初级项目_电影知识图谱
教程参考链接:
背景知识参考:SimmerChan - 知乎 (zhihu.com);
技术参考(这两篇教程交叉着看具有互补的作用):
- 知识点铺垫:知识图谱学习教程 | 来唧唧歪歪(Ljjyy.com) - 多读书多实践,勤思考善领悟(这个教程中间省略了很多知识点的介绍,而且在我做到第三个部分的时候就已经放弃,代码过时报错太多);
- 完整项目链接:SimmerChan/KG-demo-for-movie: 从无到有构建一个电影知识图谱,并基于该KG,开发一个简易的KBQA程序。 (github.com)(这个完整的项目我都还没开始做,只能之后有时间了再看);
环境配置说明:
mysql的安装是按照尚硅谷教程:02-为什么使用数据库及数据库常用概念_哔哩哔哩_bilibili;
Scrapy其实是可以不用安装的(因为现在爬取百度的难度比较大,可以直接使用教程中的sql文件,如何将sql文件导入mysql中可以直接在百度搜索);
Protege+Graphviz下载安装参考(10条消息) Graphviz安装配置教程(图文详解)_振华OPPO的博客-CSDN博客和(10条消息) Protégé基本教程【Protégé5.5.0版本】_protege软件_喵木木的博客-CSDN博客;
D2RQ下载安装参考(10条消息) D2RQ 的安装和基本使用_d2rq安装_空杯的境界的博客-CSDN博客;
jena下载与安装:(10条消息) jena4.1.0安装及使用_jena安装_长安山南君的博客-CSDN博客和(10条消息) 知识图谱构建5——Jena 和 Fuseki安装与SPARQL查询_jena fuseki_野有蔓兮的博客-CSDN博客;
2023/3/19 23:46 纯看知识点是肯定会晕的,建议是边看知识点然后看不下去了手动实践然后记录问题,再继续查资料实践;
2023/3/21 9:28 先不要跟着唧唧歪歪的项目流程走了,后面写的太乱了…而且每个小项目讲的也很简单,很容易暴毙,初学还是得找教程相对详细的;
2023/4/22 21:56 今天因为要做知识图谱的期末大作业所以回顾了一下之前学习知识图谱的流程,简单总结一下就是唧唧歪歪的项目跟到第三个部分就因为代码版本问题已经没法继续跟下去了,而知乎SimmerChan大佬的无论是文章还是项目都非常的牛,只是可惜时间不足无法继续学习下去。本博客的第一部分主要参考的是SimmerChan和唧唧歪歪的知识点并结合自己在网上查资料等进行的补充,第二部分原计划是跟着唧唧歪歪的从零开始学习知识图谱完整流程跟下来,但是做到基于REFO的知识问答就已经做不下去了,原本是打算第二部分作为一个中间零碎知识点的过渡,便于之后第三部部分直接跟着SimmerChan的项目构建一个完整的电影知识图谱,但是因为时间原因第二部分和第三部分都未能按时完成。关于完整的知识图谱项目,可以关注之后我的知识图谱期末大作业,一个面向暴雨洪涝灾情的知识图谱。
一、知识图谱基础
1.知识图谱概述
计算机一直面临着这样的困境 – 无法获取网络文本的语义信息;
为了让机器能够理解文本背后的含义,我们需要对可描述的事物(实体)进行建模,填充它的属性,拓展它和其他事物的联系,即构建机器的先验知识;
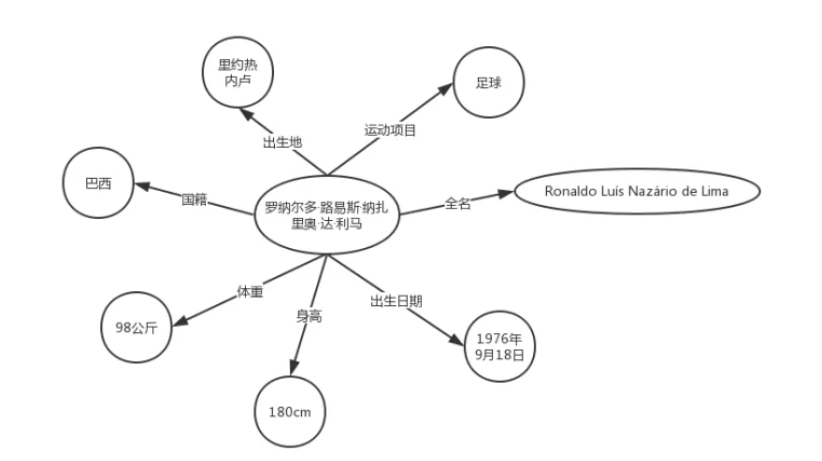
上面的例子中围绕罗纳尔多这个实体进行了相应的拓展,得到了上述知识图,而这对机器来说就相当于拥有了先验知识,当计算机看到罗纳尔多便会进行推理“这是一个名字为Ronaldo Luís Nazário de Lima的巴西足球运动员”;
上面的知识图并不代表知识图谱的实际组织形式(尽管很多文章都喜欢给这种图),之后会介绍知识[图谱形式化的表现形式](#1.2 知识图谱);
1.1 语义网络
知识图谱的本质是为了表示知识,实际上知识图谱的背后的思想可以追溯到另一种知识表示形式 – 语义网络;
语义网络由相互连接的节点和边组成,节点表示概念或者对象,边表示它们之间的关系(is-a关系,part-of关系等);
在表现形式上语义网络和知识图谱相似,但是语义网络更侧重于描述概念之间的关系,知识图谱更偏重描述实体之间的关联
1.2 知识图谱
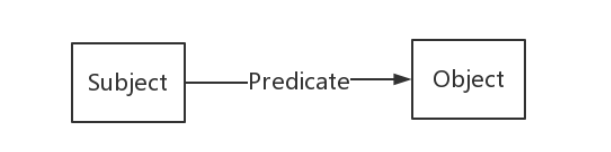
知识图谱并没有一个标准的定义,其中一种定义是说,“知识图谱是由一些相互连接的实体及其属性构成”,即知识图谱是由一条条知识组成,每条知识被表示为一个SPO三元组
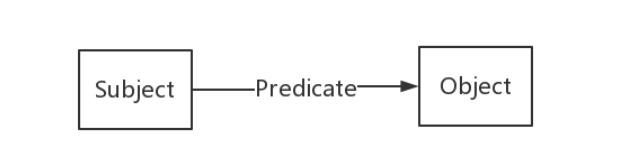
在知识图谱中常使用RDF形式化地表示这种三元关系,RDF图中共有三种类型:
- International Resource Identifiers(IRIs):IRI可以看作URI或URL的推广,在整个网络或者图中唯一定义了一个实体/资源(类似身份证号);
- literals:字面量,可以把它看做是带有数据类型的纯文本 – 借用数据结构中树的概念,字面量类似叶子节点,
出度为0,即不能有指向外部节点的边; - blank nodes:简单来说就是没有IRI和literal的资源,或者说匿名资源;
SPO三元关系中每个部分对应RDF中的约束:
- Subject可以是IRI或blank node;
- Predicate是IRI;
- Object三种类型都可以;
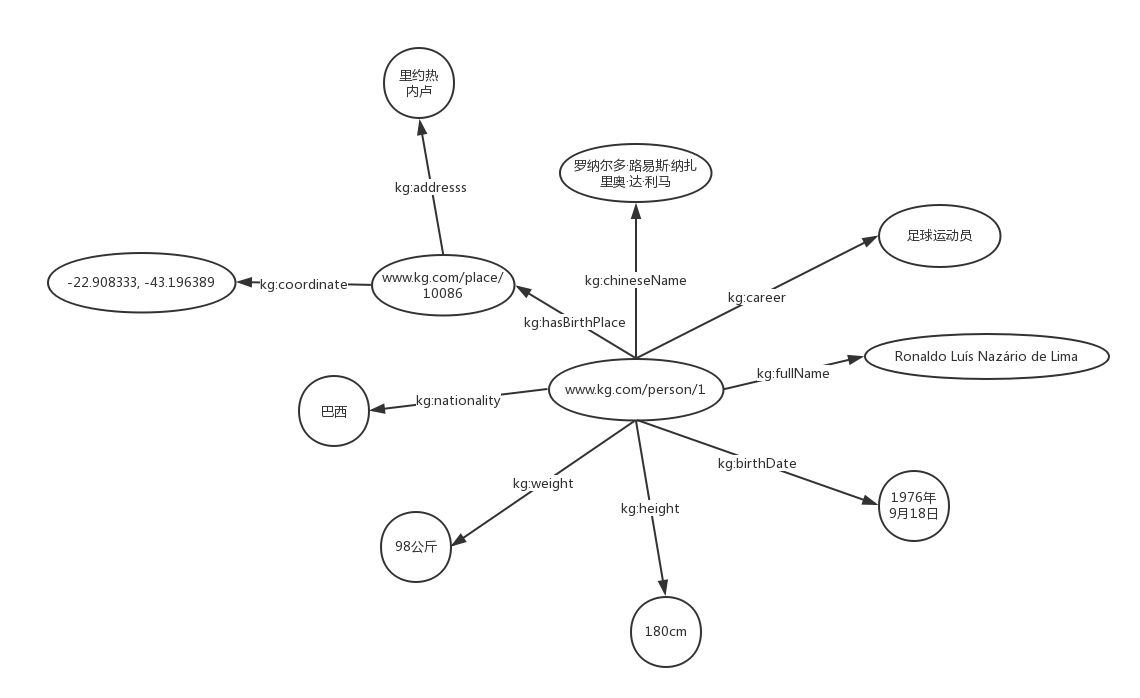
“罗纳尔多的中文名是罗纳尔多·路易斯·纳扎里奥·达·利马”这样一个三元组用RDF形式来表示

- “ww w.kg.com/person/1”是一个IRI,用来唯一的表示“罗纳尔多”这个实体;
- “kg:chineseName”也是一个IRI,用来表示“中文名”这样一个属性;
kg是RDF文件中定义的前缀,用于代替某些较长的字符串,如定义prefix如下
@prefix kg:<http: www>
则kg:chineseName实际就是http: www/chineseName的缩写
这里使用更加形式化的知识图谱对前面的知识图进行表示
2.知识图谱概念
主要介绍语义网络、语义网、链接数据和知识图谱这些概念之间的区别;
2.1 语义网络
语义网络Semantic Network,注意与语义网Semantic Web区分;
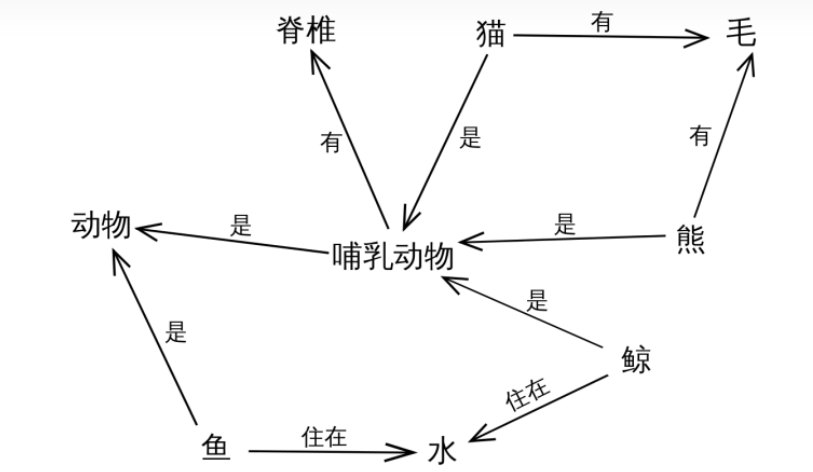
语义网络用相互连接的节点和边表示知识:
- 节点表示对象、概念
- 边表示节点之间的关系
| 优点 | 缺点 |
|---|---|
| 容易理解和展示 | 节点和边的值没有标准,完全是由用户自己定义 |
| 相关概念容易聚类 | 多源数据融合比较困难,因为没有标准 |
| 无法区分概念节点和对象节点 | |
| 无法对节点和边的标签进行定义 |
语义网络可以较容易的让我们理解语义和语义关系,其表达形式简单直白,符合自然。但是因为缺少标准,所以语义网络较难应用于实践;
RDF的提出解决了语义网络的缺点1和缺点2,在节点和边的取值上做了约束,制定了统一标准,为多源数据的融合提供了便利;
RDFS和OWL解决了语义网络无法区分概念和对象的问题(这将在之后详细介绍),即主要解决语义网络的缺点3和缺点4;
2.2 语义网和链接数据
相对于语义网络,语义网和链接数据倾向于描述万维网中的资料和数据之间的关系;
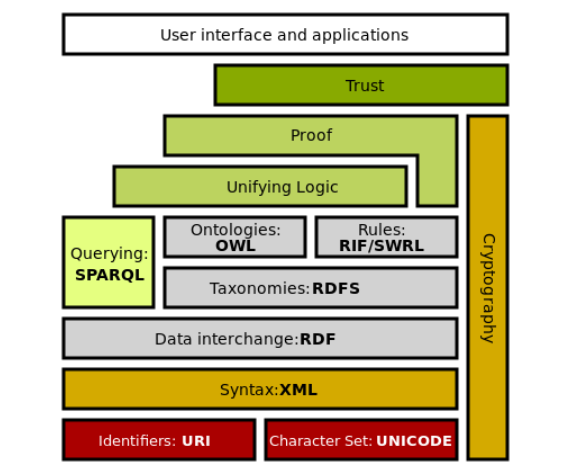
实际上语义网、链接数据还有Web 3.0都是同一个概念,都是指W3C制定的用于描述和关联万维网数据的一系列技术标准,即语义网技术栈;
2.3 知识图谱
知识图谱的更加正式的定义为,由本体作为Schema层,与RDF数据模型兼容的结构化数据集(这个概念不是很好理解可以不用理解)
链接数据和知识图谱最大的区别在于:
- 链接数据强调的是知识图谱之间的相互链接;
- 知识图谱不一定要链接外部的知识图谱,更强调有一个本体层定义实体的类型和实体之间的关系;
2.4 小结
语义网络是个早期概念,是最早尝试用节点和边表示知识的产物,但是其缺点太多了。之后出现RDF,OWL/RDFS等技术重新用节点,边构成的图结构知识表示,就是语义网。语义网克服了语义网络的缺点,成为现在重要的研究对象;
语义网,链接数据,Web3.0本质上是一个概念即Semantic Web,知识侧重点不一样时,会叫不同的名字:
语义网是更官方的叫法,也是学者喜欢的叫法。这个名字侧重描述“互联网上的知识工程”,更侧重数据细化之后的semantic;
链接数据是更简单的叫法,侧重描述数据集之间的链接属性,就是那个web;
知识图谱并没有公认的定义,只需要知道知识图谱是一个图数据结构,包括节点和边,节点上是实体,边表示实体间的关联关系;
3.知识图谱技术
RDF和RDFS/OWL这两种知识图谱的基础技术,是类语义网概念背后通用的技术,而知识图谱只是其中最广为人知的概念;
3.1 RDF
3.1.1 RDF概述
RDF(Resource Description Framework)是一种用于描述Web资源的标记语言,其本质是一个数据模型:
- 资源:所有在Web上被命名且具有URI统一资源描述符的东西,如网页;
- 描述:对资源属性的一个陈述,以表明资源的特性或资源之间的联系;
- 框架:框架是指与被描述资源无关的通用模型,用以包容和原理资源的多样性、不一致性和重复性;
总的来说,RDF定义了一种通用的框架,即资源-属性-属性值的三元组,来描述Web上各种资源;
下面是一个简单的RDF例子:
1 | |
RDF形式上表示为SPO三元组,也称为语句或知识
RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系;
在[知识图谱简介](#1.2 知识图谱)中介绍了RDF节点和边的类型约束;
3.1.2 RDF序列化
如何存储和传输RDF数据?即创建RDF数据集并将其序列化?主要的方式有RDF/XML,N-Triples,Turtle,RDFa,JSON-LD等;
- RDF/XML,顾名思义,就是用XML的格式来表示RDF数据。之所以提出这个方法,是因为XML的技术比较成熟,有许多现成的工具来存储和解析XML。然而,对于RDF来说,XML的格式太冗长,也不便于阅读,通常不会使用这种方式来处理RDF数据;
- N-Triples,即用多个三元组来表示RDF数据集,是最直观的表示方法。在文件中,每一行表示一个三元组,方便机器解析和处理;
- Turtle,应该是使用得最多的一种RDF序列化方式了。它比RDF/XML紧凑,且可读性比N-Triples好;
- RDFa, 即“The Resource Description Framework in Attributes”,是HTML5的一个扩展,在不改变任何显示效果的情况下,让网站构建者能够在页面中标记实体,像人物、地点、时间、评论等等。也就是说,将RDF数据嵌入到网页中,搜索引擎能够更好的解析非结构化页面,获取一些有用的结构化信息;
- JSON-LD,即“JSON for Linking Data”,用键值对的方式来存储RDF数据;
3.2 RDFS/OWL
RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系或属性 – RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述;
RDFS(模式语言schema language)和OWL(本体语言ontology language)解决了RDF表达能力有限的困境;
RDFS/OWL可以看作是RDF的“衣服”,因为它们都是用来描述RDF数据的,RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类定义及其属性的定义;
3.2.1 RDFS
RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类似的类定义及其属性的定义
- RDFS不区分对象属性(object property,实体和实体之间的关系)和数据属性(data property,实体和literal字面量的关系)
下面主要介绍RDFS中几个比较重要的词汇
rdfs:Class. 用于定义类。
rdfs:domain. 用于表示该属性属于哪个类别。
rdfs:range. 用于描述该属性的取值类型。
rdfs:subClassOf. 用于描述该类的父类。比如,我们可以定义一个运动员类,声明该类是人的子类。
rdfs:subProperty. 用于描述该属性的父属性。比如,我们可以定义一个名称属性,声明中文名称和全名是名称的子类。
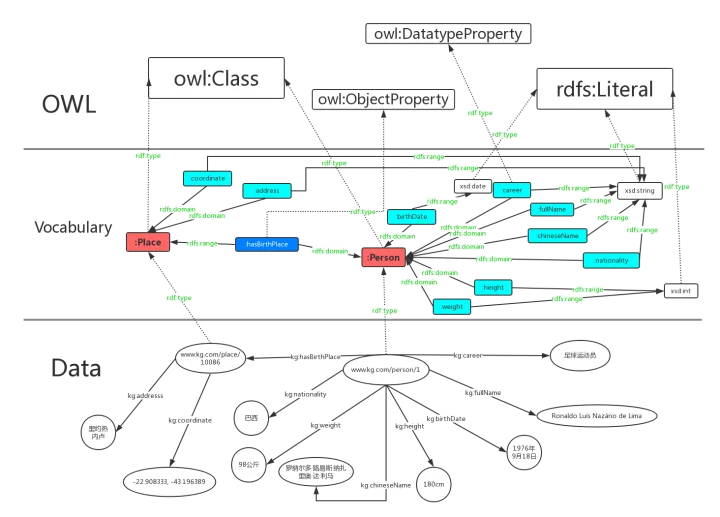
RDF和RDFS/OWL在知识图谱中代表的层面各不相同
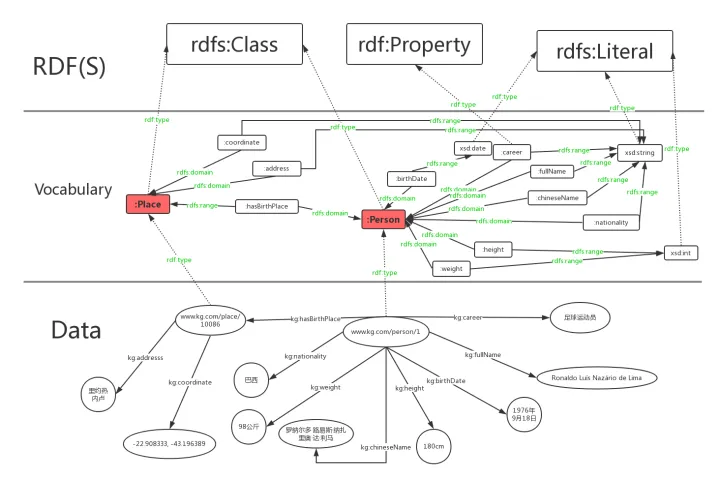
Data层是用RDF对罗纳尔多知识图的具体描述,Vocabulary是自定义的一些词汇(类别,属性),RDF(S)则是预定义词汇,从下到上是一个具体到抽象的过程;
图中用红色圆角矩形表示类,绿色字体表示rdf:type,rdfs:domain,rdfs:range三种预定义词汇,虚线表示rdf:type这种所属关系;
3.2.2 OWL
RDFS是RDF词汇的拓展,OWL是RDFS的拓展,添加了额外的预定义词汇;
schema层的描述语言换为OWL后,层次图表示为
owl中的常用词汇如下:
描述属性特征的词汇
owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
owl:equivalentClass. 表示某个类和另一个类是相同的。
owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
owl:sameAs. 表示两个实体是同一个实体。
关于OWL和OWL2的更多信息参考知识图谱基础 之 二.知识表示与知识建模 | 来唧唧歪歪(Ljjyy.com) - 多读书多实践,勤思考善领悟;
3.3 D2RQ
文章参考:
- 知识图谱学习与实践(6)——从结构化数据进行知识抽取(D2RQ介绍) - cooldream2009 - 博客园 (cnblogs.com);
- (11条消息) D2R使用方法1_d2rmm_smallsmallbright的博客-CSDN博客;
将结构化数据转换为RDF有两种主要方式,一种是直接映射,本质上是通过编写启发式规则将数据库中的表转换为RDF三元组(将表结构映射到对应的三元组中),另一种是使用D2RQ;
D2RQ工具是一种将结构化数据转换成RDF三元组的工具,可以将Mysql的数据映射到在protege中定义的本体上,支持使用SPARQL查询非RDF数据库;
D2RQ平台的组成:
D2RQ映射语言,一种声明的映射语言,用于描述本体和关系数据模型之间的关系;
D2RA引擎,一种服务于Jena语义网工具库插件,使用映射(即使用一个可定制的D2RQ Mapping文件)重写对数据库的SQL访问的Jena API调用,并且将查询结果传递给框架高层;
D2R服务器,一个提供调试用的链接数据视图和HTML视图的HTTP服务器,还提供了一个SPARQL协议endpoint数据接口;
3.4 SPARQL
SPARQL是RDF的查询语言,它基于RDF数据模型,可以对不同的数据集撰写复杂的连接,同时还被所有主流的图数据库支持;
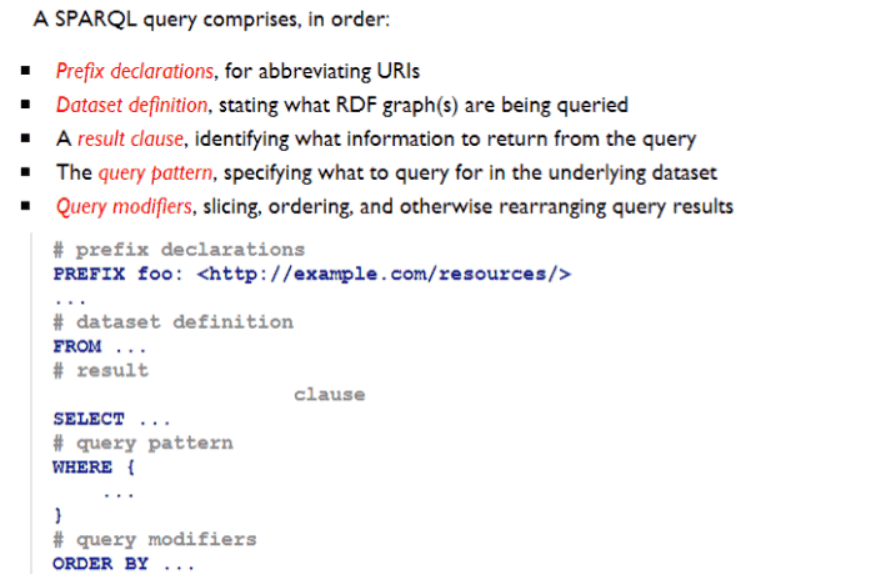
从语法上结构上来看,SPARQL和SQL语言还是有一定的相似性的。比较重要的区别有:
- 变量,RDF中的资源,以“?”或者“$”指示;
- 三元组模板 (triple pattern), 在WHERE子句中列示关联的三元组模板,之所以称之为模板,因为三元组中允许变量;
- SELECT子句中指示要查询的目标变量;
3.5 Apache Jena
Jena是一个开源的Java语义网框架,用于构建语义网和链接数据应用,主要组件有:
- TDB:用于存储RDF的组件
- Jena提供了RDFS、OWL和通用规则推理机
- Fuseki:Jena提供的SPARQL服务器,也就是SPARQL endpoint
3.6 Protege
protege是一个基于java语言开发的本体编辑和知识获取软件,也被称为本体开发工具,是基于知识的编辑器;
protege是一个本体编辑和知识获取软件;
Protégé提供了本体概念类,关系,属性和实例的构建,并且屏蔽了具体的本体描述语言,用户只需在概念层次上进行领域本体模型的构建;
Protege的主要用途:
- 类模拟(Class modeling):protégé提供了一个图形化用户界面来模拟类(领域概念)和它们的属性及关系;
- 实例编辑(Instance editing):从这些类中,protégé自动产生交互式的形式,全用户或领域专家进入的有效实例成为可能;
- 模型处理(Model processing):protégé有一个插件库,可以定义语义、解答询问以及定义逻辑行为;
- 模型交换(Model exchange):最终的模型(类和实例)能以各种各样的格式被装载和保存,包括XML、UML和资源描述框架RDF;
二、电影知识图谱
前面已经介绍了实际在构建知识图谱的过程中会涉及的一些技术,下面就简单的举一个例子介绍构建一个电影知识图谱的大致流程;
1.结构化数据获取
1.1 Mysql建库
库内包含 演员、电影、电影类型、演员->电影、电影->类型 五张表:
- 演员 :爬取内容为 ID, 简介, 中文名,外文名,国籍,星座,出生地,出生日期,代表作品,主要成就,经纪公司;
- 电影 :ID,简介,中文名,外文名,出品时间,出品公司,导演,编剧,类型,主演,片长,上映时间,对白语言,主要成就;
- 电影类型: 爱情,喜剧,动作,剧情,科幻,恐怖,动画,惊悚,犯罪,冒险,其他;
- 演员->电影: 演员ID, 电影ID;
- 电影-> 类型: 电影ID, 类型ID;
直接按照下面的建表语句创建数据库和数据表即可(cmd或者Navicat的命令列界面皆可进行创建)
1 | |
创建完成后可以使用如下语句查看创建的数据库和对应的表
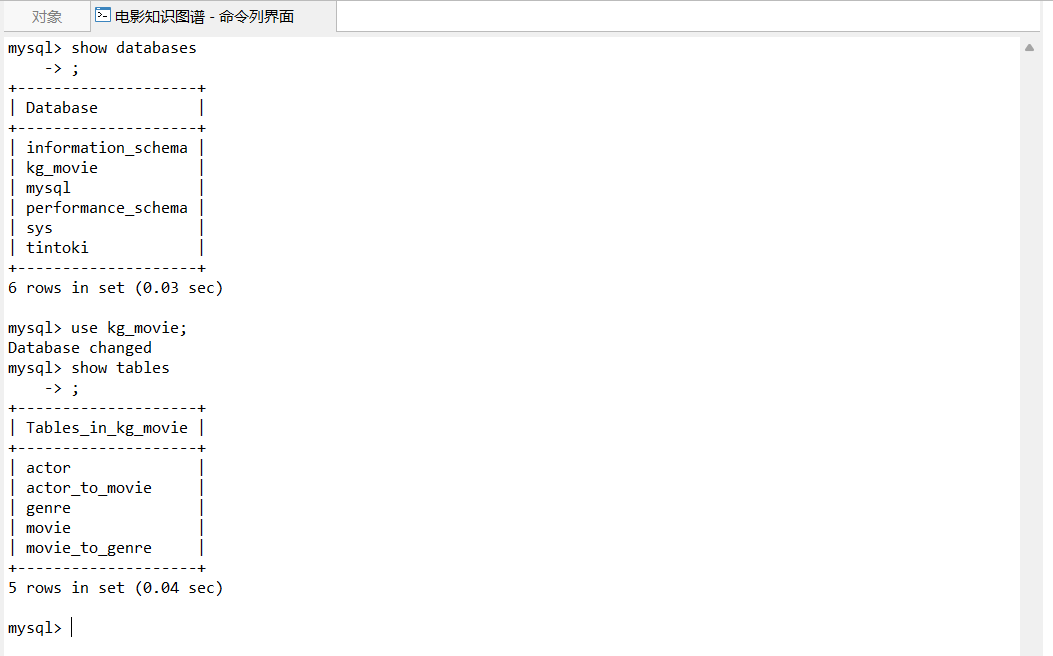
1.2 导入sql文件
教程中使用了scrapy框架对百度百科进行爬取,爬取电影类数据,包含电影22219部,演员13967人,演员电影间联系1942个,电影与类别间联系23238,电影类别10个,教程中已经给出了相关的数据集,所以无需重复爬取,直接在Navicat中导入即可
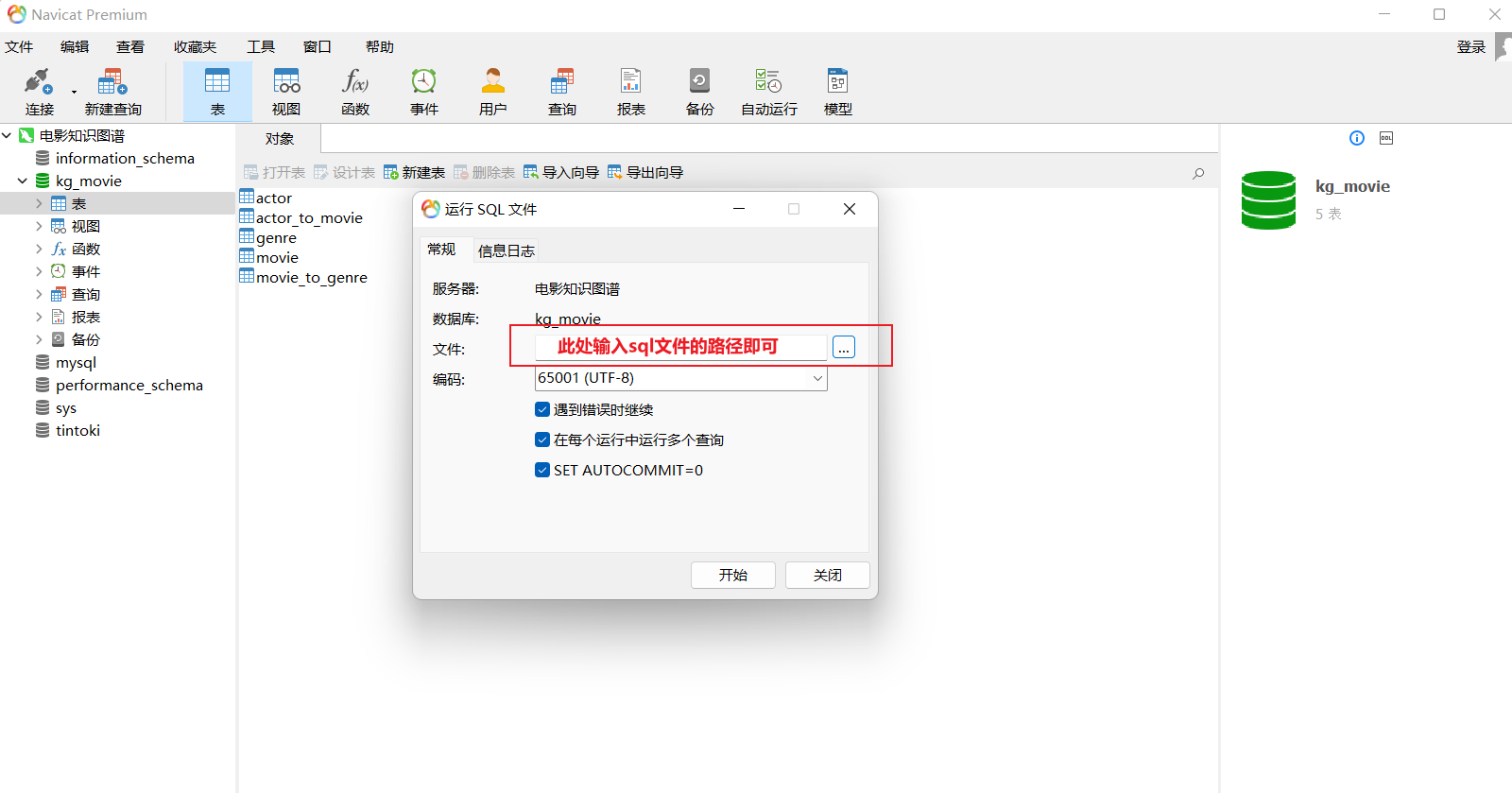
1.3 小结
第一部分对半结构化数据即百度百科的电影数据进行了爬取并将其保存在Mysql数据库中,这意味着我们获得了一份结构化数据;
2.数据处理
2.1 结构化数据转为RDF
将结构化数据转换为RDF有两种主要方式,一种是直接映射,本质上是通过编写启发式规则将数据库中的表转换为RDF三元组(将表结构映射到对应的三元组中),另一种是使用D2RQ;
这里只介绍使用D2RQ的方式,D2RQ主要功能就是将查询语言SPARQL通过mapping文件(R2RML-kit)将其转换为SQL语句进而在关系数据库上进行查询;
在d2rq的目录下使用
1 | |
命令可以创建默认mapping映射文件,而实际上还需要根据定义的本体对mapping文件进行修改:
将vocab前缀省略,使得表达简练
将默认的映射词汇改为本体中的词汇
- 在处理外键的时候要注意当前编辑的属性的domain和range,belongsToClassMap是domain,refersToClassMap是range
编写bat文件可以实现上述要求的对mapping文件的自动修改
1 | |
执行上述bat程序后还需要手动对mapping文件(.ttl)中的内容进行修改
1 | |
2.2 启动D2R-Server(在线)
D2R Server 是一个将关系数据发送到语义网的工具,该工具可以让RDF浏览器或HTML浏览器访问数据库,并使用SPARQL查询语句查询数据库;
前面使用默认脚本生成了D2RQ Mapping(Turtle格式的RDF文档),接着希望通过Mapping文件对关系数据库的数据进行转换和访问,主要有两种方式,一种是通过 D2R Server 自动调用 D2RQ Engine 对数据进行转换访问,另一种在自己的 Java application 中通过 Jena/Seasame 的 API 去使用 D2RQ Engine;
使用D2R-Server默认的数据处理和访问方式浏览链接数据的方式,只需要在D2R目录下执行命令
1 | |
然后在 Web 浏览器中访问 http://localhost:2020, 便可以默认的 HTML 浏览器、DF 浏览器以及 SPARQL 查询端对数据进行访问;
2.3 RDF转存为Ntriples(离线)
在d2rq目录下执行
1 | |
可以将RDF数据转存为Ntriples格式的文件(.nt)(参考[RDF序列化](#3.1.2 RDF序列化))

2.4 Ntriples转为TDB
TDB 是Jena用于存储RDF的组件,属于存储层面的技术;
在jena的bat目录下使用如下命令
1 | |
将Ntriples格式的数据加载到TDB中(也可以认为是使用TDB格式存储RDF数据)
2.5 启动jena fuseki(在线)
进入fuseki目录下,运行命令:
1 | |
注意:–loc的参数是前面Ntriples转换为TDB中TDB数据库的路径,kg_movie是显示的数据库名
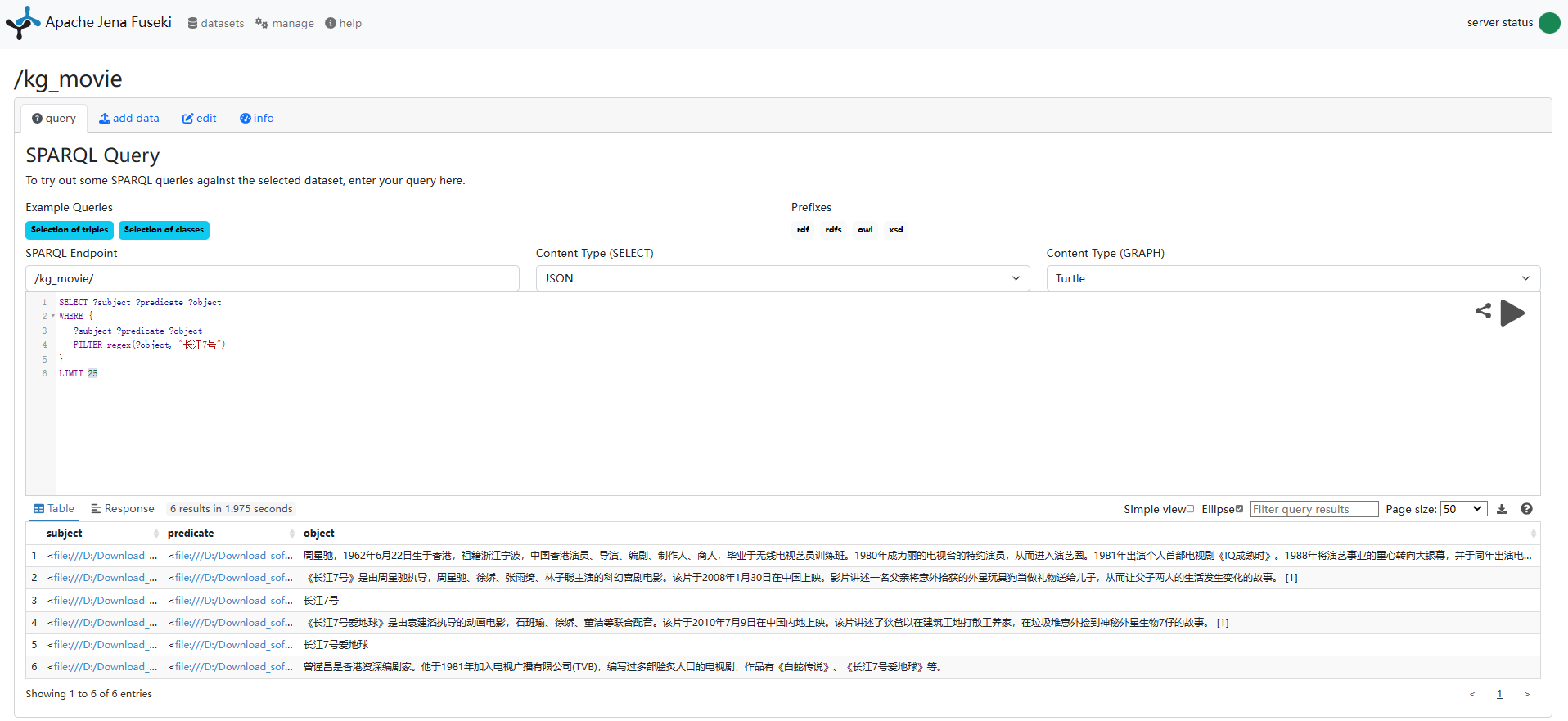
启动后,访问Fuseki网站地址: http://localhost:3030/可以直接在网页中使用SPARQL进行查询(也可以把自然语言转换为 SPARQL 模板后进行查询)
启动成功后的shell界面
在网页中使用SPARQL查询界面
3.本体建模
参考文章:
- 概述:实践篇(一):数据准备和本体建模 - 知乎 (zhihu.com);
- 详细:(12条消息) Protege 使用教程(详细讲解 入门简单易懂)_protege软件_星川皆无恙的博客-CSDN博客;
在Apache Jena fuseki服务器的配置文件中,可以指定本体,从而实现推理机制;为了使得Jena能够在目标本体上进行推理,需要使用protege生成自定义的本体文件;
本体的构建方式主要有两种:自顶向下和自底向上
- 开放域知识图谱的本体构建通常用自底向上的方法,自动地从知识图谱中抽取概念、概念层次和概念之间的关系 – 因为开放的世界太过复杂,用自顶向下的方法无法考虑周全,且随着世界变化,对应的概念还在增长;
- 领域知识图谱多采用自顶向下的方法来构建本体。一方面,相对于开放域知识图谱,领域知识图谱涉及的概念和范围都是固定或者可控的;另一方面,对于领域知识图谱,我们要求其满足较高的精度;
这里采用自顶向下的方法来构建本体结构,使用的工具是protege,需求是使用Protege软件构建实体关系最终生成OWL文件;
3.1 建立IRI
(1)打开protege后在Ontology IRI中填写新建本体资源的IRI(自定义符合标准即可)
3.2 类别设计
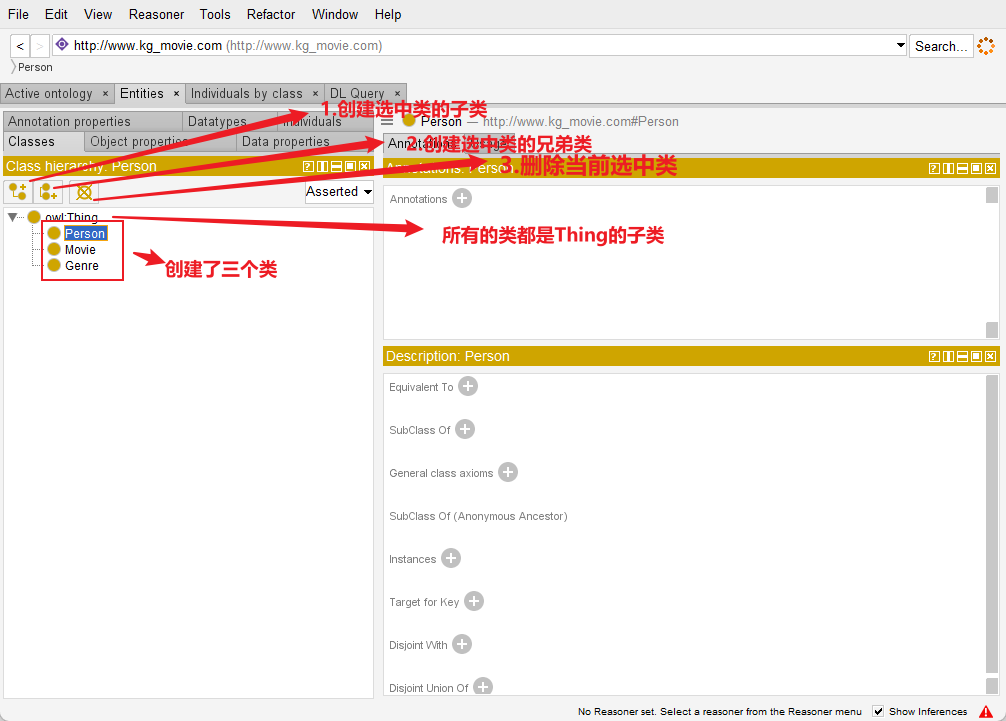
(1)点击“Entities”tab标签,选择“Classes”标签,在这个界面,创建电影知识图谱的类/概念;
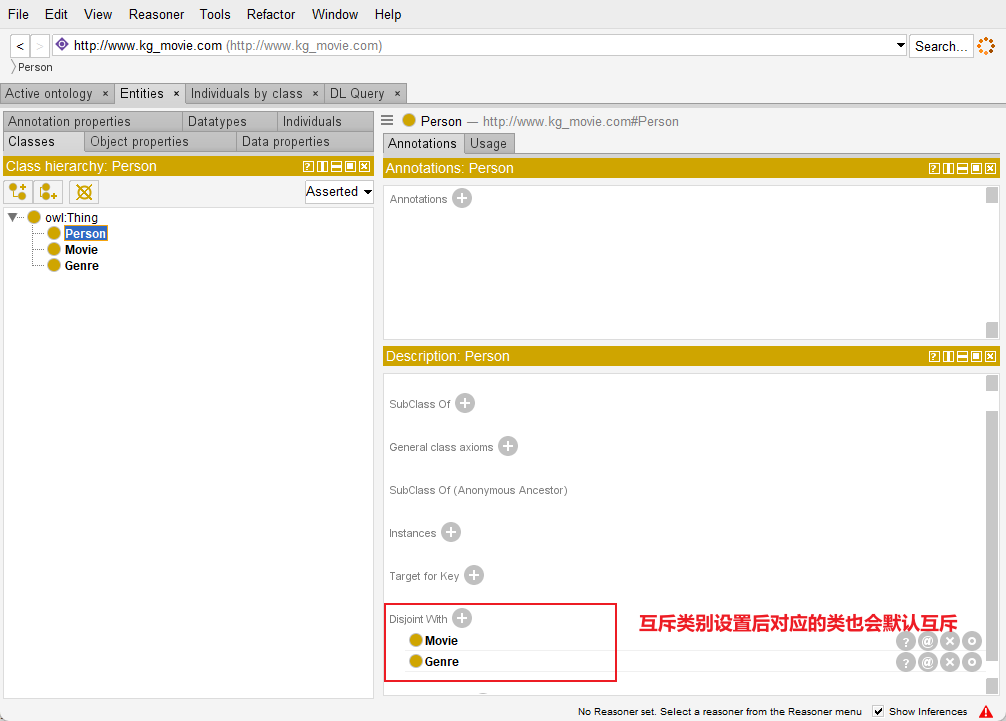
(2)设置互斥类别(依次对三个属性进行设置)
3.3 对象属性设计
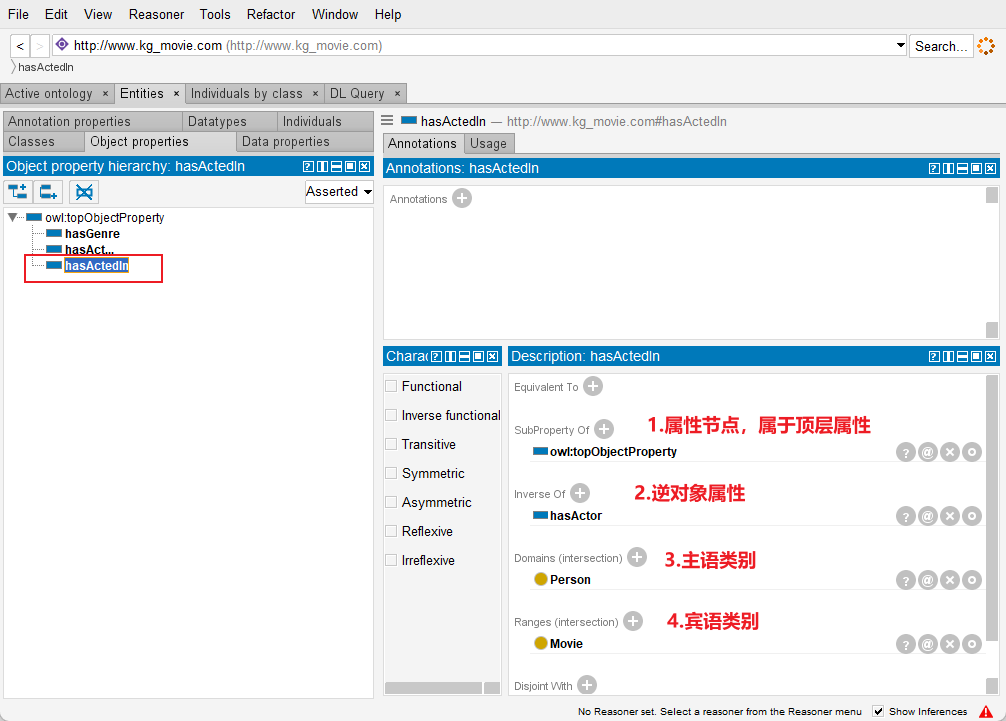
(1)切换到”Object Properties”页面,在此界面创建类之间的关系,即对象属性,这里创建了三个对象属性分别是hasActedIn、hasActor、hasGenre
- hasActedIn:某人参演了某电影
- hasActor:某电影的演员
- hasGenre:某电影的题材
(2)点击hasActedIn属性进行属性配置并依次对三个对象属性进行配置
3.4 数据属性设计
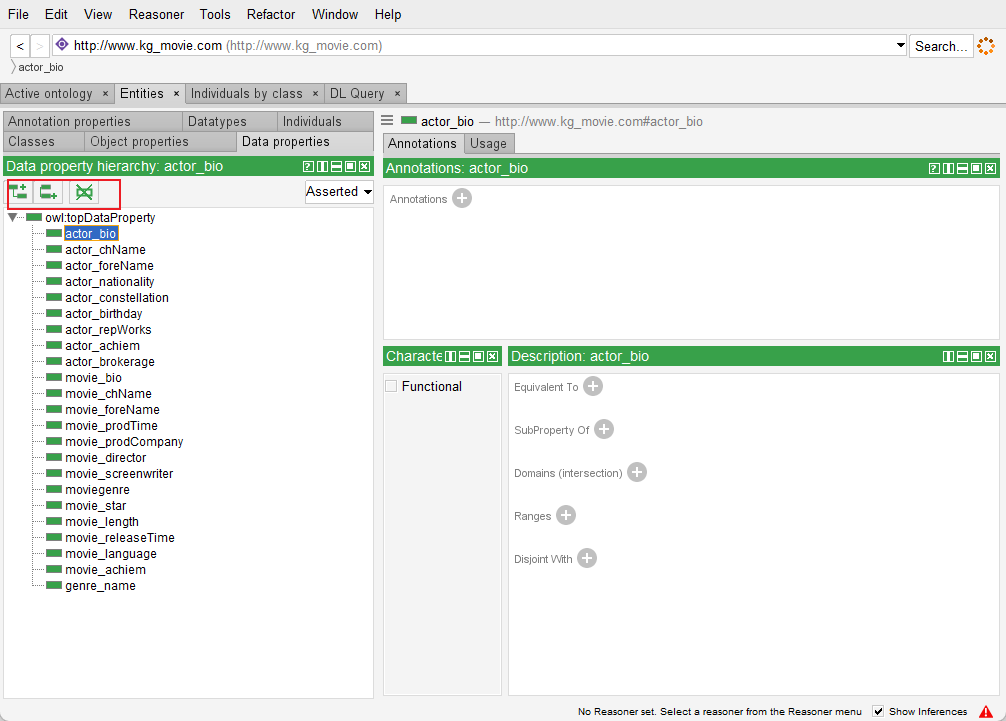
(1)最后切换到”Data properties”,在该界面创建类的属性,即数据属性,需要注意数据属性相当于树的叶子节点,只有入度,而没有出度;
点击DataProperty,建立具体的子属性类别,具体类别按照数据库中的表单进行设计即可;
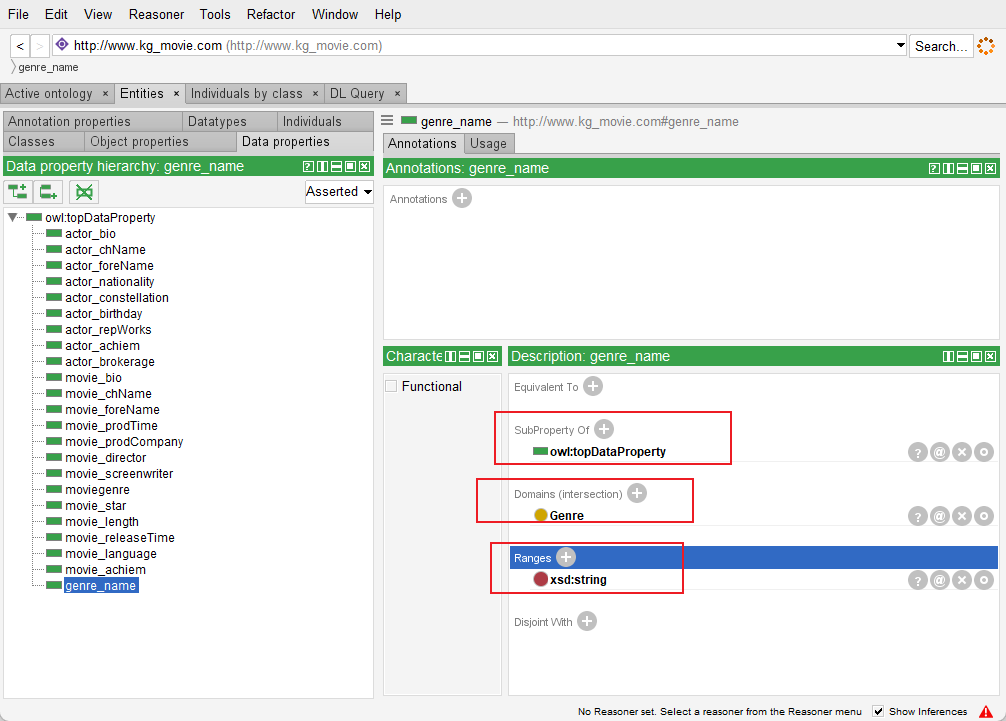
(2)为具体的属性类别添加描述限制(对其他具体属性类别依次进行类似描述限制)
3.5 查看关系图
首先配置ontoGraf,如依次勾选 Window – Tabs – OntoGraf,接着点击OntoGraf进行查看
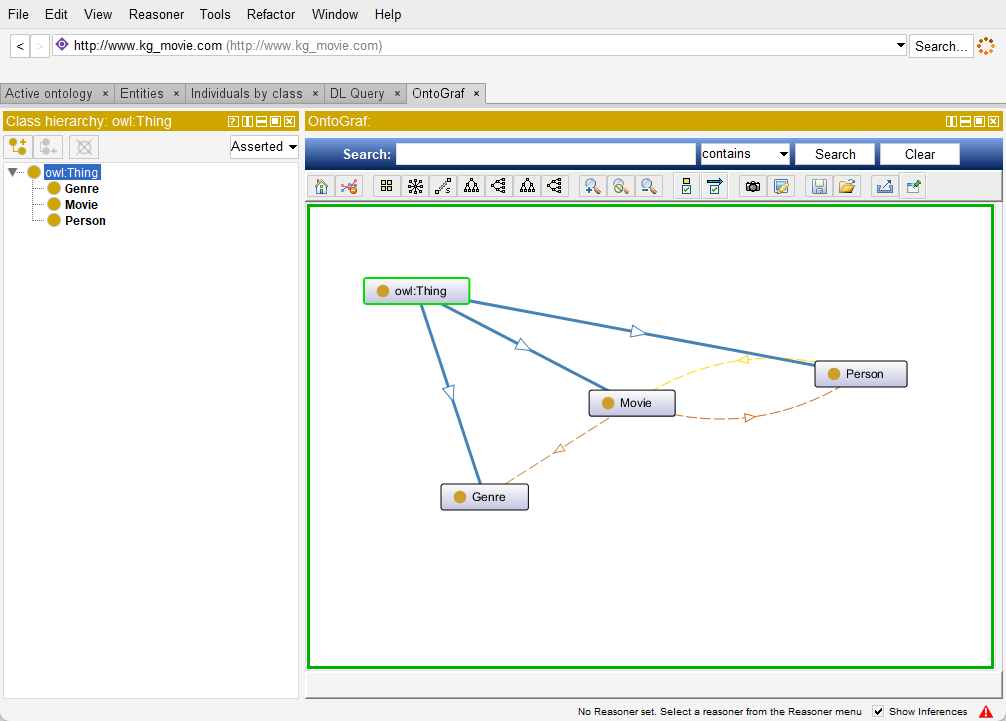
最后保存文件,依次选择File – Save As ,对话框选择Turtle Syntax类型保存即可;
4.基于REFO的知识问答
关于REFO和RE的区别参考:Python REfO包_程序模块 - PyPI - Python中文网 (cnpython.com);
基于REFO的知识问答原理:
- 首先通过REFO提供的匹配能力,在输入的自然语言问题中进行匹配查找,如果找到预先设定的词或词性组合,那么就认为该问题与这个词或词性组合匹配;
- 预先设定的一个词或词性组合对应着一个SPARQL查询模板,于是借助REFO完成了自然语言到查询模板的转换;
- 得到查询模板后,利用Jena fuseki 服务器提供的端口进行查询得到返回的结果;
4.1 代码结构
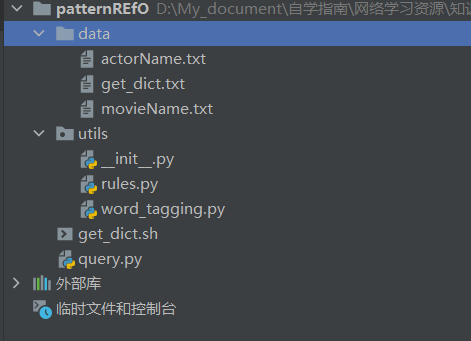
data目录存放由数据库导出生成的字典文件,用于扩展jieba分词,由 get_dict.sh 生成;
utils目录存放查询预处理模块:
- word_tagging.py 用于将词的文本和词性打包;
- rules.py 内定义各种规则并将自然语言转换为SPARQL查询语言,最终以JSON返回结果;
query.py 为程序入口,运行它来进行简单的KBQA;
4.2 小结
这个小节的项目做崩了,总结一下为什么:
- 不要贪小便宜去使用以前的环境,以前配置的虚拟环境不仅有许多冗余的包,而且也可能缺少新的项目所需要的包,并且库之间的版本依赖关系也可能因为新加入的或重复下载的包被打乱;
- 不要随便去修改除了本项目以外的其他文件(如包文件的
__init.py__),很可能修改一时很爽,但改完项目还是跑不起来到时候后悔药都没有(因为那些重要的配置文件不是自己写的也不知道怎么改回去);- 解决办法就是把这个库删了重新从网上下载一遍