中级项目_推荐系统
2022/11/8 8:16 昨天大概好好想了想,发现最近半年在学校基本没做什么项目,然而下学期就要准备考研了,就更没可能做项目了,所以这里打算开始着手跟着尚硅谷的几个教程做几个项目出来,本来打算的是跟着github上面找到的项目做的,但是发现实际效果(项目整体的可视化程度和完整程度,就是说甚至都展示不出来)和开发时间(因为有些甚至没有Readme文档,所以看源码需要很多时间,当然对自身而言是一个提升,但因为确实现在我们没什么时间了,所以得更换方案了);然后昨天在寻找项目的时候发现基本上都是一些自己没有接触过的东西,然后就产生了畏惧心理,这里我说一下,对于这些项目中出现的陌生环境以及陌生的框架、技术等,都不要畏惧,因为在基础技能扎实(甚至不需要扎实,只要你学过复习几个小时就能回忆起来)的情况下这些新的概念不过都是一些类似的,而且开发全栈或多种技术框架混合的项目带能算得上一个真正的项目;
2022/11/8 10:43 这个项目涉及的代码和使用的框架基本上都是我没有接触过的,暂且打算边学边做,不会再专门花时间系统性的学习(这对我来说也是一次全新的尝试,以前一直都是系统性学习之后做一些简单的项目或者根本没有实战,导致一段时间之后就遗忘了之前学习的知识点);
2023/2/8 9:15 时隔几个月,我又回来准备继续完成这部分的内容了,关于这几个月我在做什么,首先恶补了JAVA相关的技术栈,也是我们在这个项目中会使用到的一些,然后就是准备期末复习…寒假在家接近摆了一个月,只能说任何人无论多么自律真的都会有一段时间低迷,可以偶尔自己放纵但是千万不要习惯于放纵,接着寒假就开始准备考研的事情,把高数的基本章节大概看了看然后这边准备第二轮的高数复习,之所以还是想把这个项目捡起来做还是觉着自己额外学了那么多课外知识不整出个东西来不是很甘心,所以趁最近事情不是很多试一试;我额外补充学习的知识点肯定是不够用的,但是现在已经不适合我慢悠悠的系统性学习之后再跟着做了,边做边理解最后做一个完整的回顾总结;
项目参考:尚硅谷机器学习和推荐系统项目实战教程(初学者零基础快速入门)_哔哩哔哩_bilibili
一、推荐系统算法
1.基于人口统计学的推荐
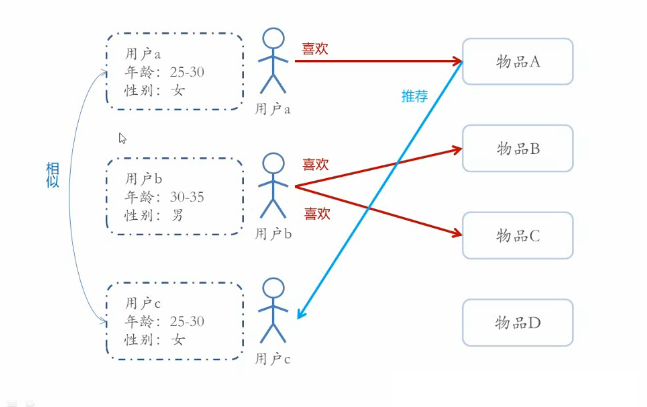
基于人口统计学的推荐机制(Demographic-based Recommendation)是一种最易于实现的推荐方法,它只是简单的根据系统用户的基本信息发现用户的相关程度,然后将相似用户喜爱的其他物品推荐给当前用户
对于没有明确含义的用户信息(比如登录时间、地域等上下文信息),可以通过聚类等手段,给用户打上分类标签;
对于特定标签的用户,可以根据预设的规则(知识)或者模型,推荐出对应的物品;
1.1 用户画像
用户信息标签化的过程一般又称为用户画像(User Profiling)
用户画像(User Profile)就是企业通过收集与分析消费者社会属性、生活习惯、消费行为等主要信息的数据之后,完美地抽象出一个用户的商业全貌作是企业应用大数据技术的基本方式;
用户画像为企业提供了足够的信息基础,能够帮助企业快速找到精准用户群体以及用户需求等更为广泛的反馈信息;
作为大数据的根基,它完美地抽象出一个用户的信息全貌,为进一步精准、快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础;
2.基于内容的推荐
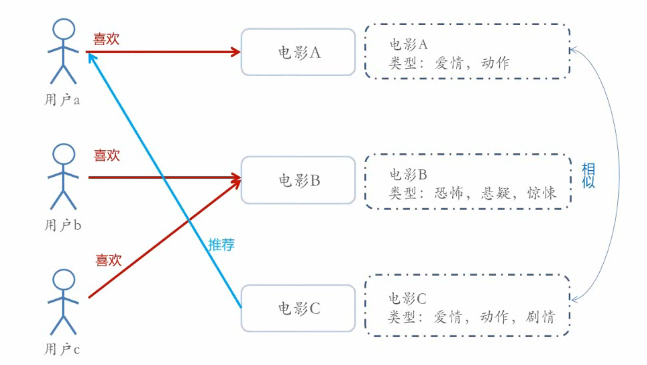
Content-based Recommendations(CB)根据推荐物品或内容的元数据,发现物品的相关性,再基于用户过去的喜好记录,为用户推荐相似的物品;
- 通过抽取物品内在或者外在的特征值,实现相似度计算。比如一个电影,有导演、演员、用户标签UGC、用户评论、时长、风格等等,都可以算是特征;通俗的来讲将对物品的特征提取称为“打标签”(有些网站还请专业的人员对物品进行基因编码/打标签(PGC)),主要有以下几种形式
- 对于物品的特征提取 —— 打标签
- 专家标签(PGC)
- 用户自定义标签(UGC)
- 降维分析数据,提取隐语义标签(LFM)
- 对于文本信息的特征提取 —— 关键词
- 分词、语义处理和情感分析(NLP)
- 潜在语义分析(LSA)
- 对于物品的特征提取 —— 打标签
- 将用户(user)个人信息的特征(基于喜好记录或是预设兴趣标签),和物品(item)的特征相匹配,就能得到用户对物品感兴趣的程度,在一些电影、音乐、图书的社交网站有很成功的应用;
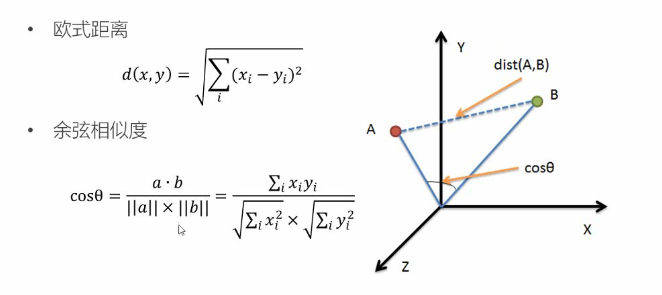
2.1 相似度计算
相似度的评判,可以用距离表示,一般更常用的是”余弦相似度”
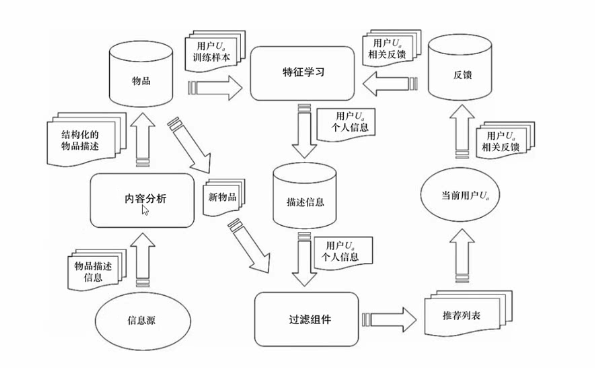
2.2 高层次结构
下图是基于内容推荐系统的高层次结构,参考下图可以对整个推荐系统的运行、架构有一定理解
2.3 特征工程
最好的掌握特征工程的方法就是刷两道题,这里推荐Kaggle上的House Prices - Advanced Regression Techniques | Kaggle
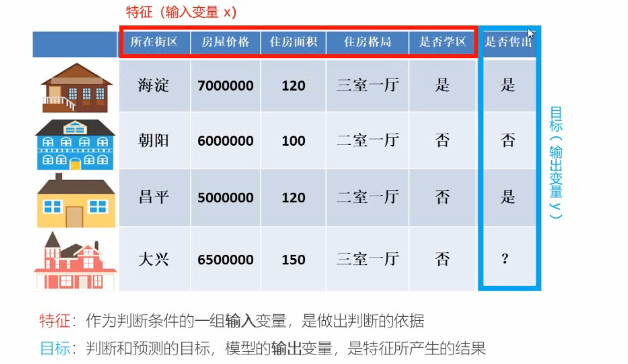
- 特征(feature):数据中抽取出来的对结果预测有用的信息,特征的个数就是数据的观测维度;
- 特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程,特征工程一般包括特征清洗(采样、清洗异常样本),特征处理和特征选择;
2.3.1 特征处理
特征按照不同的数据类型分类,有不同的特征处理方法
(1)数值型
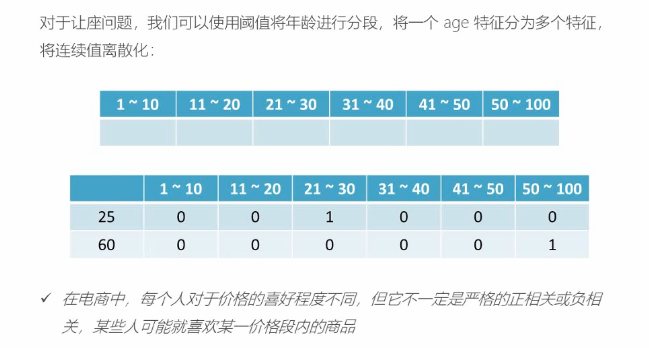
归一化处理

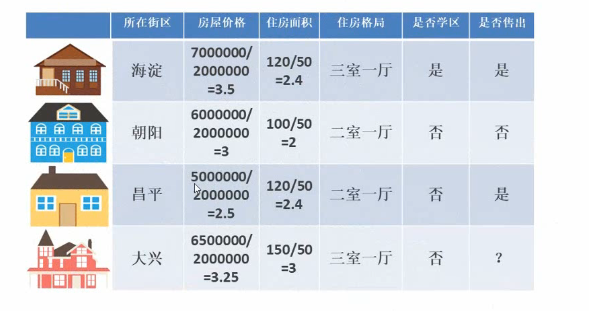
离散化处理


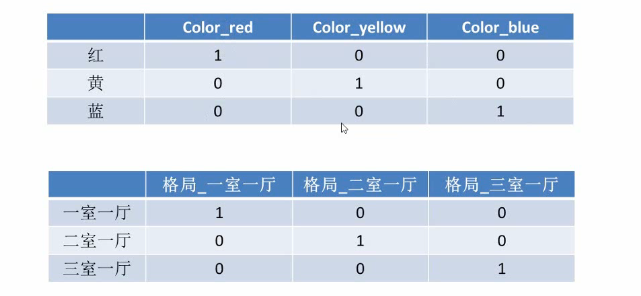
(2)类别型

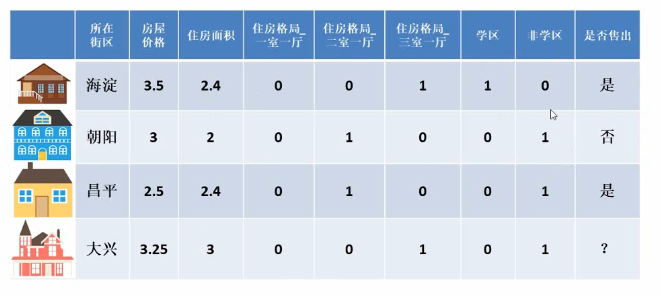
(3)时间型

(4)统计型

2.4 反馈数据
在特征工程之后得到的数据就可以用于模型训练了训练完成之后,我们还需要收集一些反馈数据对整个模型做评估和优化,下面是推荐系统常见的反馈信息
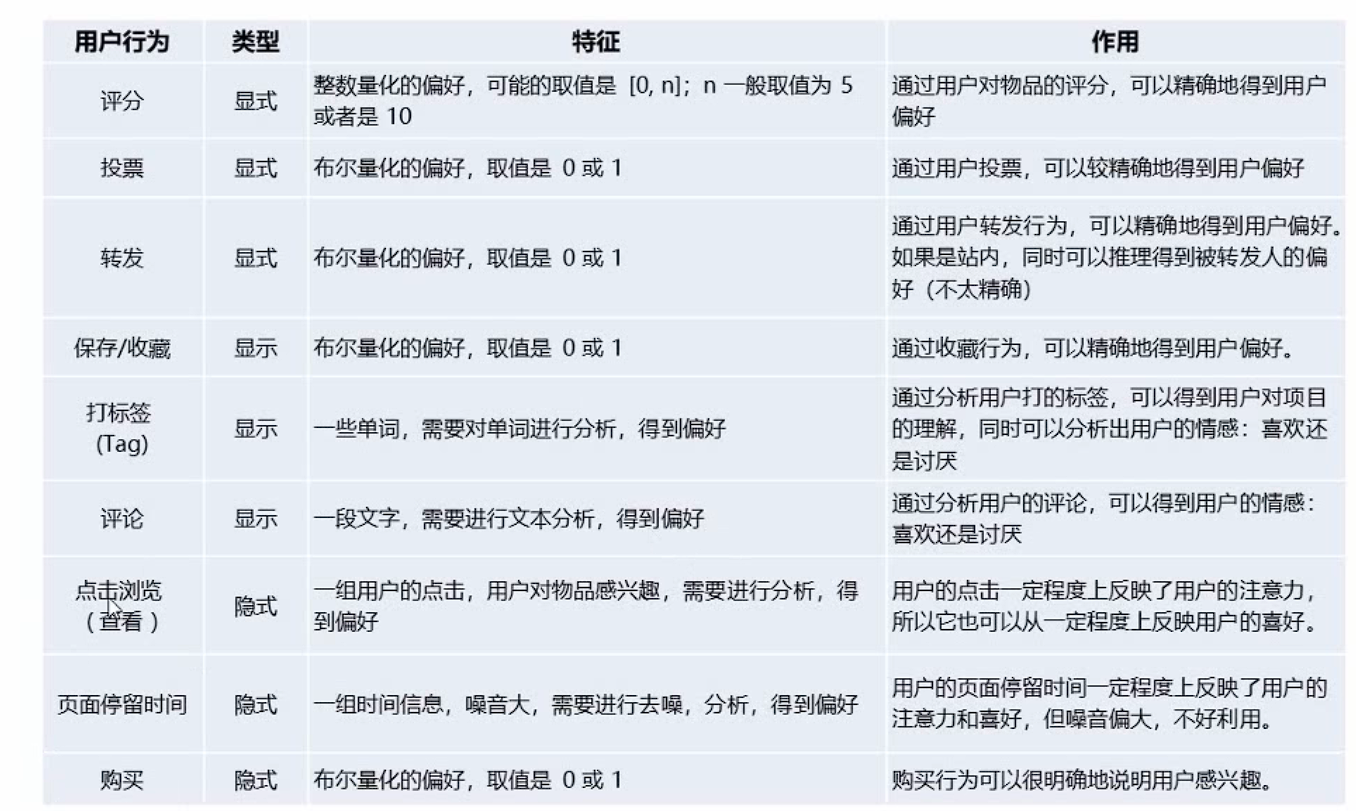
2.5 基于UGC的推荐
用户用标签来描述对物品的看法,所以用户生成标签(UGC)是联系用户和物品的纽带,也是反应用户兴趣的重要数据源;
一个用户标签行为的数据集一般由一个三元组(用户,物品,标签)的集合表示,其中一条记录(u,i,b)表示用户u给物品i打上了标签b

缺点:这种方法倾向于给热门标签(谁都会给的标签,如“大片、”搞笑”等)、热门物品(打标签人数最多)比较大的权重,如果一个热门物品同时对应着热门标签,那它就会“霸榜”,推荐的个性化、新颖度就会降低;
解决方法是将热门标签和热门物品的权重降低一定程度;
2.5.1 TF-IDF

TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级
词频

逆向文件频率
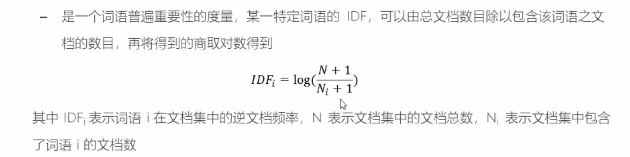
基于TF-IDF对UGC的改进

上面的公式如果在分子乘上log(N+1)^2^,分母上乘以n*,i^2^就是完整的TF-IDF公式,但是因为N是不变项,没有必要增大计算量所以可以忽略;
这种化简的思想非常重要,可以极大的简化计算和算法设计;
3.基于协同过滤的推荐
基于内容(Content based,CB)主要利用的是用户评价过的物品的内容特征,而CF方法还可以利用其他用户评分过的物品内容;
简单来说CF就是利用用户的行为数据、用户和物品的关联;
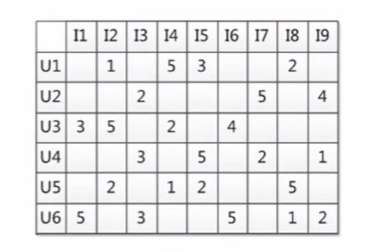

CF的问题在于没有办法解决冷启动的问题,也就是一开始根本没有历史数据和行为数据,就没有办法进行CF的分析;
协同过滤(Collaborative Filtering,CF)可以分为基于近邻的协同过滤(User-CF&Item-CF)和基于模型的协同过滤(SVD&LSA&SVM);
3.1 基于近邻的推荐
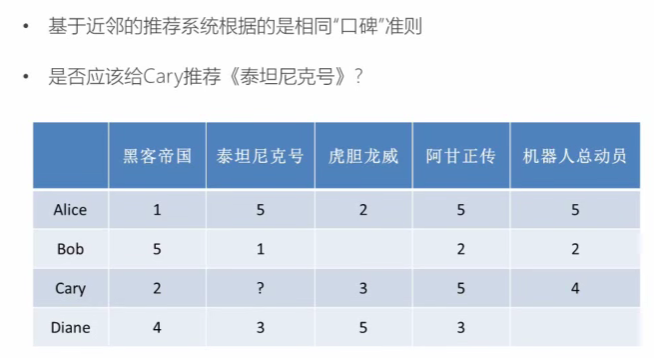
基于用户的推荐:用户Alice和Cary的行为相对接近(对不同的电影评分相近)
基于物品的推荐:泰坦尼克号和阿甘正传的列评分类似(用户的评分相当于该电影的一组评分)
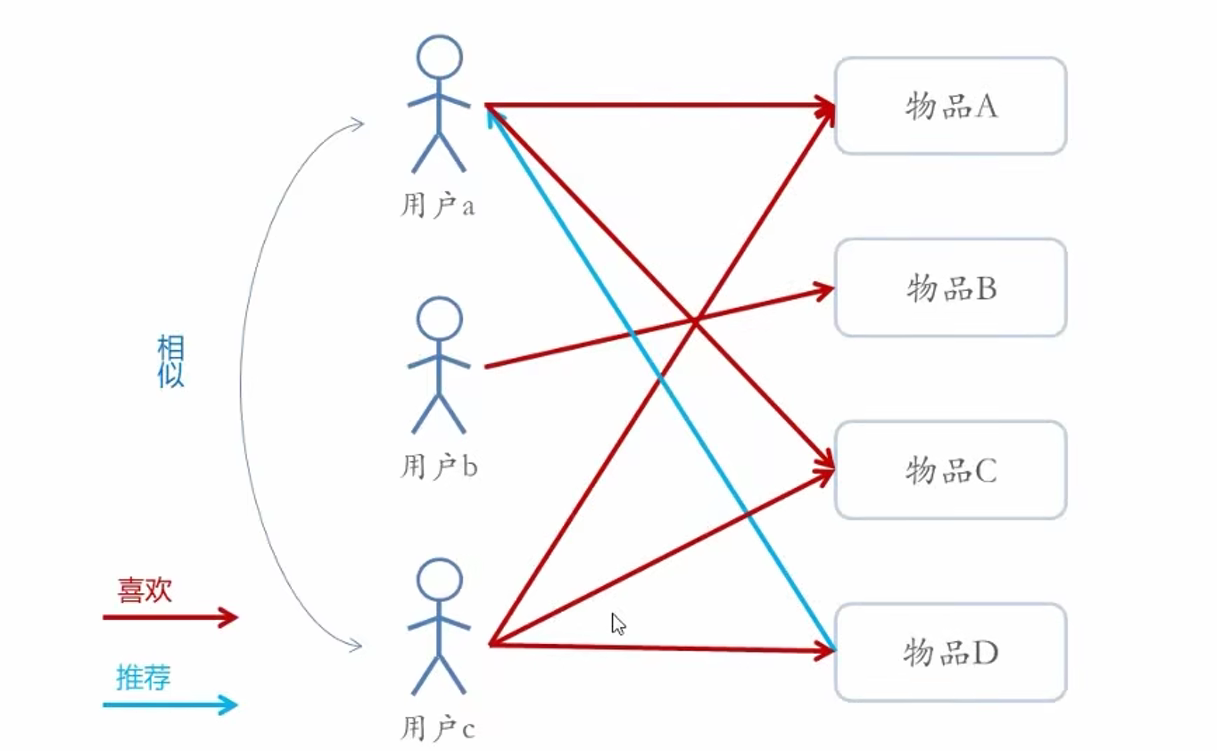
基于用户的协同过滤

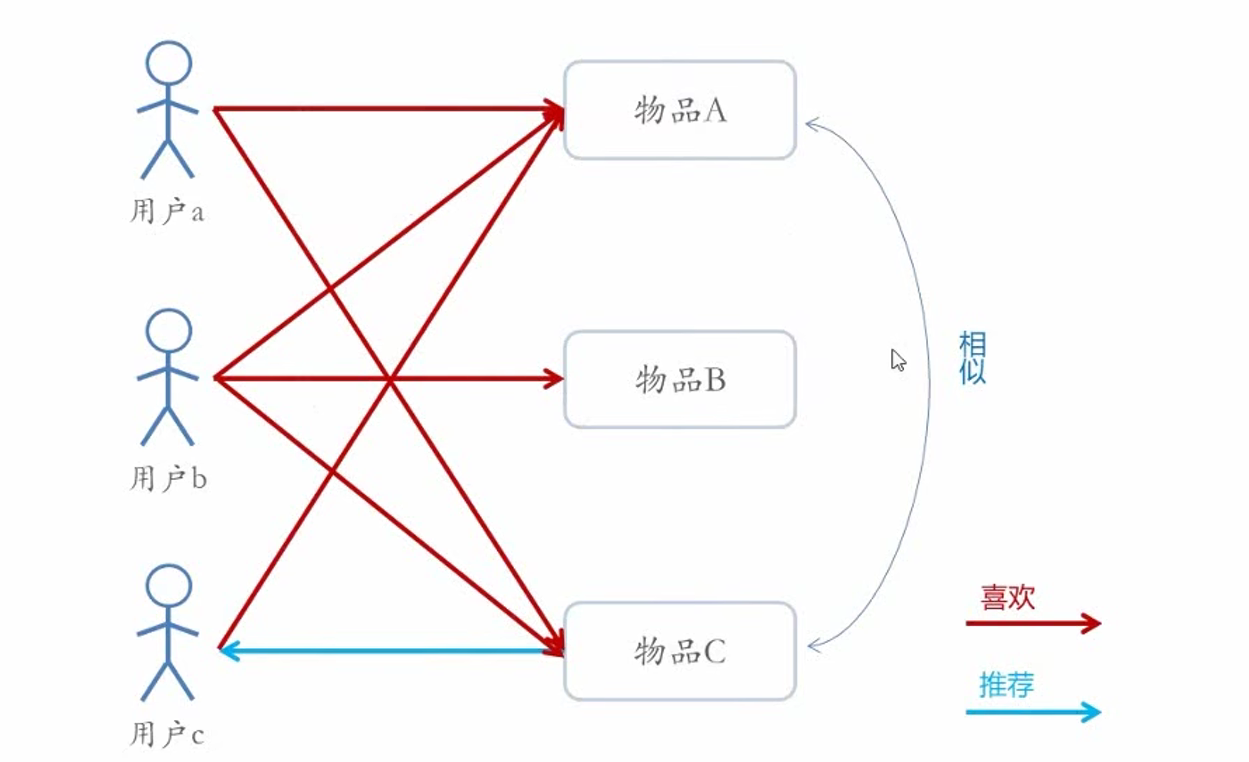
基于物品的协同过滤

User-CF和Item-CF的抉择
推荐策略的选择和具体的应用场景有很大的关系

小结

3.2 基于模型的推荐
基于模型的协同过滤推荐,就是基于样本的用户偏好信息,训练一个推荐模型。然后根据实时的用户喜好的信息进行预测新物品的得分,计算推荐;
基本思想(基于的数据仍然是行为数据):
用户具有一定的特征,决定着他的偏好选择;
物品具有一定的特征,影响着用户需是否选择它;
用户之所以选择某一个商品,是因为用户特征与物品特征相互匹配;

基于模型和基于近邻的区别

3.2.1 隐语义模型
训练模型时,可以基于标签内容来提取物品特征,也可以让模型去发掘物品的潜在特征;这样的模型被称为隐语义模型(Latent Factor Model,LFM)

隐语义模型如何揭露这些隐藏的特征?

隐语义模型的实例

(1)矩阵因子分解

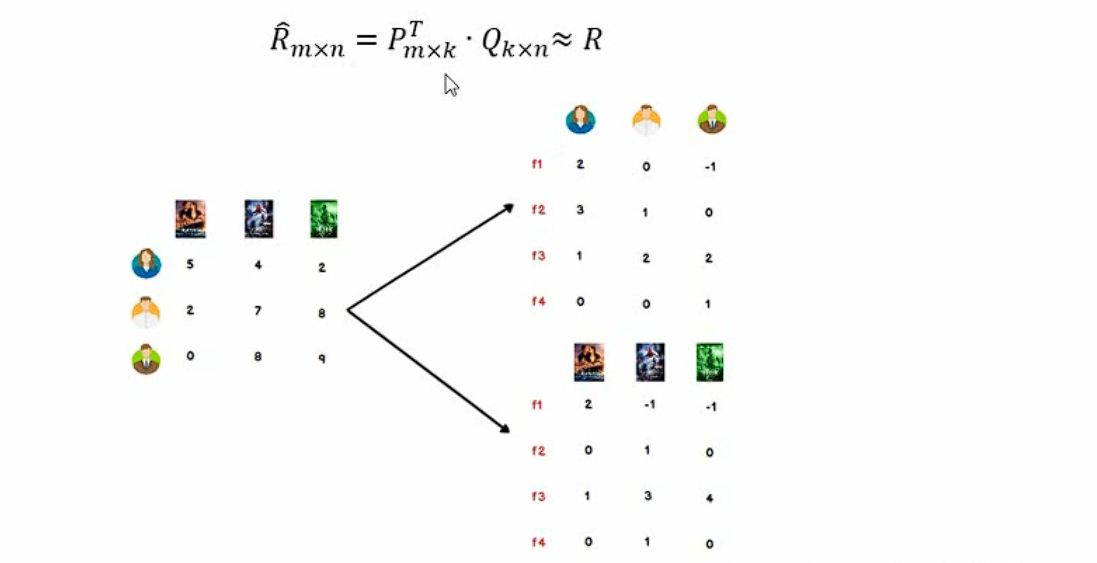
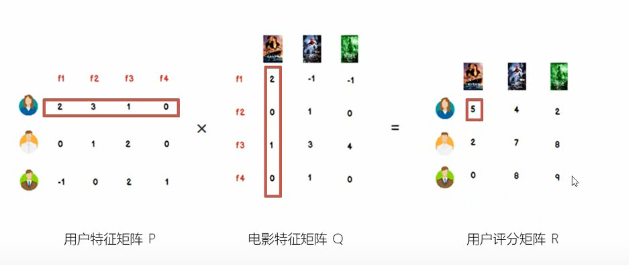
LMF的再理解

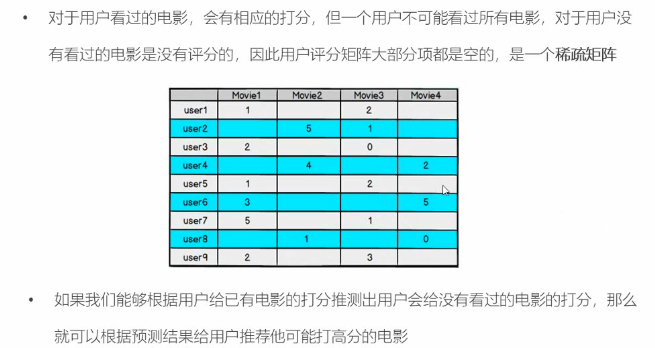
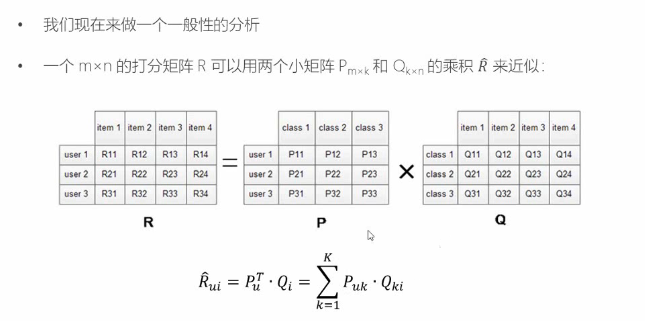
至于怎么样拆分为两个矩阵的乘积,这就涉及到一定的领域知识和“玄学”,当然验证方法是可以找到的,就是对比新的矩阵和原矩阵对应位置的数值是否基本一致;
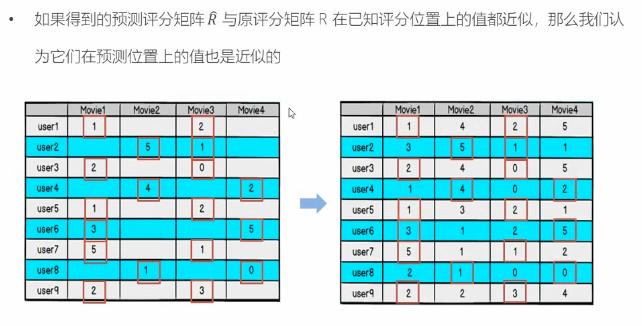
(2)损失函数

ALS算法





梯度下降算法
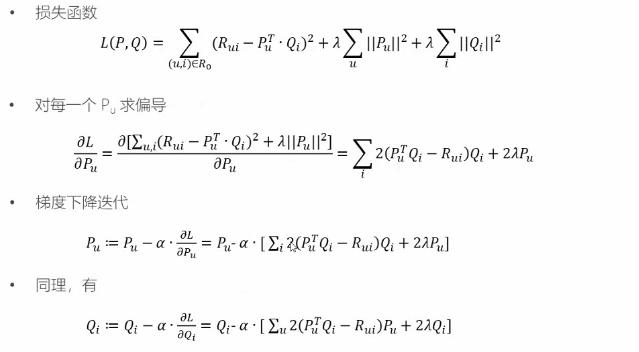
二、电影推荐系统
1.项目系统设计
项目以推荐系统建设领域知名的经过修改过的 MovieLens 数据集作为依托,以某科技公司电影网站真实业务数据架构为基础,构建了符合教学体系的一体化的电影推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。
1.1 项目框架
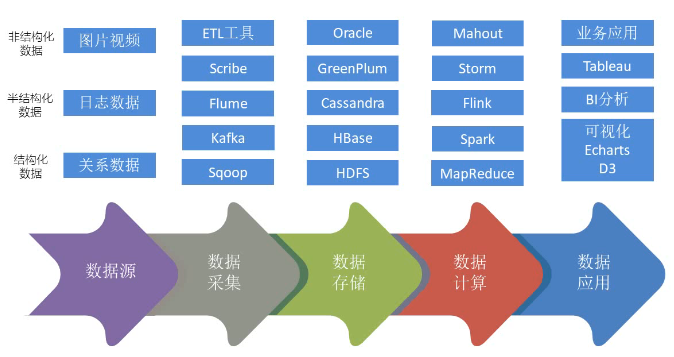
1.1.1 大数据处理流程
对于一个数据来讲是存在生命周期的
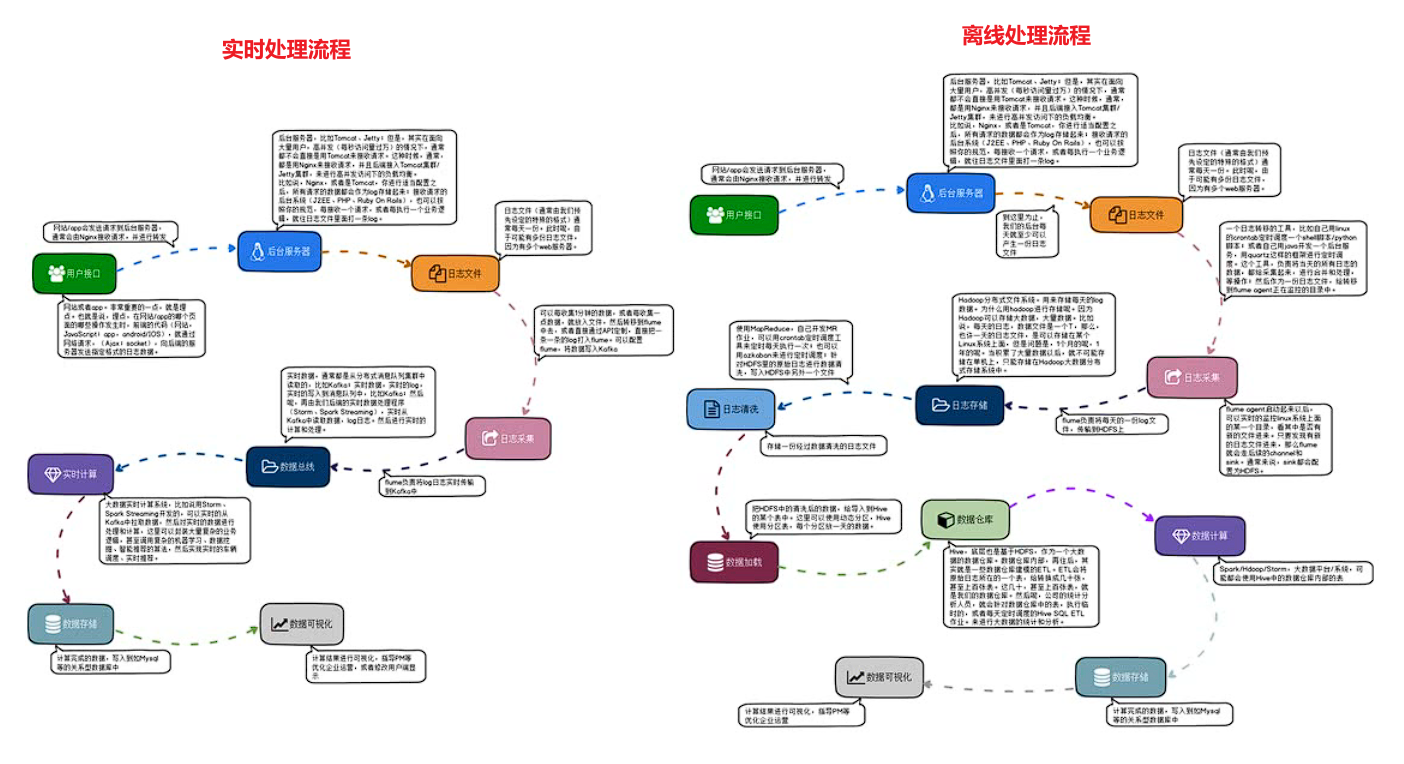
下图分别是大数据的实时处理流程和离线处理流程
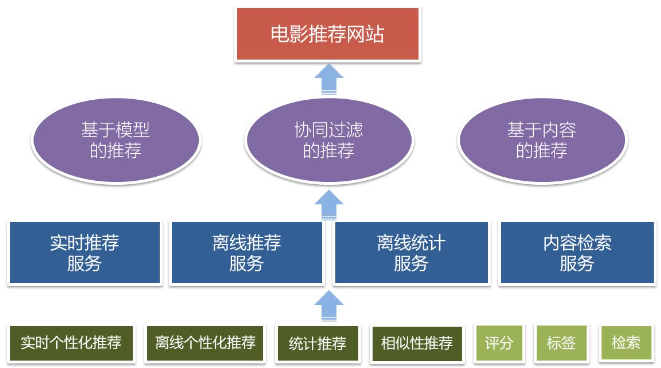
1.1.2 系统模块设计
1.1.3 项目系统架构
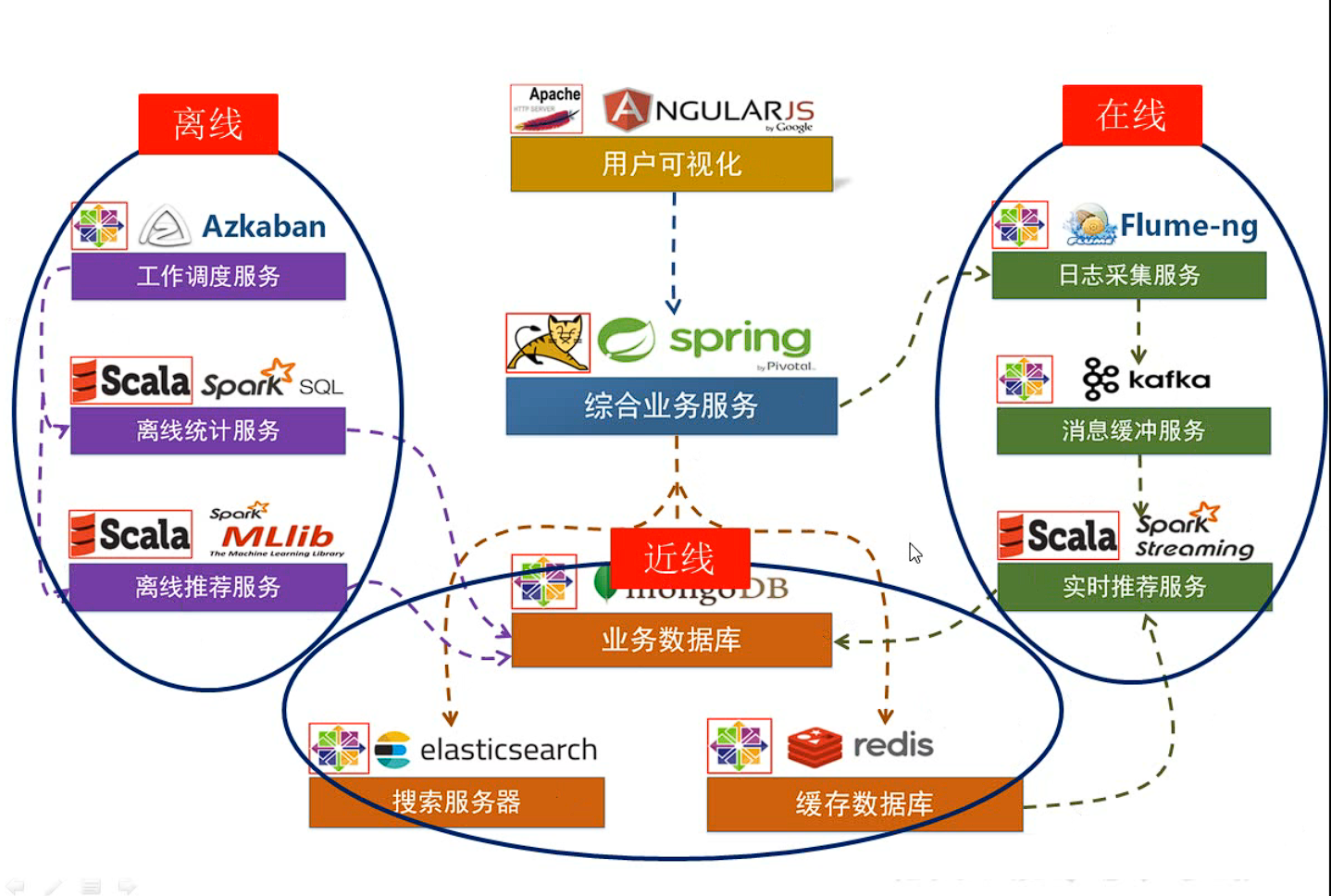
- 用户可视化:主要负责实现和用户的交互以及业务数据的展示,主体采用 AngularJS2 进行实现,部署在 Apache 服务上;
- 综合业务服务:主要实现 JavaEE 层面整体的业务逻辑,通过 Spring 进行构建,对接业务需求,部署在 Tomcat 上;
- 数据存储部分
- 业务数据库:项目采用广泛应用的文档数据库 MongDB 作为主数据库,主要负责平台业务逻辑数据的存储;
- 搜索服务器:项目使用 ElasticSearch 作为模糊检索服务器,通过利用 ES 强大的匹配查询能力实现基于内容的推荐服务;
- 缓存数据库:项目采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求;
- 离线推荐部分
- 离线统计服务:批处理统计性业务采用 Spark Core + Spark SQL 进行实现,实现对指标类数据的统计任务;
- 离线推荐服务:离线推荐业务采用 Spark Core + Spark MLlib 进行实现,采用ALS 算法进行实现;
- 工作调度服务:对于离线推荐部分需要以一定的时间频率对算法进行调度,采用 Azkaban 进行任务的调度;
- 实时推荐部分
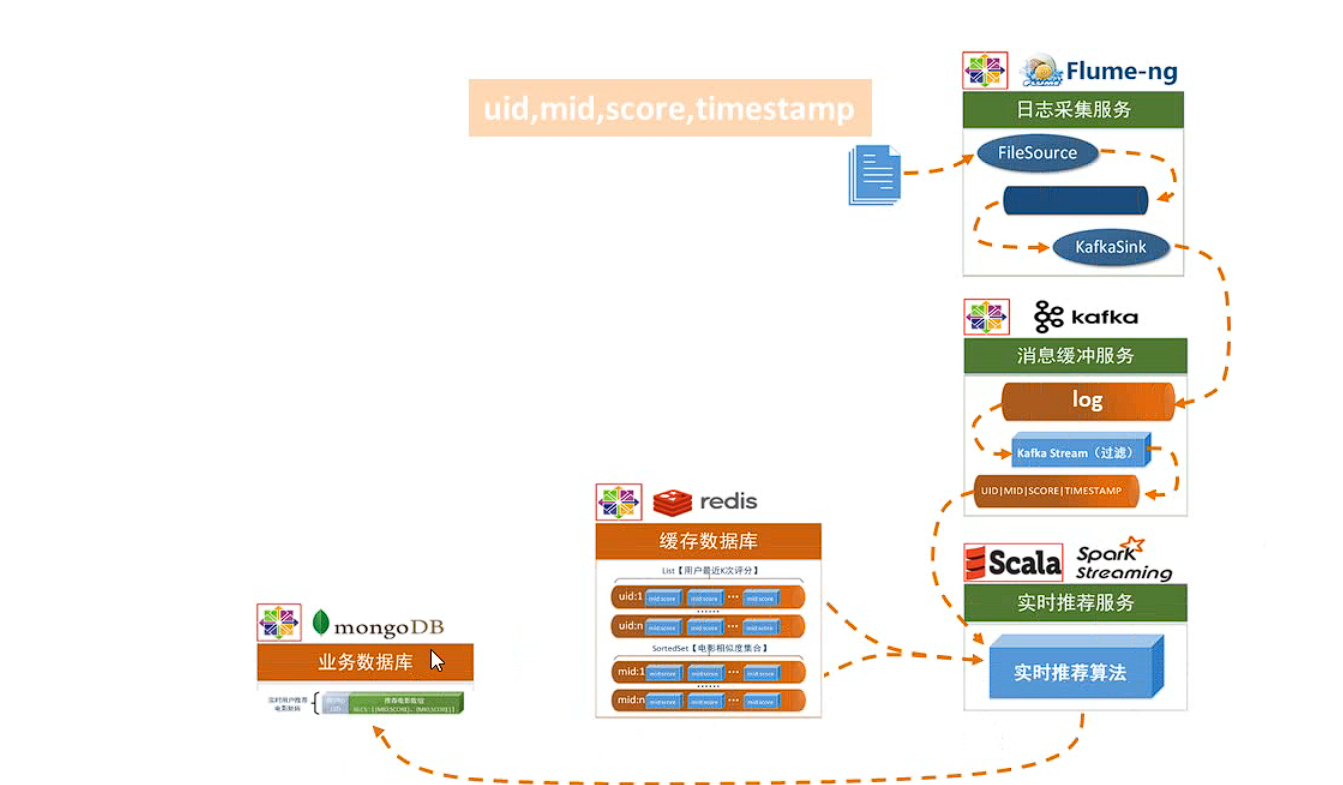
- 日志采集服务:通过利用 Flume-ng 对业务平台中用户对于电影的一次评分行为进行采集,实时发送到 Kafka 集群;
- 消息缓冲服务:项目采用 Kafka 作为流式数据的缓存组件,接受来自 Flume 的数据采集请求,并将数据推送到项目的实时推荐系统部分;
- 实时推荐服务: :项目采用 Spark Streaming 作为实时推荐系统,通过接收 Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到 MongoDB 数据库;
对上述项目系统架构具体化
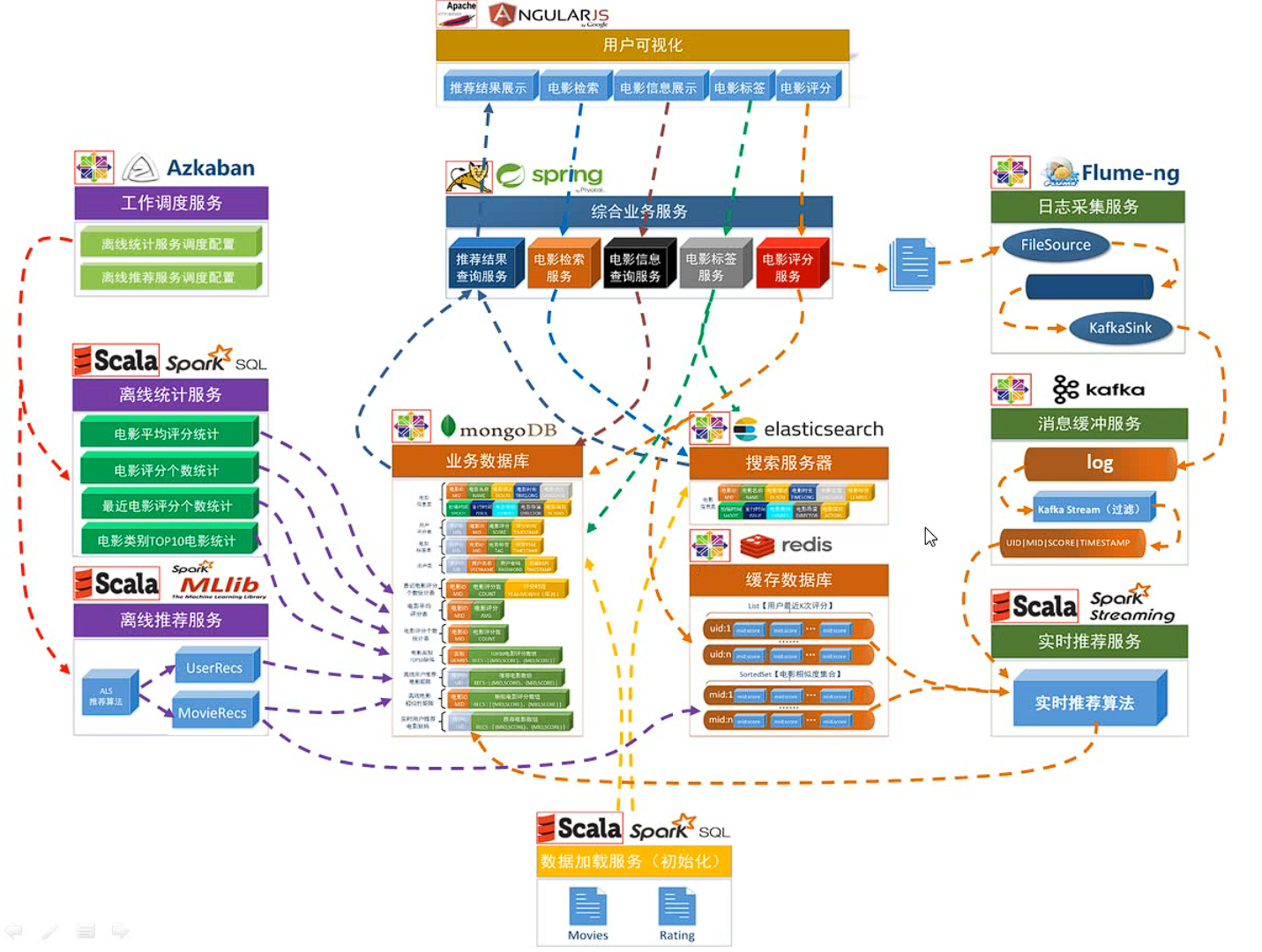
1.1.4 项目数据流图
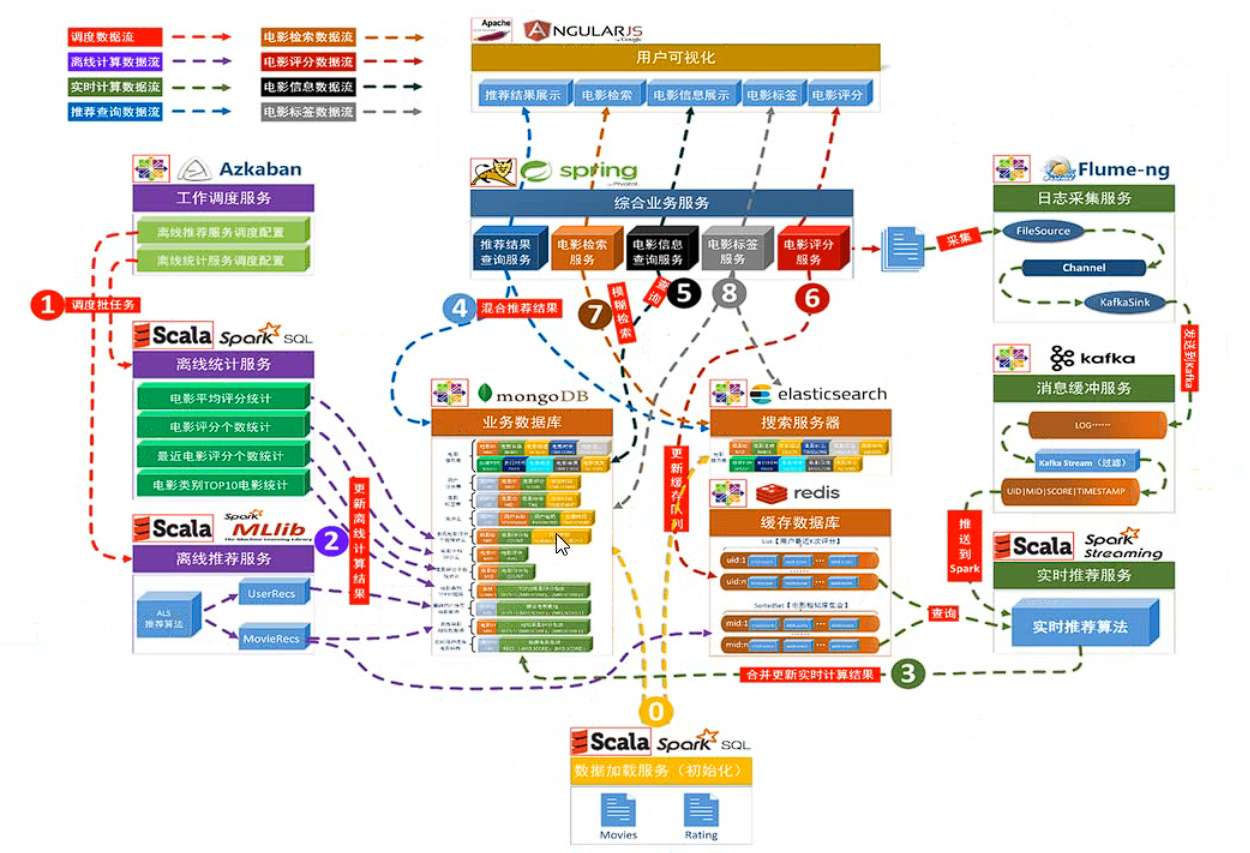
系统初始化部分
0.通过 Spark SQL 将系统初始化数据加载到 MongoDB 和 ElasticSearch 中;
离线推荐部分
1.通过 Azkaban 实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行;
2.离线统计服务从 MongoDB 中加载数据,将【电影平均评分统计】、【电影评分个数统计】、【最近电影评分个数统计】三个统计算法进行运行实现,并将计算结果回写到 MongoDB 中;离线推荐服务从 MongoDB 中加载数据,通过 ALS 算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到 MongoDB 中;
实时推荐部分
3.Flume 从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka 中;Kafka 在收到这些日志之后,通过 kafkaStream 程序对获取的日志信息进行过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一个 Kafka 队列;Spark Streaming 监听 Kafka 队列,实时获取 Kafka 过滤出来的用户评分数据流,融合存储在 Redis 中的用户最近评分队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结构和 MongDB 数据库中的推荐结果进行合并;
业务系统部分
4.推荐结果展示部分,从 MongoDB、ElasticSearch 中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综合给出相对应的数据;
5.电影信息查询服务通过对接 MongoDB 实现对电影信息的查询操作;
6.电影评分部分,获取用户通过 UI 给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到 Redis 群中,另一方面,通过预设的日志框架输出到 Tomcat 中的日志中;
7.项目通过 ElasticSearch 实现对电影的模糊检索;
8.电影标签部分,项目提供用户对电影打标签服务;
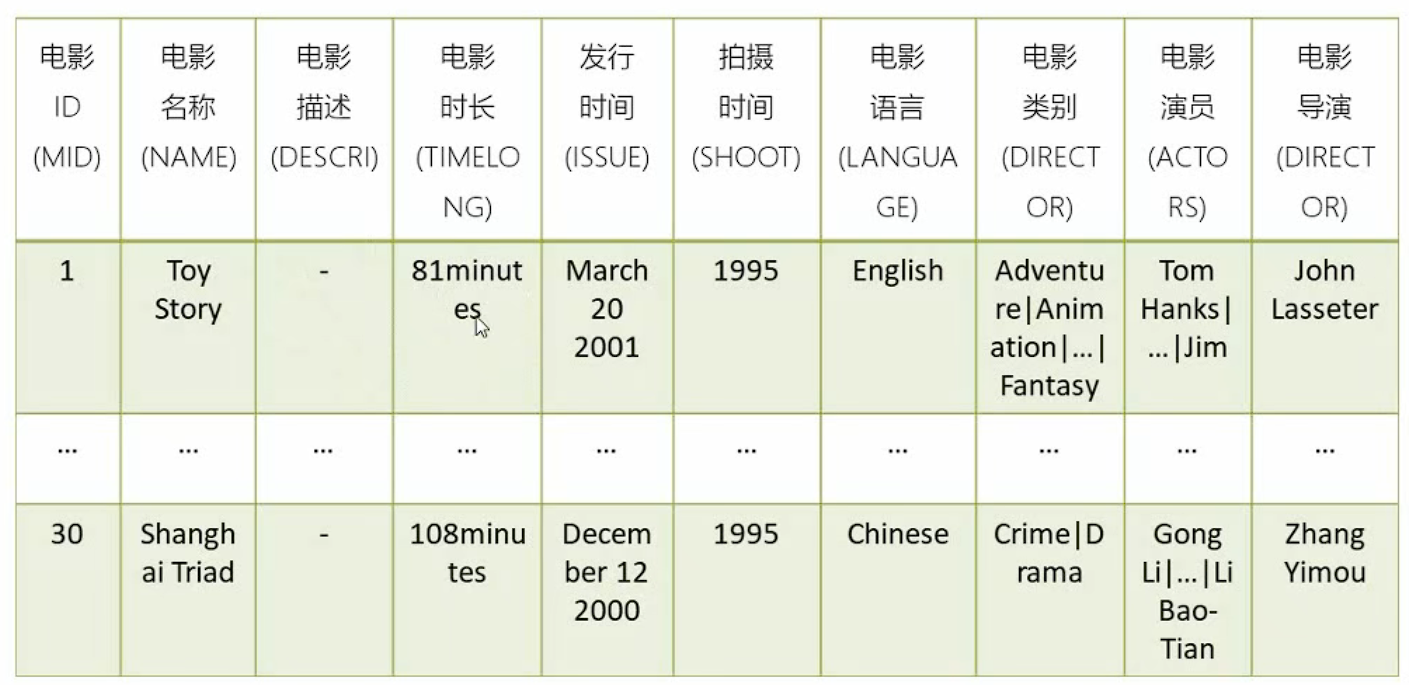
1.2 数据源解析
初始数据源是如下三个csv文件,分别是电影信息、用户评分信息和电影标签信息(数据源被dataloder加载到数据库中)

1.2.1 电影信息
1.2.2 用户评分信息
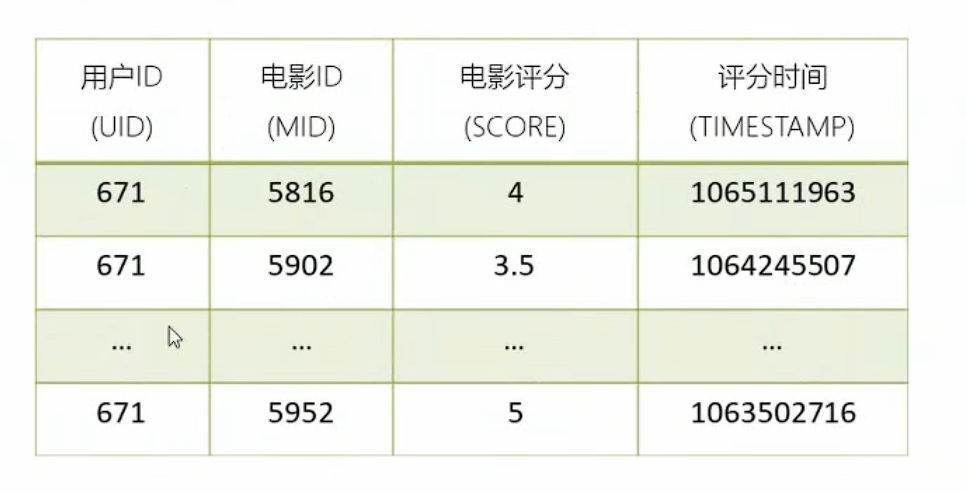
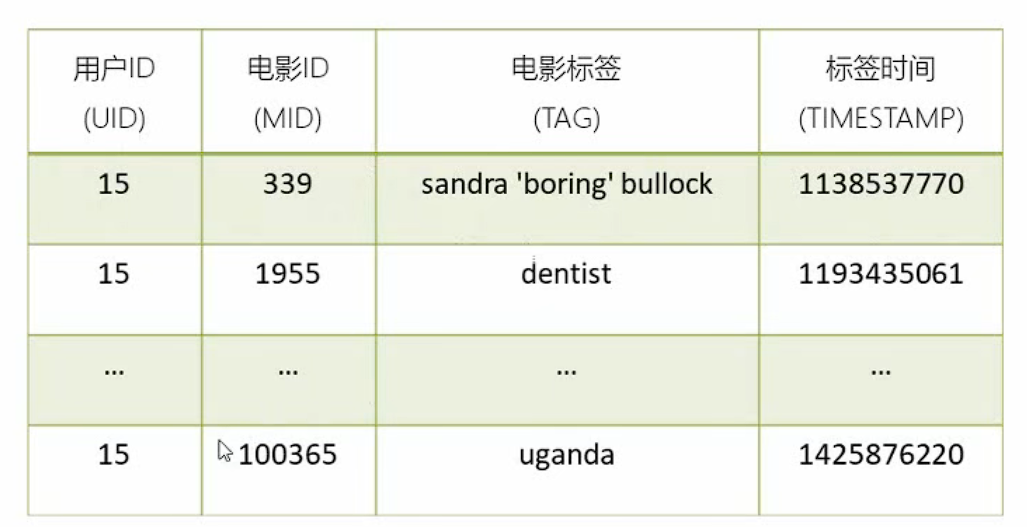
1.2.3 电影标签信息
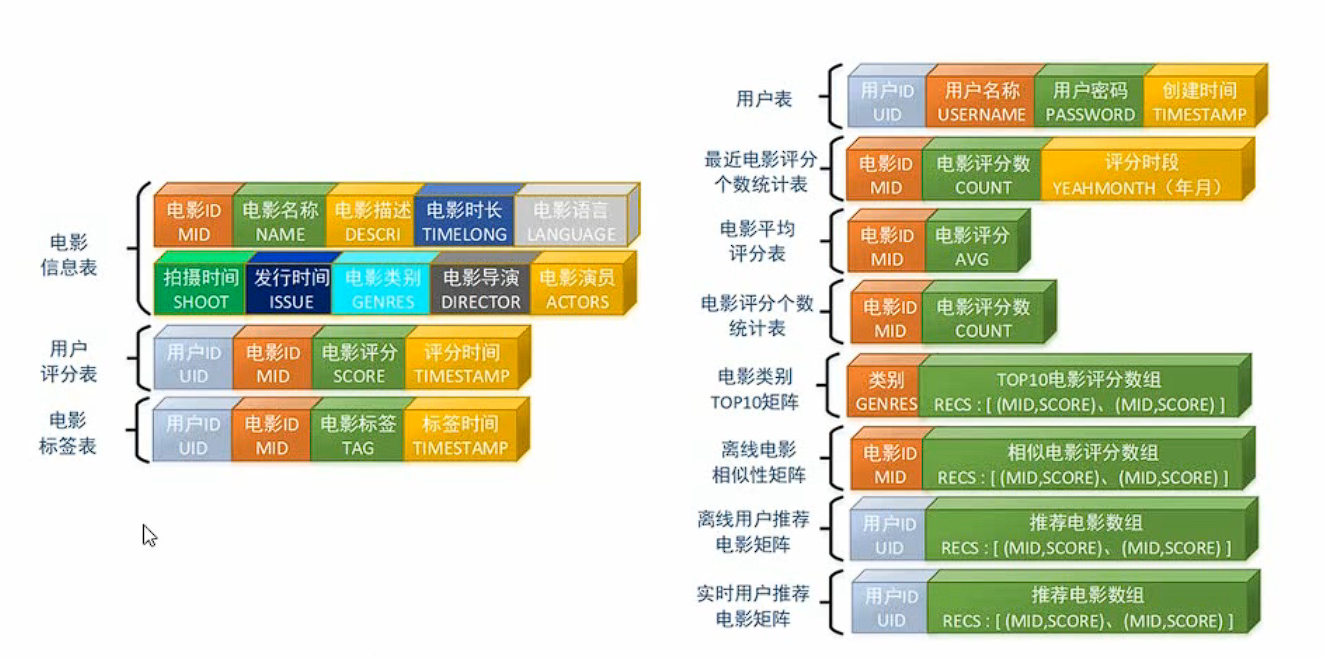
1.2.4 主要数据模型
左边三个就是初始源数据,右边就是整个项目会涉及的其他数据模型
1.3 项目模块化
1.3.1 统计推荐模块
本模块对应整体架构中的离线统计服务,主要分为四个部分:
- 历史热门电影统计;
- 近期热门电影统计;
- 电影平均评分统计;
- 各类别Top10优质电影统计;
主要想法是首先从mongoDB中将原始数据读出,接着离线统计服务做对应的离线统计计算(使用SQL进行统计,对于不同的类型的服务使用的SQL是不同的),将得到的内容写回mongoDB中
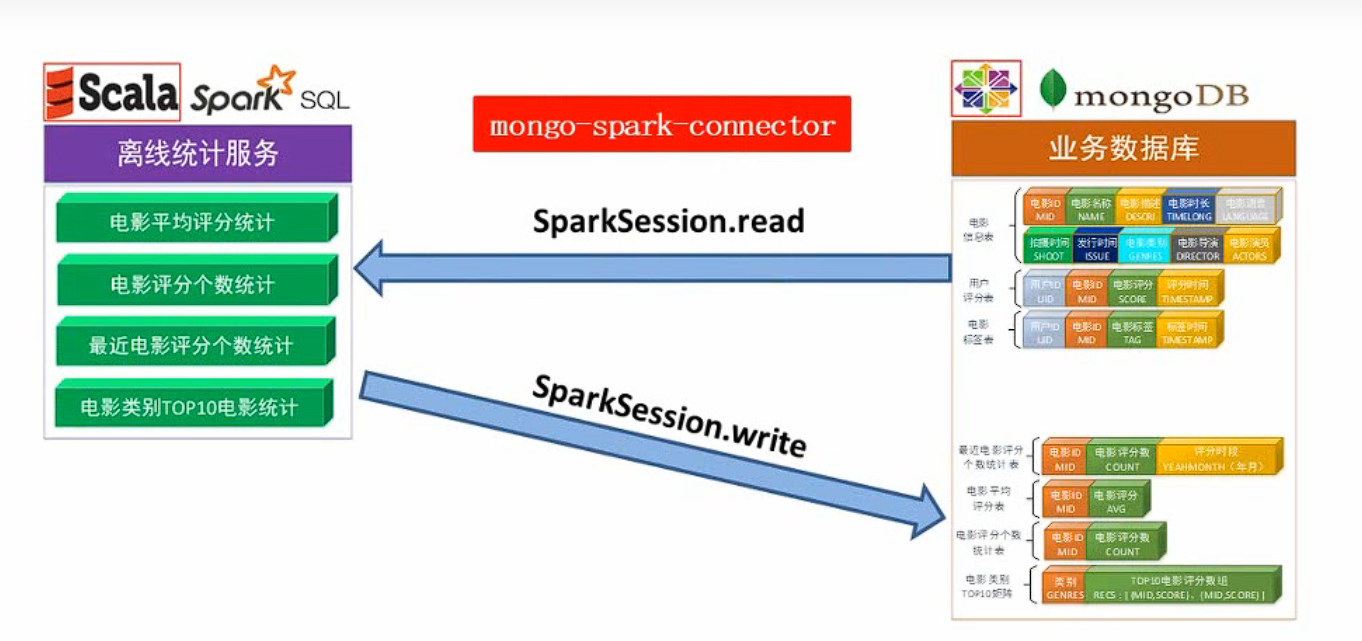
1.3.2 离线推荐模块
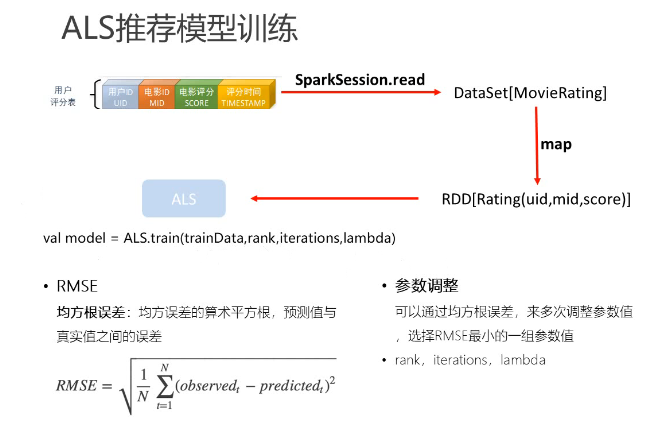
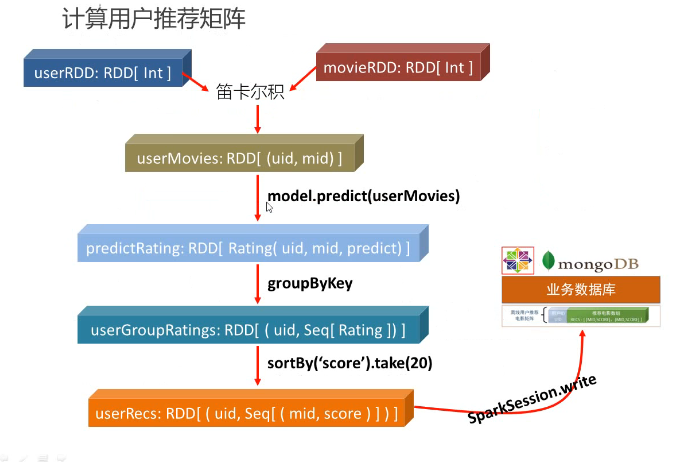
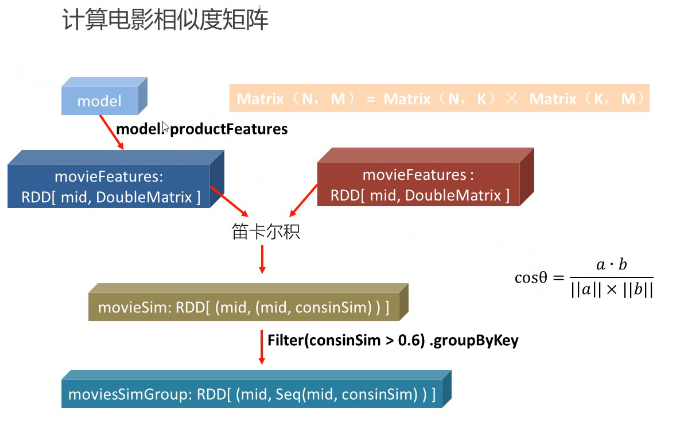
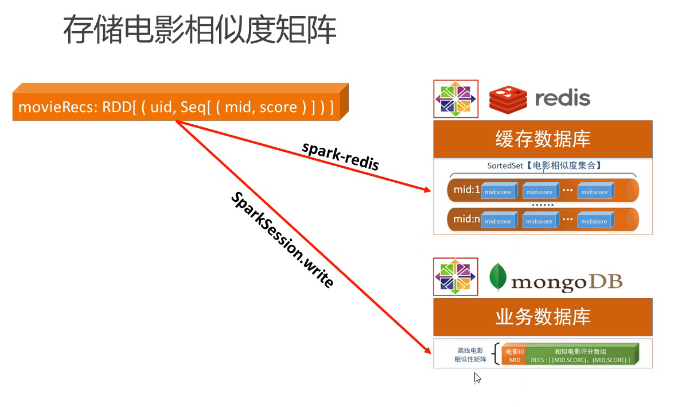
本部分的核心是用ALS算法训练隐语义模型,用于计算用户推荐矩阵,附带的一个产品是电影相似度矩阵;
1.3.3 实时推荐模块
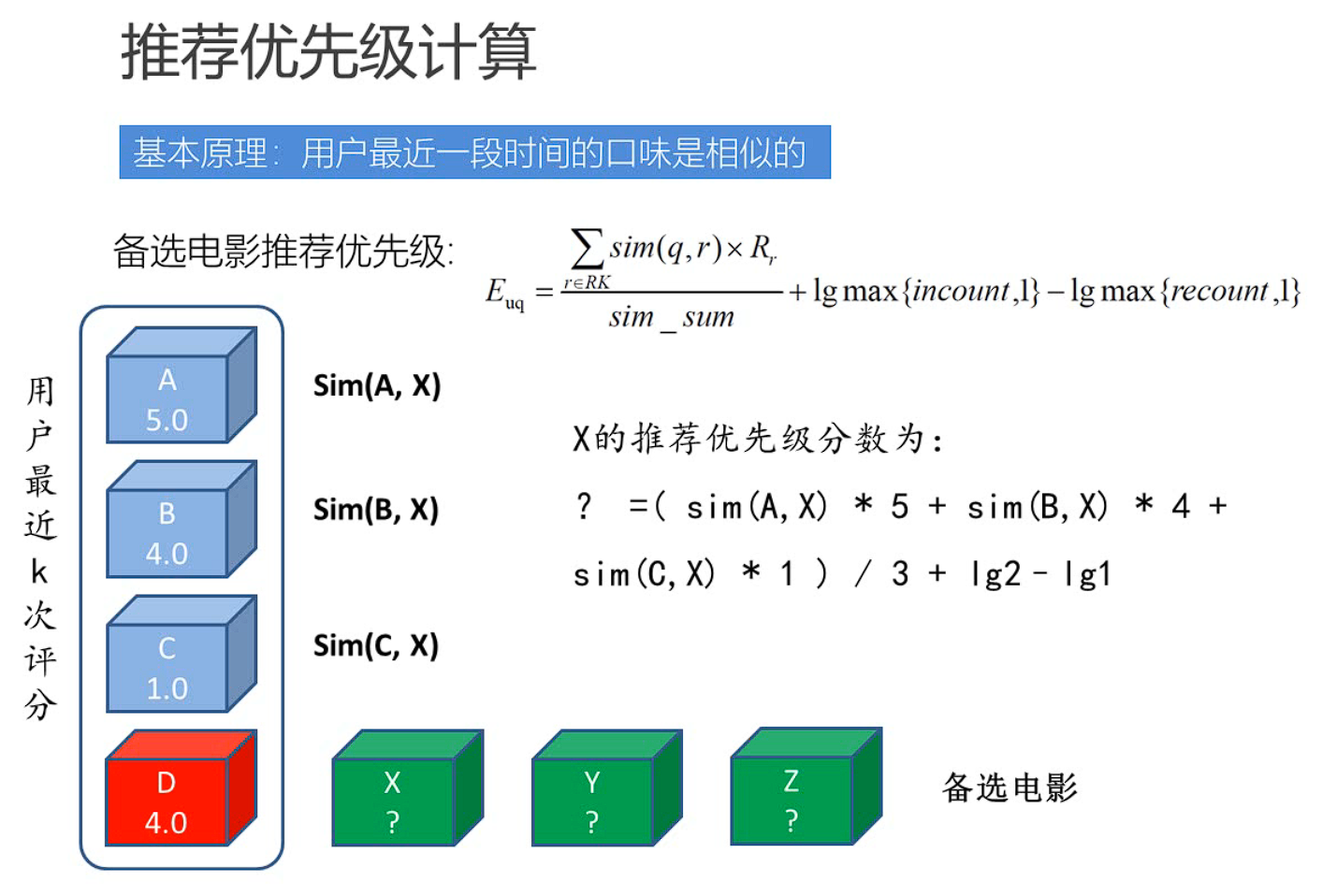
实时推荐系统的要求主要有:计算速度要快,结果可以不是特别精确,有预先设计好的推荐模型;
(1)实时推荐架构
(2)实时推荐优先级计算
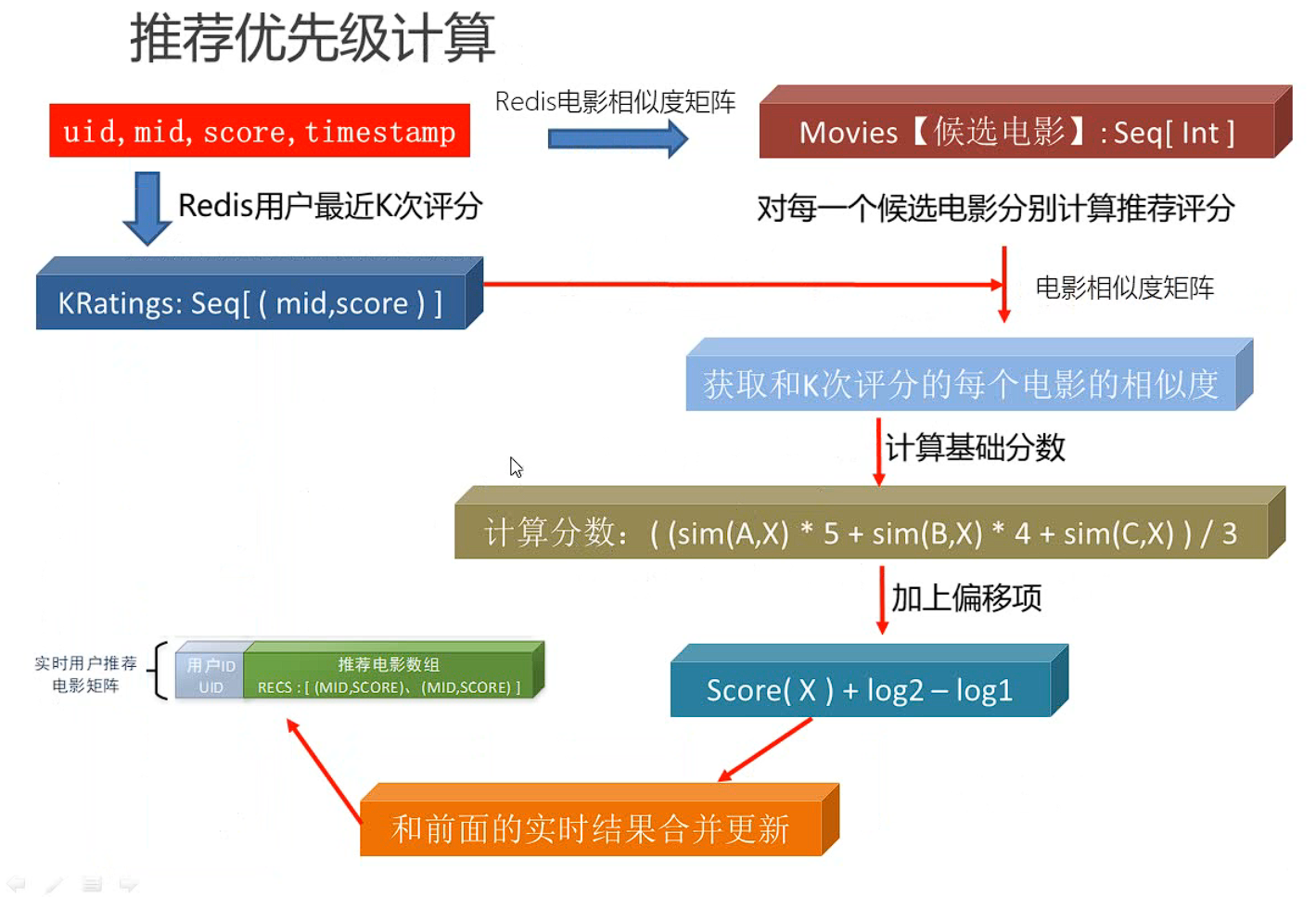
1.3.4 基于内容的推荐模块

1.4 工具环境配置
1.4.1 Windows下环境配置
按照教程把需要的环境配置一下,因为之前学其他课程可能安装过一些所以有些东西就不需要重复安装了(我是很担心重复安装导致环境出错),这里对每一个环境的配置做一个记录总结;
数据库的安装(非关系型数据库)
MongoDB是由C++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似JSON对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。
- MongoDB安装与配置:根据教程(18条消息) MongoDB的下载与安装_头秃怎么办的博客-CSDN博客_mongodb怎么下载
Redis是一个基于内存的高效的非关系型数据库,另外推荐下载Redis Desktop Manager可视化管理工具,来管理Redis;
RedisDump是一个用于Redis数据导入/导出的工具,是基于Ruby实现的,所以要安装RedisDump,需要先安装Ruby
- Ruby安装:教程参考(18条消息) 2. Ruby下载安装_开猿节流的博客-CSDN博客_ruby下载
Andriod SDK的安装
在学习爬虫的时候为了使用Android设备做APP抓取,所以额外下载了Andriod SDK(可以看作是一个用于开发和运行Andriod应用的一个软件),然后被书上忽悠去先下载了Andriod Studio(这是一个功能非常强大的用来做安卓开发调试的官方工具),However,这里仅仅只是将Android Studio的安装包下载在本地并没有安装,因为安装过程中还需要科学上网…因为目前官网上并没有单独的Android SDK的下载包,所以我在一个小网站找到并下载了适合版本的Andriod SDK镜像,这是我们下载并解压好的文件目录;
- (4条消息) Android Studio 下载 与 安装 详细步骤_蚩尤后裔的博客-CSDN博客_android下载安装教程(各显神通的话就直接安装Andriod Studio吧)
- Android SDK的下载与安装 - 菜鸟学飞ing - 博客园 (cnblogs.com)(不然还是老老实实的安装镜像)
- 你以为这么简单?远远没结束,要想成功安装Andriod SDK必须在电脑上配置JDK环境,这对大多数从事JAVA开发的人来说是最基础的事,但是在此之前我是真的没怎么用过JAVA,所以需要安装配置;Android 开发是在 Java 的基础上进行的,Android 使用 Java 语言 作为开发工具 ,Android SDK 引用了大部分的 Java SDK(就是咱们现在说的JDK),少部分被 Android SDK 抛弃而是用其独有的,所以安装 Android SDK 之前必须先安装 Java JDK(这玩意是学JAVA最基础需要安装的环境,一切JAVA的根基!!!);
这里给一个JAVA生态的关系图

1.4.2 Linux下环境配置
前面提到在本地机器上安装环境(该项目中用到了多种工具进行数据的存储、计算、采集和传输)很可能导致一些不必要的冲突,所以这里推荐使用虚拟机进行配置,推荐将CPU的内存设置的尽可能大,即CPU>4、MEM>4GB;
如果虚拟机磁盘不足可以参考VMware虚拟机下ubuntu磁盘扩容(亲测有效) - 腾讯云开发者社区-腾讯云 (tencent.com)扩容,如果要扩容内存直接修改内存大小即可;
(1)MongoDB(单节点)环境配置
1.通过 WGET 下载 Linux 版本的 MongoDB
1 | |
2.将压缩包解压到指定目录
1 | |
3.将解压后的文件移动到最终的安装目录
1 | |
若提示权限不够则使用su切换超级用户或者使用sudo提升命令权限
4.在安装目录下创建 data 文件夹用于存放数据和日志
1 | |
5.在 data 文件夹下创建 db 文件夹,用于存放数据
1 | |
6.在 data 文件夹下创建 logs 文件夹,用于存放日志
1 | |
7.在 logs 文件夹下创建 log 文件
1 | |
8.在 data 文件夹下创建 mongodb.conf 配置文件
1 | |
9.在 mongodb.conf 文件中输入如下内容
- 首先使用vim编辑器打开该文件
1 | |
- 此时为一般模式,输入i进入编辑模式,输入以下内容
1 | |
- 编辑模式下ESC退回一般模式,接着输入:wq保存并退出
如果在图形化界面下可以直接使用复制粘贴进文件,使用vim编辑器是在纯代码的环境下
10.启动 MongoDB 服务器
1 | |
第一个问题就是直接找不到共享库,解决办法参考启动mongodb出现找不到libssl问题如何解决?这篇文章值得一看 - 优草派 (ycpai.cn)即设置符号链接;
第二个问题是在/ lib/x86_64-linux-gnu文件夹中,有指向libssl.so.1.0.0的名称libssl.so.10和指向libcrypto.so.1.0.0的libcrypt.so.10的符号链接,显示
2023/2/18 23:20 现在仍然无法解决,所以没办法往下进行,在mongodb - mongod: error while loading shared libraries: libssl.so.10 libcrypto.so.10 - Stack Overflow中寻找答案;
2023/2/18 23:38 初步排查应该是下载的mongondb的版本不同,在Ubuntu上下载了红帽的mongondb;
2023/2/18 23:54 重新安装Ubuntu版本的mongodb,成功运行,安装还是按照上述步骤,只是将网址改为https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu1604-3.4.4.tgz;


11.访问 MongoDB 服务器
1 | |
12.停止 MongoDB 服务器
1 | |

(2)Redis(单节点)环境配置
1.通过 WGET 下载 REDIS 的源码
1 | |
2.将源代码解压到安装目录
1 | |
3.进入 Redis 源代码目录,编译安装
1 | |
4.安装 GCC
1 | |
Ubuntu下不要使用yum,使用apt-get成功安装,参考(2条消息) 没有已启用的仓库。 执行 “yum repolist all” 查看您拥有的仓库。 您可以用 yum-config-manager –enable <仓库名> 来启用仓库_腾阳的博客-CSDN博客_没有已启用的仓库;
5.编译源代码
1 | |
6.编译安装
1 | |
7.创建配置文件
1 | |
8.修改配置文件中以下内容(推荐使用vim,管理员权限进行修改)
1 | |
1 | |
9.启动 Redis 服务器
1 | |
10.连接 Redis 服务器
1 | |
11.停止 Redis 服务器
1 | |

(3)ElasticSearch(单节点)环境配置
在配置之前需要安装Ubuntu下的JAVA环境,详情参考https://blog.csdn.net/qq_53137707/article/details/126731868;
介绍几个这个步骤可能会用到的Linux命令
- chown elsearch:elsearch elasticsearch-5.6.4 -R:修改该目录的权限为elsearch(elasticsearch不能在root用户下启动,会报错)
- chmod:重置目录权限,使用详情参考https://blog.csdn.net/ichen820/article/details/115524278
- su elsearch:在root用户的身份下切换为elsearch用户
- rm -rf:删除文件夹
- touch:新建文件
1.通过 Wget 下载 ElasticSearch 安装包
1 | |
2.修改配置参数
在limits.conf文件末尾添加如下配置
1 | |
1 | |
在90-nproc.conf文件末尾添加
1 | |
1 | |
在sysctl.con文件末尾添加
1 | |
1 | |
最后执行
1 | |
3.解压 ElasticSearch 到安装目录
1 | |
4.进入 ElasticSearch 安装目录,分别创建 ElasticSearch 数据文件夹 data和ElasticSearch 日志文件夹 logs
1 | |
5.修改 ElasticSearch 配置文件
1 | |
1 | |
- yml文件中#后面的内容表示注释,注意不要直接在原注释上面修改,在下面新增;
- /home/tintoki/elasticsearch-5.6.2/bigdata/data和/home/tintoki/elasticsearch-5.6.2/bigdata/logs可以手动创建避免无法找到(home目录下不是直接的elasticsearch-5.6.2目录这一点需要注意,尽管在视图中看起来是其直接子目录);
6.测试
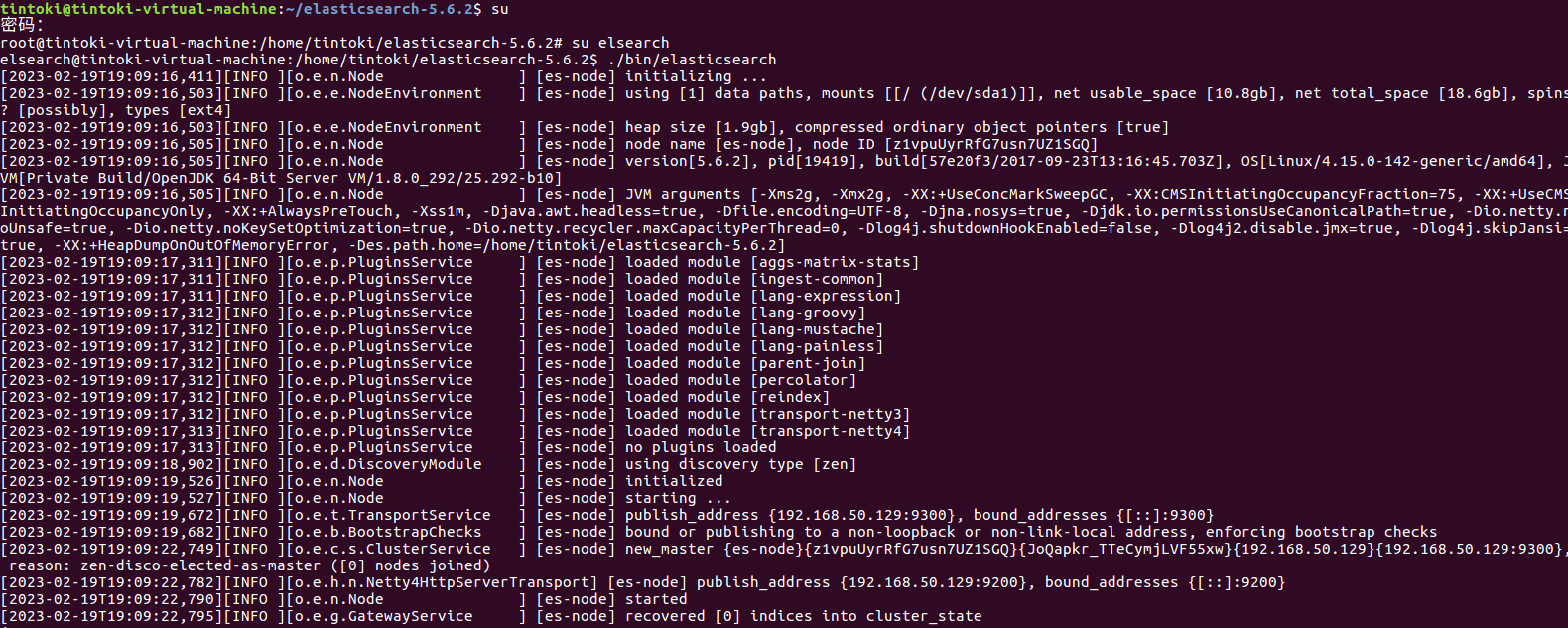
首先切换用户并进入ElasticSearch安装目录,使用./bin/elasticsearch启动服务,出现如下情形表示开启成功
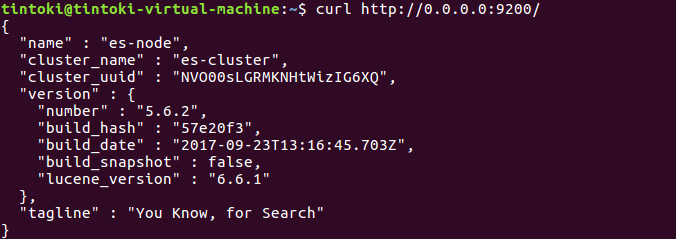
重新打开一个shell,输入curl http://0.0.0.0:9200/测试得到如下结果
在客户端(第二个打开的shell)查看并关闭服务(注意需要切换到elsearch用户下)

(4)Azkaban(单节点)环境配置
1.安装 GIT
1 | |
2.通过 git 下载 Azkaban 源代码
1 | |
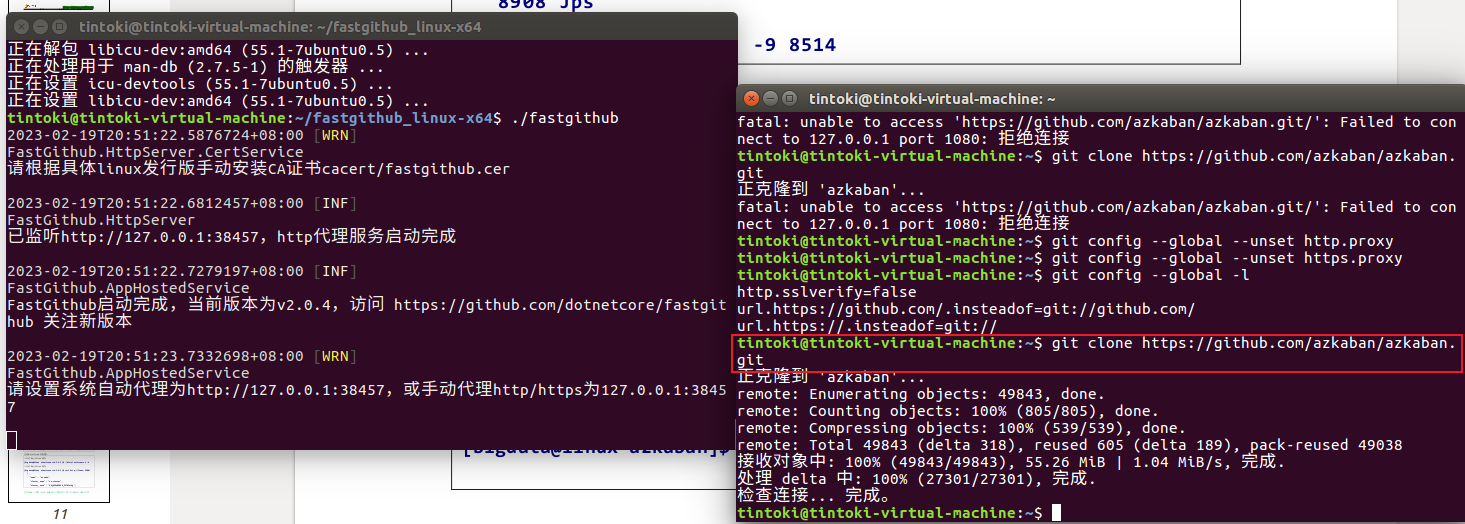
使用git访问github的时候可能会有速度上的限制一直进不去,可以参考https://zhuanlan.zhihu.com/p/428454772下载fastgithub使用(下载的库是libicu-dev而不是libicu),但是不知道什么原因有时候还是一直下载不了...(只能多尝试两次,没别的办法,网上说的什么把https修改为git也不可行)
3.安装编译环境
1 | |
1 | |
(第二个gcc-c++*会抛出一长串东西,不用管)
4.执行编译命令
- 使用gradlew命令报错JAVA_HOME的问题,参考https://www.zditect.com/article/57550939.html解决,本质上就是之前设置JAVA_HOME的时候设置到bin目录里面去了,实际上只需要设置到bin的上一级目录即可;
- 在分步骤编译的过程中,可能某个步骤会报错,参考https://blog.csdn.net/weixin_44291548/article/details/119022392和http://www.chinacion.cn/article/5065.html解决,本质上就是重新执行这一步的编译即可(不要使用`./gradlew clean build`一步编译,时间长而且会卡住);
首先清空编译
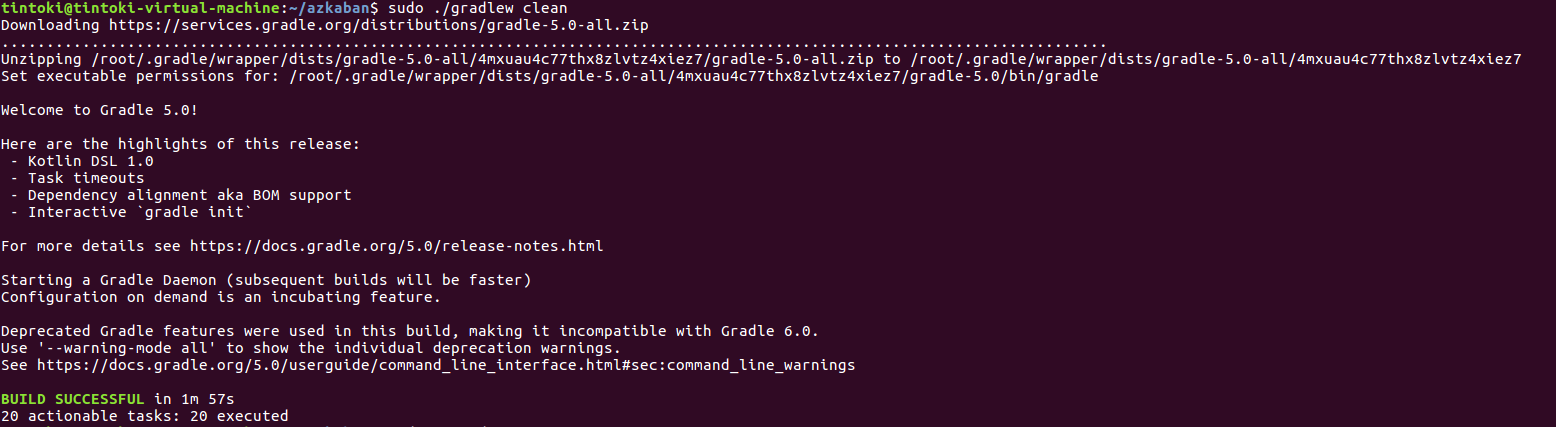
接着编译并安装插件(出现BUILD SUCCESSFUL表示成功)
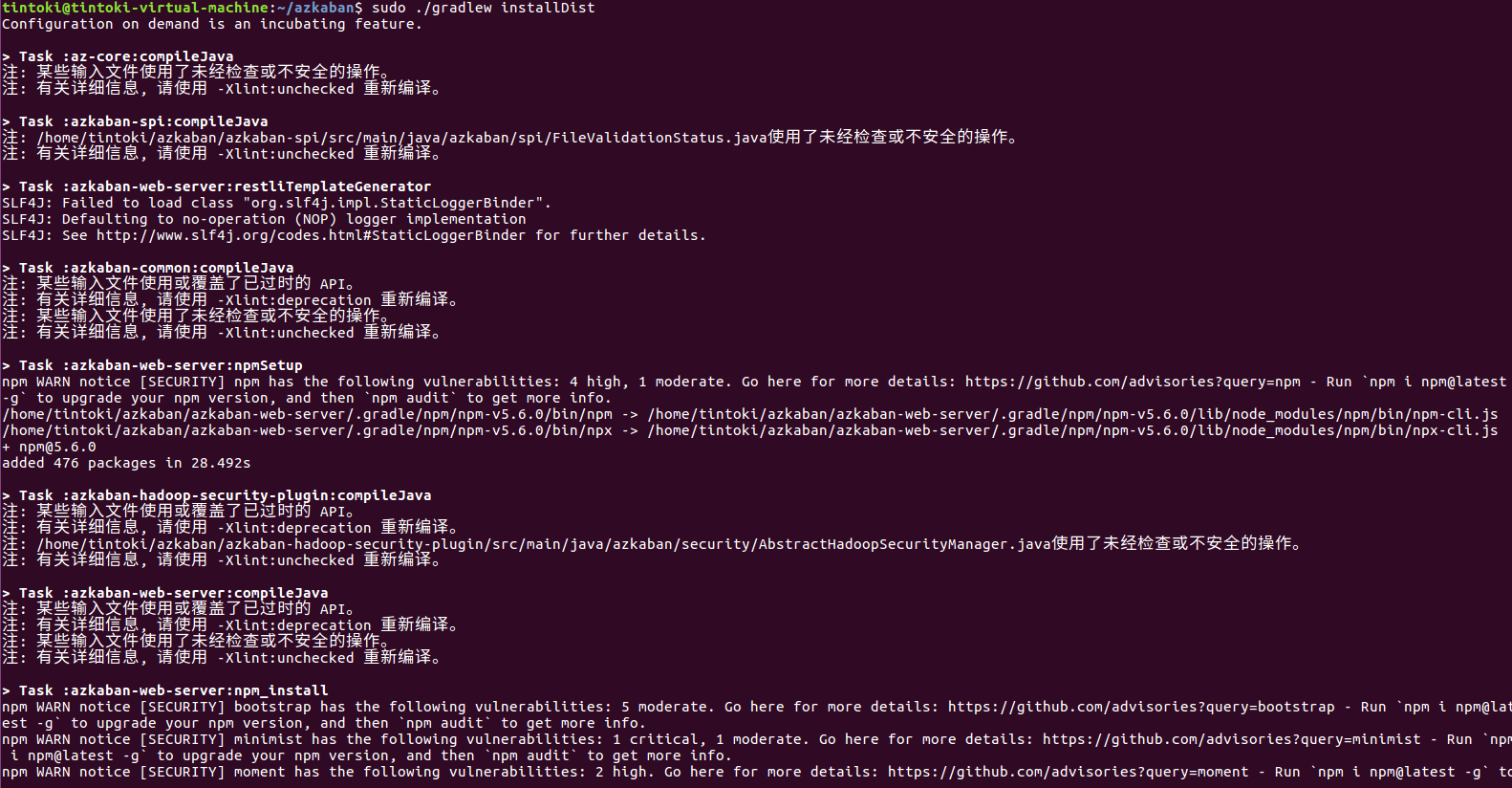
最后编译但不运行测试
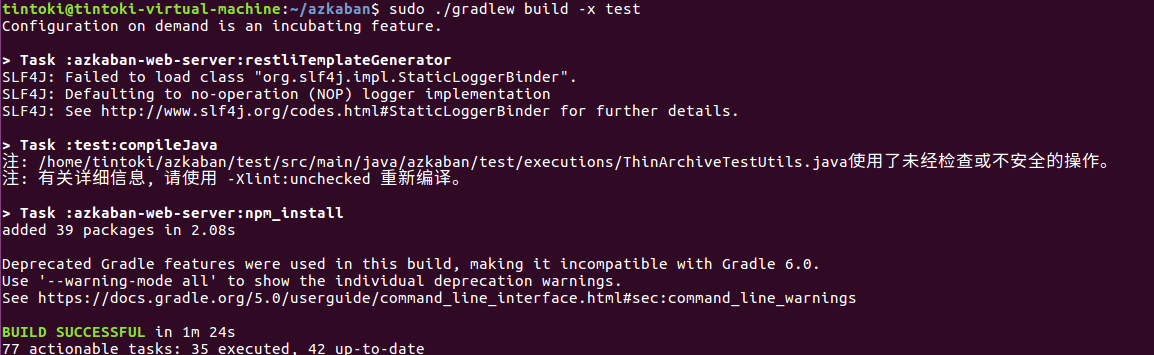
5.部署Azkaban Solo
拷贝并解压压缩文件

启动 Azkaban Solo 单节点服务

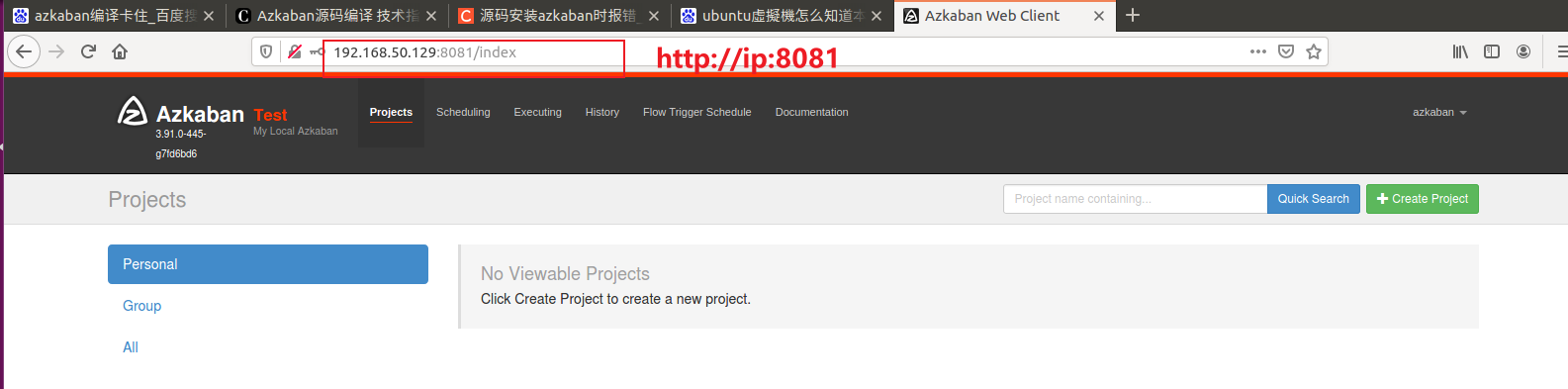
访问 Azkaban Solo 单节点服务(用户名:azkaban,密码 azkaban)
关闭 Azkaban Solo 单节点服务

(5)Spark(单节点)环境配置
- 关于Spark和Scala、Hadoop的关系参考https://zhidao.baidu.com/question/1581248874790042060.html(三者相互独立没必要全都下载);
- 关于解压报错可以参看https://blog.csdn.net/weixin_43988251/article/details/128032586,主要还是因为网上的链接有些过期导致下载的压缩文件有问题解压失败;
- 关于如何获取最新下载链接以及详细安装参考https://zhuanlan.zhihu.com/p/595304446;
- 最后一点,修改环境变量之前最好先查一下资料再修改,避免覆盖到时候什么都找不到了,关于环境变量的配置参考https://www.cnblogs.com/c-abc/p/4337179.html;
1.通过wget下载并解压 spark 安装包
2.进入spark安装目录

3.复制并修改slave配置文件(新版为worker文件)
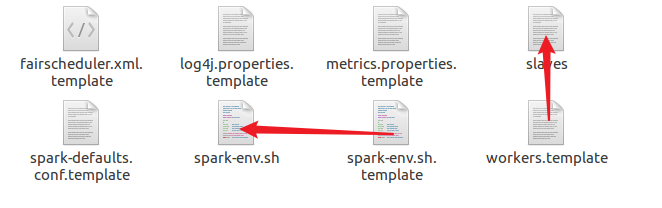
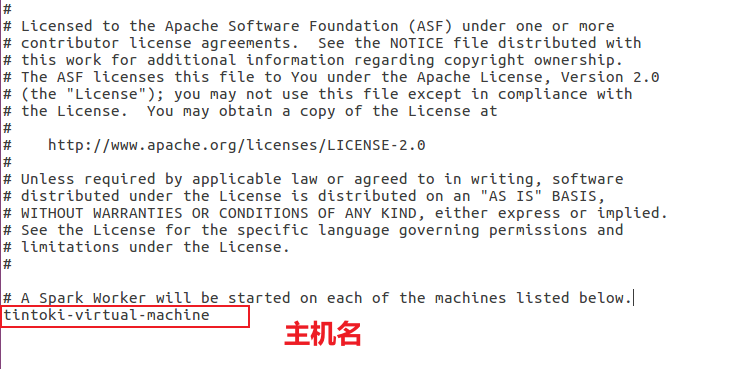
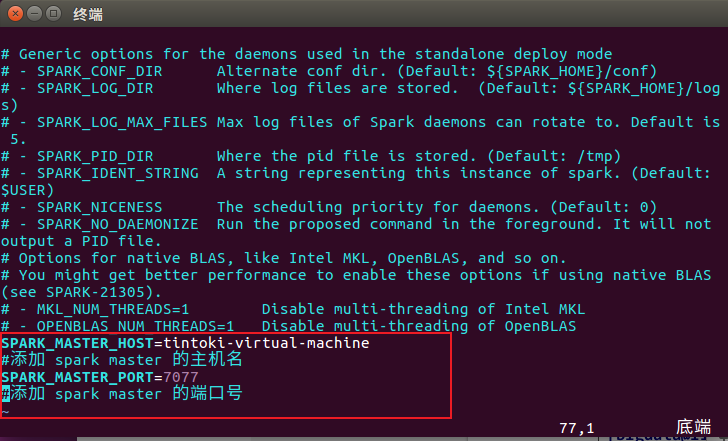
4.复制并修改Spark-Env配置文件
5.启动Spark之前安装并打开ssh服务
参考链接https://zhuanlan.zhihu.com/p/512937312
- 开启ssh服务:service ssh start
- 查看ssh服务是否开启:ps -e | grep ssh
- 检查ssh服务状态((显示active running表示服务正常)):sudo systemctl status ssh
- 关闭ssh服务:service ssh stop
6.启动Spark
启动Spark集群
1 | |
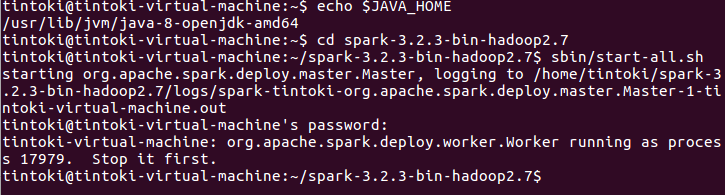
访问 Spark 集群,浏览器访问 http://主机名:8080
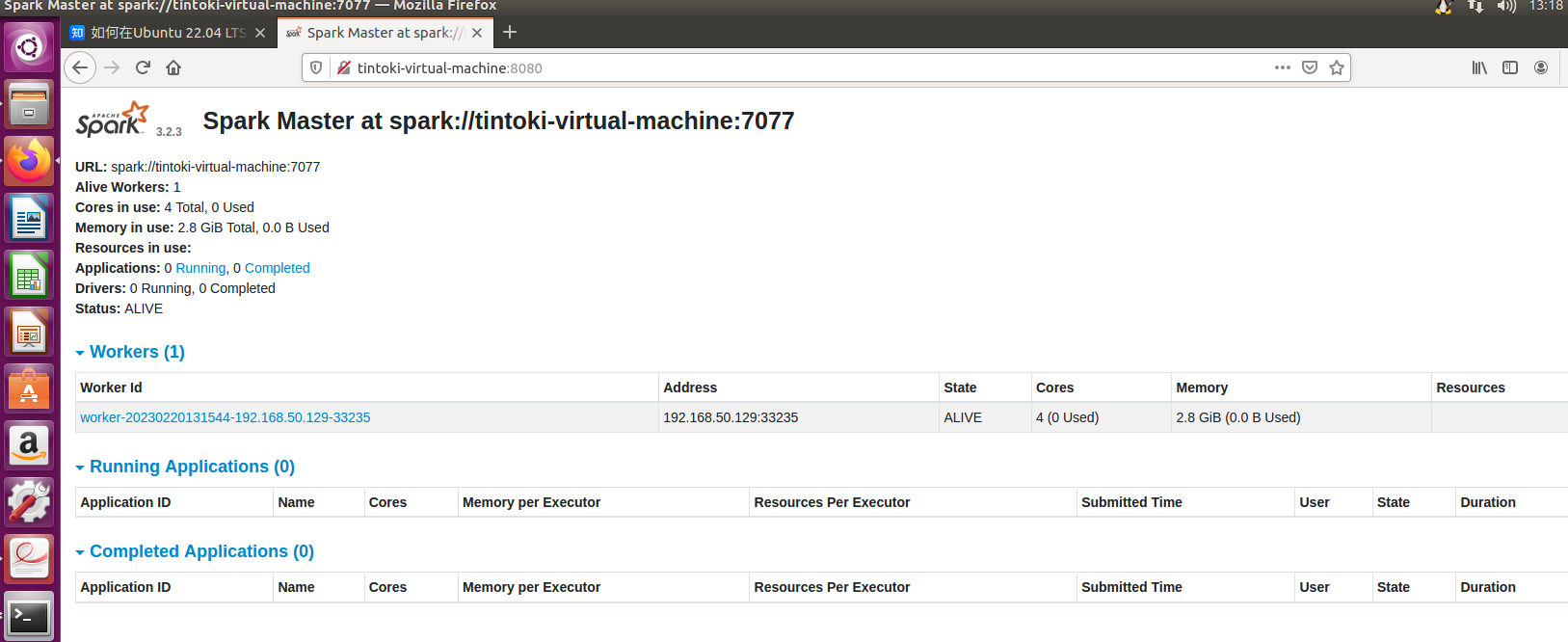
关闭Spark集群
1 | |

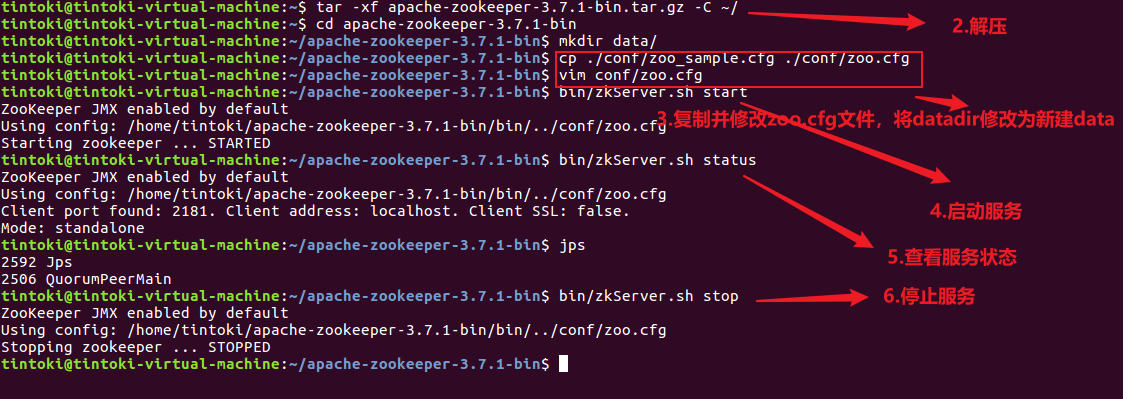
(6)Zookeeper(单节点)环境配置
1.通过 wget 下载 zookeeper 安装包
1 | |
(Zookeeper的配置很简单几乎没有任何问题)
2.启动服务
1 | |
3.查看服务状态
1 | |
4.停止服务
1 | |
(7)Flume-ng(单节点)环境配置
1.wget下载flume安装包
1 | |
获取最新的下载地址可以在https://flume.apache.org/download.html寻找;
2.解压
1 | |
(8)Kafka(单节点)环境配置
1.下载并解压Kafka安装包,进入目录修改配置文件
1 | |
1 | |
2.开启服务(启动kafka服务之前需要先开启zookeeper服务)
1 | |
3.创建Topic
1 | |
查看话题列表
1 | |

Kafka创建主题报错参考https://blog.csdn.net/zhangphil/article/details/123093909和[(1条消息) Kafka报错:Exception in thread “main“ joptsimple.UnrecognizedOptionException: zookeeper is not a recogn_血煞长虹的博客-CSDN博客](https://blog.csdn.net/succing/article/details/127334561)解决;
4.关闭服务
1 | |
(9)IDEA集成开发环境
Linux下安装IDEA参考https://www.ngui.cc/el/381715.html?action=onClick(有账号可以无需参考pojie);
启动IDEA
1 | |
(10)Maven安装
配置maven mvn 命令参考:https://blog.csdn.net/qq_37933685/article/details/80691044;
IDEA配置Maven参考:https://blog.csdn.net/coldLight1/article/details/119760681 (Windows版),https://blog.csdn.net/weixin_43790083/article/details/128984966(Linux版);
2.项目框架搭建
2023/2/22 16:45 今天下午简单的搞了一下,然后遇到了非常多的问题(报错一头雾水,不知道怎么管理项目树…这就是啥都不懂然后强行进行项目的后果),短暂的反思过后决定应该先学会简单使用IDEA,至少需要了解它的一些特性,学习完毕后再继续进行项目的跟进;
2023/2/22 19:01 刚才又简单的回顾了一下尚硅谷的IDEA教程,参考JAVA - Tintoki_blog (gintoki-jpg.github.io),发现投入时间和精力去学习IDEA没什么必要,反之我们在项目开发过程中总结遇到的问题进而逐渐熟悉使用IDEA进行开发是更好的选择,所以不要担心花费过多的时间,只要能解决的问题就不是问题(期间记录好解决问题的思路);
2.1 目录结构
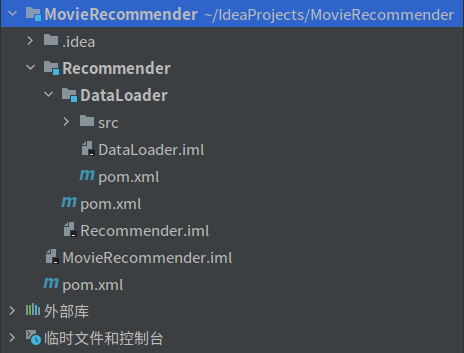
根据教程的指示我们并没有生成和教程一样的.xml文件,参考https://blog.csdn.net/xinhe96/article/details/123789402解决(项目目录下执行`mvn idea:module`);
由于操作失误导致DataLoader变成了directory和moudle,在删除之后发现新建提示存在同名moudle,参考https://blog.csdn.net/qq_43751200/article/details/125158407解决;
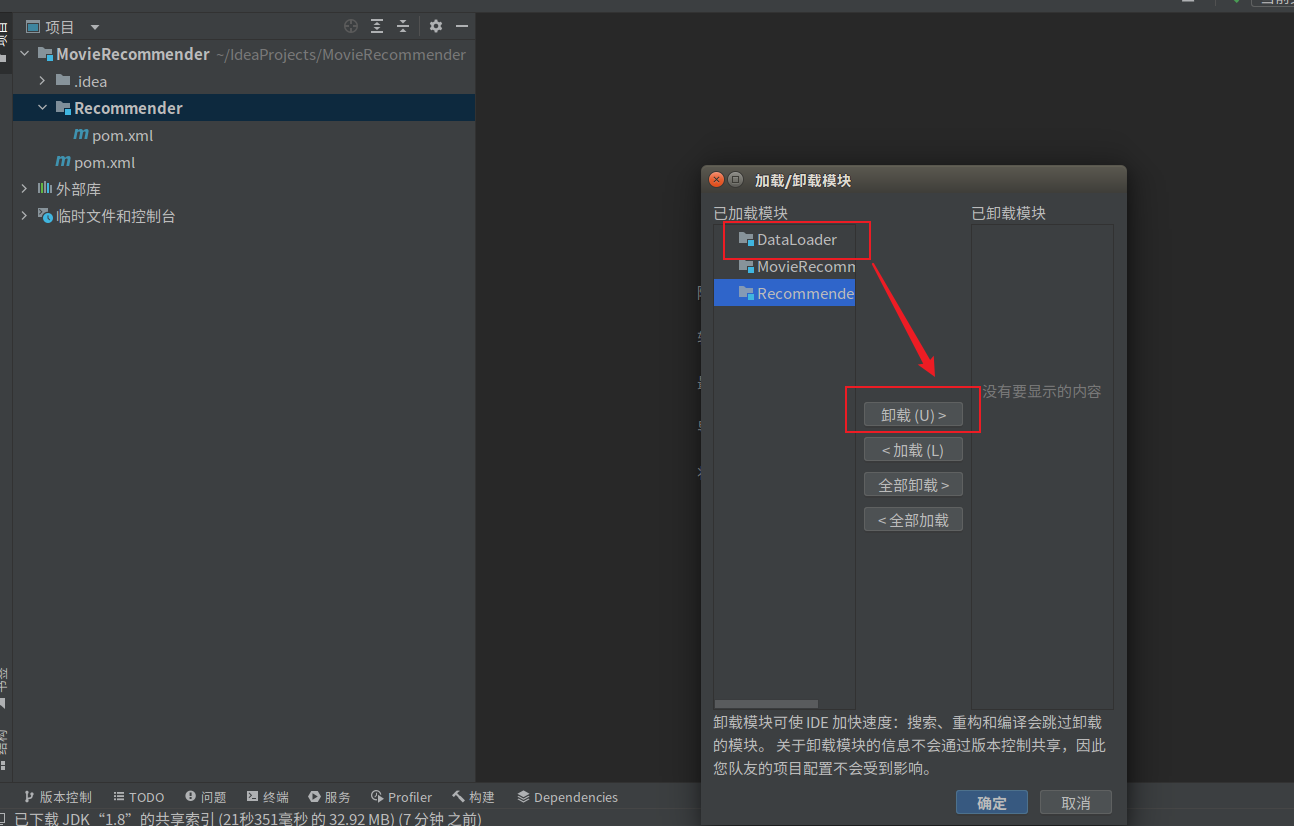
Q:IDEA中的directory和moudle有什么区别?为什么有时候创建会出错?
2.2 版本信息
MovieRecommender/pom.xml
1 | |
2.3 项目依赖
- IDEA同步失敗Unresolved dependency:https://blog.csdn.net/zhonglunshun/article/details/128655893
- Maven提示vulnerabilities info:https://blog.csdn.net/weixin_38189581/article/details/128322847
- Dependency ‘org.apache.spark:spark-sql_2.13:3.2.3’ not found:這種按照所屬的groupid在https://mvnrepository.com/中尋找可用的artifactId和version即可,注意嚴格嚴格匹配
MovieRecommender/pom.xml
1 | |
MovieRecommender/Recommender/pom.xml
1 | |
MovieRecommender/Recommender/DataLoader/pom.xml
1 | |
2.4 未解决问题汇总
这个问题在网上没有任何有效的解决办法,最离谱的是新建一个项目之后可以正常的对目录结构进行全局库的配置…而且不管怎么配置怎么捣鼓都是没问题的,查阅了大量资料也没找出来解决办法(主要是还花费了我两三个小时真的无语),因此只能删除整个项目重新开始;
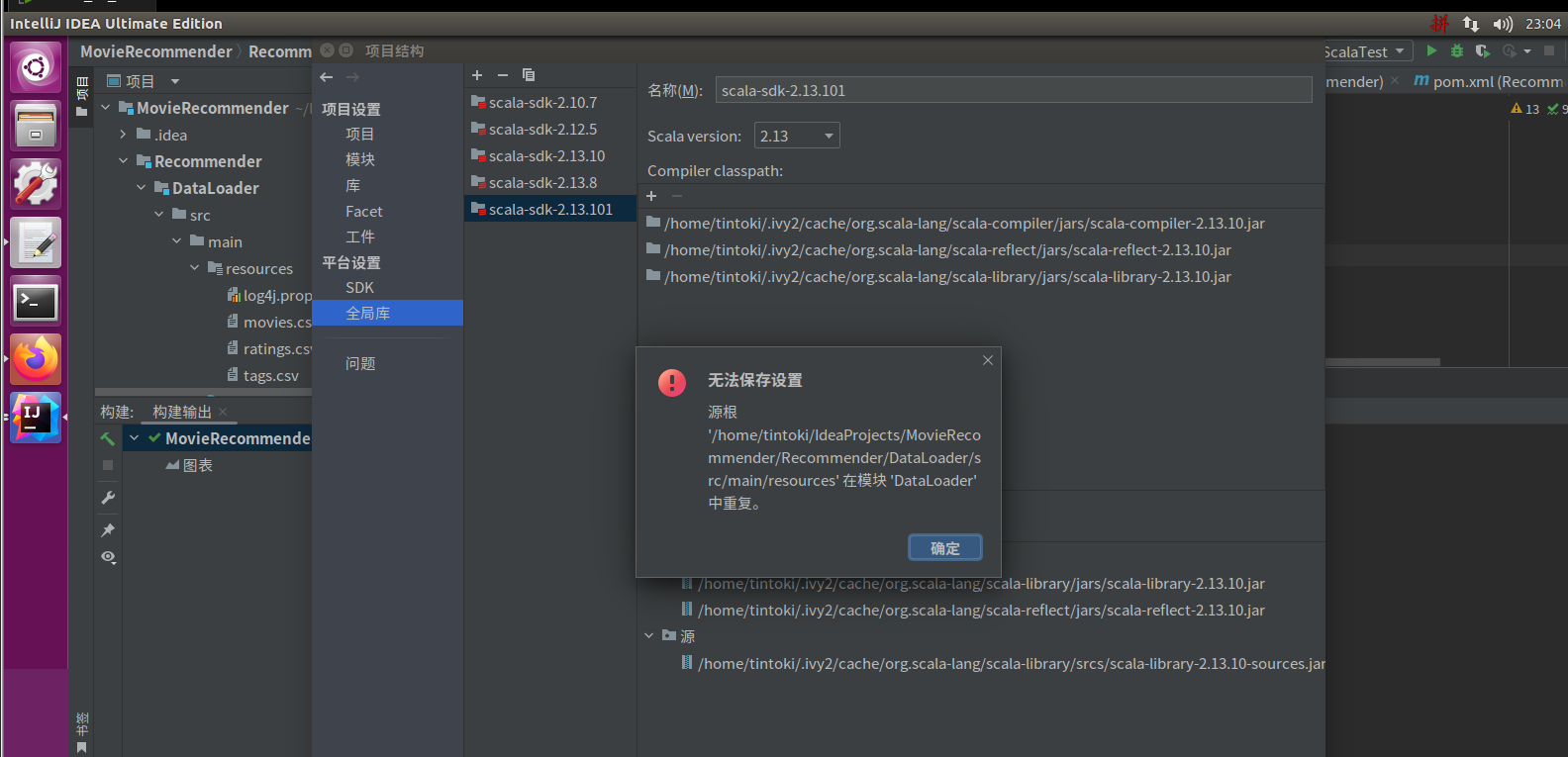
———–2023/2/22———–
IDEA同步失敗Unresolved dependency:https://blog.csdn.net/zhonglunshun/article/details/128655893
Maven提示vulnerabilities info:https://blog.csdn.net/weixin_38189581/article/details/128322847
Dependency ‘org.apache.spark:spark-sql_2.13:3.2.3’ not found:這種按照所屬的groupid在https://mvnrepository.com/中尋找可用的artifactId和version即可,注意嚴格嚴格匹配
———–2023/2/23———–
IDEA配置安裝scala:首先需要在Ubuntu中下載scala,參考https://www.lxlinux.net/6435.html,然後在IDEA中下載scala插件並在IDEA中進行配置,此處參考https://blog.csdn.net/u010416101/article/details/127505064;
Mongodb 重新啓動報錯,解決辦法參考https://blog.csdn.net/qq_42910468/article/details/103076136;
scala編譯報錯,原因是java和scala版本不同,解決方法參考https://blog.csdn.net/miaohui8023/article/details/105327734和https://blog.csdn.net/miaohui8023/article/details/105314937(他媽的不知道IDEA抽什麼風飛得給我說resources重復,一直修改不好只能重新搭建項目);
———–2023/2/24———–
IDEA測試鏈接Mongdbhttps://www.ttt5.cn/145835.html;
spark、scala版本號需要保持一致https://blog.csdn.net/weixin_36172296/article/details/115572036;
spark版本需要與mongdb對應https://spark-packages.org/package/mongodb/mongo-spark;
NoSuchFieldError(以上兩點都可以歸結爲版本衝突,也就是run時候會報該錯誤)https://blog.csdn.net/weixin_39452168/article/details/108146847,Maven helper使用方法參考https://blog.csdn.net/GyaoG/article/details/120599475,現在只需要細心的把衝突的依賴解決即可;
2023/2/24 17:35 已放弃,凭借现在自己的实力确实没办法解决这些问题,等之后再进行;