ;case '!' :peekChar ();if (ch == '=' )getChar ();break ;
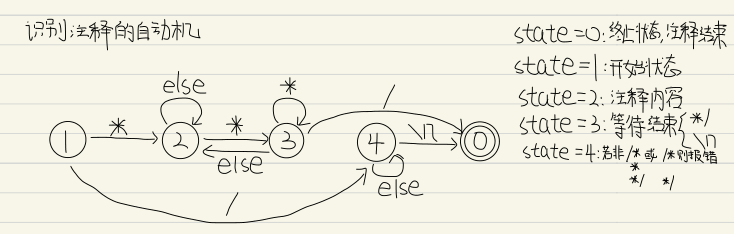
注意实验要求注释和宏定义均被忽略,这意味着”#”以及”//“、”/**/“之后的内容都将被忽略,而前者的处理方式和后两者又有不同,因为前者只会注释一行,这意味着只需要读取到”\n”就可以停止忽略了,但是对于C注释来说我们需要构造特殊的自动机来判断
我们这里考虑了C中所有可能的注释情况,不同的书写方式注释效果是不同的,相应自动机的处理方式也不同
1 2 3 4 5 6 7 8 9 10 第一种情况
3.3.6 lexer 当我们拥有词法分析的基本的功能函数之后我们就可以组装得到一个完整的词法分析程序了;
词法分析程序从源文件的第一个字符开始分析:
假如是字符则使用子程序getIdentifierKeyword处理;
假如是数字则使用子程序getNumericalConstant处理;
假如是单引号则使用子程序getCharConstant处理;
假如是双引号则使用子程序getStringConstant处理;
除上述情况外,且并没有读取到诸如换行、文件末尾等特殊情况,使用子程序getPunctuator处理;
当读取到文件末尾且输入缓冲区为空,词法分析程序停止工作并清clear输入缓冲区,退出程序;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 bool Lexer::lexer () bool res = 1 ;while (!(fileSource.eof () && stringBuffer.empty ()))char ch = peekChar ();if (isAlpha (ch))Token token ("Identifier" , countLine, countColumn, "" ) ;getIdentifierKeyword (token);else if (isdigit (ch))token ("Numerical_Constant" , countLine, countColumn, "" );getNumericalConstant (token);else if (ch == '\'' )token ("Char_Constant" , countLine, countColumn, "" );getCharConstant (token);else if (ch == '\"' )token ("String_Literal" , countLine, countColumn, "" );getStringConstant (token);else if (!isws (ch))token ("Punctuator" , countLine, countColumn, "" );getPunctuator (token,ch,res);else getChar ();clear ();return res;
3.4 main函数 main函数的逻辑非常简单,通过用户shell输入的第二个参数argv[1]获取到需要分析的filename,使用lexer词法分析程序对其进行分析,分析程序作为一个循环体,只有当文件指针指到EOF且读入缓冲区为空时才会结束此次词法分析;
当用户shell输入不符合规则(如只输入了一个参数或者参数顺序不正确),抛出异常提示并退出词法分析程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int main (int argc, char const *argv[]) if (argc == 2 )Lexer C_lexer (argv[1 ]) ; bool noerr = C_lexer.lexer (); printResult (); else "Usage: ./exe <file name>" << endl;return 0 ;
4.功能演示 我们将分别按照实验要求构造不同的源程序进行测试
(1)可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号;
(2)可以识别并跳过源程序中的注释;
(3)可以统计源程序中的语句行数、各类单词的个数、以及字符总数,并输出统计结果;
(4)检查源程序中存在的词法错误,并报告错误所在的位置;
(5)对源程序中出现的错误进行适当的回复,使词法分析可以继续进行,对源程序进行一次扫描,即可检查并报告源程序中存在的所有词法错误;
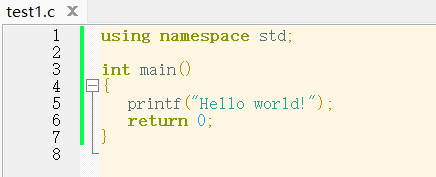
4.1 识别功能 源程序如下
这是一个非常简单的源程序,我们主要的目的就是测试在完全正确的情况下词法分析程序能否识别源程序中的每个单词符号并以token形式输出
首先是错误输入会导致程序报错并退出
接着正确输入得到输出如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 Type: Identifier
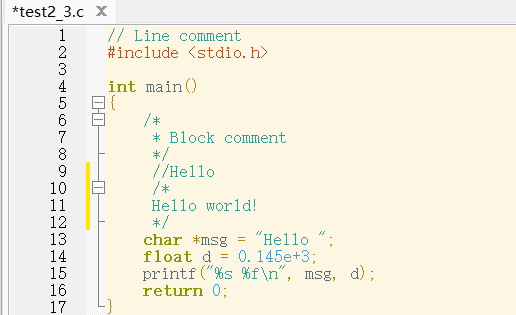
4.2 注释功能 接下类我们测试其跳过源程序中的注释以及宏定义,测试代码如下
我们直接观察可以很明显的知道词法分析程序应该输出的是形如
下面我们进行测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 Type: Keyword
可以看到,词法分析程序的确忽略了宏定义以及各种形式的注释,对实际有意义的单词进行分析;
4.3 纠错功能 我们实现的词法分析程序并没有对错误的单词进行修改等,只是简单的记录并跳过并报告其错误位置,这是一种最简单的错误处理方式;
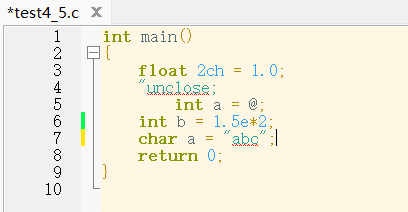
下面的源程序可以很明显的看出几个错误,字符串常量双引号不匹配、int型变量a赋值错误、C变量名不能以数字开头
我们使用词法分析程序看是否存在这样的错误
运行结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 Type: Keyword
可以看到程序非常完美的查出了所有错误并跳过这些错误(报告这些错误的位置和内容),完成了整体源文件的分析;
5.不足 其实很明显我们可以看到4.3中的不足,char a="abc"这个语法是错误的,但是我们额程序并没有检测出来,原因其实很简单,因为我们实现的仅仅只是一个词法分析程序,并没有联系上下文的能力,也就意味着词法分析程序仅仅只能检测词法错误并不能检测语法错误,要实现对语法错误的检测就需要借助之后我们设计的语法分析程序;