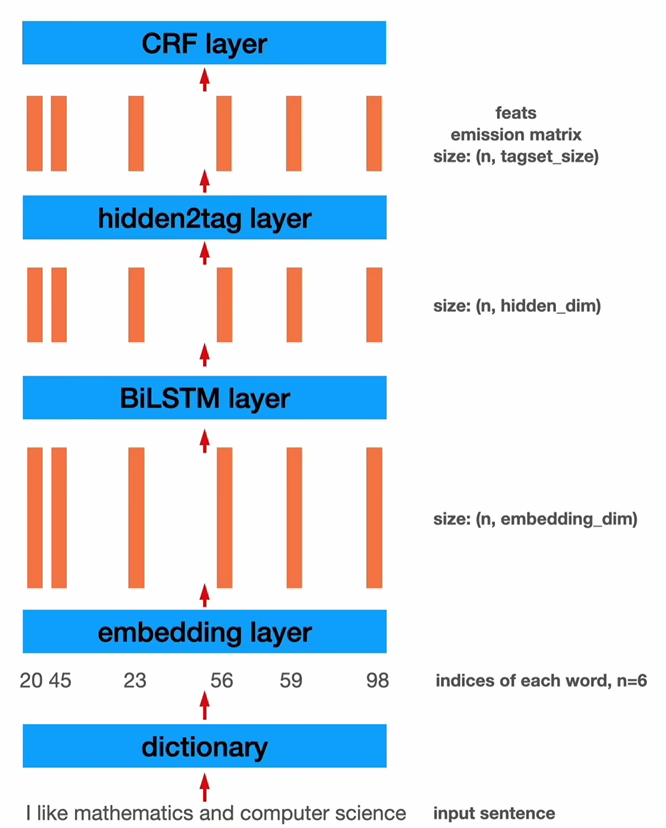
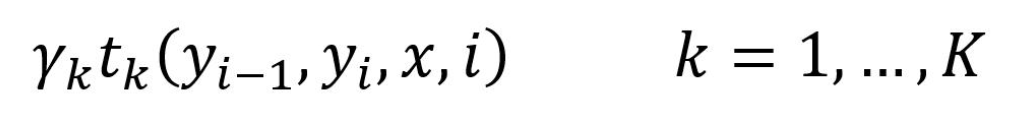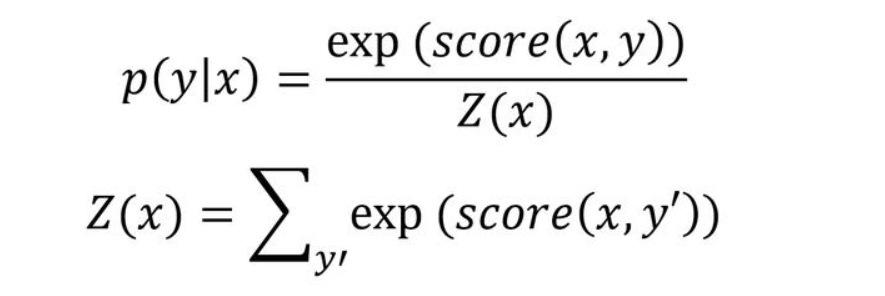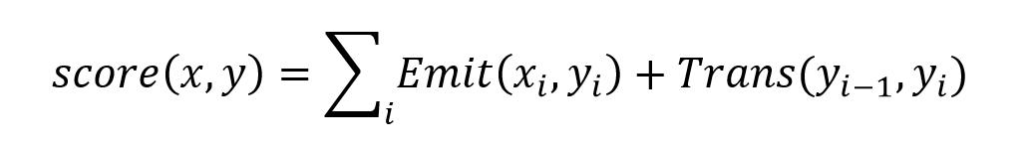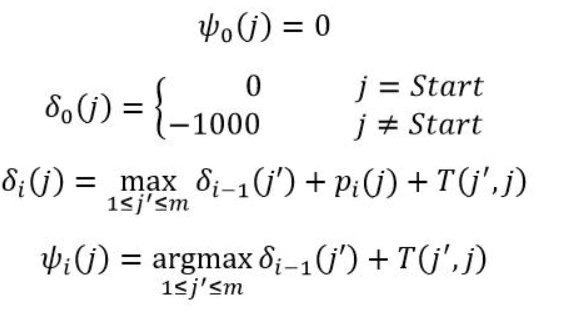项目基本要求
内容:基于给定的暴雨洪涝中文语料库,利用已人工标注的样本作为训练集和测试集,基于深度学习和预训练模型,编程实现暴雨洪涝中文文本中的发生时间和发生地点两类实体的识别和抽取。
数据集:见附件
完成目标:
作业要求:
源代码请附加Readme文件说明使用的主要包的版本,以及其他可能影响代码运行的事项。
PS:改代码并不是说换一换变量名称什么的就OK了,实际上需要修改的是使用的模型或者一些输出;
参考链接:
一、背景 1.命名实体识别概述 知识抽取是实现自动化构建大规模知识图谱的重要技术,其目的在于从不同来源、不同结构的数据中进行知识提取并存入知识图谱中(详情参考知识图谱 - Tintoki_blog (gintoki-jpg.github.io) );知识抽取同样属于NLP的研究领域,指自动化地从文本中发现和抽取相关信息,并将多个文本碎片中的信息进行合并,将非结构化数据转换为结构化数据;
非结构化数据的知识抽取包括命名实体识别、关系抽取及事件抽取,本项目主要针对其中的命名实体识别;
命名实体识别是指从文本中检测出命名实体,并将其分类到预定义的类别中,例如人物、组织、地点、时间等;一般情况下,命名实体识别是知识抽取其他任务的基础;
想要从文本中进行实体抽取,首先需要从文本中识别和定位实体,然后再将识别的实体分类到预定义的类别中去 – 这也是本项目需要实现的,即实体的识别和抽取;
实体抽取的方法分为三类:基于规则的方法、基于统计模型的方法和基于深度学习的方法,因为规定使用深度学习,所以我们这里仅介绍该类方法,另外两类可参考小知识 | 知识图谱:知识抽取之命名实体 (qq.com) ;
1.1 基于深度学习的方法 与传统统计模型相比,基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征;
目前,用于命名实体识别的神经网络主要有卷积神经网络(ConvolutionalNeural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)以及引入注意力机制(AttentionMechanism)的神经网络;一般地,不同的神经网络结构在命名实体识别过程中扮演编码器的角色,它们基于初始输入以及词的上下文信息,得到每个词的新向量表示;最后再通过CRF模型输出对每个词的标注结果;
一些比较经典的用于实体识别抽取的模型有
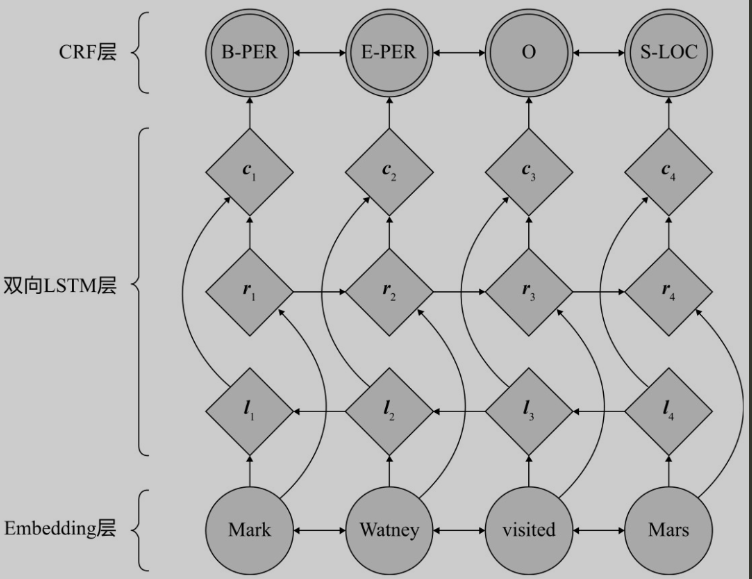
LSTM-CRF命名实体识别模型
该模型使用了长短时记忆神经网络(Long Shot-Term Memory NeuralNetwork, LSTM)与CRF相结合进行命名实体识别。
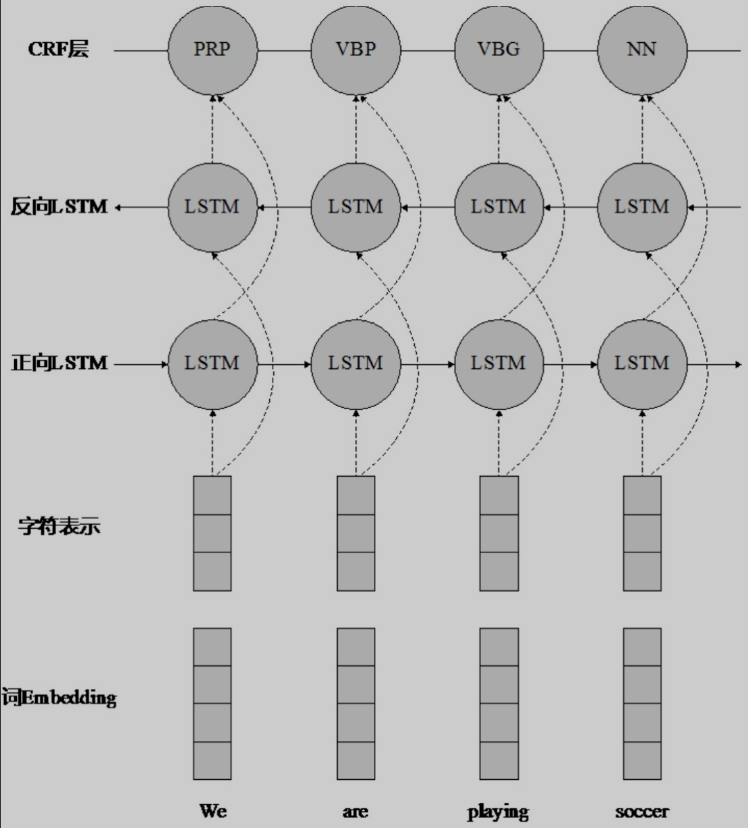
LSTM-CNNs-CRF序列标注模型框架
该模型与 LSTM-CRF 模型十分相似,不同之处是在Embedding 层中加入了每个词的字符级向量表示。
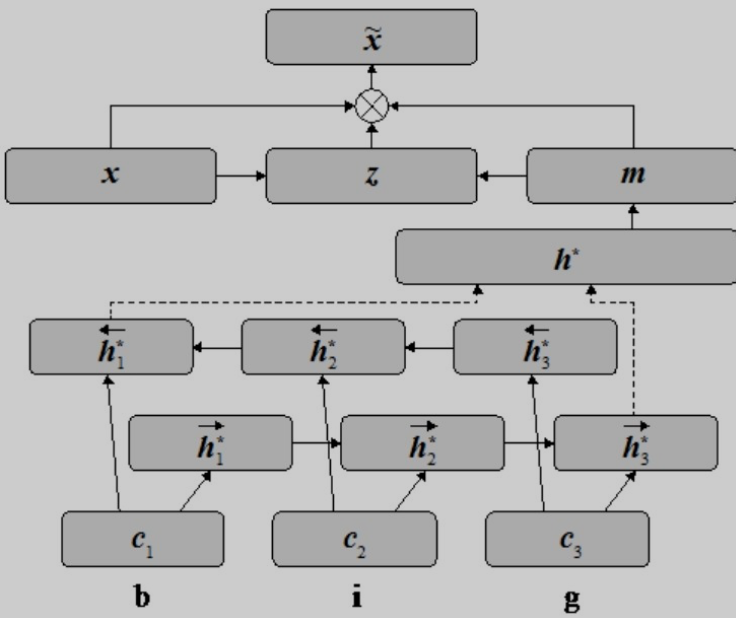
基于注意力机制的词向量和字符级向量组合方法
注意力机制可以帮助扩展基本的编码器-解码器模型结构,让模型能够获取输入序列中与下一个目标词相关的信息。
基于注意力机制的词向量和字符级向量组合方法认为除了将词作为句子基本元素学习得到的特征向量,命名实体识别还需要词中的字符级信息。因此,该方法除了使用双向 LSTM 得到词的特征向量,还基于双向LSTM计算词的字符级特征向量。
2.中文命名实体识别 2.1 中文分词 中文命名实体抽取需要先了解基于字标注的中文分词,简单的中文分词我们知道形式如下
基于字标注的中文分词结果如下
基于字标注的意思就是给每个字都进行标注,上述标注的类型主要有四种
词首即一个词的开始,词尾即一个词的结束,词中表示词中间的词,假如该词只有一个字则用单字表示;
2.2 数据处理 实体识别和中文分词类似,就是将不属于实体的字用O标注,把实体用BME规则标注,最后按照BME规则将实体提取出来即可;
下面是一个实体识别的例子
每个实体用都用大括号括了起来,并标明实体类别(标注方式并不需要严格遵守这样的键值格式,只要能将实体识别并提取出来即可)
因为下面的例子都是基于玻森数据提供的命名实体识别数据,与我们项目本身提供的数据集可能存在一些差别,所以先简单介绍一下玻森数据集,主要包含以下6个实体类别
数据处理首先要做的就是把原始数据按照BMEO的规则变成字标注的形式便于模型训练,上述文本按字标注后的结果如下(可以看出这不仅仅只是简单的字标注分词,同时结合了实体类别)
接着习惯性的,按照标点符号将一个长句子分为多个短句子(逗号、句号、双引号等),结果如下
与先前新闻文本分类相同,因为无法直接将文本类型的数据放入模型训练,因此需要先建立一个word2id词典,将每个汉字转换成id(最直观的做法就是按照数据集中中汉字出现的次数进行排序后赋id,id从1开始)
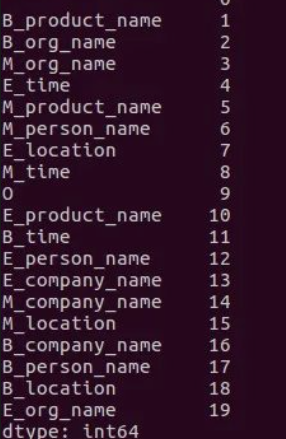
将汉字转换为id后,再建立一个tag2id词典,将每个字标注的类型转换成id(这里的id从1开始,顺序可以自定义,因为3*6+1所以一共19个tag对应的id)
拥有了word2id和tsg2id之后,就可以将先前按照标点切分的短句以一一对应的顺序将汉字和每个字的标签转换为id,分别存放在两个数组中,将该数组保存在同一个pkl文件中,这样模型使用时候就可以直接读取,不用每次都处理数据了;
这里习惯把每一句话都转换成一样的长度(这与先前新闻文本分类是一个道理),这个长度可以自定义(最好统计后再确定),比它长的就把后面舍弃,比它短的就在后面补零。
比如下面是长度为10的文本对应的word2id和tag2id
1 2 [132,45,0 ,456,432 ,8,654,3 ,0 ,0 ]1,2,2,2 ,3,4,5,5 ,0 ,0 ]
Q:为什么这里是按照字的粒度而不是词的粒度划分?词向量和字向量的区别在哪里?
A:词向量和字向量都是自然语言处理中常用的表示文本的方式,但它们的表示粒度不同。
词向量(Word Embedding)是将每个单词表示为一个向量(因此使用词向量之前需要进行分词),这个向量通常是一个固定长度的实数向量,每个维度代表着该单词在不同语义维度上的分布情况。词向量的好处是能够捕捉到单词之间的语义关系,例如在词向量空间中,语义相近的单词的向量距离较近。常用的词向量算法有word2vec、GloVe等。
字向量(Character Embedding)则是将每个字母或字符表示为一个向量。相比于词向量,字向量的表示粒度更细,可以更好地捕捉词语的构成和形态等信息,特别适用于中文和其他一些没有明确词汇边界的语言。常用的字向量算法有FastText、CharCNN等。
因此,词向量适用于处理基于单词的任务,如文本分类、情感分析、机器翻译等,而字向量适用于处理基于字符的任务,如中文分词、命名实体识别等。
综上,对于本次任务使用字向量更合适。
3.BiLSTM-CRF介绍 参考链接:彻底了解 BiLSTM 和 CRF 算法-pytorch bilstm crf (51cto.com) ;
BiLSTM-CRF是一种序列标注模型,常用于自然语言处理领域的命名实体识别、词性标注等任务。其全称为Bidirectional Long Short-Term Memory - Conditional Random Field,结合了双向长短时记忆网络(Bidirectional LSTM)和条件随机场(CRF)两个模型的优点,能够克服单向LSTM模型无法处理双向上下文信息的问题,同时能够利用CRF模型的全局标注优化策略来提高模型的准确性。
BiLSTM模型是一种递归神经网络,它可以学习长文本序列中的特征,具有前向和后向两个方向的传播。与传统的单向LSTM模型相比,它能够捕捉到上下文中的更多信息,有利于提高模型的准确性。而CRF模型则是一种概率图模型,能够通过考虑全局标注的约束条件来优化模型的输出结果,进一步提高模型的准确性。
在BiLSTM-CRF模型中,BiLSTM用于学习上下文特征,将上下文特征序列作为CRF的输入,CRF则用于学习标签之间的转移概率,从而能够更好地对标注序列进行建模,从而实现更准确的序列标注任务。
为什么不单独使用 BiLSTM 进行标注?BiLSTM 可以预测出每一个字属于不同标签的概率,然后使用 Softmax 得到概率最大的标签,作为该位置的预测值。这样在预测的时候会忽略了标签之间的关联性,例如 BiLSTM 在作分词任务时,将某句话的第一个词预测为动词,紧接着的第二个动词同样被预测为动词,而实际上动词后面不能直接跟动词,因此 BiLSTM 没有考虑标签间联系。此时需要 在 BiLSTM 的输出层加上一个 CRF,使得模型可以考虑类标之间的相关性,标签之间的相关性就是 CRF 中的转移矩阵,表示从一个状态转移到另一个状态的概率。
参考如下分词任务
综上,BiLSTM+CRF 考虑的是整个类标路径的概率而不仅仅是单个类标的概率。
3.1 CRF特征函数 CRF包含两种特征函数,第一种特征函数是状态特征函数,也称为发射概率,表示字 x 对应标签 y 的概率
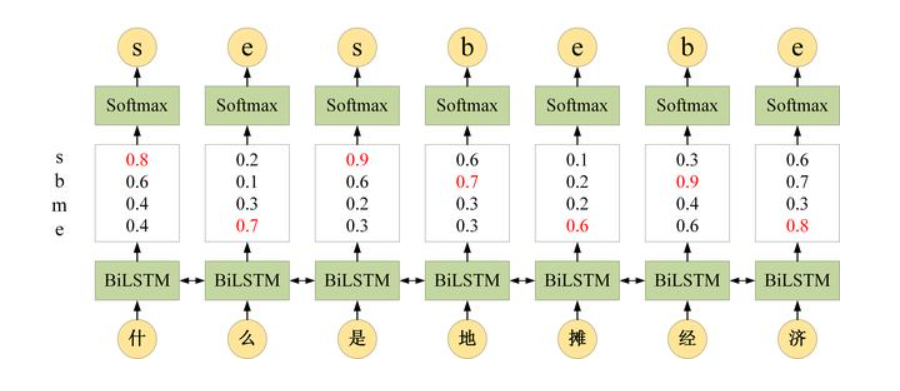
在 BiLSTM+CRF 中,这一个特征函数 (发射概率) 直接使用 LSTM 的输出计算得到,LSTM 可以计算出每一时刻位置对应不同标签的概率(如’什’对应sbme标签的概率分别为0.8,0.6,0.4和0.4)
CRF 的第二个特征函数是状态转移特征函数,表示从一个状态 y1 转移到另一个状态 y2 的概率
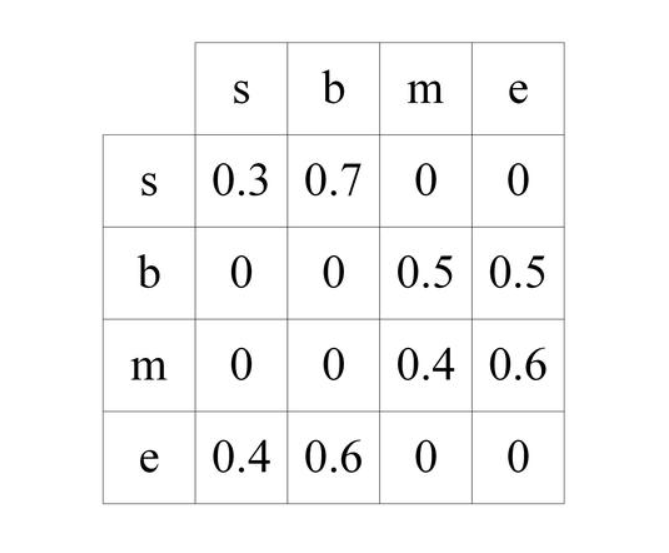
CRF 的状态转移特征函数可以用一个状态转移矩阵表示,在训练时需要调整状态转移矩阵的元素值,前面分词任务中的CRF转移矩阵就可以表示为
3.2 BiLSTM-CRF 一个最基本的BILSTM-CRF网络模型框架如下
1 2 3 4 5 6 7 8 9 10 11 12 class BiLSTM_CRF (nn.Module): def __init__ (self, vocab_size, tag2idx, embedding_dim, hidden_dim ): 2 , 1 , bidirectional=True ) len (tag2idx), len (tag2idx))
其大致结构可以表示为
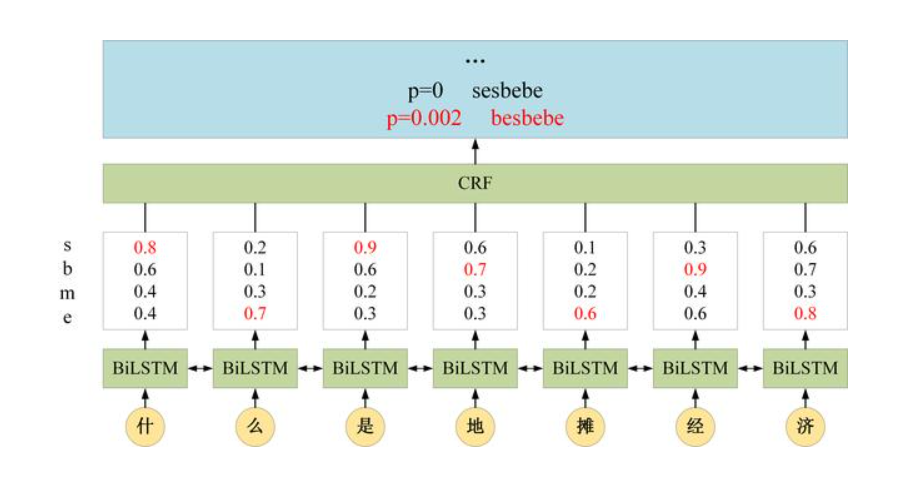
给定一个句子x,其标签序列为y的概率使用如下公式计算
公式中的Z(x)表示所有标签序列打分的指数和,假如序列的长度为i,标签的个数为k,则序列的数量为k^i^,这无法直接计算,需要使用前向算法进行计算
公式中的score需要使用下面的式子计算,其中的Emit对应发射概率,即LSTM的输出概率,Trans对应了转移概率即CRF状态转移矩阵中对应的数值
BILSTM-CRF采用最大似然法进行训练,其对应的损失函数如下
公式中的logZ(x)需要使用前向算法计算,这里不做介绍,详情参考彻底了解 BiLSTM 和 CRF 算法-pytorch bilstm crf (51cto.com) 损失函数的计算;
3.3 viterbi算法 训练好模型后,预测过程需要用 viterbi 算法对序列进行解码,一些使用的符号意义如下
基于上述符号,viterbi算法的递推公式如下
基于上述递推式计算得到的δi(j)和ψi(j)向前标注序列
二、实体识别 1.数据集介绍 原始语料库如下
实验任务是基于深度学习或预训练模型编程实现暴雨洪涝中文文本中的发生时间和发生地点两类实体的识别和抽取,这意味着需要将两类训练语料分别处理过后一起作为训练数据放入模型进行训练;
首先需要对原始语料进行处理,基于时间标签的文本内容如下
基于位置标签的文本内容如下
观察可以发现,前几行对于训练来说毫无意义(因为标题、新闻发布时间以及新闻发布渠道对于文本时间和位置没有任何关系,同时这些内容也没有人工标注),为了减少网络的运算量也为了尽量保持数据集的整洁性,只需要获取正文内容即可,正文内容基本都是从第四行开始,因此对所有文本从第四行开始读取并将其融合为一行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 open ('origin_data.txt' ,'a' ,encoding='utf-8' ) 'D:\My_document\大三下文档\知识图谱\作业\第二次作业\实验2语料\暴雨洪涝时间标签' for dir in dirs:'\\' +dir with open (fname,'r' ,encoding='utf-8' )as src_file:0 ,1 ,2 ]'' for x in range (len (lines)):if x not in dirtyid:'\n' )print (str_new)' ' ,'@' )+'\n' )
处理过后的文本形式如下
这样处理过后的文本一共有1929行,为了之后方便处理(因为原始的时间标签和位置标签都有些问题,直接处理1929条数据会不断报错),将这些数据以200行一个文本的形式区分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 open ('original_data.txt' , 'r' ,encoding='UTF-8' ) for line in diff_line:len (line_list) 200 print ('源文件数据行数:' ,count) for i in range (0 ,len (line_list),n)]for i,j in zip (range (0 ,int (count/n+1 )),range (0 ,int (count/n+1 ))): with open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/test_data/%d.txt' % (j+1 ),'w+' ,encoding='UTF-8' ) as temp:for line in diff_match_split[i]:print ('拆分后文件的个数:' ,i+1 )
拆分后的文件形式如下
接下来就需要对每行的文本按照BEMO规则进行字标注,已知时间标签主要有DS DO TO TS,位置标签主要有LOC;
一开始想法很简单,直接按照规则@地名/LOC@这种形式检测开始标志@和结束标志@即可提取出实体和对应标签,但实际上原始语料中还存在@地名/LOC@地名/LOC@这种形式,因为没有很好的办法从前往后对实体进行界定,所以打算手动对这些不规范的实体进行调整,但是经过实际尝试发现人工标注数据太耗费时间了,因此初次进行数据处理的办法失效;
经过观察发现,文本中常见的几种标记方式主要有 @四川/LOC@、@四川/LOC@西安/LOC@、@四川、@/LOC@、中国/LOC@ 这几种形式,实际上能够提取的合法实体形式应该是四川/LOC,既然从前往后界定实体边界失效,考虑从后往前(具体实现的时候就是将文本翻转),逐字符进行比对,开始标志为出现符号‘@’且其后紧跟字符’C’,读取实体名称,以字符‘@’或其他标点符号为结束标志(避免 中国/LOC@ 这种没有结束标志的实体);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/word2id_re_loc.txt' ,'a' ,encoding='utf-8' ) 'D:/My_code/jupyter notebook/大三下作业/EntityExt/LOC_data' for dir in dirs:print ('当前处理文件路径:' +datapath+'\\' +dir )open (datapath+'\\' +dir ,'r' ,'utf-8' )for line in input_data.readlines():1 ]0 while i < len (text_re):if text_re[i] == '@' and text_re[i+1 ] == 'C' : 5 '' while text_re[i] not in punc: 1 if len (content)!=0 : ' ' +'COL_E/' +content[0 ])for j in content[1 :len (content)-1 ]:' ' +'COL_M/' +j)' ' +'COL_B/' +content[-1 ])if i==len (text_re)-1 and text_re[i]=='@' : 1 else :' O/' +text_re[i])1 if i==len (text_re)-1 and text_re[i]=='@' : '\n' )break '\n' )
处理时间标签的代码形式和位置标签的代码类似,这里给出不同的部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 for dir in dirs:print ('当前处理文件路径:' +datapath+'\\' +dir )open (datapath+'\\' +dir ,'r' ,'utf-8' )for line in input_data.readlines():1 ]0 while i < len (text_re):if text_re[i] == '@' and text_re[i+1 ] == 'S' and text_re[i+2 ] == 'D' : 4 '' while text_re[i] not in punc: 1 if len (content)!=0 : ' ' +'SD_E/' +content[0 ])for j in content[1 :len (content)-1 ]:' ' +'SD_M/' +j)' ' +'SD_B/' +content[-1 ])if i==len (text_re)-1 and text_re[i]=='@' : 1 elif text_re[i] == '@' and text_re[i+1 ] == 'O' and text_re[i+2 ] == 'D' : 4 '' while text_re[i] not in punc: 1 if len (content)!=0 : ' ' +'OD_E/' +content[0 ])for j in content[1 :len (content)-1 ]:' ' +'OD_M/' +j)' ' +'OD_B/' +content[-1 ])if i==len (text_re)-1 and text_re[i]=='@' : 1 elif text_re[i] == '@' and text_re[i+1 ] == 'S' and text_re[i+2 ] == 'T' : 4 '' while text_re[i] not in punc: 1 if len (content)!=0 : ' ' +'ST_E/' +content[0 ])for j in content[1 :len (content)-1 ]:' ' +'ST_M/' +j)' ' +'ST_B/' +content[-1 ])if i==len (text_re)-1 and text_re[i]=='@' : 1 elif text_re[i] == '@' and text_re[i+1 ] == 'O' and text_re[i+2 ] == 'T' : 4 '' while text_re[i] not in punc: 1 if len (content)!=0 : ' ' +'OT_E/' +content[0 ])for j in content[1 :len (content)-1 ]:' ' +'OT_M/' +j)' ' +'OT_B/' +content[-1 ])if i==len (text_re)-1 and text_re[i]=='@' : 1 else :' O/' +text_re[i])1 if i==len (text_re)-1 and text_re[i]=='@' : '\n' )break '\n' )
处理过后的文本形式如下
因为在进行训练的过程中需要考虑字的先后顺序,所以这种翻转的形式还需要翻转回来,利用如下代码
1 2 3 4 5 6 7 8 9 10 open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/word2id_re_loc.txt' ,'r' ,'utf-8' ) open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/word2id_loc.txt' ,'w' ,'utf-8' ) for line in input_text.readlines():1 ]'\n' )
将文本翻转得到如下形式
接着将上述长句形式按照标点符号进行切分,便于切割后放入模型进行训练(长文本会极大的增加模型的训练量)
1 2 3 4 5 6 7 8 9 with open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/word2id_new.txt' ,'rb' ) as inp:'utf-8' )'[,。!?、‘’“”()]/[O]' .encode('utf-8' ,texts).decode('utf-8' ), texts)open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/wordtagsplit.txt' ,'w' ,'utf-8' )for sentence in sentences:if sentence != " " :'\n' )
处理过后的文本形式如下
最后只需要将汉字对应的id(自定义)和上述已经标注好的规则标签对应存入句子数组中打包为pkl文件即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 def data2pkl ():list ()list ()list ()list ()set ()open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/wordtagsplit.txt' ,'r' ,'utf-8' )for line in input_data.readlines():0 for word in line:'/' )0 ])1 ])1 ])if word[1 ]!='O' :1 if numNotO!=0 :print (len (datas),tags)print (len (labels))range (1 , len (set_words)+1 )for i in tags]range (len (tags))"unknow" ] = len (word2id)+1 print (word2id)60 def X_padding (words ):list (word2id[words])if len (ids) >= max_len: return ids[:max_len]0 ]*(max_len-len (ids))) return idsdef y_padding (tags ):list (tag2id[tags])if len (ids) >= max_len: return ids[:max_len]0 ]*(max_len-len (ids))) return ids'words' : datas, 'tags' : labels}, index=range (len (datas)))'x' ] = df_data['words' ].apply(X_padding)'y' ] = df_data['tags' ].apply(y_padding)list (df_data['x' ].values))list (df_data['y' ].values))from sklearn.model_selection import train_test_split0.2 , random_state=43 )0.2 , random_state=43 )
调用pickle函数将最终结果写入 TheNews.pkl 文件中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import pickleimport oswith open ('D:/My_code/jupyter notebook/大三下作业/EntityExt/complete_data/TheNews.pkl' , 'wb' ) as outp:print ('** Finished saving the data.' )
运行上述函数得到如下输出表示成功
在之后的训练过程中可以直接调用pickle的load方法读取 TheNews.pkl 文件中的数据,经过划分后的训练集和测试集数量分别是7655和2393;
2.模块划分 2.1 模型介绍 这里主要介绍BiLSTM网络模型的搭建,也就是pycharm目录中的BiLSTMCRF.py文件;
BiLSTM-CRF网络主要分为embedding层、双向LSTM层以及全连接层,最终是单层CRF;
embedding层定义如下,如果使用了预训练词向量模型则调用vec.txt文件进行初始化
1 2 3 4 5 word_embeddings = tf.get_variable("word_embeddings" ,[self.embedding_size, self.embedding_dim])if self.pretrained:
接着是双向LSTM层,分为前向LSTM和反向LSTM,最终输出作为全连接层的输入
1 2 3 4 5 6 7 8 9 10 lstm_fw_cell = tf.nn.rnn_cell.LSTMCell(self.embedding_dim, forget_bias=1.0 , state_is_tuple=True )1.0 , state_is_tuple=True )False ,None )2 )
全连接层对LSTM层的输出进行加权求和,最后使用tanh函数作为激活函数加入非线性因素
1 2 3 4 5 W = tf.get_variable(name="W" , shape=[self.batch_size,2 * self.embedding_dim, self.tag_size],"b" , shape=[self.batch_size, self.sen_len, self.tag_size], dtype=tf.float32,
CRF层用于计算loss、转移矩阵以及likelihood
1 2 log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(bilstm_out, self.labels, tf.tile(np.array([self.sen_len]),np.array([self.batch_size])))
然后使用viterbi算法计算序列以及score
1 self.viterbi_sequence, viterbi_score = tf.contrib.crf.crf_decode(bilstm_out,self.transition_params,tf.tile(np.array([self.sen_len]),np.array([self.batch_size])))
最后一步选择Adam优化器优化损失函数
1 2 optimizer = tf.train.AdamOptimizer(self.lr)
2.2 训练模块 训练模块位于untils.py文件,与常规模型训练类似,通过一定数量的epochs来最小化训练数据上的损失函数;
函数接受参数包括 model(表示序列标注模型)、sess(表示 TensorFlow 的 session 对象)、saver(表示 TensorFlow 中的 saver 对象,用于保存训练好的模型)、epochs(表示训练的轮数)、batch_size(表示每一批数据的大小)、data_train(表示训练数据)、data_test(表示测试数据)、id2word(表示将 id 转化为 word 的字典)、id2tag(表示将 id 转化为 tag 的字典);
1 2 batch_num = int (data_train.y.shape[0 ] / batch_size) int (data_test.y.shape[0 ] / batch_size)
上述代码表示计算了训练数据和测试数据中每一批数据的数量,并且存储在 batch_num 和 batch_num_test 变量中
进入epoch循环之后每次循环中会对训练数据进行一次遍历。在每次循环中,会遍历训练数据中的每一批数据,并将其输入模型进行训练。训练时,会将当前批次的数据 x_batch 和 y_batch 分别作为模型的输入和标签,并将其通过 feed_dict 提供给 TensorFlow 计算图中的相应节点进行计算
1 2 3 4 5 6 7 8 9 10 11 for batch in range (batch_num):0 if batch%100 ==0 :for i in range (len (y_batch)):for j in range (len (y_batch[0 ])):if y_batch[i][j]==pre[i][j]:1 print ("train acc:" ,float (acc)/(len (y_batch)*len (y_batch[0 ])))
每训练完一定数量的批次后,计算当前的训练精度,并将其输出。具体来说,会遍历当前批次中的每一个样本,并且将预测的标签 pre 与真实的标签 y_batch 进行比较,计算准确率。如果当前批次的编号是 100 的倍数,就会将当前的准确率输出到控制台上;
每训练完一轮后,会将训练好的模型保存到磁盘上。具体来说,每隔 3 轮会将当前训练的模型保存到名为 modelX.ckpt 的文件中,其中 X 表示当前的轮数。
1 2 3 if epoch%3 ==0 :print ("model has been saved" )
2.3 测试模块 test模块位于utils.py文件中,主要用于输入测试数据,对模型进行测试的函数。具体来说,它的输入包括一个已经训练好的模型(model)、一个已经启动的会话(sess)、一个词到id的映射表(word2id)、一个id到标签的映射表(id2tag)以及一个批处理大小(batch_size)。
1 model,sess,word2id,id2tag,batch_size
函数的实现中,首先要求用户输入要测试的文本,并且将其按照标点符号进行切割
1 2 text = input ("Enter your input: " ).decode('utf-8' );u'[,。!?、‘’“”()]' , text)
然后,将文本中的每一个句子转换为一个包含词id的序列。如果某个词不在词表(word2id)中,则用”unknow”对应的id来代替
1 2 3 4 5 6 7 8 9 text_id=[]for sen in text:for word in sen:if word in word2id:else :"unknow" ])
对于每一个句子,如果长度不足(max_len),则将其填充到相应的长度
1 2 3 zero_padding=[]0 ]*max_len)len (text_id)))
接着,将所有的句子打包成一个批次,并将其输入到模型中,得到模型的预测结果,最后,将预测结果转换为对应的实体(entity)并进行输出
1 2 3 4 5 6 feed_dict = {model.input_data:text_id}0 ],id2tag)print ('result:' )for i in entity:print (i)
3.实验结果 调用
开启训练,训练输出结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 train acc: 0.010416666666666666
经过模型训练得到上述实验结果,主要评价指标为查全率、查准率以及F1分数:
查全率(recall):模型在测试集中能够正确预测出的正样本数量与测试集中所有正样本数量的比例为 X%。
查准率(precision):模型在测试集中预测为正样本的样本中,表示真正是正样本的数量与所有被预测为正样本的样本数量的比例为 Y%。
F1分数(F1 score):F1分数综合了查准率和查全率的指标,其计算公式为 2 * (precision * recall) / (precision + recall);
其中,查全率衡量了模型能够识别出所有的正样本的能力,而查准率则衡量了模型在预测正样本时的准确性。F1分数是综合了这两个指标,用于综合评估模型的性能。在我们的实验中,我们得到了一个具有较高查全率和查准率的模型,最终其F1分数0.84,表明该模型在预测正样本时具有很好的准确性和召回率。
观察实验结果可知BiLSTMCRF模型具备很快的收敛速度,但是也可以观察看到一方面是模型的学习能力过强,一方面因为模型的训练数据不足,在训练过程中出现了过拟合的现象,最终对训练得到的模型进行测试,输入命令
前面说过一方面模型学习能力太强,一方面我们的数据因为是自己清洗的所以可能并不是特别标准,同时数据量不够,这些原因都可能导致模型的泛化能力变弱,具体表现就是我们在测试的过程中会出现如下情况
因此如果想要提高模型的泛化能力可以从以下几个方面入手(需要根据具体情况采取合适的方法才可能得到更好的结果):
更多的数据:收集更多的数据可以使模型接触到更多的变化和情况,提高模型的泛化能力。可以通过增加训练集数据、进行数据增强等方式来实现。
正则化:正则化可以减少模型的复杂度,降低过拟合的风险,进而提高泛化能力。可以使用L1、L2正则化、dropout等方法。
交叉验证:使用交叉验证可以评估模型的泛化能力,并帮助我们调整模型的参数,进而提高泛化能力。
模型结构优化:可以通过增加或减少网络层数、调整每一层的神经元数、使用更优的激活函数等方法来调整模型结构,以提高泛化能力。
集成学习:通过将多个模型进行集成,可以得到更好的结果,同时降低过拟合的风险,提高泛化能力。可以使用投票、堆叠等集成方法。
对抗训练:对抗训练可以通过引入对抗样本,使得模型能够更好地抵御噪声、干扰等攻击,提高泛化能力。
知识蒸馏:知识蒸馏可以通过将一个复杂的模型的知识迁移到一个简单的模型中,使得简单的模型也能够具有类似复杂模型的泛化能力。
4.实验总结 本次实验要求基于给定的暴雨洪涝中文语料库,利用已人工标注的样本作为训练集和测试集,基于深度学习和预训练模型,编程实现暴雨洪涝中文文本中的发生时间和发生地点两类实体的识别和抽取。在完成实验的过程中我个人认为最难的一步在于数据的处理,吸收了上一次的经验教训后这次在数据处理的时间花费上不是很长,得到了在训练中能够得到较好结果的训练数据,但是本次实验中使用的数据集比较小,未来可以尝试更大的数据集进行实验。此外,除了BiLSTM-CRF还可以尝试其他的实体抽取模型,如基于注意力机制的模型。