自然语言处理_中级
参考书:《自然语言处理》双锴
2023/3/29 10:12 前面学NLP的时候参考的资料太杂了,导致思维导图之类的全部错乱,这里参考北京邮电大学的自然语言教材进行二次学习(初级那篇文章看不懂可以直接看这篇),这本书非常适合自学者(强推);
2023/4/3 8:28 学完教材上面的科普性内容之后,适当的看一些典型模型如Transformer、Bert的介绍,然后看现在比较新的模型的介绍;
2023/4/5 10:39 教材后半部分的内容几乎都是一些比较重复的内容,所以决定直接跳出教材开始看视频进一步拓展;
2023/4/27 23:12 李宏毅的机器学习课程挺有用的,讲了许多关于NLP包括自注意力机制等在内的知识点,有空真的可以结合PDF看一看,纯看文本真的不好理解;
2023/4/28 8:57 NLP近两年来的发展变换太快了,甚至连ChatGPT都不知道Google Bard(毕竟它的数据库只更新到2021年),而且网上有很多降智的文章(甚至把不是同一个层级的东西放在一起对比),看这些文章的时候注意一定要擦亮眼睛;可以结合使用ChatGPT和New bing,增加搜索效率;
第一章 绪论
在写博客的过程中往往会重复介绍一些概念,这是因为有些学科之间是交叉的(如知识图谱和自然语言处理),这也侧面表现这些知识点的重要性,因此重复介绍增加理解并不是浪费时间。而实际上博客中大部分内容都是介绍性的,即不涉及技术、代码方面的详细介绍,因为我认为这部分仅靠看书或者看公式是没办法掌握的,需要结合实际项目理解,因此关于一些具体的技术详细的介绍会放在“项目”类的博客中。
1.NLP概述
1.1 NLP定义
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学交叉领域下的分支学科。该领域主要探讨如何处理及运用自然语言、自然语言认知(即让计算机“懂”人类的语言)、自然语言生成系统(将计算机数据转化为自然语言),以及自然语言理解系统(将自然语言转化为计算机程序更易于处理的形式)。
- 自然语言实际就是日常生活中使用的语言(包括书面文字和语音视频等);
- 自然语言处理是对自然语言进行数字化处理的一种技术;
1.2 NLP难点
(1)单词边界界定
界定字词边界通常使用的办法是取用能让给定的上下文最为通顺且在文法上无误的一种最佳组合。在书写上,汉语也没有词与词之间的边界。
(2)词义消歧
许多字词不只有一个意思,需要选出使句意最通顺的解释。
(3)句法模糊
自然语言的文法通常是模棱两可的,针对一个句子通常可能会剖析出多棵剖析树,必须要依赖语意及前后文的信息才能在其中选择一棵最为适合的剖析树。
(4)不规范输入
语音处理中的方言,文本处理任务中的拼写、语法或OCR识别错误。
(5)语言行为与计划
句子通常并不只是字面上的意思。
2.NLP发展
2.1 理性主义方法阶段
理性主义方法的核心思想是人类大脑中的语言知识是通过一般遗传而提前固定下来的,假设语言的关键部分在出生时就已经扎根于大脑,作为人类遗传的一部分,理性主义方法会努力设计人工制作的规则,将相关知识和推理机制融入智能NLP 系统。
该阶段的典型方法是专家系统,这种系统旨在通过推理知识来解决复杂问题,优势在于其执行逻辑推理能力的透明性和可解释性。
2.2 经验主义方法阶段
该阶段的NLP特点是通过数据语料库和机器学习、统计或其他方法来使用数据样本。
与理性主义方法相反,经验主义方法假设人类思维只从联想、模式识别和概括的一般操作着手,为了使得大脑更好地学习自然语言的详细结构,需要存在丰富的感官输入才可以。
该阶段的典型方法是基于统计的学习方法,更通俗的来说以数据驱动的机器学习方法为显著标志。
3.深度学习和NLP
在传统的机器学习中,由于特征是由人设计的,需要大量的人类专业知识,显然特征工程也存在一些瓶颈。同时,相关的浅层模型缺乏表示能力,因此缺乏形成可分解抽象级别的能力,这些抽象级别在形成观察到的语言数据时将自动分离复杂的因素。
浅层判别模型尽管取得了成功,但它们仍然难以通过行业专家人工设计特征来涵盖语言中的所有规则。除不完整性问题外,这种浅层模型还面临稀疏性问题,因为特征通常仅在训练数据中出现一次,特别是对于高度稀疏的高阶特征。因此,在深度学习出现之前,特征设计已经成为统计NLP的主要障碍之一。
深度学习方法利用包含多个隐藏层的神经网络来解决机器学习任务,无需特征工程,因为深层神经网络能够利用多层非线性处理单元的级联从数据中学习表示以进行特征提取。
在将深度学习应用到NLP问题的过程中,出现了两个重要技术突破:
- 序列到序列学习:利用循环网络以端到端的方式进行编码和解码;
- 注意力建模:注意力建模最初是为了解决对长序列进行编码的困难,但随后的发展显然扩展了它的功能,能够对任意两个序列进行高度灵活的排列,且可以与神经网络参数一起进行学习;
第二章 NLP基础
自然语言处理一般可分为语料库与语言知识库的获取、文本预处理、文本向量化表示、模型训练与预测四大步骤。其中语料库与语言知识库的获取、文本预处理、文本向量化表示为自然语言处理任务的基础工作,最后一步模型训练与预测依托于具体的自然语言处理任务。
1.语料库与语言知识库
语料库与语言知识库是NLP领域的数据资源。一方面语料库与语言知识库是相关语言处理任务的支撑,为语言处理任务提供先验知识进行辅助;另一方面,语言处理任务也为语料库与语言知识库提出了需求,并能够对语料库与语言知识库的搭建、扩充起到技术性的指导作用。
1.1 语料库
语料,即语言材料,包括文本和语音。
语料库(Corpus)即语料的集合,也可称为自然语言处理领域的数据集,是为一个或者多个应用目标而专门收集的,有一定结构的、有代表的、可被计算机程序检索的、具有一定规模的语料集合。
语料库具备三个显著特点:
语料库中存放的是在语言的实际使用中真实出现过的语言材料;
语料库以电子计算机为载体承载语言知识的基础资源,但并不等于语言知识;
真实语料需要经过加工(分析和处理),才能成为有用的资源;
根据不同标准,语料库有多种划分方式,详情可自行Google,无论哪一类的语料库的构建都需要具有代表性、结构性、平衡性和规模性四大特性,并需要具有元数据用于辅助理解语料库:
代表性:在应用领域中,不能依据数据量而界定是否是语料库,语料库是在一定的抽样框架范围内采集而来的,并且能在特定的抽样框架内做到代表性和普遍性。
结构性:语料库必须以电子形式存在,计算机可读的语料库结构性体现在语料记录的代码、元数据项、数据类型、数据宽度、取值范围、完整性约束。
平衡性:平行语料一般有两类,一类是指在同一种语言语料上的平行,其平行性表现为语料选取的时间、对象、比例、文本数、文本长度等几乎是一致的。另一类是指两种语言或者多种语言之间的平行采样和加工。
规模性:大规模的语料对语言研究特别是对自然语言研究处理很有用,但是随着语料库的增大,垃圾语料越来越多,语料达到一定规模以后,语料库功能不能随之增长,语料库规模应根据实际情况而定。
元数据:元数据是描述数据的数据(Data about Data),主要是描述数据属性
(Property)的信息,如语料的时间、地域、作者、文本信息等,元数据能够帮助使用者快速理解和使用语料库,对于研究语料库有着重要的意义。
1.2 语言知识库
语言知识库包括词典、词汇知识库、句法规则库、语法信息库、语义概念等各类语言资源,是自然语言处理系统的必要组成部分。
语言知识库可分为两类:一类是显性语言知识库,如词典、规则库、语义概念库等,可以采用形式化结构描述;另一类是隐式语言知识库,这类语料库的主体是文本,即语句的集合。隐式语言知识库中每个语句都是非结构化的文字序列,该库的知识隐藏在文本中,需要进一步处理才能把隐式的知识提取出来,供机器学习和使用。
Q:语料库和语言知识库的区别?
A:
语料库是由自然语言文本组成的数据集,而语言知识库是关于自然语言结构和用法的规则和信息集合。虽然它们都对计算机理解和生成自然语言至关重要,但它们的目的和内容不同。
语料库是指一个或多个文本的集合,通常是计算机自然语言处理任务的训练数据。语料库可以包含从新闻文章和社交媒体帖子到百科全书和小说的各种类型的文本。它们通常被用来训练机器学习模型,帮助模型学习不同类型的文本的语言特征,从而在未来能够准确地分类新的文本。
语言知识库(知网是一个典型的显性语言知识库)是一个关于语言结构、语法、语义和语用等方面的信息集合。它们可能包括词汇、短语、句法规则、语义关系等等。语言知识库通常由语言学家和计算机科学家手动构建和维护,其目的通常是帮助理解语言的结构和意义,以便更好地处理和生成自然语言。
2.文本预处理
自然语言处理任务中获取语料后的第一步就是文本预处理,文本预处理的目标为将文本转变成结构化文本形式以提供给后续步骤。
2.1 数据清洗
NLP中数据清洗的目的在于排除非关键信息,只保留文本内容阐述的文字信息,同时尽可能减少这些信息对算法模型构建的影响;
数据清洗工作可以使用正则表达式来完成(其他方式自行Google);
除此之外,文本的标准化也是一项非常重要的工作,如英文文本大小写不统一、中文文本简体字和繁体字共存等会大大增加模型的学习难度,通常需要预先将英文文本的大写字母转换成小写,将中文文本的繁体字转化为简体字,从而实现文本大小写以及繁简的统一,以便用于后续处理;
2.2 分词处理
分词又称为标记化,即将句子、段落、文章等长文本分解为以词为单位的数据表示;
NLP的任务通常以词为粒度来进行,如传统的词袋模型BOW统计词频形成文本向量,词向量以词为单位构建词向量表示等;
近年来也涌现出以字/字符、句子为粒度的自然语言处理技术,但词语级别的自然语言处理技术仍占据主流地位;
2.2.1 英文分词
英文文本的句子、段落之间以标点符号分隔,单词之间以空格作为自然分界符,因此英文分词只需根据标点符号、空格拆分单词即可;
但是英语单词存在多种形态,根据空格分词后还需要进一步做词性还原、词干提取处理;
2.2.2 中文分词
中文文本是由连续的字序列构成,中文分词的本质是将连续的字序列按照一定的规范重新组合成词序列的过程;
中文文本的词与词之间没有天然的分隔符,并且不同的分割方式还会导致歧义问题,因此中文分词相对于英文分词要复杂得多;
关于中文分词这一问题的研究和探索,可大致归纳为:规则分词、统计分词和混合分词(规则+统计)三个流派
- 规则分词主要是通过人工设立词库,按照一定的方式进行匹配切分,该方法的实现简单高效,但对于分词歧义、新词问题效果很差;
- 统计分词主要利用字与字相邻出现的频率(相连字在不同文本中出现的次数)来反映成词的可靠度,统计语料中各个字组合共同出现的频度,当组合频度高于某一临界值时,认为此字组合可能会构成词,当对一条中文文本进行分词时,对整条文本中不同划分结果(即不同的字组合)计算概率,取最大概率的分词方式,该方法能够更好地应对新词发现等特殊场景;
- 混合分词是规则分词和统计分析两种方法的结合,是目前最为常用的分词方法;
2.3 特征过滤
经过文本预处理过后的每一条文本都被表示为一个词序列,这个词序列可能包含一些与自然语言处理任务无关或者无意义的词,称为噪声,通常需要对这个词序列进行过滤以去除噪声,从而得到清洁词序列;
2.3.1 停用词过滤
停用词(Stop Words)指一些没有具体含义的虚词,包括连词、助词、语气词等无意义的词,这些虚词仅仅起到衔接句子的作用,对文本分析没有任何帮助甚至会造成干扰,因此需要对分词后的数据做停用词的去除。去除停用词需要借助停用词表,常用停用词表可以在网络上下载;
注意使用的停用词表也需要根据具体任务而定,盲目使用某些停用词过滤可能会导致无法表达原有语义;
2.3.2 基于频率过滤
停用词词表是一种剔除无意义词的方法,还可以使用频率统计过滤高频无意义词以及低频罕见词
- 高频词包含很多停用词,这些停用词需要被过滤,但另外一些数据集中的常见词、重要词需要保留;
- 罕见词不仅无法作为预测的凭据,还会增加计算的开销(噪声);
词汇表中60%以上的词都是罕见词。这就是所谓的重尾分布,并且在实际数据中这种分布屡见不鲜。罕见词带来了很大的计算和存储成本,却收效甚微,所以去除罕见词是十分必要的;
2.3.4 词干提取&词性还原
英文单词存在多种形态,在分词处理后还需进行词干提取(Stemming)、词性还原(Lemmatisation)处理,从而将单词长相不同,但是含义相同的词合并,这样方便后续的处理和分析;
词干提取是去除单词的前后缀得到词根的过程:cities children 需要转换为 city child
词形还原是基于词典,将单词的复杂形态转变成基础形态:does done doing did 需要还原成 do
当然词干提取不一定会取得好的效果,比如’news’和’new’是两个意思,但是都会被提取成’new’,因此是否采取词干提取以及词性还原需要根据具体任务而言;
3.文本向量化
经过文本预处理后的每一条文本被表示为一个词序列,这个词序列依旧是文本字符串的表示形式,计算机无法直接对其进行处理和分析,因此需要对这个词序列进行向量化,将其转换为计算机可处理的文本表示形式,即数值向量,并且希望这个数值向量能够表示原始文本的语义信息以及文本之间的相似关系;
3.1 One-Hot
One-Hot指的是一个词的One-Hot向量中只有该词对应索引位置的值为1,其余值都为0;
One-Hot存在如下问题:
- 这种表示方法中不同单词的 One-Hot 向量相互正交,即词与词之间是完全独立的,无法衡量不同词之间的关系;
- One-Hot 向量只能反映某个词是否在句中存在,不能表示出单词出现的频率,无法衡量不同词的重要程度;
- 当语料库非常大时,需要建立一个词表对所有单词进行索引编码,假设有 100万个单词,每个单词就需要表示成100万维的向量,而且这个向量是很稀疏的,只有一个位置为 1,其他全为 0,高维稀疏向量导致机器的计算量大并且造成了计算资源的浪费;
3.2 BOW
词袋表示也称为计数向量表示,基本思想是先将句子进行向量转换,转换过后的向量维度为语料库词表的长度(即有多少个词则维度为多少),该向量每个索引位置上的值为索引序列对应词在这句话中出现的次数;
BOW表示将每条语句看作是若干词汇的集合,考虑了词表中的词在句子中的出现次数,能够在一定程度上表示出词在句子中的重要程度;
BOW存在如下问题:
- BOW 表示方法忽略了句子中词的位置信息,而词的位置不同表达的语义会有很大的差别。例如,“爸爸妈妈爱中国”和“中国爱爸爸妈妈”这两个句子的BOW表示相同,但很明显所表达的语义完全不同;
- BOW表示方法虽然统计了词在句子中出现的次数,但仅仅通过“出现次数”这个属性无法区分常用词(如“我”“是”“的”等)和关键词在句子中的重要程度。例如,“是的,是的,小明爱中国”一句中,关键词很明显是:“小明”“爱”“中国”,但若使用BOw表示方法,“是”和“的”两词在句中分别出现了两次,即这两个词的重要程度要比“小明”“爱”“中国”这些关键词要高;
3.3 TF-IDF
词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)与词袋表示思想类似,都是对语料库进行分词编号建立索引序列作为词表,然后以词表的长度为向量的维度对文本进行向量化,但TF-IDF向量的值不仅仅考虑词频;
TF-IDF 的核心思想是若一个词在一篇文章中出现次数较多且在其他文章中很少出现,则认为这个词具有很好的类别区分能力,该词的重要性也越高;
词频TF指的是一个词在一篇文章中出现的频率

逆文档频率(IDF)主要是为了实现:一个词在所有文章中出现次数越多,代表其分类能力越差,该单词的重要性越低,权重越小。IDF使用总的文章数目除以包含该关键词的文章数目,然后对结果取对数(分母+1是为了避免分母为0)

TF-IDF的计算公式如下
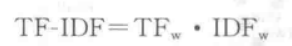
词频-逆文档频率表示方法在 BOW 表示的基础上进行了一定的改进,在保留文章的重要词的同时可以过滤掉一些常见的、无关紧要的词。但该方法也存在一些问题:
- IDF 是一种试图抑制噪声的加权,更倾向于文中频率较小的词,这使得TF-IDF算法的精度不够高;
- 与 BOW 表示方法相同,TF-IDF也未考虑词的位置信息,导致了语义信息的丢失;
3.4 Word2Vec
Word2Vec本质上是一种降维操作,将词语从One-Hot表示降维到Word2Vec形式的表示;
Word2Vec是一种基于神经网络的分布式文本表示方法,该方法将单词映射成一个指定维度的稠密向量(典型取值为200维或300维),这个向量是对应单词的分布式表示(Distributional Representation),并且能够在一定程度上表达单词的语义信息以及单词与单词之间的相似程度;
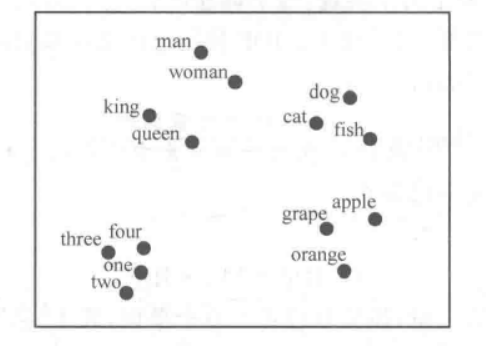
简单理解分布式表示方法即上下文相似的词其语义也相似,词的分布式表示将每一个词映射到一个具有意义的稠密向量上,Queen和King在某些维度上具有相似性,对词向量采用T-SNE进行降维可以看到与之语义接近的词语
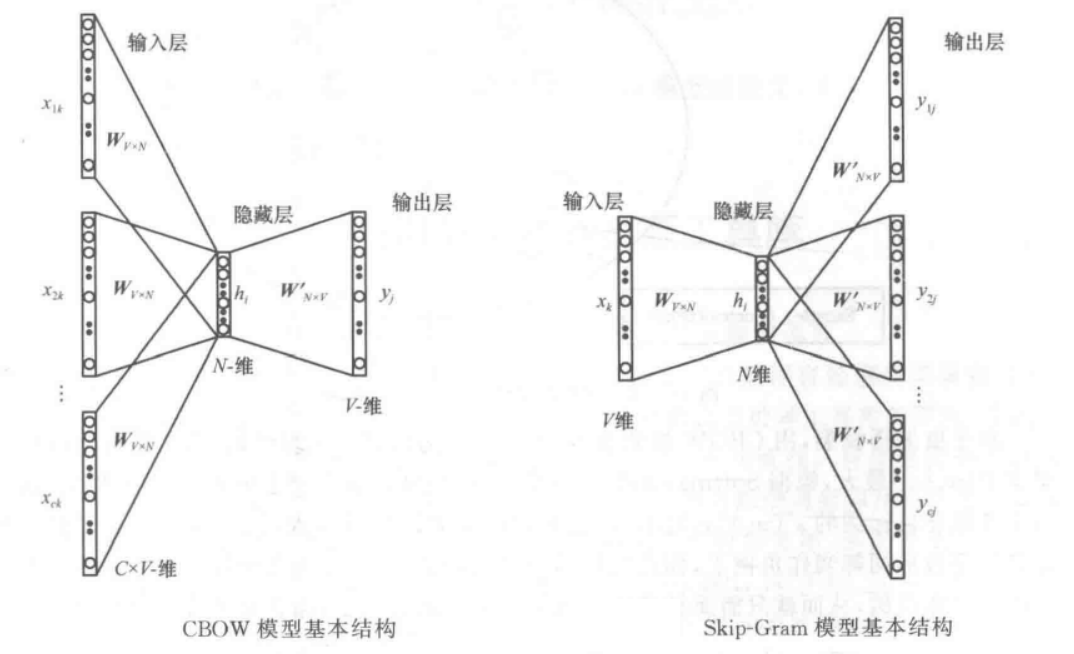
Word2Vec的核心思想是通过词的上下文得到词的向量化表示,该方法包括连续词袋(Continuous Bag-of-Words,CBOW)和Skip-Gram两种模型,其中CBOw模型根据上下文的词预测中间词,Skip-Gram 根据中间词预测上下文的词。两者都采用 One-Hot 向量作为模型的输入,通过反向传播训练完模型以后,最后得到的其实是神经网络的权重,将权重视为该词的表示向量;
Skip-Gram 和 CBOW 是 Word2Vec 的两种将文本进行向量表示的实现方法,但两者之间也存在一定的区别:
- CBOW方法是用周围词预测中心词,从而利用中心词的预测结果不断地调整周围词的向量。训练完成后,每个词都会作为中心词,对周围词的词向量进行调整,从而获得整个文本里所有词的词向量。CBOW对周围词的调整是统一的:求出的梯度的值会同样地作用到每个周围词的词向量当中去。所以CBOW预测行为的次数跟整个文本的词数几乎是相等的(每次预测行为才会进行一次反向传播,这也是最耗时的部分),复杂度是 O(V);
- Skip-Gram 是用中心词来预测周围的词。在 Skip-Gram 中,会利用周围的词的预测结果来不断地调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。所以 Skip-Gram 进行预测的次数是要多于CBOW 的:因为每个词在作为中心词时,都要使用周围词进行预测一次。这样相当于比CBOW的方法多进行了K次(K 为窗口大小),因此时间的复杂度为O(KV),训练时间比CBOW 要长;
在Word2Vec之后的第二年,GloVe(Global Vectors for Word Representation,全局词向量表示)被提出,该方法也属于分布式表示方法,与Word2Vec不同的是该方法并未使用神经网络模型,而是基于全局词频统计构建词汇共现(共同出现)矩阵,并对共现矩阵降维;
与之前的表示方法相比,这两种方法解决了数据稀疏、向量维度过高、字词之间关系无法度量的问题,但这两种方法得到的词向量都是静态词向量(即词向量在训练结束后不会根据上下文进行改变),静态词向量无法解决多义词的问题;
常见的GPT、BERT等模型中的动态词向量区别于直接训练得到静态词向量的方式,动态词向量是在后续使用中把句子传入语言模型,并结合上下文语义得到更准确的词向量表示。动态词向量解决了多义词的问题,并凭借其在多项自然语言处理任务中取得的优异表现,迅速成为目前最流行的文本向量化表示方法(最近大火的Chat-GPT聊天机器人使用的就是动态词向量);
第三章 语言模型
语言模型是自然语言处理领域最基础的任务,通过语言模型训语练得到的文本特征可以直接地广泛应用于各类下游任务当中
1.语言模型
在计算机技术发展的初期,为了对存在的大量文本进行分析,人们归纳出了针对自然语言的语法规则,从而对已有的语料进行处理。但是手工编写规则既费时又费力,而且制定的规则并不能涵盖所有的语言学现象。所以,研究者们提出了语言模型(Language Model)来对文本进行建模,语言模型通过概率分布来计算文本质量,对大量文本进行训练得到的语言模型还可以应用于各类自然语言处理的下游任务中;
对于一个由多个单词组成的语言序列w1…wn,语言模型可以计算该序列出现的概率P(w1…wn)
- 从算法的角度,语言模型是对一个序列的概率分布进行建模,从而找出概率较高的序列;
- 从实际运用的角度,希望语言模型能够计算出由相同单词的不同顺序组成的序列里面最符合人类语言表达方式的序列作为输出;
2.统计语言模型&神经网络语言模型
2.1 统计语言模型
统计语言模型利用统计学的原理来计算一个序列出现的概率,将词的序列看作是一个随机事件,并赋予该序列相应的概率来描述这个序列属于某种语言集合的可能性。例如,给定一个词汇集合 V,对于一个由 V 中的词构成的序列S=<w1,w2,…,wn>∈V,统计语言模型赋予这个序列一个概率 P(S)来衡量 S 符合自然语言的语法和语义规则的置信度;
N元语言模型即N-gram是一种最广泛的使用的统计语言模型,也是在神经网络模型出现之前最广泛适用的一种语言模型;
N元语言模型引入了马尔可夫假设(Markov Assumption):一个单词出现的概率只与它前面出现的有限的一个或几个单词有关,计算当前单词出现的概率公式如下
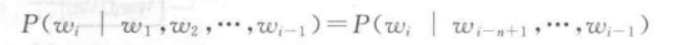
基于上述概率公式,可以定义不同的N元语言模型:
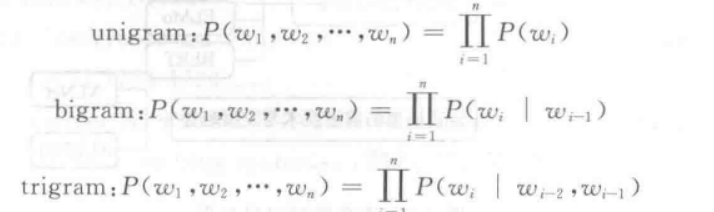
当N=1的时候称其为一元语言模型,每个单词出现的概率只与它自己有关,与上下文无关,这种情况下一个句子的概率就等于每个单词的概率相乘;
当使用多元语言模型的时候,会涉及条件概率,这些条件概率都是从一个很大的语料库中统计得到(使用极大似然估计计算每一项条件概率 – 根据大数定律,样本数量足够大时可以近似用频率来代替概率)
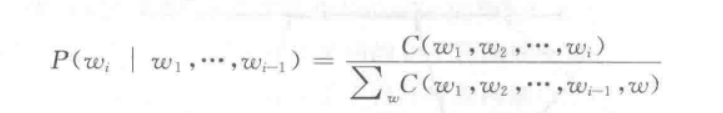
其中C(w1…wi)表示w1…wi这个序列在语料库中出现的次数;
随着N的增大,N元语言模型的两个缺陷会显现:
- 参数空间呈指数级增长,计算量十分巨大;
- N过大的时候,很多单词组合在语料中出现次数少或从未出现过,造成数据稀疏;
理论上,训练语料的规模越大,参数估计的结果就越可靠,但实际上即便训练数据的规模非常大,还是有很多单词序列在训练语料中不会出现,这就导致很多参数是0;为了避免因为乘以0导致整个句子的概率为0,使用最大似然估计方法时需要加入平滑(smoothing)来避免参数取零。最常用的一种平滑方式称为Laplace平滑,计算方式如下
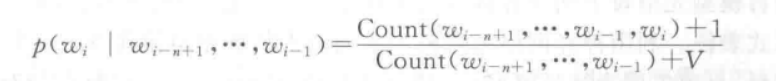
在计算每个单词出现概率的时候,分子加一,分母加上语料库的大小,避免了计算出来的概率为 0;
在传统统计语言模型中,基于极大似然估计的语言模型缺少对上下文的泛化,比较“死板”,但在某些具体的自然语言处理应用中,这种“死板”反而是一种优势,这种语言模型的灵活性低,但能够降低召回率,提升准确率;
2.2 神经网络语言模型
N-gram语言模型有很多问题,其中一个是N-gram只考虑了其相邻的有限个单词,无法获得上文的长时依赖;另一个问题是N-gram只是基于频次进行统计,没有足够的泛化能力;
神经网络语言模型NNLM以及词向量的概念随之提出,词向量代替N-gram使用的高维离散变量,采用具有一定维度的实数连续向量来进行单词的分布式表示,以此解决维度爆炸的问题,同时使用词向量可以考虑词之间的相似性;
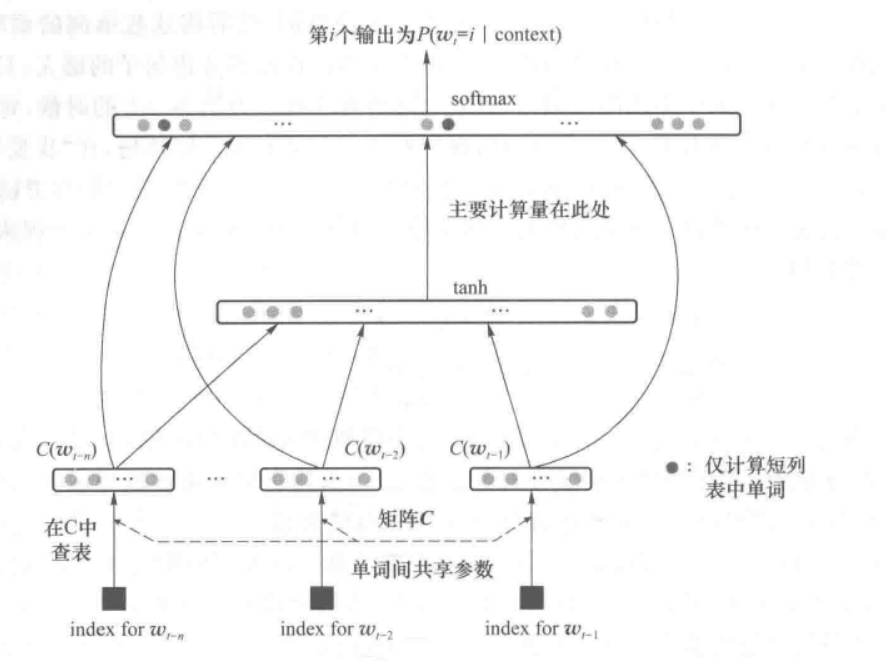
上面是一个简单的NNLM,由输入层、投影层、隐藏层以及输出层构成;
神经网络语言模型先给每个词在连续空间中赋予一个向量(词向量),再通过神经网络去学习这种分布式表征,利用神经网络去建模当前词出现的概率与其前 N-1 个词之间的约束关系;
NNLM将联合概率拆分为两步计算:首先将词汇表中的每个词对应一个分布式向量表示,对句子中的词向量通过函数得到联合概率,然后在大语料上通过神经网络来学习词向量和联合概率函数的参数;
将上述NNLM抽象为下面的四层结构
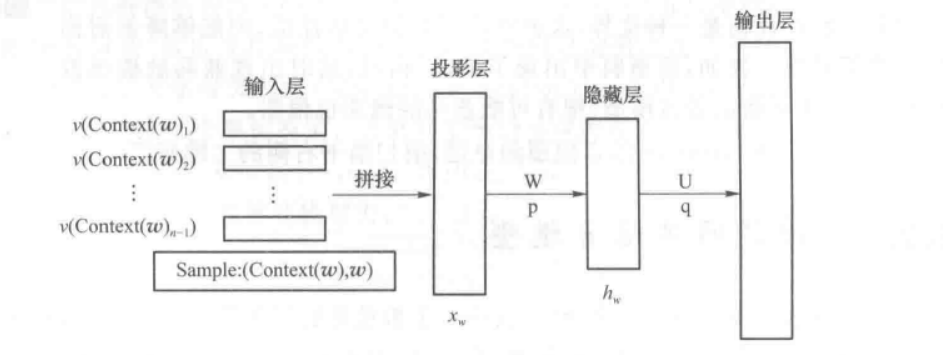
网络的输入为文本的索引序列,嵌入层embedding是一个矩阵,可以看作是一个随机初始化的词向量,会在反向传播中进行更新,神经网络训练完成之后这部分就是词向量;
隐藏层接收拼接后的嵌入层输出作为输入,以tahn为激活函数,经过计算得到该隐藏单元在每一个单词上的输出,经过Softmax操作进行归一化,得到输出在每一个单词上的概率分布;
NNLM 的优点在于:
- NNLM 相比 N-gram 语言模型不需要事先计算保存所有的概率值,而是通过函数计算得到;
- NNLM增加了单词词向量,可以表达单词的相似性(即语义和语法特征);
- 利用神经网络求解最优参数及Softmax的使用,相比N-gram可以更加平滑的预测序列单词的联合概率,且对包含未登录词的句子预测效果很好;
随着深度学习技术的不断发展,目前基于循环神经网络(RNN)的语言模型成为科研界的主流。循环神经网络的最大优势在于,可以真正充分地利用所有上文信息来预测下一个词,而不像前面的其他模型那样,只能有N个词的窗口,只用前N个词来预测下一个词。从形式上看,这是一个非常理想的模型,它能够用到文本的所有信息。但是循环神经网络,使用起来却非常难优化,如果优化得不好,长距离的信息就会丢失。在RNNLM里只使用了最朴素的 BPTT优化算法,就已经比N-gram语言模型中的结果有了巨大的提高。后续为了解决 RNN出现梯度爆炸等问题,长短期记忆网络(LSTM)也被广泛应用于语言模型。
3.评价指标
当训练得到一个语言模型的时候,需要一个标准来评价语言模型的好坏;前面说过语言模型任务的定义是模型计算每个序列出现的概率,因此提出使用困惑度来度量一个概率分布或概率模型预测样本的好坏程度;
困惑度还可以用来比较两个概率分布或概率模型,低困惑度的概率分布模型或概率模型能更好地预测样本;
困惑度的通俗解释,如果一个语言模型的困惑度为X,表示在平均情况下该模型预测下一个单词的时候会有X个单词等可能地作为下一个单词的合理选择;
对于序列w1、w2…wn,困惑度的计算公式
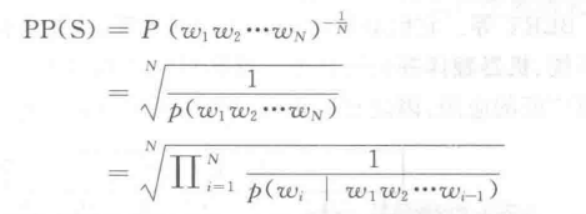
其中S代表一个句子,N是句子长度,P(wi)是第i个单词的概率,w0表示START即句子的起始位置,作为一个占位符;
从公式可以看出,句子的概率越大,表示语言模型越好,困惑度就越小;
4.预训练语言模型
预训练思想的本质是模型参数不再是随机初始化,而是通过一些任务(如语言模型)进行预训练。大型语料库上的预训练模型(Pre-trained Model,PTM)已经可以学习通用的语言表征,这对于下游的NLP相关任务是非常有帮助的,可以避免大量从零开始训练新模型。
第一代预训练模型旨在学习词向量,通常采用浅层模型(Word2Vec),但这种方法无法理解更高层次的文本概念(句法结构、语义角色、指代);
第二代预训练模型旨在学习上下文的词嵌入(OpenAI GPT、BERT),它们会学习更合理的词表征,这些表征囊括了词的上下文信息,可以用于问答系统、机器翻译等后续任务;
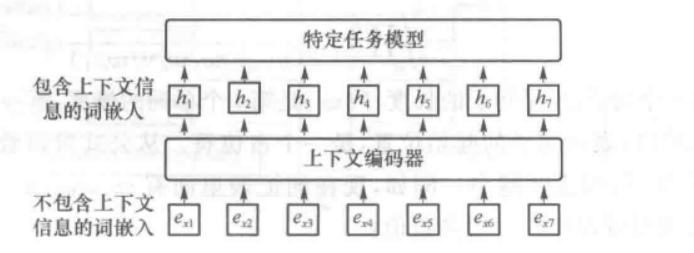
上图是NLP模型训练的一般结构,NLP任务一般会预训练e这些不包含上下文信息的词嵌入,接着针对不同的任务确定不同的上下文信息编码方式以构建特定的隐藏向量h;
预训练语言模型的输入同样是e这些词嵌入,但是会在大规模语料库上预训练上下文编码器,即将预训练编码的信息提高一个层级;
Q:预训练模型和普通语言模型的区别?
A:
预训练语言模型(Pretrained Language Model)和普通语言模型(Regular Language Model)之间的主要区别在于它们的训练方式和目的。
普通语言模型通常使用监督学习算法训练,它们的目的是从给定的输入序列中预测下一个单词或字符。这些模型通常使用固定的输入和输出语料库,因此它们对新的、未见过的数据的泛化能力较差。
普通语言模型通常采用基于统计的方法,例如n-gram模型或者隐马尔可夫模型等,以及深度学习方法,如循环神经网络(RNN)和卷积神经网络(CNN)等。它们的训练目标是最小化给定语言数据集的困惑度(Perplexity)或交叉熵(Cross-Entropy),以预测下一个单词或字符的概率。
预训练语言模型则通过无监督学习算法对大规模的语料库进行预训练。在这个过程中,模型学习如何表达语言的通用特征和模式,而不是仅仅针对特定的任务进行调整。这使得预训练模型能够更好地理解语言,包括更好的泛化能力和更好的上下文感知能力。预训练模型可以用来进行各种自然语言处理任务,如语言生成、文本分类、命名实体识别和问答系统等。
预训练语言模型则使用了大规模的未标记语料库来预训练模型,例如BERT、GPT等。这些模型使用了一些预训练任务来学习语言的表示,如掩码语言模型(Masked Language Model,MLM)、下一句预测(Next Sentence Prediction,NSP)等。预训练模型的目标是学习到通用的语言表示,以便于迁移到各种下游任务中。
预训练模型通过微调(fine-tuning)来进一步适应特定任务,以提高任务性能。微调通常是在较小的特定任务语料库上完成的,而不是在整个语料库上重新训练整个模型。这使得预训练模型能够在更广泛的应用场景中使用,并获得更好的效果。
综上,PLMs可以看作是一种更加通用、更加强大的语言模型,它不仅可以进行下一个单词或字符的预测,还能够进行文本分类、命名实体识别、问答等多种任务。而TLMs则更加专注于某一特定任务,如机器翻译、语音识别等。
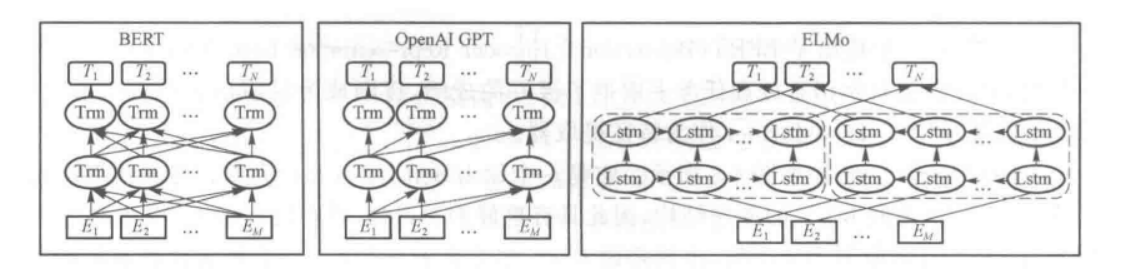
4.1 ELMo模型
Word2Vec的做法的缺点是对于每一个单词都有唯一的一个向量表示,而对于多义词显然这种做法不符合直觉,因为单词的意思和上下文相关,ELMo的做法是只预训练语言模型,而词向量是通过输入的句子实时输出的,这样单词的意思就是上下文相关的了,就可以在很大程度上缓解歧义的发生(动态词向量);
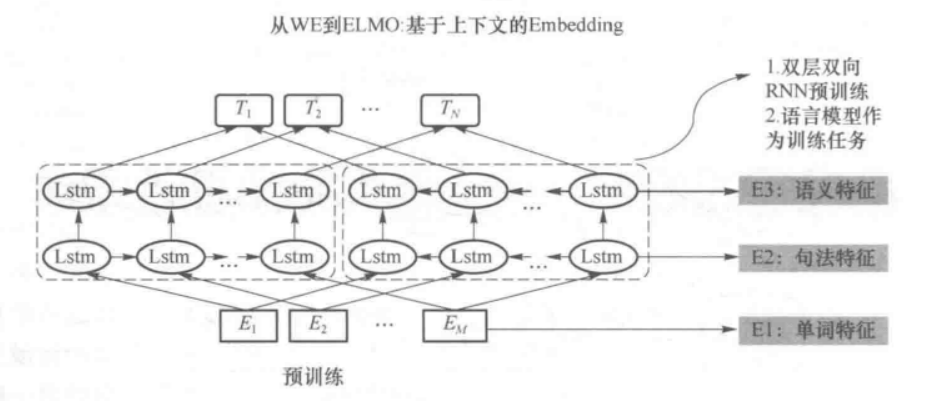
ELMO模型的网络结构采用了双层双向 LSTM,目前语言模型训练的任务目标是根据单词wi的上下文去正确预测单词wi,wi之前的单词序列称为上文,之后的单词序列称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外wi的上文,右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文。每个编码器的深度都是两层LSTM叠加,计算方式为
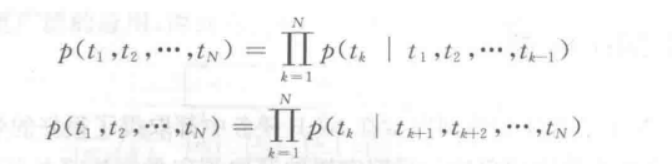
将预训练模型训练好之后可将其用于下游任务
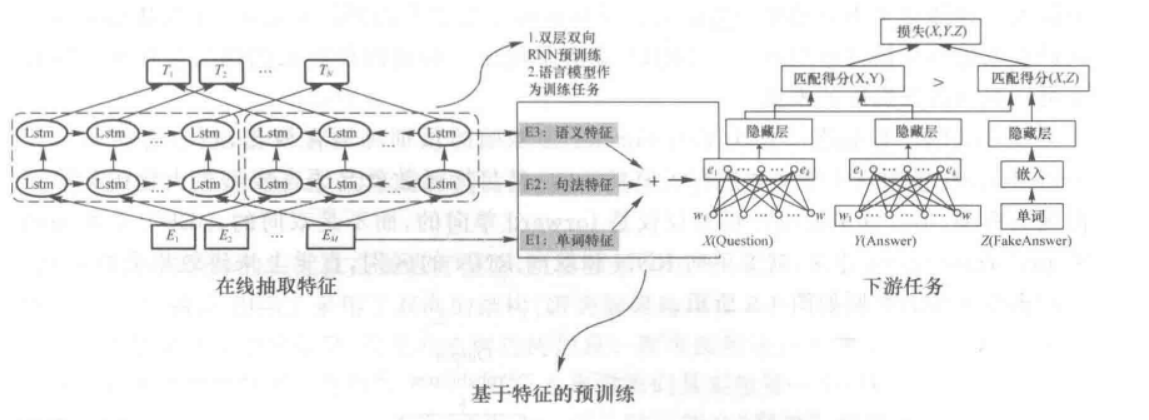
假设下游任务仍然是QA问题,此时对于问句X,先将句子X作为预训练好的ELMo网络的输入,这样句子X中每个单词在ELMo网络中都能获得对应的三个词向量(单词特征、句法特征、语义特征),之后给予这三个词向量中的每一个词向量一个权重,这个权重可以学习得来,根据各自权重累加求和,将三个词向量整合成一个,然后将整合后的这个词向量作为问句X在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
ELMO使用LSTM作为特征提取器,但是LSTM网络的提取能力有限,下面的BERT会使用Transformer作为特征提取器,这也是之后常用的特征提取器;
4.2 BERT模型
(BERT模型可以参考李宏毅的自然语言课程)
BERT主要采用Transformer作为特征提取器,Transformer的结构如下
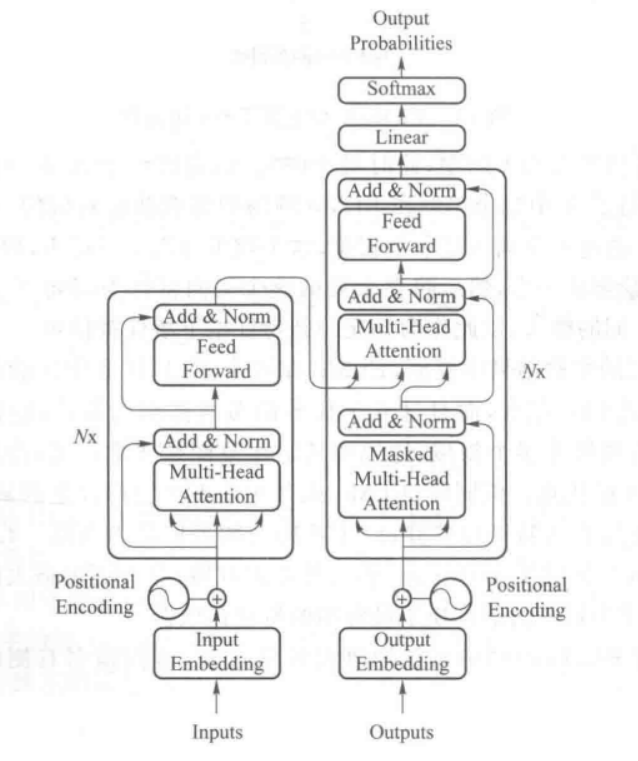
Transformer是由自注意力和前馈神经网络组成的模型,区别于RNN的顺序结构,Transformer拥有更好的并行性;
Transformer 将序列中的任意两个位置之间的距离缩小为一个常量,在构建语言模型的过程中该设计结构能更好地捕捉上下文的信息(虽然 ELMO 用双向LSTM来做特征提取器,但是这两个方向的 LSTM 其实是分开训练的,只是最后在损失层做了简单相加,仅仅从单方向做特征提取是不能描述清楚单词的语义)
BERT是双向的Transformer Block连接,GPT是forward单向(类似双向RNN和单向RNN的区别)
BERT 是一个语言表征模型(Language Representation Model),通过超大数据、巨大模型和极大的计算开销训练而成,在11个自然语言处理的任务中取得了最优。而预训练已经被广泛应用在各个领域了,多是通过大模型大数据来完成,这样的大模型给小规模任务也能带来极大的提高。
第四章 分类任务
自然语言处理一般包含四大主流任务:分类任务、生成式任务、序列标注任务和句子关系推断任务,这些大类的任务又涵盖多种子任务:
分类任务包括文本分类(Text Classification)、情感分析(Sentiment Analysis)、意图识别(Intent Detection)等;
生成式任务包括机器翻译(Machine Translation)、文本摘要(Text Summarization)、阅读理解(Reading Comprehension)、问答系统(Question-Answering System)、对话系统(Dialogue System)等;
序列标注任务包括命名体识别(Name Entity Recognition)、词性标注(Part-of-Speech Tagging)等;
句子关系推断任务包含文本推断(Natural Language Interference)、文本语义相似度(Semantic Text Similarity)等;
1.评价指标
为了判定各种分类算法的好坏,需要制定评价标准来衡量各个算法的性能;
分类任务常用的评价指标包括准确率、错误率、查全率(召回率)、查准率(精确率)、F值、P-R曲线、ROC曲线、AUC等,这些评价指标适用于分类任务的各种子任务;
混淆矩阵Confusion Matrix的定义如下

True Positive(TP)表示将真实正类预测为正类的样本集合,True Negative(TN)表示将真实负类预测为负类的样本集合,False Positive(FP)代表将真实负类预测为正类的样本集合,False Negative(FN)代表将真实正类预测为负类的样本集合;
定义准确率为
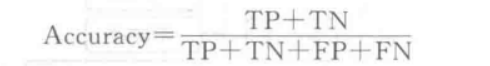
错误率定义为
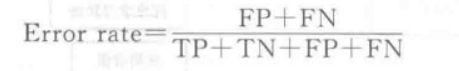
准确率和错误率不仅适用于二分类,对于多分类任务也适用
查全率表示为
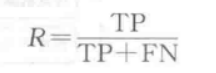
查准率表示为
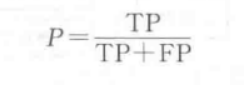
举两个例子凸显查全率和查准率:
- 对于地震的预测,希望查全率非常高,也就是每次地震都希望预测出来,这个时候可以牺牲查准率,即情愿发出1000次警报,把10次地震都预测正确了,也不要预测100次,对了8次漏了2次;
- 在广告推荐场景下,我们希望推送给用户的内容更切合用户的兴趣,以此减少对用户的打扰,因此在保证一定查全率的基础上,更注重于对推荐内容的查准率;
查全率和查准率仅在二分类情况下可以使用,多分类任务可以拆作若干二分类任务处理。查全率和查准率在某些情况下是互相矛盾的,即查全率高时查准率低,查准率高时查全率低
F值定义为
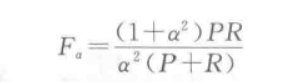
其中,a代表召回率与精确率重要程度的比值,例如a=2表示召回率的重要程度是精确率的两倍,当a=1时,为F1值;
下图是逻辑回归任务的P-R曲线
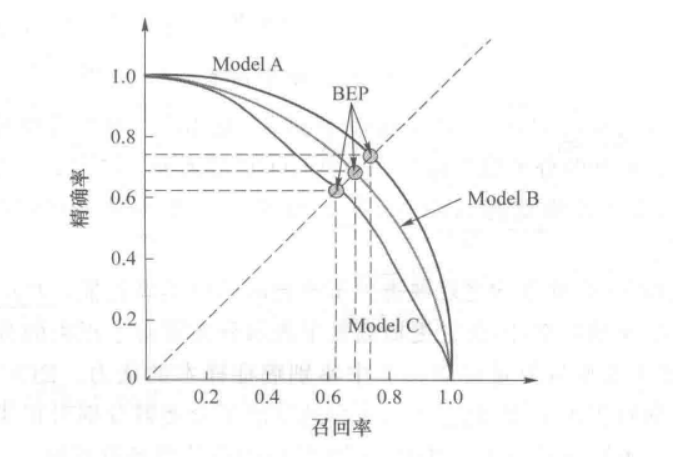
对一个模型的P-R曲线而言,召回率和精确率是互相影响的,只有当召回率和精确率都较高时,F 值才会变高;
对不同模型的 P-R 曲线(即图中的 Model A、Model B、Model C)而言,越靠近右上角的曲线代表该分类器的性能越好,即分类器性能 A>B>C;
图中 BEP(Break-Even Point)代表召回率等于精确率的情况,一般来说,BEP越靠近右上角,代表该分类器效果越好;
P-R 曲线由于计算召回率和精确率,因此它更加侧重于表示分类器对于正类的分类性能;
ROC曲线全称为接收者操作特征曲线,由不同阈值下的真正率和假正率绘制而成;
真正率表示为

假正率表示为
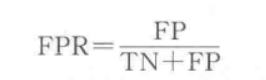
下图是一个ROC曲线的例子,发现真正率越高,假正率越低,即曲线越偏向坐标系左上角分类器的效果越好
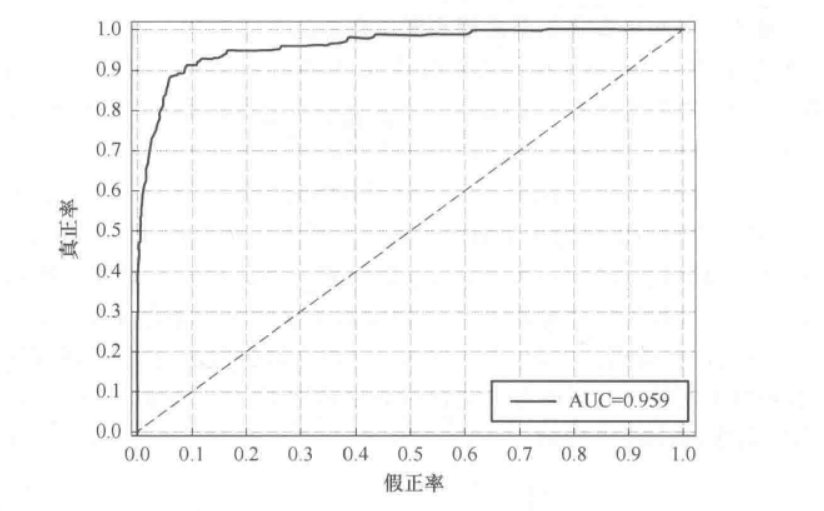
ROC曲线由于计算真正率和假正率,因此它更加兼容地反映了分类器分别对正类和负类的分类能力,P-R 曲线和 ROC 曲线均能反映类别不平衡时的分类器性能,不同场景下 P-R 曲线和ROC曲线的使用各有优缺点;
AUC曲线又称为曲线下面积,表示ROC曲线和横轴围成的面积大小,AUC越大表示模型的分类能力越强(通常AUC的值介于[0.5,1]之间,即介于随机预测和百分之百预测正确);
2.文本分类
文本分类极大地方便了人类各式各样的“判断”需求
文本分类任务可进一步从文本长度、文本内容等方面进行细分:
- 文本可划分为短文本、句子级别的文本和篇章级别的文本;
- 文本可划分为仅包含文字的文本和包含文本以及图片的文本(多模态);
实现文本分类的算法主要包含两类:
- 基于传统机器学习:朴素贝叶斯、支持向量机、决策树、随机森林、K近邻等;
- 基于深度学习:卷积神经网络、循环神经网络、记忆网络、注意力机制、胶囊网络、预训练语言模型等;
2.1 基于机器学习
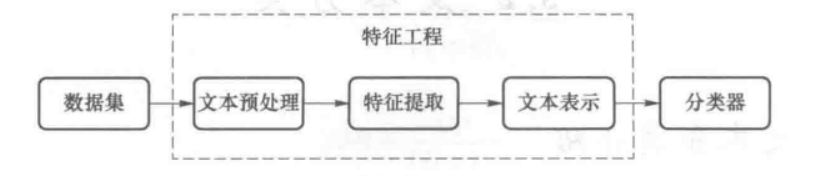
基于传统机器学习的文本分类方法将文本分类问题拆分成特征工程和分类器两部分:
- 特征工程分为文本预处理、特征提取、文本表示三个部分,目的是将文本转换成计算机可以理解的格式
- 分类器利用提取的特征进行分类
特征工程
文本预处理阶段主要用于提取文本中的关键词,滤除非关键词,详情可参考[文本预处理](# 2.文本预处理),接着使用词袋模型、N-gram词袋模型、TF-IDF等提取文本特征,最后将文本向量化
分类器
基于传统机器学习的分类器种类繁多,主要有朴素贝叶斯、支持向量机、决策树、随机森林、K近邻等;
2.1.1 朴素贝叶斯
朴素贝叶斯是一种在假定各特征条件相互独立的情况下(然而这样的假设在实际情况中并不常见),基于贝叶斯定理的分类方法;
对于一个给定的数据集,该方法首先会学习输入输出的联合概率分布,再通过该分布利用贝叶斯定理求出针对输入的最大输出;
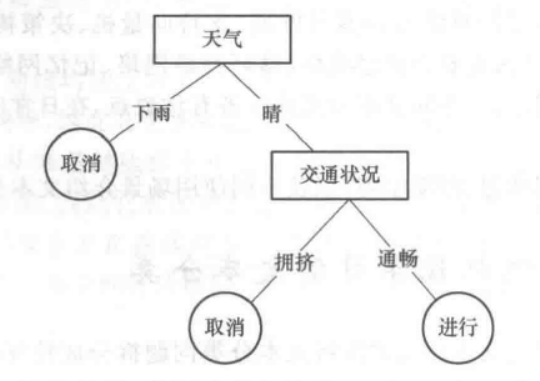
2.1.2 决策树
决策树是一种基本的分类和回归方法;
决策树模型呈树状结构,每个树节点基于某一特征对样本进行二分类;
学习时根据信息增益和损失函数建立决策树,预测时利用树模型进行分类;
决策树的建立通常包含三个步骤:特征选择、决策树生成和决策树的修剪;
典型的决策树模型有ID3、C4.5、CART等算法;
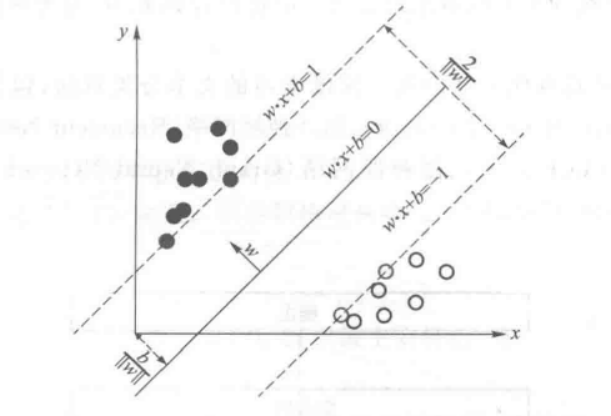
2.1.3 支持向量机
支持向量机是一种二分类模型,它是定义在特征空间上的间隔最大的线性分类器;支持向量机利用核技巧可以针对线性不可分特征进行分类;
支持向量机的核心思想在于如何使得间隔最大化,可看作是一个求解凸二次规划的问题;
2.1.4 K近邻学习
给定一个数据集,其中的实例类别已定,分类时,对新的实例,根据其 K个最近邻的训练实例的类别,通过多数表决等方式进行预测;K 近邻法实际上是利用训练数据集对特征向量空间进行划分,并将其作为分类依据;K值的选择、距离度量和分类决策是K近邻法的三个基本要素;
2.1.5 集成学习
集成学习本身不是一个机器学习算法,集成学习指的是通过构建多个弱学习器以组件强学习器,进而完成学习任务;弱学习器可由朴素贝叶斯、决策树、支持向量机等算法实现;
集成学习既可用于分类问题集成,也可用于回归问题集成;
集成学习主要分为三类:
- Bagging:对分类任务而言,基于Bagging的集成学习利用训练集学习多个弱分类器,再对多个分类器输出的结果进行结合并预测,结合策略包括平均法、投票法、学习法等;
- Boosting:首先从训练集中学习一个弱分类器,再针对弱分类器的学习误差调整训练集的权重,使得被错误学习的样本具有较高的权重,被正确学习的样本具有较低权重;再利用更新后的数据集训练第二个弱分类器,以此循环,直至达到指定的弱分类器数量;最后对这些弱分类器的预测结果进行整合,得到强分类器;
- Stacking:基于Stacking的集成学习算法分为两层,第一层由若干基学习器构建,这些基学习器已在训练集上训练完成,它们的预测结果将作为特征输入第二层的学习器中继续学习,并输出最终的预测结果;
2.2 基于深度学习
基于传统机器学习的文本分类的主要问题在于其文本表示是高维度、高稀疏的,特征表示能力较弱;并且需要人工进行特征工程,成本高;
基于深度学习一方面解决了文本表示的问题,接着利用卷积神经网络、循环神经网络等深度学习网络结构自动获取特征表达能力,实现端到端解决问题而无需人工特征工程;
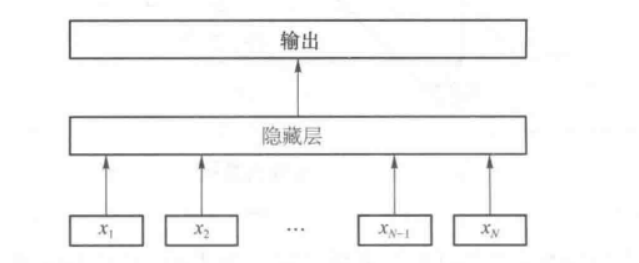
2.2.1 FastText
FastText 首先将本文中的词映射为词向量(WordEmbedding),再对这些词向量做平均池化求得句向量,并将句向量通过隐藏层学习隐藏特征,如多层全连接层,最后通过Softmax 输出对应每个类别的概率;
FastText模型的损失函数为负对数似然函数(也称为交叉熵损失函数),一般表示为
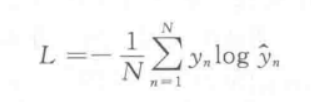
其中N表示样本数量,yn表示第n个样本的真实标签,y’n表示第n个样本的预测类别的概率;
2.2.2 卷积神经网络
TextCNN是一个典型的使用CNN进行文本分类的模型,核心在于利用卷积层和池化层提取文本特征;
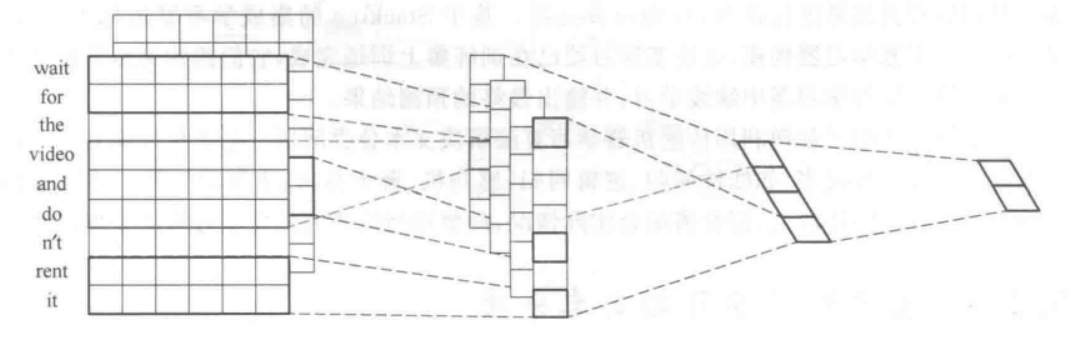
该模型的损失函数为交叉熵损失函数
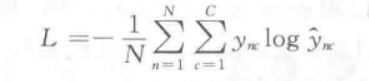
其中N为样本数量,C为类别数量,ync表示第n个样本在第c个类别上的真实标签,y’nc表示第n个样本在第c个类别上的预测概率;
2.2.3 循环神经网络
RNN擅长处理基于事件的序列
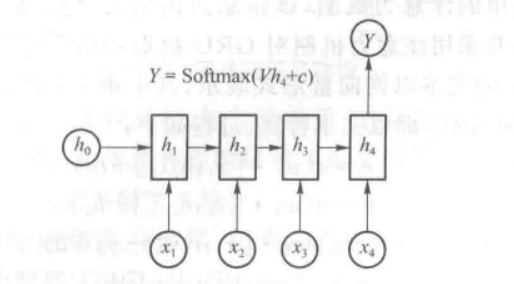
但是RNN在反向传播的过程中会出现关于时间的连乘操作,因此容易产生梯度爆炸和梯度消失(详情参考出现梯度消失与梯度爆炸的原因以及解决方案 - 控球强迫症 - 博客园 (cnblogs.com)),因此引入了RNN的变体长短期记忆LSTM和门控制单元GRU缓解这一问题;
循环神经网络采用交叉熵损失函数
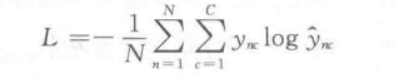
其中N为样本数量,C为类别数量,ync表示第n个样本在第c个类别上的真实标签,y’nc表示第n个样本在第c个类别上的预测概率;
2.2.4 注意力机制
注意力机制顾名思义,就是突出文本中某些重要特征的地位从而帮助提升模型的预测效果;
注意力机制可以和其他模型如Attention+RNN混合使用,也可以单独使用如Transformer;
- 可根据注意力范围不同分为全局注意力机制(Global Attention)和局部注意力机制(Local Attention);
- 可根据注意力权重的大小,分为硬注意力机制(Hard Attention)和软注意力机制(Soft Attention);
- 可根据注意力对象的不同,分为自注意力机制(Self-Attention)和互注意力机制(Co-Attention);
2.2.5 图神经网络
文本中由于词与词之间存在关联关系,如句法关系、语义关系,因此文本可以以结构化形式表示,如句法图、语义图等;
由于图神经网络善于提取图特征,因此我们可以使用图神经网络来学习词的潜在特征,从而获得文本特征;
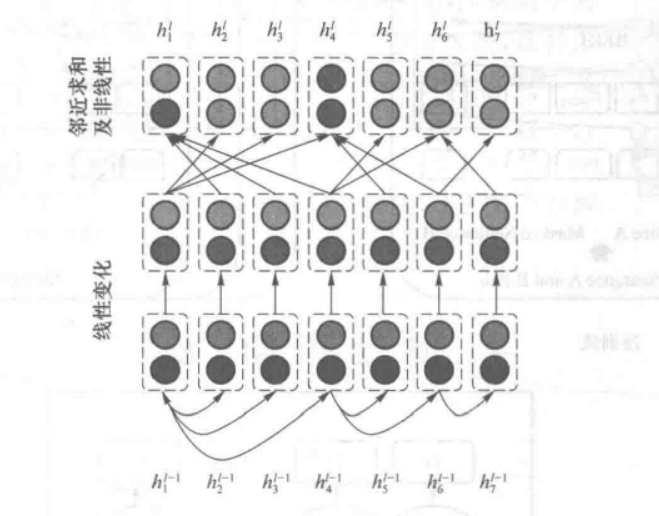
用于分类任务的图神经网络多种多样,包括图卷积神经网络GCN、图注意力网络GAN等;
2.2.6 预训练语言模型
预训练语言模型突破了静态词向量无法解决一词多义的问题,预训练语言模型包括ELMo、GPT、BERT、XLNet等;
BERT由多个Transformer组成(Transformer为自注意力机制)

BERT语言模型分为两个阶段,分别为预训练阶段(Pre-train)和微调阶段(Fine-tuning):
- 在预训练阶段,BERT采用Masked Language Model(MLM)和Next Sentence Prediction(NSP)两个任务对BERT进行训练。MLM对句子中某些词进行遮掩(Mask),然后预测这些被遮掩的地方原有的单词是什么。NSP 则利用两个句子,判断这两个句子是否一句为另一句的下一句话。在MLM和NSP中,句子输入到BERT之前会使用“[CLS]”和“[SEP]”对输入进行包裹,其中“[CLS]”代表整个输入的文本征,“[SEP]”代表句子对的分割标志;
- 在Fine-tuning阶段,BERT可被用于文本分类任务,即在相关数据集上,继续训练BERT参数,并使用”[CLS]”对应的文本特征用于预测类别概率,损失函数可使用交叉熵损失函数;
3.情感分析
情感分析又称为意见挖掘,是对带有情感色彩的主观性文本进行分析、归纳、推理的过程;
情感分析的发展大致分为三个阶段:
- 基于人工或规则的情感分析:准确率高但效率低下;
- 基于传统机器学习的情感分析
- 基于深度学习的情感分析
情感分析的研究邻域主要包括:
- 基于词:旨在给词语赋予情感信息,构建情感词典,情感词典的构建通常采用人工标注或者自动化方法;
- 基于句子和篇章:主要分析文本整体的情感倾向,目前这种情感分析应用范围最广,目前主流解决方法为使用传统机器学习或者深度学习;
- 基于视角:基于视角的情感分析主要研究两点,一是对视角的提取(Aspect Extraction),二是针对视角的情感分析(Aspect-based Sentiment Analysis)。现阶段,解决该种情感分析的主流算法大部分都采用了神经网络,但模型结构与文本分类任务、基于句子和篇章的情感分析存在一定差异;
3.1 基于机器学习
基于传统机器学习的情感分析与文本分类基本类似,其将情感分析拆分为两个步骤,特征工程和分类器。在特征工程阶段,文本将由文本预处理、特征提取、文本表示被表征成计算机可以处理的向量形式。此后,对提取到的特征采用分类算法进行情感分析,这里的分类算法仍包括线性回归、逻辑回归、感知机、K近邻法、朴素贝叶斯、决策树、支持向量机、集成学习、聚类学习等传统机器学习算法,分类过程与文本分类任务大致相似。
3.2 基于深度学习
基于深度学习的情感分析包括以下主流算法:FastText、卷积神经网络、循环神经网络、注意力机制、图神经网络、胶囊网络、预训练模型等。基于句子、篇章级别的情感分析算法与文本分类算法保持一致,而基于视角的情感分析算法由于需针对视角进行分类,所以与之前的文本分类算法产生了较大不同。
3.2.1 基于篇章
下面的模型称为HAN,旨在提取篇章级别的文本特征;
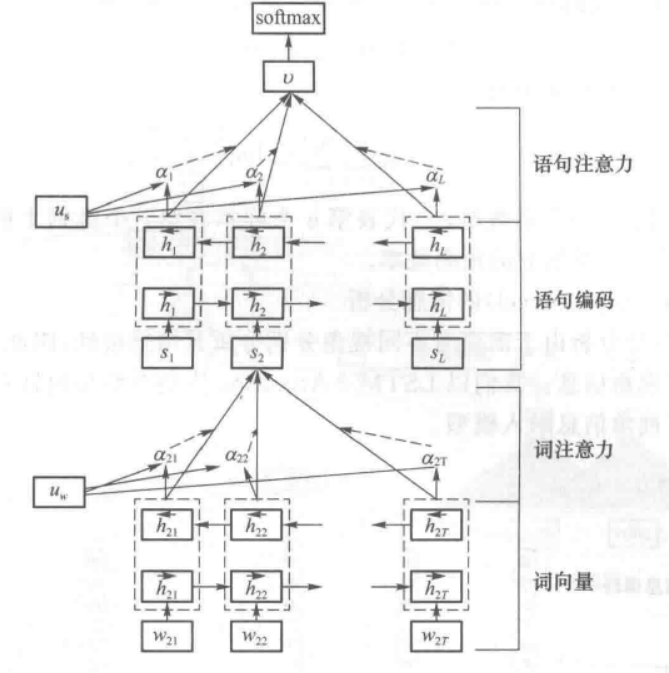
模型主要分为两层,第一层从词特征提取得到句特征,第二层从句特征提取得到段落特征,两次的特征提取过程均结合注意力机制;
3.2.2 基于视角
基于视角的情感分析由于需要对不同视角分别分析其情感极性,因此相比于句子、篇章级别的分类,多了视角信息。以LSTM+Attention为例介绍如何针对视角进行细粒度情感分类,如何将视角信息融入模型。
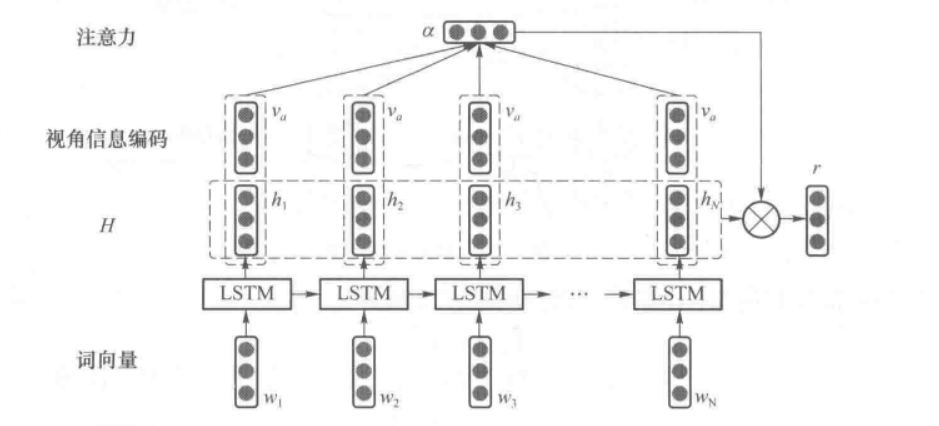
AT-LSTM运用普通LSTM来提取词的上下文特征,再运用结合视角信息的注意力机制求得句表征;
4.意图识别
意图识别的任务在于识别出文本蕴含的意图,主要应用于包含多轮对话的应用,因为多轮开放域对话中用户所述内容范围极广,漫无目的地搜寻并生成答案一方面会导致效率低下,另一方面会使得答复内容不佳,因此需对文本背后所指向的意图进行判别,再针对该意图生成有目的性的答复;
现阶段实现意图识别的主流方法包含三种:
- 基于词典及模板的规则方法:因为不同的意图会有不同的邻域词典,因此可以通过文本和各个邻域词典的匹配程度来判断该文本的意图,这就需要高质量的邻域词典,一般人为构建规则模板;
- 基于查询点击日志的方法:在搜索引擎等类型业务场景下,利用用户点击日志来判断用户意图;
- 基于分类模型的方法:同文本分类和情感分析类似,分为基于传统机器学习和深度学习的算法,其中传统机器学习算法主要包括朴素贝叶斯、决策树、支持向量机、集成学习等,深度学习算法包括卷积神经网络、循环神经网络、注意力机制、预训练语言模型等,这些算法在使用上和其他分类任务相似;
第五章 信息抽取任务
信息抽取作为NLP的任务之一,可以实现实体、关系、事件等事实的快速抽取,这些事实信息可以帮助阅读者快速理解文本语义内容;
广义上讲,信息抽取处理的对象可以是文本、图像、语音和视频等多种媒体,但随着文本信息抽取研究的快速发展,信息抽取往往被用来专指文本信息抽取;
文本信息抽取指从自然语言文本中自动抽取实体、关系、事件等事实信息,并形成结构化数据输出,其目标是从大量数据中准确、快速地获取目标信息,提高信息的利用率;
文本信息抽取广义上主要包括三个阶段:
- 自动处理非结构化的自然语言文本;
- 选择性抽取文本中指定的信息;
- 就抽取的信息形成结构化数据表示;
具体技术路线上信息抽取主要包括四个关键子任务:
- 命名实体识别:从自然语言文本中识别出诸如人名、组织名、日期、时间、地点、特定的数字形式等内容,并为之添加相应的标注信息;
- 实体链指:通过实体链指技术简化、统一实体的表述方式,提高信息抽取结果的准确度;
- 关系抽取:通过关系抽取技术识别实体之间存在的语义上的联系;
- 事件抽取;使用事件抽取技术从含有事件信息的文本中抽取出用户感兴趣的事件信息,将非结构化的自然语言文本以结构化的形式呈现出来;
Q:NLP中的信息抽取是否和知识图谱中的知识抽取存在关联?
A:知识提取和信息提取是相关的概念,指的是从非结构化数据(如文本或图像)中自动提取有意义的insights的过程;
信息提取侧重于从非结构化数据中提取特定的信息片段,而知识提取则侧重于从提取的信息中提取更高层次的见解或知识,知识抽取一般基于信息抽取;
1.命名实体识别
NER的目的是识别出文本中表示命名实体的成分并对其进行分类,命名实体一般被认为是专有名词,它可以是文本中的人名、地名、组织机构名、日期等实体类型;
自然语言文本中的命名实体包含了丰富的语义信息,从原始文本中识别有意义的命名实体或命名实体指称(命名实体在文本中的引用)在自然语言理解中起着至关重要的作用;
命名实体识别的演化过程如下
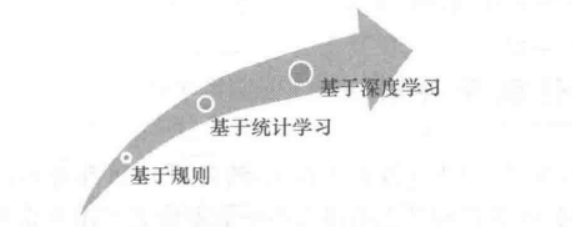
1.1 基于规则
早期的命名实体识别主要是基于规则的方法,由语言学家依据数据集特征人工构建特定规则模板。具体而言,该方法通过观察实体名称自身的特征和短语的常见搭配,人为制定一些规则来构建规则集合。其中,制定规则采用的特征包括统计信息、标点符号、关键字、位置词、中心词等。制定好规则后,通常将文本与规则匹配以实现命名实体识别。
这种基于规则的方法局限性非常明显,不仅要观察和分析实体名称的特征,还要有相关领域专业研究者的参与,这将消耗巨大的时间和人力成本。此外,规则一般只在某一特定的领域内有效,要想应用到其他的领域中则必须修改规则集合。由于人工进行规则迁移的代价比较高,此方法在不同的领域之间缺乏很好的可移植性,且不容易在其他实体类型或数据集上扩展,无法适应数据的变化。
1.2 基于统计学习
Q:传统机器学习和统计学习的区别?
A:
机器学习算法通常被设计用于对新数据进行准确预测,而统计学习方法通常被用于深入了解数据的基本结构,并对所研究的群体进行推断;
机器学习通常涉及建立复杂的模型,这些模型可以捕捉变量之间复杂的关系,而统计学习往往侧重于更容易解释的更简单的模型;
常见的统计学习方法有线性回归、逻辑回归、决策树、随机森林、K近邻、支持向量机、主成分分析等;
常见的机器学习方法有线性回归、逻辑回归、决策树、随机森林、支持向量机、主成分分析、集群、自编码器等;
从上述方法也可以看出,实际上机器学习可以被视为统计学习的延伸,因为它将许多统计方法和技术,如线性回归、逻辑回归和决策树,纳入其算法中。机器学习还引入了新技术,如神经网络和深度学习,可以学习变量之间更复杂的关系;
统计学习和机器学习之间的区别并不总是明确的,术语可能因上下文和应用领域而异。在某些情况下,统计学习方法可能更侧重于推断和理解数据的底层结构,而机器学习方法可能更多地侧重于预测和优化新数据的性能;
命名实体识别大多采用有监督的统计学习模型,主要步骤为:
- 首先根据标注好的数据,应用领域知识和工程技巧设计复杂的特征来表征每个训练样本;
- 然后,通过对训练语料所包含的语义信息进行统计和分析,从训练语料中不断发现有效特征。有效特征可以分为
停用词特征、上下文特征、词典及词性特征、单词特征、核心词特征以及语义特征等; - 最后,应用统计学习算法,训练模型对数据的模式进行学习;
序列标注是目前最为有效,也是最普遍的命名实体识别方法。当使用序列标注处理时,文本中每个词有若干个候选的类别标签,此时命名实体识别的任务就是对文本中的每个词进行序列化的自动标注;
1.3 基于深度学习
深度学习几乎不需要特征工程和邻域知识,通常包括三部分:
输入分布式表示:对输入样本进行分布式表示;
上下文编码:利用输入分布式表示学习上下文编码,获取文本上下文编码的过程可以让模型学习文本的深层次信息,常见的上下文编码结构有卷积神经网络(Convolutional Neural Network)、循环神经网络(Recurrent Neural Network)、递归神经网络(Recursive Neural Network)、神经语言模型(Neural Language Model)等;
标签解码:在得到了文本的上下文编码之后,标签解码模块以其作为输入并预测相应文本对应的标签序列,主流的标签解码结构有
条件随机场CRF、循环神经网络等;
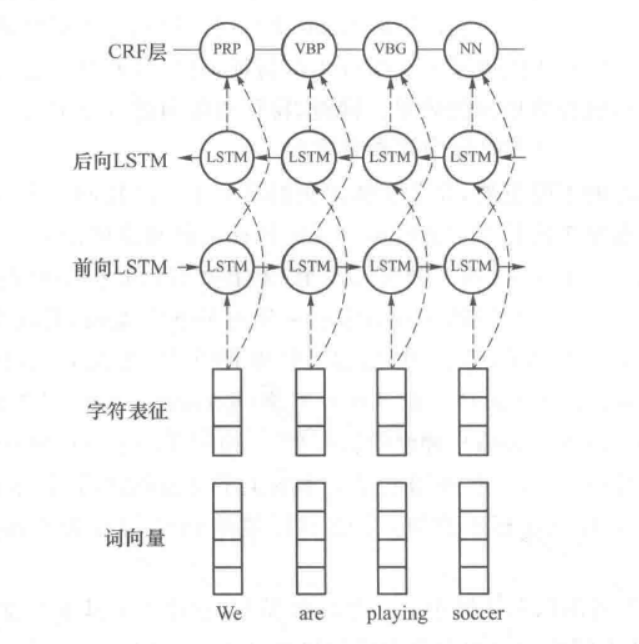
下面是一个简单的基于深度学习的命名实体识别的例子;
首先将每个单词拆分为字符嵌入形式输入CNN,经过卷积和最大池化,得到单词的字符表示。
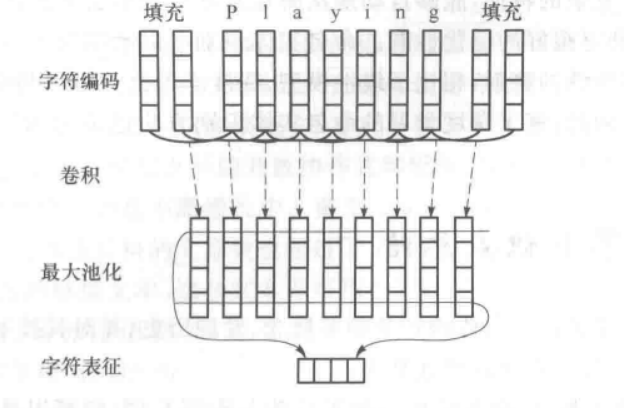
接着把单词的字符表示和词嵌入拼接起来,得到单词的最终表示。
然后将句中每个单词的最终表示输入BiLSTM,对词与词之间的联系进行建模,得到每个位置的单词融合上下文语义的向量表示。
最后将每个单词的向量表示输入条件随机场,输出得到最终预测结果。
2.实体链指
实体链指评测任务旨在确定文中实体所代指的具体对象。自然语言中多个实体可能有共同的一个名称,这意味着一个名称可能对应多个实体(即歧义)。一般情况下,名称在上下文中其指代的对象是明确的,因此根据上下文来自动确定名称所具体指代的实体是实体链指技术的主要目的;
命名实体识别任务和实体链指任务的区别:
- 命名实体识别只需区分实体的类别(如人名、地名和机构名等),而实体链指则需要找到所指代的具体对象。例如,“他去年搬到了华盛顿。”这句话,在命名实体识别任务中只需要知道“华盛顿”指代的是一个地点即可,而在实体链指任务中则需知道“华盛顿”具体指的是华盛顿州,还是华盛顿特区或者是其他什么地方,即实体链指的主要侧重点和难点在于如何消解字面的歧义;
实体链指任务使用的数据包括知识库和标注语料,其中标注语料指包含大量人工标注的链接文本,这些文本可用作实体链指的训练和评测语料;
实体链指的定义:实体链指是在给定文本中,将实体指称与目标知识库中若干候选实体关联起来的过程,也被称为命名实体链接、实体消歧、实体共指消解等,用于将出现在文章中的名称链接到其所指代的实体上去
大部分的实体链指方法都可以分为如下两个步骤:
- 候选实体生成:根据在文本识别出的实体指称,从知识库中选出一组实体作为实体链指的候选实体同时排除那些不可能是目标实体的其他实体;
- 实体消歧:实体歧义是指同一个实体指称在不同上下文中或在特定知识库中对应着多个不同实体。具体来说,一个实体可能存在多个实体指称,或者多个实体可能存在相同的实体指称。实体消歧的主要目标是从文本中识别出实体指称后,根据实体指称及其所在上下文,分析候选实体集合中哪些实体能与实体指称相匹配,对候选实体集中的实体进行排序,并选出最恰当的实体;
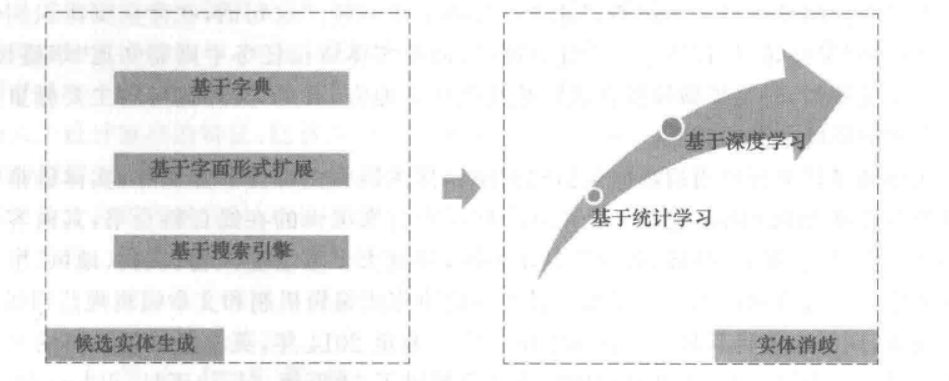
下面是实体链指技术方法的演化过程
2.1 生成候选实体
生成候选实体的方法包括:
- 基于字典:基于字典的方法通过在外部词典等数据源中,以字面匹配的方式进行实体识别,从而获取候选实体集,字典中往往包括实体的多种表达方式,如变体、缩写、混淆名称等。
- 基于字面形式扩展:基于字面形式扩展的方法旨在识别相关文档中实体指称的其他可能的扩展形式,并利用这些扩展形式来生成候选实体集。
- 基于搜索引擎:基于搜索引擎的方法是指将实体指称在搜索引擎中检索出一定数量的相关页面,并将这些页面加入候选实体集。
2.2 实体消歧
实体消歧是实体链指技术面临的主要难题,主要分为:
- 基于统计学习的方法:该类方法主要利用一些统计学特征,如实体相关的统计信息、实体分布信息、实体相似度、文本主题信息等,对实体指称和候选实体进行向量表示,并通过计算实体指称向量和候选实体向量之间的相似度进行实体排序和选择,该方法缺乏对实体语义层面的考量。
- 基于深度学习的方法:基于深度学习实体链指方法的核心思路是通过神经网络学习实体、实体指称、上下文及其相互之间关联关系的向量表示,从而为不同实体及实体之间的语义关系构建统一的表示,并映射在相同的特征空间,最终通过计算语义向量相似度,经排序得到目标实体。
一个经典的深度学习的模型如下,该模型对实体指称及其上下文信息与其候选实体进行语义相似度建模,同时利用文本主题信息衡量实体指称与候选实体在表征同一主题的能力以及它们之间的相似度;
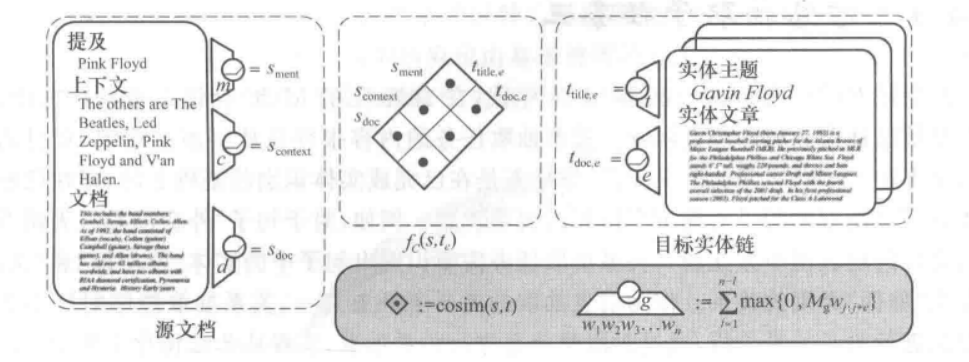
首先,将源文本中的实体、上下文和整个文本使用CNN进行向量表示(图中左部虚线框);
其次,对候选实体和该候选实体在目标知识库中的文本(代表文本主题信息)使用CNN进行向量表示(图中右部虚线框);
最后,将这些信息进行余弦相似度计算(图中中部虚线框),综合计算结果,即可选出最为匹配的候选实体;
3.关系抽取
关系抽取任务的目的是在已完成实体识别的基础上,识别出文本中实体对之间的语义关系,实现从非结构化文本中获取关系信息;
关系抽取的两个重要现实应用:
- 知识图谱:知识图谱的构建过程需要四个步骤,即知识抽取、知识表示、知识融合与知识推理
- 知识抽取是指从一些半结构化、非结构化的数据中提取出
实体、关系、属性等知识要素,其中,关系这一知识要素需要借助关系抽取技术来实现,关系抽取效果的优劣直接决定了知识图谱的准确性与完备性; - 知识表示是指将知识要素表示成分布式的向量形式,为接下来的融合和推理打下基础;
- 知识融合可对实体、关系、属性等指称项与事实对象之间进行消歧,形成高质量的知识库;
- 借助知识推理,在已有的知识库基础上挖掘隐含的知识,以丰富和扩展知识库;
- 关系抽取效果的优劣,直接决定了知识图谱的准确性与完备性。
- 知识抽取是指从一些半结构化、非结构化的数据中提取出
- 自动问答系统:自动问答系统旨在让用户直接用自然语言提问并获取答案,传统的搜索引擎是根据关键词检索并将返回大量相关文档集合,需要用户亲自去查找自己相关的资料,问答系统的实现将使用户在海量数据中查找相关资料时节省大量的时间;问答系统一般包括三个主要部分:
- 问题处理:搜索引擎首先对问题进行分析,划分该问题所属的关系类型(例如,地理位置)
- 信息检索:根据模式(例如,地理位置《北邮,?)),去匹配由关系抽取的结果所构建的知识库,获取了目标实体(例如,北京市海淀区西土城路10号);其中的匹配环节需要关系抽取的参与,因此关系抽取的效果也直接决定了自动问答系统的优劣;
- 答案抽取:最终将查询结果返回给搜索引擎;
关系抽取技术方法的演化过程如下
3.1 基于规则
早期,关系抽取领域通常使用基于规则的方法,基于规则的关系抽取需领域专家针对目标关系的语义特点,手工设定符合某种词法、句法和语义规则的规则集合,并将待识别的句子与规则集合进行匹配,匹配成功则认为该句子具有对应规则的关系。该方法需事先人工构造规则集合,这会耗费大量的时间和人力,且由于规则是针对领域构建的,其移植性较差。
3.2 基于统计学习
基于统计学习的关系抽取一般将关系抽取问题转化为分类问题,通过特征工程选取文本表征中具有代表性的特征训练分类模型,以判定实体对之间的语义关系;
- 有监督统计学习:有监督学习方法通过人工标注训练数据来获取样本,并将样本输入到预先选择的特征集中以训练分类模型。根据输入样本的文本语义表示方式的不同,可以将有监督统计学习方法分为基于特征向量和基于核函数的方法。
- 基于特征向量方法的核心是特征工程,通过启发式的方法选取特征集合,使用多层次的语言特征构造向量,以实现对输入样本文本的语义进行表征。基于特征向量的方法无须专家预先设定模式集合,节约了很多人力成本,但该方法很难再找出适合关系抽取任务的新特征,因此一些研究者转向基于核函数的方法。
- 基于核函数的方法无须像基于特征向量的方法一样构建特征集合,而是以文本的句法分析结果及其各类变形作为核函数的输入,通过计算输入示例之间的相似度,训练分类模型。但是,基于核函数的方法使用隐式方式表示特征,没有显式构造和处理语义信息,这使得这些方法的泛化能力很差。同时,较高的计算复杂度限制了该类方法在大型语料库上的应用。
- 半监督统计学习:半监督统计学习方法实现了在较少的人工参与和标注语料资源的情况下进行关系抽取,使用大量未标记数据和已标记数据进行模型学习。半监督统计学习方法解决关系抽取问题时,主要采取基于自举的思路,首先人工构造少量关系示例作为初始种子集合,然后利用模式学习或者模型训练的方法,通过迭代过程,不断扩展该关系示例集合,最终获取足够规模的关系示例,完成关系抽取的任务。半监督学习可能出现语义漂移的问题且无法对文本的语义进行深入分析,导致模型泛化能力较差。
- 无监督统计学习:无监督统计学习的训练样本是未经标注的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
3.3 基于深度学习
基于深度学习的关系抽取使用文本的语义表征来进行关系的抽取,在效果上大大超越了之前的基于知识工程的方法和基于统计学习的方法,并成为关系抽取任务的主流方式。基于深度学习的有监督关系抽取方法面临的最大问题是神经网络的训练需要大量的带标签语料,语料的标注是一个十分费时费力的过程,且语料的质量也大大影响模型训练的效果。近年来逐渐兴起的远程监督方法一定程度上可以克服这个问题,但是远程监督带来的噪声问题又成为一个新的难点,基于深度学习的关系抽取的研究方兴未艾。
4.事件抽取
事件作为信息的一种表现形式,定义为特定的人、物在特定时间和特定地点相互作用的客观事实。组成事件的元素包括:
- 触发词:触发词代表能够触动事件发生的词,是决定该事件所属类型的重要特征词;
- 论元:指与该事件相关的人物、时间、地点、事物等实体;
- 论元角色:描述了论元在事件中扮演的角色,体现了论元与该事件的语义关系;
事件抽取的目标是从非结构化文本中准确有效的发现特定的事件及事件元素,将用自然语言表达的事件以结构化的形式呈现出来;
这里举一个例子,“在A市,一辆坦克向酒店开火时,一名摄影师死亡。”这条文本中包含两个事件:
- 第一个事件是“袭击”(触发词:开火),包括三个论元:A市(论元角色:地点),酒店和摄影师(论元角色:目标)以及坦克(论元角色:武器);
- 第二个事件是“死亡”(触发词:死亡),包括三个论元:A市(论元角色:地点),摄影师(论元角色:受害者)和坦克(论元角色:工具);
事件抽取方法的演化过程如下
因为前面已经介绍过多次这些方法,而这些方法在大体上针对不同的任务的基本逻辑是相同的,所以这里不再介绍,可自行Google或参考教材《自然语言处理》第六章。
第六章 语言分析任务
本章给出语言分析任务的基本流程框架,其中的每个子任务涉及的技术都是NLP的关键技术;
参考链接:
1.语言处理层次
语言处理的层次自底向上依次为:
- 形态分析 (Morphological Analysis)
- 句法分析 (Syntax)
- 语义分析 (Semantic)
- 语用分析 (Pragmatics)
- 篇章分析 (Discourse)
- 世界知识分析 (World)
从词汇、句法直到世界知识,下一层就是上一层的基础,当下一层表述不合理时,上一层也无法实现正确表达;
1.1 形态分析
形态分析也称为词汇分析,指的是从完整书写的词形式中识别出词干,例如英语单词cowardly =coward(词干)+ ly(后缀);
一般形态分析也包括词性分析,上述例子中的ly就是将名词变为形容词;
中文分词:汉语或者大多数东亚语言中的词汇分析与英语有所不同,汉语是词汇间无间隔的句子书写方式,所以这就要求,从句子(即字序列)中切分出词,这个处理称做中文分词
大多数自然语言分析系统通常首先需要将文本分割为有语言学意义的符号单元。广义上来说,这个过程包括分词(切分)、词原型提取、词性标注以及命名实体/短语识别等一大类词法处理任务。
1.2 句法分析
句法和语义是关联的两个语言层次的概念,句法有时候也不够严格地被称为语法或文法(grammer),严格来说,语法 = 句法 + 语义;
句法指定义了句子内部各成分之间的形式化的相对位置关系,通常来说,句法 = 词典 + 规则;
句法分析的目标是给各句子成份分配句法类别标签,并确定各成份之间的句法关系;
1.3 语义分析
语义分析的目的是为意义完整的话语(utterances)赋予意义,包括词义及词义组合,这是一种与上下文无关的意义;
上下文相关的语义分析包括:
- 句子层面的语义角色标注任务:给出句子内部的谓词-论元结构
- 词义消歧
- 指代消解
1.4 语用分析
指文本符号或会话与会话生产者/用户之间的关系;
它对不同的情境上下文背景中,对话语的解释重大影响;
这部分工作困难重重,目前还没有在此方面取得突破性进展;
1.5 篇章分析
针对文本整体论述结构的分析,同时,还负责分析文本句子之间的关系;
1.6 世界知识分析
世界知识是指不受限制的常识知识,这个任务是负责推断出每个语言用户必须具备的一般世界知识;
2.形态分析
Morphological Analysis 译为形态分析,又译为词汇分析,其中形态学Morphological是语言学的一个分支,研究词的内部结构,包括屈折变化和构词法两个部分;
2.1 词的构成
(1)词是基于最小的语义单元-词素构成的
词素可以分成两种:
词干:play cat friend
词缀:-ed -s un- -ly
词缀又可以分为两种:
- 前缀:un-
- 后缀:-ed -s un- -ly
(2)变形是同一个单词的不同形式

(3)形态变换可以用来形成新词
衍生 = 词干 + 词缀
- friend + -ly = friendly
- un- + friendly = unfriendly
- unfriendly + -ness = unfriendlyness
组合 = 词干 + 词干
- rail + way = railway
2.2 分词
分词(tokenize)就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作;
2.3 词形还原
词形还原主要包含词干化Steamming和原形化Lemmatizing;
stemming是去掉词缀,比如:
play -> play
replayed -> re-play-ed
computerized -> comput-er-ize-d
Lemmatizing是找到原形,其实也就是基于变形或衍生的不同

2.4 词形标记
以句子为单位,而不是单词为单位,为每一个词标上词形,词形标记通常被用于下游的任务:命名实体识别、依赖解析:
- 默认标注器
- 正则表达式标注器
- 查询标注器
- N-Gram标注器
2.5 命名实体识别
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等;
3.句法分析
参考链接:
- 成分句法:(2条消息) 成分句法分析 & 依存句法分析 Parsing 知识图谱_成分句法分析 依存句法分析_APTX___Yellow的博客-CSDN博客;
- 依存文法:(2条消息) 句法分析:依存分析(Dependency Parsing)_满腹的小不甘_静静的博客-CSDN博客;
- 依存文法:(2条消息) 成分句法分析&依存文法分析_使用包含2个隐藏层的神经网络,实现transition-based依存解析中每一步transitio_lzk_nus的博客-CSDN博客;
句法分析的基本任务是确定句子的句法结构或句子中词汇之间的依赖关系,句法分析一般不是语言分析任务的最终目标,但是它往往是实现最终目标的重要环节;
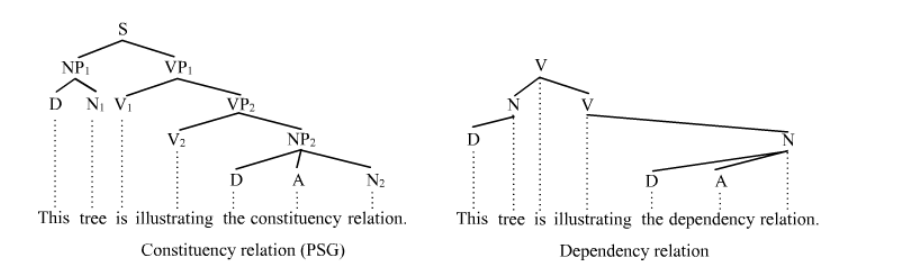
句法分析主要分为
- 句法结构分析:又被称为成分结构分析或短语结构分析;
- 依存关系分析:又称为依存句法分析或依存结构分析,简称依存分析;
- “完全句法分析”或“完全短语结构分析”指的是以获得整个句子的句法结构为目的的句法分析,“局部分析”或“浅层分析”指的是以获得局部成分为目的的句法分析;
- 成分句法分析基于词语结构的文法,依存句法分析通过词语间的语法关系的文法。通俗理解就是,前者是从一个句子、分解为若干个词语组、最后到分解到一个单词,建立语法结构分析;后者是通过词语之间的语言学联系,建立语法结构分析。
3.1 基本概念
(如果学习了编译原理 - Tintoki_blog (gintoki-jpg.github.io),对于下面这些概念应该不会陌生)
解析器
解析器用于实现解析任务,用于获得输入文本数据,并根据形式语法检查正确语法后给出输入文本的结构表示,解析器通常以解析树、抽象语法树或其他层次结构的形式构建数据结构;
解析器的主要内容包括
- 报告语法错误;
- 从经常发生的错误中恢复,以便继续处理程序的其余部分;
- 创建解析树;
- 创建符号表;
- 生成中间表示(IR);
解析器主要有两种类型
- 自顶而下分析:在这种解析中,解析器从开始符号开始建造解析树,然后尝试将开始符号转换为输入。最常见的自顶而下解析形式使用递归过程来处理输入,递归下降解析的主要缺点是回溯;
- 自下而上分析:在这种类型的解析中,解析器从输入符号开始,并尝试构造直到开始符号的解析器树;
无论是自顶向下还是自底向上的parsing搜索算法,都有共同的缺陷:
- 由于不牵涉任何语义层面处理,因此无法处理句子歧义问题,即同一个句子会有不止一种合乎文法的结构;
- 没有对每个节点各种扩展赋予权值,因此无法给出一个最合适的语法树;
因此实际的解析器搜索算法几乎都是基于这两者的基础上的优化算法,如CKY算法等;
派生
为了得到输入字符串,需要一系列的产生式规则,派生是一组产生式规则。在解析过程中,需要确定要替换的非终端,以及决定要替换的非终端的产生式规则;
主要的派生方式有两种:
- 最左端派生:在最左边的推导中,输入的句子形态从左到右被扫描和替换。
- 最后端派生:在最左边的推导中,输入的句子形态从后到左被扫描和替换。
解析树
解析树可以定义为派生的图形描述,派生的起始符号用作解析树的根。在每个解析树中,叶节点是终端,内部节点是非终端。解析树的一个属性是按顺序遍历解析树将生成原始输入字符串。
语法
语法对于描述格式良好的程序的句法结构是非常必要和重要的,语法在文学意义上表示自然语言中的句法规则;
语法根据解析类型可被分为短语/成分结构语法和依赖语法:
- 短语结构语法:一种基于成分关系的语法,成分语法和成分关系的基本要点为
- 所有相关的框架都从成分关系的角度来看待句子结构;
- 构成关系来源于拉丁语和希腊语的主谓划分;
- 从名词短语NP和动词短语VP两个方面来理解基本从句结构;
- 依赖语法:与短语结构语法相反,是建立在依存关系基础上的,依存语法和依存关系的基本要点为
- 在DG中,语言单位(即词)通过有向连接相互链接;
- 动词称为从句结构的中心;
- 每一个其他的句法单位都与动词有直接联系。这些语法单位被称为依存项;
3.2 成分句法分析
句子的组成成分叫做句子成分,也称为句法成分,句子成分由词或词组充当。在句子中,词与词之间有一定的组合关系,按照不同的关系,可以把句子分为不同的组成成分。句法结构分析也被称为语言/句子识别;
成分句法分析的任务是给定一个句子,分析出句子的短语结构句法树,比如给定句子“The little boy likes red tomatoes”,它对应的成分句法树如下
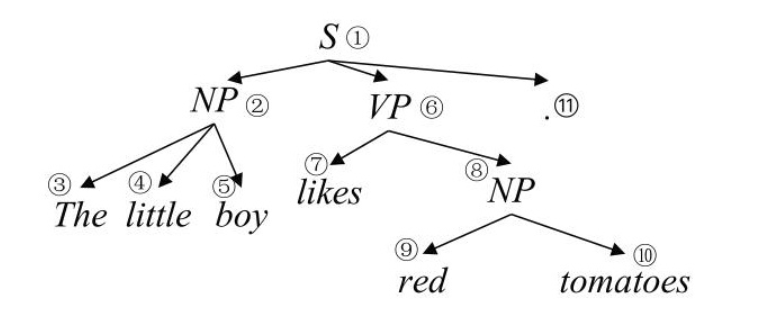
完成上述分析过程的程序模块称为句法结构分析器,简称分析器parser,如果一个句子有多种结构表示,句法分析器应该分析出该句子最有可能的结构;
常见任务
句法结构分析的基本任务主要有三个:
判断输入的字符串是否属于某种语言;
消除输入句子中的词法和结构等方面的歧义;
分析输入句子的内部结构,如成分构成、上下文关系等;
常见方法
与前面介绍的大多数自然语言处理任务的基本方法相同,句法结构分析可以分为基于规则的分析方法、基于统计的分析方法以及近年来基于深度学习的方法;
基于规则的分析方法:其基本思路是由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构歧义的消除;
基于统计的分析方法:统计句法分析中目前最成功当属基于概率上下文无关文法(PCFG或SCFG)。该方法采用的模型主要包括词汇化的概率模型(lexicalized probabilistic model)和非词汇化的概率模型(unlexicalized probabilistic model)两种;
基于深度学习的分析方法:近几年深度学习在nlp基础任务取得了不错的效果;
3.3 依存句法分析
每棵成分语法树都能转换为依存关系树,原理是先找出每个成分的中心词,然后让另一个非中心词依赖于此中心词;
相比于 CFG,依存关系语法更关注与词语间关系、高度词汇化,能更好的应用于问答系统与关系抽取等场景。另外,这种语法对就这种词语的顺序要求相对比较低,所以在处理一些语法复杂、次序排列更灵活的语言时,依存关系语法比 CFG 更有优势;
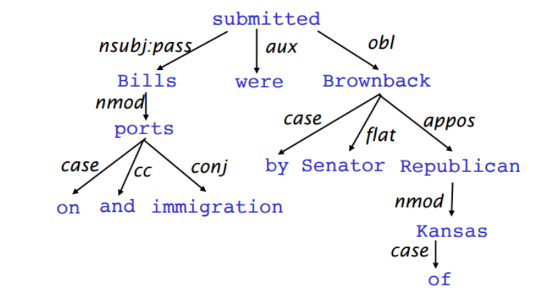
依存文法分析考虑的是句子中单词与单词之间的依存关系,而这种依存关系其实就是语法,例如主谓、动宾、形容词修饰名词等。因为构建语法树的时候选择根节点是随机的,所以选择不同的根节点可能得到不同的树结构,依存句法分析的任务就是在所有可能的树结构中选择出最合适的结构,一般依存句法分析的将原来的句子使用箭头标注出关系

(图中增加了一个根节点“ROOT”,使得completed也有依赖对象)
另一种Dependency Structure的表现形式是树状结构
3.3.1 基于转移
Transition-based Parsing基于转移的依存分析可以看作是状态机,对于句子S,state由三部分构成(Stack,Buffer,Set):
- σ-Stack:最开始只存放一个Root节点;
- β-Buffer:装有需要解析的一个句子;
- A-Set:保存分析出来的依赖关系,初始是空的;

state之间的Transition分为三类:

依存句法分析的任务就是不断地把Buffer中的词往Stack中推,跟Stack中的词判断是否有依赖关系,有的话则输出到Set中,直到Buffer中的词全部推出,Stack中也仅剩一个Root,分析完毕;
3.3.2 基于神经网络
神经依存分析主要利用了神经网络的方法代替了传统机器学习方法,用低维分布式表示来代替传统方法的复杂的高维稀疏特征表示。整个解析的过程,依然是根据之前的Transition-based方法,也就是「根据当前的状态,即Stack、Buffer、Set的当前状态,来构建特征,然后预测出下一步的动作」;
在神经依存分析中构建特征的方法很简单:利用的信息包括词(word)、词性(postag)和依赖关系的标签(label),对这三者都进行低维分布式表示,即通过Embedding的方法,把离散的word、label、tag都转化成低维向量表示;对于一个状态,可以选取stack、Buffer、set中的某些词和关系,构成一个集合,然后将集合中所有的embedding向量都拼接起来,这样就构成了该状态的特征表示;
选择哪些词、关系需要借助「经验」;
第七章 NLP&机器学习
本章主要详细介绍NLP邻域一些核心的、较新的知识点。之所以有这部分还是因为NLP在最近几年的发展太快了,书上的那些知识只能算作远古遗留,而了解最新的这些技术可以帮助我们更快从书面转移到实践
参考链接(注意参考资料尽量选择最近两年的,NLP的某些上古时代的文章观点几乎过时):
- (强推)李宏毅2021/2022春机器学习课程_哔哩哔哩_bilibili;
- (6条消息) Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT_nlp(十九):基于transformer的对话系统:rnn、seq2seq、bert、gpt2-CSDN博客;
1.NLP核心技术
尽量将这些知识点之间联系起来形成一整个知识框架。注意以下技术点并不是按照线性顺序罗列的,这些知识点之间的联系在每小节开头会给出
1.1 词嵌入
跳转:[词嵌入](# 3.文本向量化)
词嵌入简单来说就是将文本使用向量表示(即文本向量化),其中一种比较流行的方法就是word2vec算法。
Word2vec是一种用于生成单词嵌入的流行算法。换句话说,Word2vec是一种技术,用于根据给定语料库中单词的上下文创建单词在高维空间中的向量表示(嵌入)。
Word2vec算法通过在大量文本数据上训练神经网络来学习这些嵌入。在训练期间,算法考虑特定目标单词并尝试基于其向量表示预测周围单词(上下文)。通过调整神经网络的权重,算法试图最大化正确预测上下文单词的概率。
由Word2vec算法生成的单词嵌入可以用于各种自然语言处理(NLP)任务,例如文本分类、机器翻译、情感分析等等。
1.2 语言模型
跳转:[语言模型](# 第三章 语言模型)
词嵌入与语言模型的关系:
Word2vec是一种用于生成单词嵌入的技术,单词嵌入是单词在高维空间中的向量表示。这些嵌入通常作为语言模型的输入,语言模型可以生成文本或预测一系列单词的可能性。
Word2vec嵌入用作输入,可以提高语言模型的性能,特别是在训练数据量有限的情况下。通过使用预训练的单词嵌入,语言模型可以从更大、更多样化的单词和上下文集中进行学习。
一方面,虽然Word2vec和语言模型是不同的技术,但在自然语言处理领域中它们密切相关,并经常一起使用来提高各种NLP任务的性能。另一方面,一些最广泛使用的语言模型,例如GPT(预训练生成式转换器)和BERT(来自Transformer的双向编码器表示),使用的神经网络与Word2vec中使用的相似。
1.3 Encoder-Decoder架构
(1)Seq2Seq架构与Encoder-Decoder架构的关系:
Seq2Seq架构是一种特定于序列输入和输出数据的编码器-解码器架构,专门针对文本或语音等顺序数据的特定需求
编码器-解码器架构是解决各种机器学习任务的通用框架,包括自然语言处理(NLP)。基本思想是使用两个神经网络:一个编码器网络,将输入数据编码为固定长度的向量表示,一个解码器网络,将向量表示解码为输出数据。
Seq2Seq架构是一种特定于处理顺序输入和输出数据的编码器-解码器架构。它由两个递归神经网络(RNNs)组成,一个用于编码输入序列,另一个用于解码输出序列。编码器RNN处理输入序列并产生一个固定长度的向量表示,然后将其传递给解码器RNN生成输出序列。
除了seq2seq,还有一些其他的encoder-decoder架构,比如Transformer、BERT以及GPT,每个架构都有其独特的优点和适用场景,具体选择哪个取决于任务需求和数据集特点。
(2)Encoder-Decoder与语言模型的关系:
编码器-解码器架构和语言模型是不同的NLP技术,但是在某些条件下,编码器-解码器模型可以被视为一种语言模型,因为它能够基于输入数据(例如提示或不完整的句子)生成输出数据(例如文本)。
实际上很多人根本就没有认真区分过架构和语言模型这两个词,所以有时候混用也没关系。
针对Seq2Seq序列问题,比如翻译一句话,可以通过Encoder-Decoder模型来解决。
Encoder-Decoder指的是同时具备编码和解码的框架(如下图所示),借助中间的定长向量C传递信息
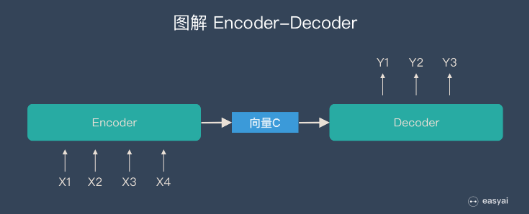
针对不同的任务,可以选择不同的编码器和解码器(常选用RNN、LSTM或GRU)
1.3.1 Seq2Seq架构
Seq2Seq架构与语言模型的关系:
语言模型是一种可以生成文本或预测一系列单词的可能性的模型。它们通常用于语言生成、文本分类和语言建模等任务。
Seq2Seq(序列到序列)是一种神经网络架构,通常用于自然语言处理(NLP)任务,例如机器翻译和文本摘要。该架构旨在接受一系列输入标记(例如单词或字符)并生成一系列输出标记。
Seq2Seq序列可以用作一种语言模型(应用领域交叉),其中输入和输出序列代表同一文本的不同部分。例如,在机器翻译中,输入序列可能是一种语言中的句子,而输出序列则是将该句子翻译成另一种语言的结果。同时Seq2Seq模型可以使用类似于语言模型的技术进行训练,例如最大似然估计或困惑度最小化。还可以使用注意力机制进行增强,这在语言模型中通常用于提高性能。
Seq2Seq架构和语言模型都是NLP中重要的工具,这两个工具没有孰优孰劣之分(毕竟它俩的应用范围不同):
- Seq2Seq架构通常用于涉及生成或转换序列的任务,例如机器翻译、文本摘要和对话生成。旨在将可变长度的标记序列作为输入,并生成可变长度的标记序列作为输出;
- 语言模型在NLP中用于广泛的任务,包括语言生成、文本分类、情感分析等。语言模型旨在预测一系列单词的概率或根据给定提示生成新的文本;
使用哪种工具取决于具体的任务和输入输出数据的性质。
Seq2Seq(Sequence-to-sequence)正如字面意思:输入一个序列,输出另一个序列,其中输入序列和输出序列的长度是可变的。任何满足[输入序列,输出序列]条件的架构都可以称为Seq2Seq序列架构。
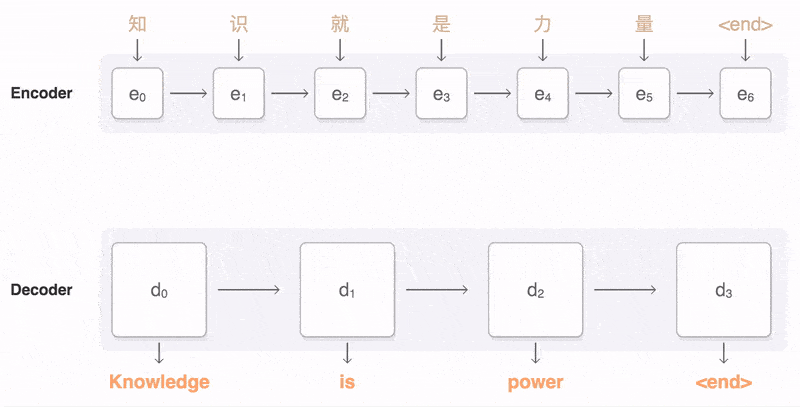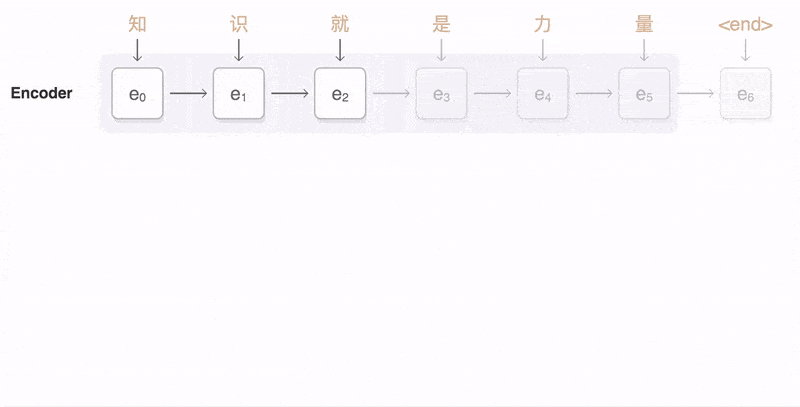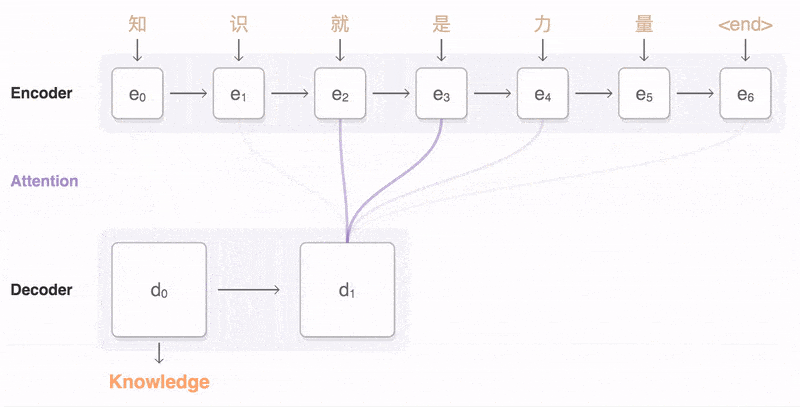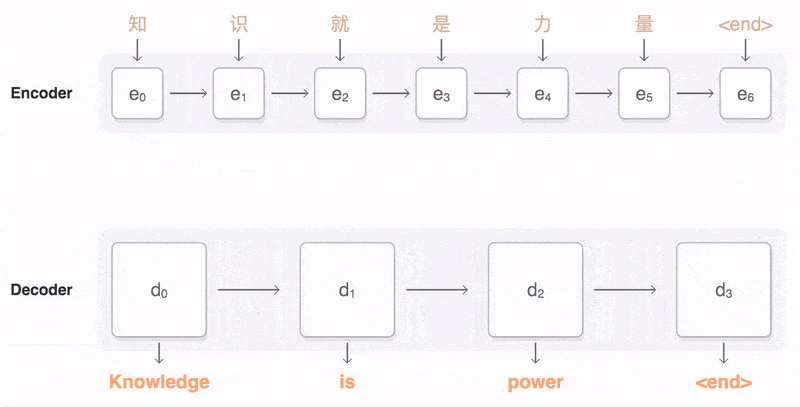
1.3.2 Attention&Self-Attention
Attention机制详解可以看视频理解,纯看公式确实难以理解,当然仅仅只是形成一个直观感受还是很容易的
Seq2Seq与Attention机制的关系:
注意力机制和Seq2Seq模型密切相关,因为注意力通常用于增强Seq2Seq模型的性能(当然Attention机制并不一定必须在Encoder-Decoder 框架下使用)。
在Seq2Seq模型中,编码器网络生成输入序列的固定长度向量表示,然后将其用作解码器网络的初始隐藏状态。解码器网络随后根据输入序列和先前生成的标记逐个生成输出序列。然而,在许多情况下,输入序列的不同部分可能与输出序列的不同部分相关性更大。注意力机制通过允许解码器在每个时间步骤上有选择地关注不同部分的输入序列,取决于解码器的当前状态和先前生成的标记,解决了这个问题。
换句话说,注意力机制使解码器能够集中关注输入序列中最相关的部分,而不是平等地处理整个序列。这可以显著提高Seq2Seq模型的性能,特别是对于涉及长输入序列或输入输出序列之间存在复杂依赖关系的任务。
总的来说,注意力机制是自然语言处理(NLP)领域中的一个重要工具,并且通常与Seq2Seq模型结合使用,以改善各种语言相关任务的性能,例如机器翻译和文本摘要。
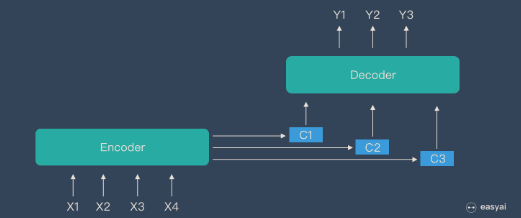
普通的Seq2Seq模型中,Encoder(编码器)和 Decoder(解码器)之间只有一个「向量C」来传递信息,且C的长度固定。这意味着当输入句子比较长时,所有语义完全转换为一个中间语义向量C来表示,单词原始的信息已经消失,可想而知会丢失很多细节信息。
为了解决上述问题,提出了Attention机制。Attention机制的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量C」,而是编码成一个向量的序列(如下图)。
- 输出:每个输出的词Y会受到每个输入X
1,X2,X3,X4的整体影响,不是只受某一个词的影响,毕竟整个输入语句是整体而连贯的,但同时每个输入词对每个输出的影响又是不一样的,即每个输出Y受输入X1,X2,X3,X4的影响权重不一样,而这个权重便是由Attention计算,也就是所谓的注意力分配系数,计算每一项输入对输出权重的影响大小; - 编码:在根据给到的信息进行编码时(或称特征提取),不同信息的重要程度是不一样的(可用权重表示),即有些信息是无关紧要的,比如一些语气助词之类的,所以这个时候在编码时,就可以有的放矢,根据不同的重要程度针对性汲取相关信息;
下面这个例子分别展示使用普通的Seq2Seq和使用了Attention机制的Seq2Seq进行翻译的区别
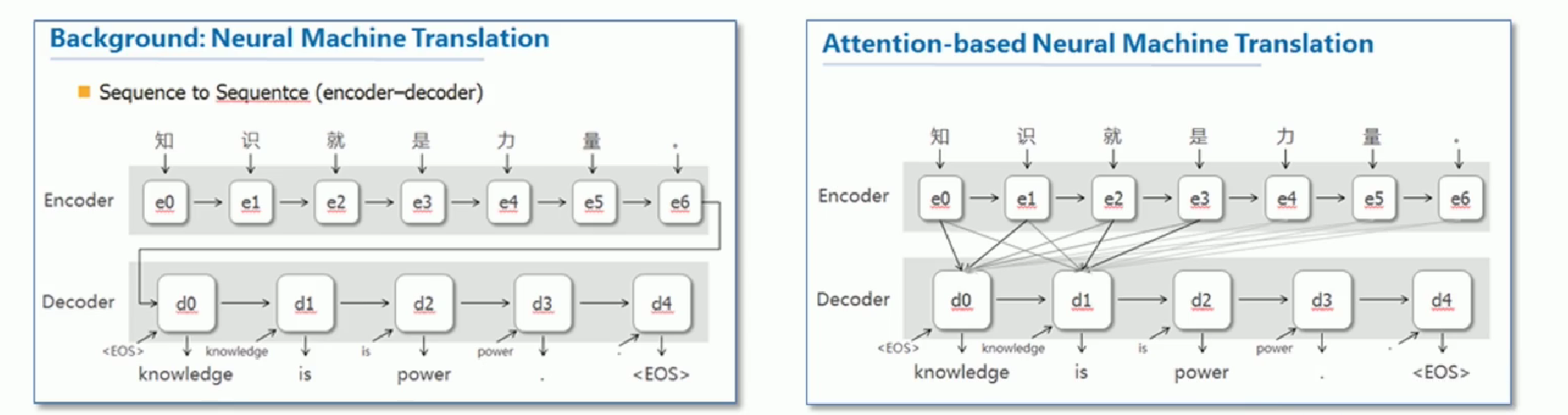
1.4 Transformer架构
(1)Transformer和language model的关系:
Transformer是一种神经网络结构,由一系列注意力机制组成,允许模型权衡输入序列中不同部分的重要性。通过这样做,Transformer能够并行处理序列,而不是按顺序处理,使其比先前的神经网络结构(如递归 神经网络)更加高效。
可以基于Transformer架构构建语言模型,用于预测一系列单词的概率。事实上,许多最先进的语言模型,如GPT-3,都基于Transformer架构。这些模型通过利用Transformer的自我注意机制来模拟输入序列中的长程依赖关系,能够生成高度连贯和流畅的文本。
(2)Transformer是否比Seq2Seq架构更加先进?
Transformer专门设计用于解决Seq2Seq模型的一些限制,例如无法有效处理长序列以及建模句子中远距离单词之间的依赖关系的困难。Transformer通过使用自我注意机制来克服这些限制,这使其能够同时关注输入序列中的所有位置。
此外,Transformer被证明比Seq2Seq更具有计算效率,因为它可以并行计算输入序列并减少所需的计算次数。
因为介绍transformer的篇幅太大了,不放在这个小专题里,额外开一节,参考[Transformer](# 2.Transformer详解)。下面主要介绍的都是基于Transformer架构发展而来的当今较流行的语言模型。
1.4.2 BERT语言模型
跳转:[BERT语言模型](# 4.2 BERT模型)
参考链接(BERT和GPT的知识点可能会有交叉,因此我们放在一起讲):关于ChatGPT:GPT和BERT的差别(易懂版) - 知乎 (zhihu.com);
BERT和Transformer的关系:
BERT基于Transformer架构,该架构于2017年推出,利用多层双向Transformer编码器对大量文本数据进行预训练。预训练过程涉及预测句子中的掩码单词和预测序列中的下一个句子,这使BERT能够学习单词之间的上下文关系。
BERT是NLP中Transformer架构最著名、最广泛使用的应用之一。Transformer架构是BERT的基础,它使BERT能够捕获单词之间的长距离依赖关系并理解单词的上下文使用方式。
BERT在之前一直是最流行的方向,几乎统治了所有的NLP领域,事实上在GPT-3发布之前BERT一直优于GPT。BERT和GPT两者之间的主要区别:
- BERT的特点是,双向预训练语言模型+fine-tuning(微调)
- GPT的特点是,自回归预训练语言模型+Prompting(指示/提示)
(1)预训练
在BERT的预训练任务中,主要使用“填空题”的方式完成预训练 – 即预训练时随机盖住一些输入的文字,被mask的部分是随机决定的,当我们输入一个句子时,其中的一些词会被随机mask
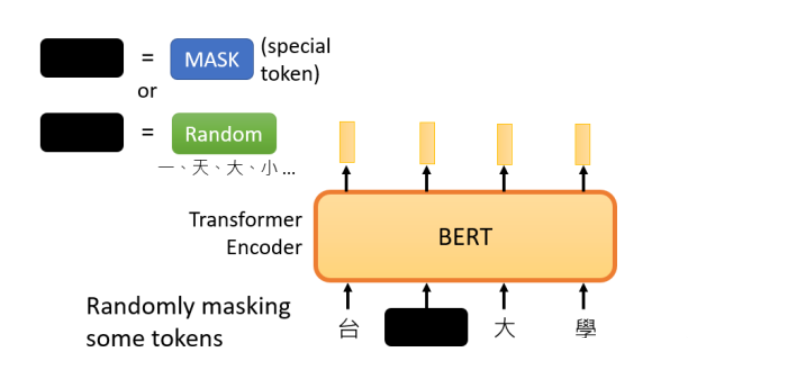
Mask的实现方法主要有两种:
- 用一个特殊的符号替换句子中的一个词,我们用 “MASK “标记来表示这个特殊符号,可以把它看作一个新字,这个字完全是一个新词,它不在字典里,这意味着mask了原文;
- 随机把某一个字换成另一个字。原本中文的”湾”字被放在这里,选择另一个中文字来替换它,可以变成 “一 “字,变成 “天 “字,变成 “大 “字,或者变成 “小 “字,这里只是用随机选择的某个字来替换;
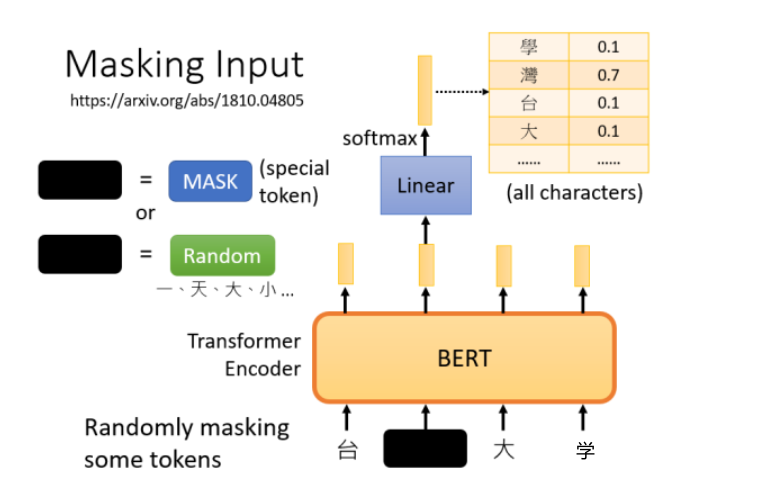
两种方法都可以使用。使用哪种方法也是随机决定的。因此,当BERT进行训练时,向BERT输入一个句子,先随机决定哪一部分的汉字将被mask。mask后,一样是输入一个序列,我们把BERT的相应输出看作是另一个序列,接下来,我们在输入序列中寻找mask部分的相应输出,然后,这个向量将通过一个Linear transform,输入向量将与一个矩阵相乘,然后做softmax,输出一个分布。
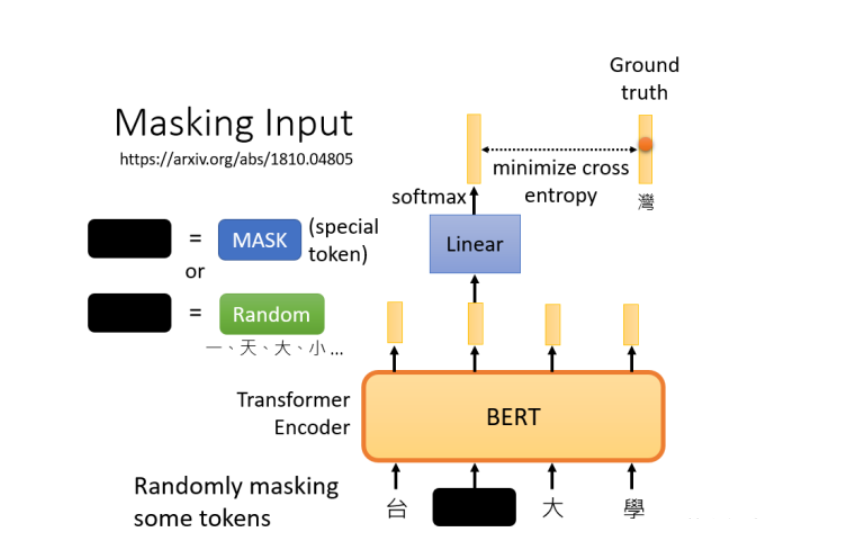
在训练过程中,我们知道被mask的字符是什么,而BERT不知道,我们可以用一个one-hot vector来表示这个字符,并使输出和one-hot vector之间的交叉熵损失最小。
(2)fine-tuning
这里以情感分类任务为例介绍如何使用预训练好的BERT模型(我们称这种方式为fine-tuning)。
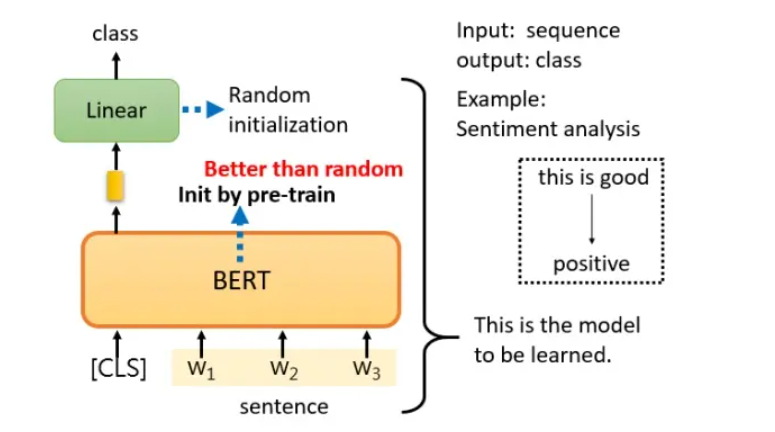
此处的sentence是需要用来判断情绪的句子,添加一个[CLS]标记后放在sentence前面,然后将整个句子扔到BERT中。4个输入会对应4个输出,只需要看对应[CLS]的输出部分,该输出是一个向量,对它进行Linear transform后进行Softmax就可以得到情感分类的结果。根据不同的任务进行对应的操作来获得较好的结果,这就是fine-tuning。
1.4.3 GPT语言模型
(1)GPT和BERT的关系:
- BERT,全称为Bidirectional Encoder Representations from Transformers,是由Google AI Language团队在2018年提出的预训练语言模型;
- GPT(Generative Pre-trained Transformer)是由OpenAI研究团队在2018年提出的一种语言模型;
GPT是由OpenAI于2018年推出的一系列大规模预训练语言模型。与BERT类似,GPT也基于Transformer架构,并且在大量文本数据上进行预训练。然而,BERT主要设计用于需要理解给定句子上下文的任务,而GPT则旨在生成连贯自然的文本。
GPT的预训练过程涉及预测序列中的下一个单词,从而使其学习单词之间的关系并生成符合语法和语境要求的文本。 GPT模型已用于各种NLP任务,例如文本完成,文本分类和机器翻译。
GPT和BERT之间存在关系,因为它们都基于Transformer架构并利用大量文本数据进行预训练。然而,这两种模型的预训练目标是不同的,BERT专注于理解上下文,而GPT专注于生成自然语言。
(2)Google推出的聊天机器人chat-gpt就是基于GPT语言模型实现。
GPT语言模型起源于对传统预训练语言模型(如ELMO和ULMFit)的改进和升级。
(1)预训练
GPT要做的任务是,预测接下来会出现的token是什么。假设训练资料里面,有一个句子是“台湾大学”,那GPT拿到该句子的时候,选取<BOS>这个Token对应的输出,作为Embedding的结果,用这个embedding去预测下一个应该出现的token是什么。
embedding使用h表示,通过一个Liner Transform再通过一个softmax后得到一个概率分布,训练的目标是该输出的概率分布和正确答案的交叉熵越小越好。
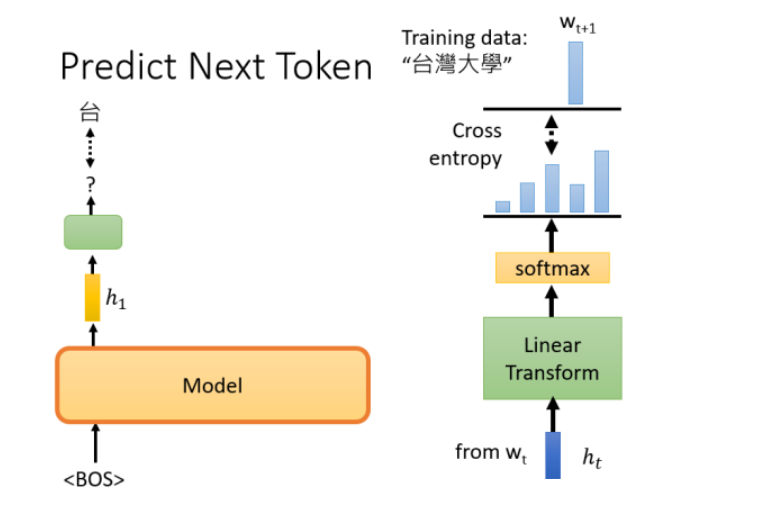
根据句子“台湾大学”,下一个应该出现的token是”台”,即训练模型的目标就是,根据BOS给的embedding,输出”台”这个token。
接下来要做的就是依次迭代,输入<BOS>和“台”,经过embedding后预测“湾”…
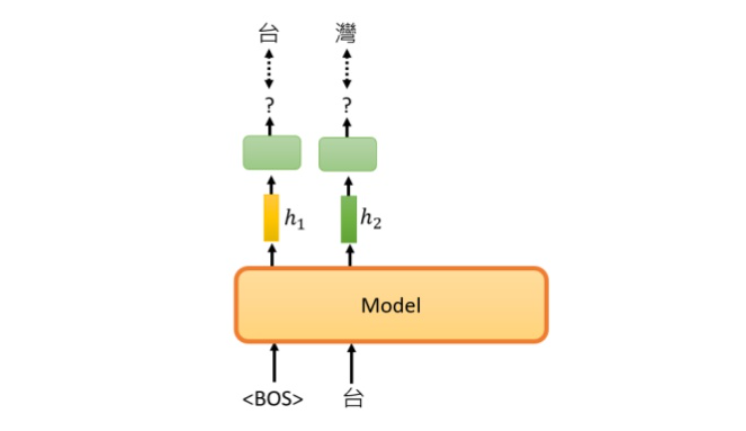
GPT网络的训练不需要标注数据,因此它非常适合超大数据集体量的情况。
(2)Prompting
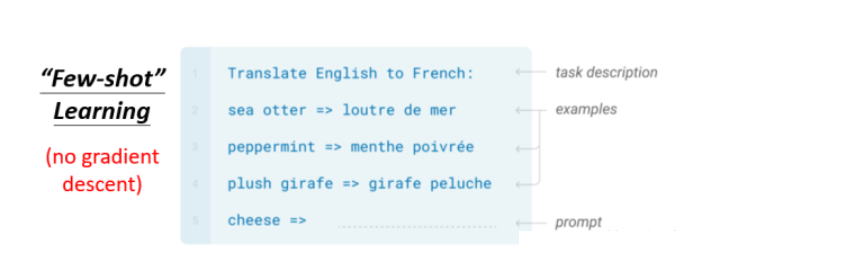
GPT的参数比BERT大很多,因此使用fine-tuning将耗费很多时间,GPT提出了一种更接近人类的使用方式,即Prompting。
假设我们要使用预训练的GPT模型做翻译,只需要给出“task description”以及”examples”,那么接下来我们给出要翻译的内容也就是”prompt”的时候,GPT会根据“task description”以及”examples”学会翻译。
1.4.4 LaMDA语言模型
(LaMDA现在(2023/4/28)在网上并没有找到特别多的信息(当然我指的是中文信息,毕竟以我现在的能力只看得懂中文的资料),因此相关介绍也比较少)
(1)LaMDA语言模型和GPT语言模型的关系:
- Google LaMDA专门为对话型AI应用而设计,经过训练可在对话上下文中理解和生成自然语言响应。它旨在用于诸如聊天机器人、语音助手和其他对话界面等任务。
- OpenAI GPT是一种更通用的语言模型,旨在根据给定的提示或输入生成自然语言文本。它是在大量文本数据上训练的,并可进行微调,以用于特定的自然语言处理任务,例如语言翻译、问答或情感分析。
总的来说,虽然LaMDA和GPT都使用基于Transformer的神经网络架构,但它们的预期用例和训练目标是不同的。LaMDA专注于对话型AI应用,而GPT是一种更通用的语言模型,可用于各种自然语言处理任务的微调。
(2)Google推出的聊天机器人Bard就是基于LaMDA语言模型实现。
LaMDA的全称是Language Model for Dialogue Applications,主要用于对话应用程序。与前辈BERT、GPT-3一样,LaMDA也基于Transformer架构。与其他模型不同的是,LaMDA在对话方面接受了更多训练。
2.Transformer详解
参考链接:
2.1 模型背景
目前在序列建模和转换问题中,如语言建模和机器翻译,所采用的主流框架为[Encoder-Decoder框架](# 1.3 Encoder-Decoder架构)。
传统的Encoder-Decoder一般采用RNN作为主要方法,基于RNN所发展出来的LSTM和GRU也被曾认为是解决该问题最先进的方法。而RNN模型的计算被限制为顺序,这种机制阻碍了样本训练的并行化,又会导致在计算过程中信息丢失从而引发长期依赖问题。RNN及其衍生网络(LSTM,GRU)的缺点就是慢,问题在于前后隐藏状态的依赖性导致无法实现并行。
Transformer抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。使用Attention机制是考虑到RNN及其变体的计算限制为顺序,即RNN相关算法只能从左向右依次计算或者从右向左依次计算,这样的顺序机制带来两个问题:
- 时间片t的计算依赖时刻t-1的计算结果,这样限制了模型的并行能力。
- 顺序计算的过程中信息会丢失。尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
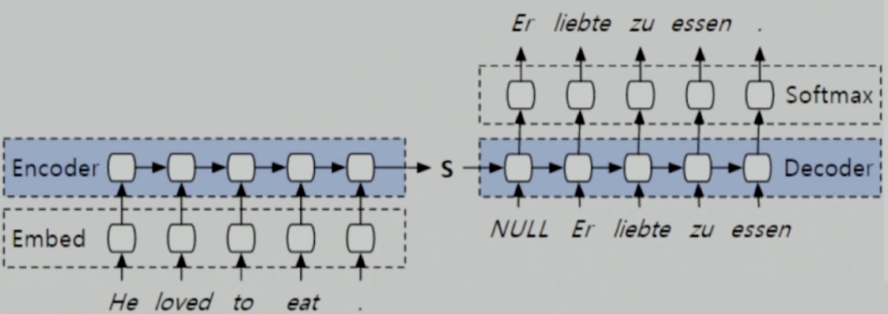
上图中的Encoder和Decoder,无论使用RNN或它的哪种变体,都无法避免输出的单词是前后相互依赖的关系,也就是说对于后面的输出,它依赖前面状态和当前输入。这就意味着,我们想要得到这个输出,那就必须得到前面的状态。所以必须要走完上一步,才能走下一步。所以说它的计算被限制为顺序,阻碍了样本的并行化训练。
Transformer主要有以下特点:
- 基于Attention机制,将序列中任意两个位置之间的距离缩小为一个常量。
- Transformer利用self-attention机制实现快速并行,改进了RNN/LSTM最被人诟病的训练慢的缺点,同时也符合现有GPU框架的矩阵化训练。
- Transformer可以增加到非常深的深度(利用残差机制),充分发掘DNN模型的特性,提升模型准确率。
2.2 模型结构
经典的Transformer结构如下
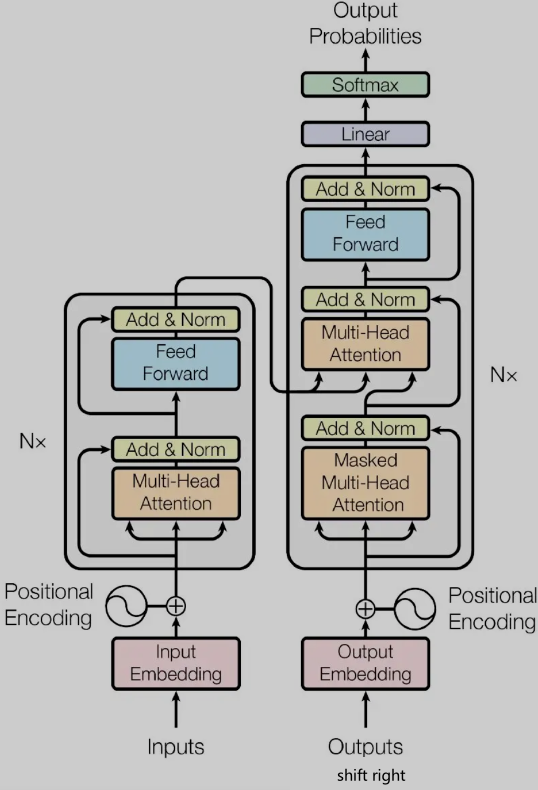
左边部分是encoder,右边部分是decoder,两边都有Nx表示不止一个encoder和decoder(encoder的结构都是相同的,但是参数不同,decoder同理);
自底向上看各部分为:
- 首先是encoder部分的输入和decoder部分的输入,经过Embedding;
- 其次是Positional Encoding(位置编码);
- 其次是Multi-Head Attention(多头注意力机制);
- 其次是Add&Norm(跳跃连接&LayerNorm);
- 其次是Feed Forward(前馈神经网络);
- 其次是输出层(Linear、Softmax)。
基于上述结构,可以举一个机器翻译的例子
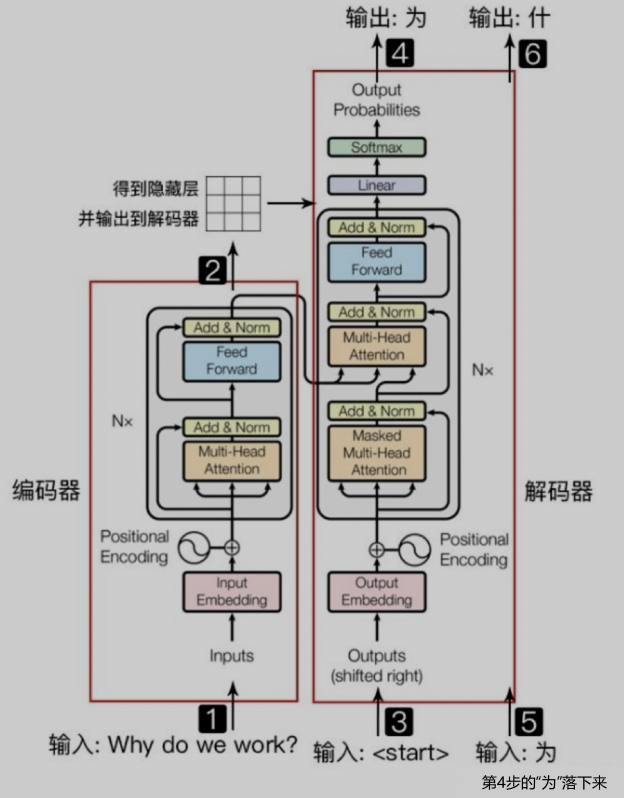
第一步:输入要翻译的英文,即encoder端的输入:”Why do we work?”;
第二步:经过encoder部分的运算后,将隐层输出到decoder端(可以认为encoder传输的是语义信息);
第三步:decoder部分输入,这里需要注意的是因为预测的时候是一个单词一个单词预测的,所以先输入的是起始符”start”
第四步:经过decoder部分的运算输出”为”;
第五步:有了”为”之后,可以用”start 为”预测”什”;
然后重复执行,直到遇到结束符表示预测结束。
2.2.1 Embedding&位置编码
在一个机器翻译场景中的数据预处理部分一般包括以下几个步骤:
- 1.将字符串转为数字编码;
- 2.按句子长度进行过滤;
- 3.添加起始符与结束符;
- 4.mini-batch、padding填充。
embedding就是用一个向量来表征一个单词或是一个句子,解决了传统onehot离散化带来的稀疏性问题。embedding作为网络的第一层被输入。
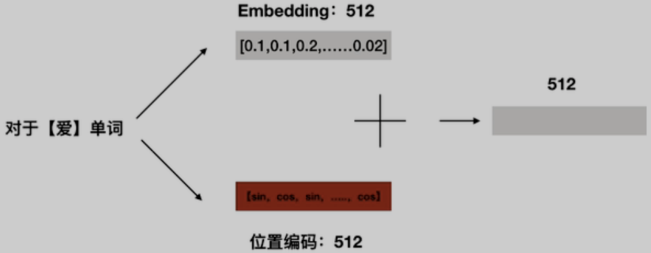
比如将“我喜欢你”这句话进行一个512维度的embedding,如下图
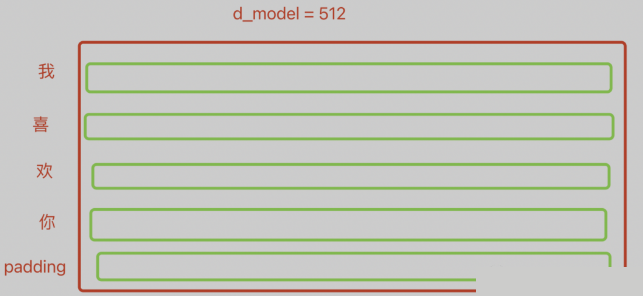
前馈神经网络的输入分别是[batch_size, src_len, d_model],对于上述例子来说就是[3, 5, 512]
embedding之后,还需要加上位置编码才能作为输入。引入位置编码是因为attention与RNN相比具有并行处理能力但是不具有位置信息显示的能力(比如“我爱你”,Transformer没有办法理解“我”需要在“爱”前面)。因此为了保留位置信息,需要引入位置编码,引入位置编码的同时也引入了绝对位置和相对位置的信息。

图中表示偶数位置使用sin函数,奇数位置使用cos函数(具体原因得看论文)
- pos指的是当前的字在这句话中的位置,比如起始符s的pos就是1,“我”的pos就是2;
- 2i代表向量编码的偶数位置,2i+1代表向量编码的奇数位置;
- dmodel指的是emb向量的维度(比如上面就是512),是一个定值;
将位置编码和embedding进行对位相加,作为encoder和decoder的输入
2.2.2 encoder部分
Encoder部分输入是单词的Embedding,再加上位置编码,然后进入一个统一的结构,这个结构可以循环很多次(N次),也就是说有很多层(N层)。每一层又可以分成Attention层和全连接层,再额外加了一些处理,比如Skip Connection,做跳跃连接,然后还加了Normalization层。
未完待续…(临近期末了,确实没什么时间慢慢看这部分内容,感兴趣直接看保姆级讲解Transformer (qq.com),这个文章讲Transformer超级详细。
2.3 模型应用
Transformer模型诞生以来,后续的研究和发展主要从模型效率、模型泛化和模型适配应用三个方面演进。
模型效率方面主要是通过调整Tansformer结构模块的内容以及整体结构的调整,降低计算和内存的复杂度。
- 关于具体模块内容的调整中,有的是对注意力机制的调整,如稀疏注意化、线性化注意力、改进多头注意力机制等;有的是对前馈神经网络的调整,如调整激活函数、调整FFN的模型容量等;其他也有对输入输出的Positional Encoding方式的调整,如采用绝对位置、相对位置等,或者是对层归一化(LN)方式的调整,如采用Pre-LN或者直接替换LN等。
- 关于整体结构的调整方面,主要的研究方向包括Tansformer轻量化、强化Cross-Block联接、引入自适应时间(ACT)等。
模型泛化方面主要是引入结构偏差或正则化,对大规模未标记数据进行预训练等。基于Transfomer的预训练模型主要可以分成三类
- 一类是仅用到编码器(Encoder),典型的是BERT模型,通常用于自然语言理解任务。
- 一类是仅用到解码器(Decoder),代表的有GPT系列模型。
- 还有一类就是同时采用编码器(Encoder)-解码器(Decoder),典型的是BART模型,在BERT基础上引入去噪目标,这类模型通常具备语言理解和生成的能力。
模型适配应用方面主要是将Transformer模型应用到更多的领域。
- Transformer模型首先是在NLP领域应用,如机器翻译及后续的BERT、GPT系列等NLP大模型。
- Transformer也被应用到计算机视觉领域,用于图像分类、物体检测、图像生成和视频处理等任务,代表性如DERT、ViT等。
- 此外,Transforme也被应用到了语音领域,用于语音识别、语音合成、语音增强和音乐生成等任务。
- NLP、视觉和语音构成的多模态场景,也是近年来Transformer应用的热点方向,例如视觉问答、视觉常识推理、语音到文本翻译和文本到图像生成等。
- 除了AI通常的NLP、视觉和语音等场景,Transformer也被应用生命科技领域,AlphaFold在蛋白结构预测方面取得重大突破。