自然语言处理_初级
参考书:《统计自然语言处理》
参考视频:
参考博客:
- python自然语言处理:https://nltk.apachecn.org(实操);
- 《自然语言处理综论 中文版》:README - slp3-zh (gitbook.io);
- 努力推石头的西西弗斯的博客_自然语言处理_51CTO博客;
2023/2/28 9:15 本学期的这几门课实际上啃书的效果都不是很大,效率太低了,推荐直接刷视频然后上手写代码,不管是知识图谱还是自然语言处理还是机器视觉技术,通通适用(因为课后作业也都涉及编程);
2023/3/2 10:15 西湖大学这个课程非常推荐!!!极其适合新手由浅入深进行学习,主要是和课程大纲类似所以可以作为学校课程的替代课程,李宏毅那个更加偏向于实际应用,可以在学完西湖大学的课程之后再看;
2023/3/2 15:56 《统计自然语言处理》这本教材可以作为中文版的教材使用,但是因为它可能偏向的是基于统计的方法,所以也不能只看书,还是要结合视频,同时概率论的知识点我们也需要复习掌握;
2023/3/4 17:23 知识图谱和自然语言处理这两门课我是真的不知道怎么学了,感觉网上的资源都太杂乱了,西湖大学的课程讲的不是不好,知识点真的非常零碎很难做笔记 – 可能这门课程真的只能上课听讲?或者是按照教学大纲一个一个去网上找知识点;
2023/3/9 11:08 这个老师上课讲的东西完全没法听,PPT也做的非常混乱,现在暂定的学习方法就是按照所给的教学大纲和PPT的重点去B站或者百度定向搜索视频或文章来学习;
绪论
自然语言处理是一门集语言学、数学、计算机科学和认知科学等于一体的综合性交叉学科,如何让计算机正确、有效地理解和处理人类语言,是当今具有巨大挑战性的理论和技术问题;
“自然语言处理(naturallanguage processing, NLP)就是利用计算机为工具对人类特有的书面形式和口头形式的语言进行各种类型处理和加工的技术”
“自然语言处理可以定义为研究在人与人交际中以及在人与计算机交际中的语言问题的一门学科。自然语言处理要研制表示语言能力和语言应用的模型,建立计算框架来实现这样的语言模型,提出相应的方法来不断地完善这样的语言模型,根据这样的语言模型设计各种实用系统,并探讨这些实用系统的评测技术”
–自然语言处理的定义
基于统计的自然语言处理的理论基础是哲学中的经验主义,基于规则的自然语言处理的理论基础是哲学中的理性主义:
NLP中的理性主义方法是一种基于规则的方法,也称为符号主义方法,这种方法的根本依据是“物理符号系统假设”,即假设人类的智能行为可以使用物理符号系统来模拟
NLP中的经验主义方法是一种基于统计的方法,这种方法使用概率或随机的方法来研究语言,建立语言的概率模型
1.NLP概述
语音和文字是构成语言的两个基本属性,语音是语言的物质外壳,文字是记录语言的书写符号系统;
1.1 研究方向
NLP研究的内容十分广泛,根据其应用的目的不同可以大致分为以下几个方向:
(1)机器翻译(machine translation,MT):实现一种语言到另一种语言的自动翻译。
(2)自动文摘(automatic summarizing或automatic abstracting):将原文档的主要内容和含义自动归纳、提炼出来,形成摘要或缩写。
(3)信息检索(information retrieval):信息检索也称情报检索,就是利用计算机系统从海量文档中找到符合用户需要的相关文档。面向两种或两种以上语言的信息检索叫做跨语言信息检索(cross-language/trans-lingual information retrieval)。
(4)文档分类(document categorization/classification):文档分类也称文本分类(text categorization/classification)或信息分类(information categorization/classification),其目的就是利用计算机系统对大量的文档按照一定的分类标准(例如,根据主题或内容划分等)实现自动归类。近年来,情感分类(sentiment classification)或称文本倾向性识别(text orientation identification)成为本领域研究的热点。
(5)问答系统(question-answering system):通过计算机系统对用户提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并做出相应的回答。问答技术有时与语音技术和多模态输入、输出技术,以及人-机交互技术等相结合,构成人-机对话系统
(human-computer dialogue system)。
(6)信息过滤(information filtering):通过计算机系统自动识别和过滤那些满足特定条件的文档信息。通常指网络有害信息的自动识别和过滤,主要用于信息安全和防护、网络内容管理等。
(7)信息抽取(information extraction):指从文本中抽取出特定的事件(event)或事实信息,有时候又称事件抽取(event extraction)。
(8)文本挖掘(text mining):有时又称数据挖掘(data mining),是指从文本(多指网络文本)中获取高质量信息的过程。文本挖掘技术一般涉及文本分类、文本聚类(text clustering)、概念或实体抽取(concept/entity extraction)、粒度分类、情感分析(sentiment analysis)、自动文摘和实体关系建模(entity relation modeling)等多种技术。
(9)舆情分析(public opinion analysis):由于网上的信息量十分巨大,仅仅依靠人工的方法难以应对海量信息的收集和处理,需要加强相关信息技术的研究,形成一套自动化的网络舆情分析系统,及时应对网络舆情,由被动防堵变为主动梳理、引导。显然,舆情分析是一项十分复杂、涉及问题众多的综合性技术,它涉及网络文本挖掘、观点(意见)挖掘(opinion mining)等各方面的问题。
(10)隐喻计算(metaphorical computation):”隐喻”就是用乙事物或其某些特征来描述甲事物的语言现象。简要地讲,隐喻计算就是研究自然语言语句或篇章中隐喻修辞的理解方法。
(11)文字编辑和自动校对(automatic proofreading):对文字拼写、用词,甚至语法、文档格式等进行自动检查、校对和编排。
(12)作文自动评分:对作文质量和写作水平进行自动评价和打分。
(13)光读字符识别(optical character recognition,OCR):通过计算机系统对印刷体或手写体等文字进行自动识别,将其转换成计算机可以处理的电子文本,简称字符识别或文字识别。相对而言,文字识别研究的主要内容更多地属于字符(汉字)图像识别问题,通常被看作是一个模式识别问题。
(14)语音识别(speech recognition):将输入计算机的语音信号识别转换成书面语表示。语音识别也称自动语音识别(automatic speech recognition,ASR)。
(15)文语转换(text-to-speech conversion):将书面文本自动转换成对应的语音表征,又称语音合成(speech synthesis)。
(16)说话人识别/认证/验证(speaker recognition/identification/verification):对一说话人的言语样本做声学分析,依此推断(确定或验证)说话人的身份。
Q:信息抽取和信息检索的区别是什么?
A:信息抽取直接从自然语言文本中抽取信息框架,一般是用户感兴趣的事实信息,而信息检索主要是从海量文档集合中找到与用户需求(一般通过关键词表达)相关的文档列表。当然,信息抽取与信息检索也有密切的关系,信息抽取系统通常以信息检索系统(如文本过滤)的输出作为输入,而信息抽取技术又可以用来提高信息检索系统的性能。
1.2 基本问题
如何面向不同的应用目标,针对不同语言单位的特点,研究歧义消解和未知语言现象的处理策略及实现方法,就成了自然语言处理面临的核心问题;
歧义是自然语言中普遍存在的语言现象,它们广泛地存在于词法、句法、语义、语用和语音等每一个层面。任何一个自然语言处理系统,都无法回避歧义的消解问题。
一个实用的自然语言处理系统必须具有较好的未知语言现象的处理能力,而且有足够的对各种可能输入形式的容错能力,即我们通常所说的系统的鲁棒性(robustness)问题。
1.3 基本方法
一般认为,自然语言处理中存在着两种不同的研究方法,一种是理性主义(rationalist)方法,另一种是经验主义(empiricist)方法;
- 理性主义方法认为,人的大部分语言知识是与生俱来的,由遗传决定
- NLP中,理性主义方法主张建立符号处理系统,由人工整理和编写初始的语言知识表示体系(通常为规则),构造相应的推理程序,系统根据规则和程序,将自然语言理解为符号结构(逻辑表达式、语义网络、中间语言等)
- 经验主义方法认为大脑一开始具备的只是具有处理联想、模式识别和通用化处理的能力,这些能力能够协助掌握具体的自然语言结构
- NLP中,经验主义方法主张通过建立特定的数学模型来学习复杂的、广泛的语言结构,然后利用统计学、模式识别和机器学习等方法来训练模型的参数,以扩大语言使用的规模;
- 经验主义的自然语言处理方法是建立在统计方法基础之上的,因此,我们又称其为统计自然语言处理(statistical natural language processing)方法;
- 在统计自然语言处理方法中,一般需要收集一些文本作为统计模型建立的基础,这些文本称为语料(corpus)。经过筛选、加工和标注等处理的大批量语料构成的数据库叫做语料库。由于统计方法通常以大规模语料库为基础,因此,又称为基于语料的自然语言处理方法;
2.基本概念
2.1 常用术语
自然语言处理NLP:通过算法、统计或常识专门处理语言和各种方法的学科;
自然语言理解NLU:对某种自然语言的文本的真正理解;
计算语言学:从语言学的角度来分析、处理自然语言,试图通过计算机来模拟人的语言能力。目前来看,计算机语言学和自然语言处理方向一致,两者可以看作同一事物的不同名称;
2.2 语言处理层次
语言处理的层次自底向上依次为:
- 形态分析 (Morphological Analysis)
- 句法分析 (Syntax)
- 语义分析 (Semantic)
- 语用分析 (Pragmatics)
- 篇章分析 (Discourse)
- 世界知识分析 (World)
从词汇、句法直到世界知识,下一层就是上一层的基础,当下一层表述不合理时,上一层也无法实现正确表达;
2.2.1 形态分析
形态分析也称为词汇分析,指的是从完整书写的词形式中识别出词干,例如英语单词cowardly =coward(词干)+ ly(后缀);
一般形态分析也包括词性分析,上述例子中的ly就是将名词变为形容词;
中文分词:汉语或者大多数东亚语言中的词汇分析与英语有所不同,汉语是词汇间无间隔的句子书写方式,所以这就要求,从句子(即字序列)中切分出词,这个处理称做中文分词
大多数自然语言分析系统通常首先需要将文本分割为有语言学意义的符号单元。广义上来说,这个过程包括分词(切分)、词原型提取、词性标注以及命名实体/短语识别等一大类词法处理任务。
2.2.2 句法分析
句法和语义是关联的两个语言层次的概念,句法有时候也不够严格地被称为语法或文法(grammer),严格来说,语法 = 句法 + 语义;
句法指定义了句子内部各成分之间的形式化的相对位置关系,通常来说,句法 = 词典 + 规则;
句法分析的目标是给各句子成份分配句法类别标签,并确定各成份之间的句法关系;
2.2.3 语义分析
语义分析的目的是为意义完整的话语(utterances)赋予意义,包括词义及词义组合,这是一种与上下文无关的意义;
上下文相关的语义分析包括:
- 句子层面的语义角色标注任务:给出句子内部的谓词-论元结构
- 词义消歧
- 指代消解
2.2.4 语用分析
指文本符号或会话与会话生产者/用户之间的关系;
它对不同的情境上下文背景中,对话语的解释重大影响;
这部分工作困难重重,目前还没有在此方面取得突破性进展;
2.2.5 篇章分析
针对文本整体论述结构的分析,同时,还负责分析文本句子之间的关系;
2.2.6 世界知识分析
世界知识是指不受限制的常识知识,这个任务是负责推断出每个语言用户必须具备的一般世界知识;
一、形态分析
Morphological Analysis 译为形态分析,又译为词汇分析,其中形态学Morphological是语言学的一个分支,研究词的内部结构,包括屈折变化和构词法两个部分;
1.词的构成
1.1 词素
词是基于最小的语义单元-词素构成的
词素可以分成两种:
词干:play cat friend
词缀:-ed -s un- -ly
词缀又可以分为两种:
- 前缀:un-
- 后缀:-ed -s un- -ly
1.2 变形
变形是同一个单词的不同形式
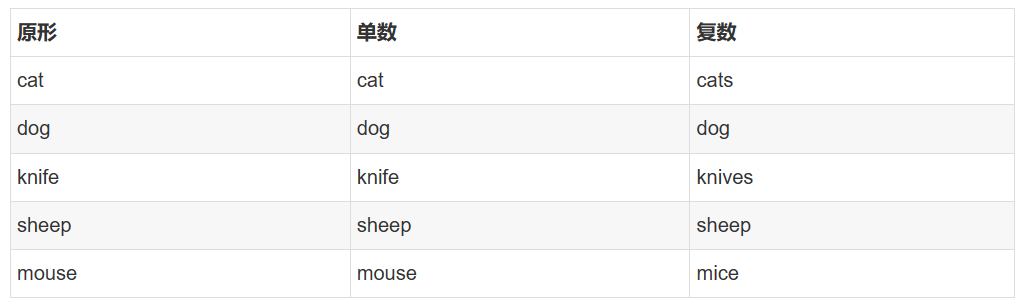
1.3 形态变换
形态变换可以用来形成新词
衍生 = 词干 + 词缀
- friend + -ly = friendly
- un- + friendly = unfriendly
- unfriendly + -ness = unfriendlyness
组合 = 词干 + 词干
- rail + way = railway
2.分词
分词(tokenize)就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作;
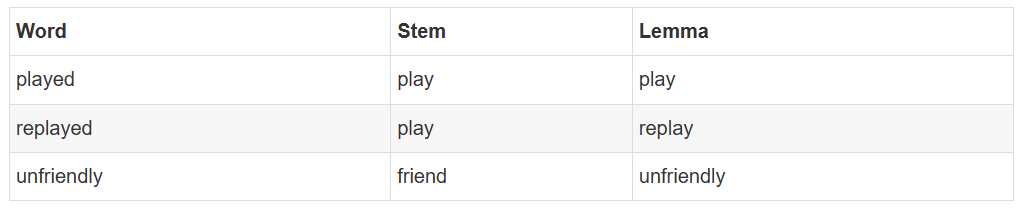
3.词形还原
词形还原主要包含词干化Steamming和原形化Lemmatizing;
stemming是去掉词缀,比如:
play -> play
replayed -> re-play-ed
computerized -> comput-er-ize-d
Lemmatizing是找到原形,其实也就是基于变形或衍生的不同
4.词形标记
以句子为单位,而不是单词为单位,为每一个词标上词形,词形标记通常被用于下游的任务:命名实体识别、依赖解析:
- 默认标注器
- 正则表达式标注器
- 查询标注器
- N-Gram标注器
5.命名实体识别
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等;
二、句法分析
1.语言模型
参考链接:
- 语言模型简介:一起入门语言模型(Language Models) - 知乎 (zhihu.com);
- 语言模型分类:一文读懂“语言模型”-51CTO.COM;
语言模型起源于语音识别(speech recognition),输入一段音频数据,语音识别系统通常会生成多个句子作为候选,究竟哪个句子更合理?就需要用到语言模型对候选句子进行排序;
什么是语言模型呢?一句话,语言模型是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。举俩例子就明白了,比如词序列A:“作者|的|文章|真|水|啊”,这个明显是一句话,一个好的语言模型也会给出很高的概率,再看词序列B:“作者|的|睡觉|苹果|好快”,这明显不是一句话,如果语言模型训练的好,那么序列B的概率就很小很小;
语言模型的定义
定义1(概率角度):假设为中文创建一个语言模型,V表示词典(V={猫,狗,猪…}),w
i∈V,语言模型表示这样一个模型,给定词典V,能够计算出任意词序列w1、w2…wn是一句话的概率p(w1、w2…wn),其中p>=0;定义2(文本生成角度):给定一个短语(一个词组或一句话),语言模型可以生成(预测)接下来的一个词;
根据概率论中的链式法则将p展开可以得到
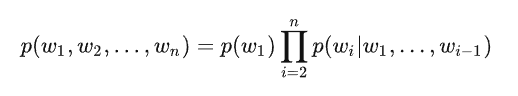
构建语言模型主要分为两个阶段:
- 模型训练:从训练数据(training data)中学习得到语言模型,即从训练样例中统计n-grams的参数,并估计其n-gram的条件概率;
- 模型测试:在给定的测试数据(test data)中评价学习得到的语言模型;
模型测试阶段需要评估一个语言模型的建模质量,一个好的语言模型应该给实际使用的句子打较高的概率;
1.1 n-gram语言模型
关于n-gram语言模型只需要看这个视频即可(这个视频是n-gam的全面介绍,非常推荐):n-gram language model(n-gram语言模型)_哔哩哔哩_bilibili;
n-gram语言模型的局限性:
- 数据稀疏问题:
- 理论上,模型阶数越高越好,但由于数据稀疏,N-gram模型中n达到一定值后,n越大性能反而越差(<6),因此n-gram模型无法用于计算高阶;
- 同时,由于数据稀疏问题,平滑对于n-gram模型的使用很重要,是否有不需要平滑就可以直接用的语言模型?
- 语言相似性:
- 基于符号的词表示方法无法考虑其概率相似度
1.2 神经网络语言模型
因为n-gram语言模型基于符号的词的表示导致其无法用于计算,故介绍了one-hot编码、词的共现矩阵以及词向量模型这些可以用于计算的词的表示方法,下面将介绍一个新的语言模型 – 神经网络语言模型;
三、未完成…
2023/3/29 15:39 这篇文章到此为止吧,参考的资料过多导致知识点太复杂了(几乎没学到什么东西),新开了一篇自然语言的博客,参考自然语言处理_中级 - Tintoki_blog (gintoki-jpg.github.io);