初级项目_中文分词
参考链接(搜索关键词“BPE编程作业”):
1.BPE算法原理
参考链接:
- (11条消息) 简介NLP中的Tokenization(基于Word,Subword 和 Character)_iioSnail的博客-CSDN博客;
- BPE 算法原理及使用指南【深入浅出】 - 知乎 (zhihu.com);
- NLP三大Subword模型详解:BPE、WordPiece、ULM - 知乎 (zhihu.com);
- 优化处理:使用 BPE 原理进行汉语字词切分(重制版) (less-bug.com);
- 分词结果的评价指标:NLP入门(2)-分词结果评价及实战 - 腾讯云开发者社区-腾讯云 (tencent.com);
基本概念:
- Word:一个单词,例如hello
- Character:一个字母,例如a
- Subword:
- 若使用单词进行编码,由于单词多且杂,容易导致OOV问题,而且不太好编码
- 若使用字母进行编码,又太少,容易丢失语义;所以人们发明了subword,将一个word分成多个subword,同时兼顾了1,2两个问题。
- OOV:Out of Vocabulary,意思是有些单词在词典中查询不到,例如一些根据词根现造的词,或者拼写错误的词等。
- Tokenization:将一段文本分成若干个元素,一个元素称为一个Token,而 token 是之后要被编码成向量然后送往模型的基本单位。
- Token:Token可以是一个单词、一个字母、甚至是“半个单词”
在介绍BPE算法之前,需要从分词说起,分词是文本预处理中尤其重要的一步,一个完整的分词流程如下:
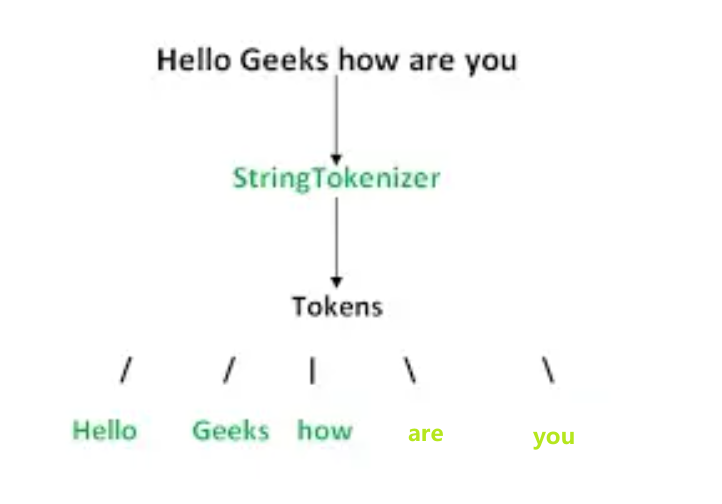
其中,执行分词的算法模型称为分词器StringTokenizer,被划分好的词称为Tokens(token不等于word,token可以是一个单词、一个字母甚至半个单词),整个过程称为Tokenization;
将划分好的token用向量表示(因为只有向量才能被输入到算法模型中),分词的目的就是让这些向量蕴含更多的信息;
但是因为一篇文本的词太多,为了方便算法模型的训练,往往选择频率最高的若干词汇组成一个词表Vocabulary;
1.1 古典分词方法
古典分词方法主要包含以下几种:按照空格分词、按照标点符号、按照语法规则分词
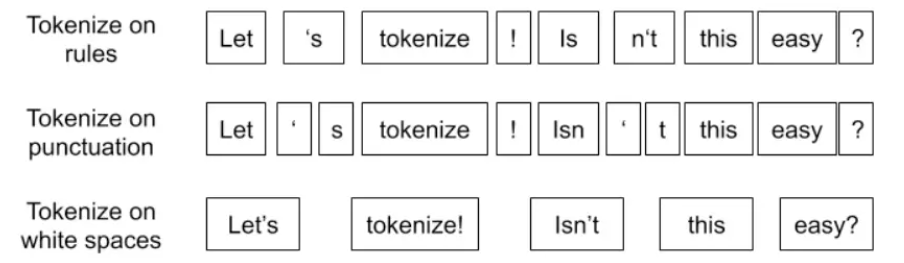
古典分词的思想非常简单且word是具有语义的,但是存在如下缺点:
- 对于未出现在词表Vocabulary中的词,模型会将其标记为未知符号Unkown,加重OOV的问题;
- 词表Vocabulary中的低频词/稀疏词在模型的训练过程中无法得到有效的训练,且难以处理拼写错误的单词;
- 古典分词一方面会增加训练冗余(look,looks,looked),一方面造成词典特别大;
1.2 单字符方法
该方法称为Character embedding,与之前在项目中基于字的embedding的思想是一致的,即直接将所有的文本分割成字母和符号;
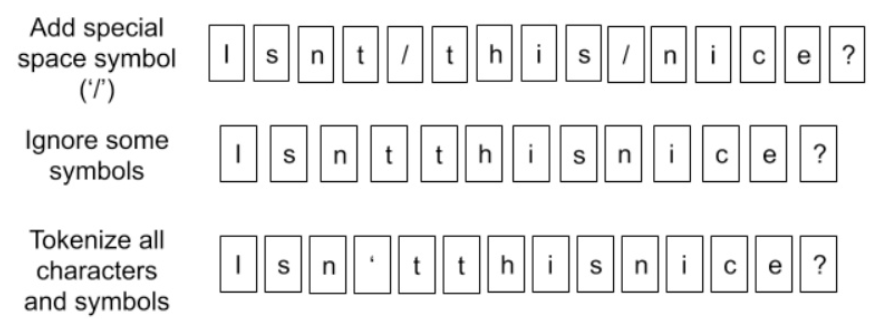
单字符的方法不存在OOV(out of vocabulary)和词典过大(因为字符的总量固定,对英语来说只有26个字符)的问题,同时可以解决单词的拼写错误问题,但缺点是
- 不具备语义(但中文的一个character可能具备语义,可以考虑对中文使用Character-based Tokenization避免直接分词) – 关于语义的问题,一方面在分词阶段,一方面在向量化的阶段,都需要考虑;
- 划分粒度太细,导致训练的花费成果较高;
1.3 Subword算法
Subword算法是一种基于子词的分词方法,是BERT算法下一种分词的算法;
Subword算法的目的是将一个词切成更小的子词,即通过一个大小适当的vocabulary来解决分词的问题,同时尽可能将分词结果中的token数目降低(可以认为是前面两种方法的折中);
Subword的基本思想类似英语中的词根词缀拼词

这些较小的token可以用于构造不同的词,这种方式不仅可以降低词表的大小、减少了OOV的问题(模型甚至可以理解从未见过的单词),也可以对形式相近的词作更好的处理;
Subword的一般原则:
- 频率非常高的词不进行拆分;
- 将罕见的词拆成小的有意义的词;
- 对于后缀,一般会增加一个特殊标记,例如将tokenization 实际会拆成 token 和 ization
</w>,使用</w>标记ization是一个后缀;
目前主要由三种主流的Subword算法,分别是Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model
1.3.1 字节对编码BPE
字节对编码(BPE, Byte Pair Encoder),又称 digram coding 双字母组合编码,本质上是一种数据压缩算法,用于在固定大小的词表中实现可变长度的子词;
BPE 首先将词分成单个字符,然后依次用新字符替换频率最高的一对字符,直到循环次数结束

上述过程中:
- 循环结束的标志是相邻两字符出现的次数都是1次或vocabulary中的token数达到设定量;
- BPE压缩过后,只需要一个压缩过后的数据加上一个字典就能表示原数据;
下面详细介绍BPE的算法过程
1 | |
注意:
- 统计字符的频数是为了判断词表中的字符是否需要删除(当频数为0时)以减小词表的大小,统计相邻字符的频数是为了进行合并以压缩语料;
- 停止符
</w>的意义在于标明该token是词后缀,如st不加</w>则可以出现在词首,如st ar,但是st</w>表示该token只能出现在词尾,如we st</w>;- 新字符仍然可以参与后续的merge,BPE算法的本质就是一种贪心算法;
利用上述算法思想来解决一个完整的例子,假设我们拥有这样一句话作为语料库
1 | |
预处理:拆分、加停止符、统计单词的频率(为了下面统计字符的频率做准备)
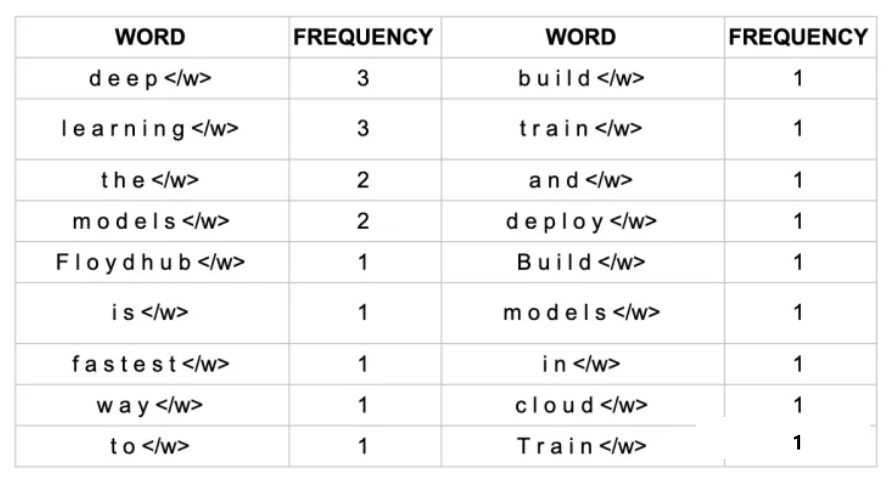
根据上面的结果建立初步vocabulary(原始vocabulary以char为粒度)
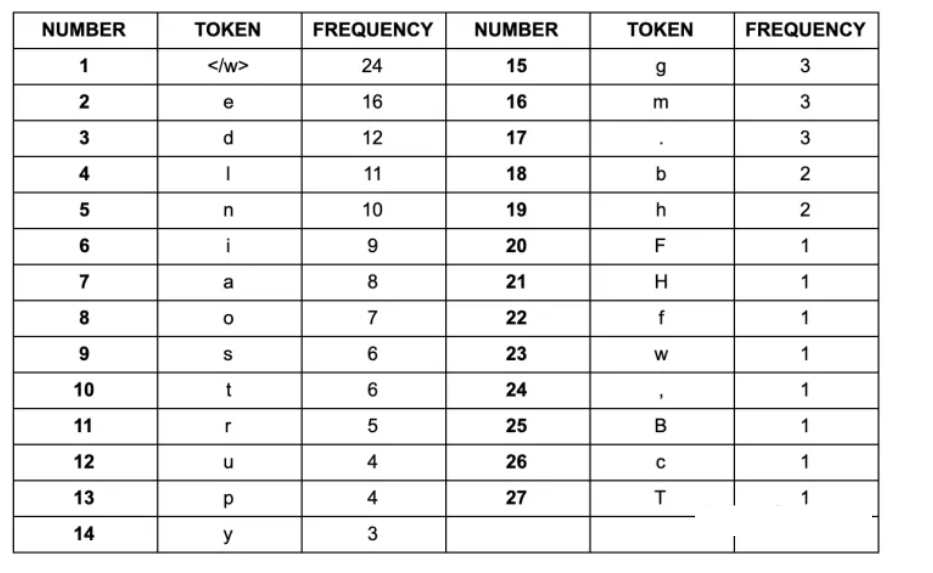
因为在所有的pair组合中de出现的频次是最高的,所以使用de将d和e替换并更新vocabulary
每次merge后的vocabulary带下可能有如下3种变化:
- +1,表明加入合并后的新子词,同时原来的2个子词还保留(2个字词分开出现在语料中);
- +0,表明加入合并后的新子词,同时原来的2个子词中一个保留,一个被消解(一个子词完全随着另一个子词的出现而紧跟着出现);
- -1,表明加入合并后的新子词,同时原来的2个子词都被消解(2个字词同时连续出现);
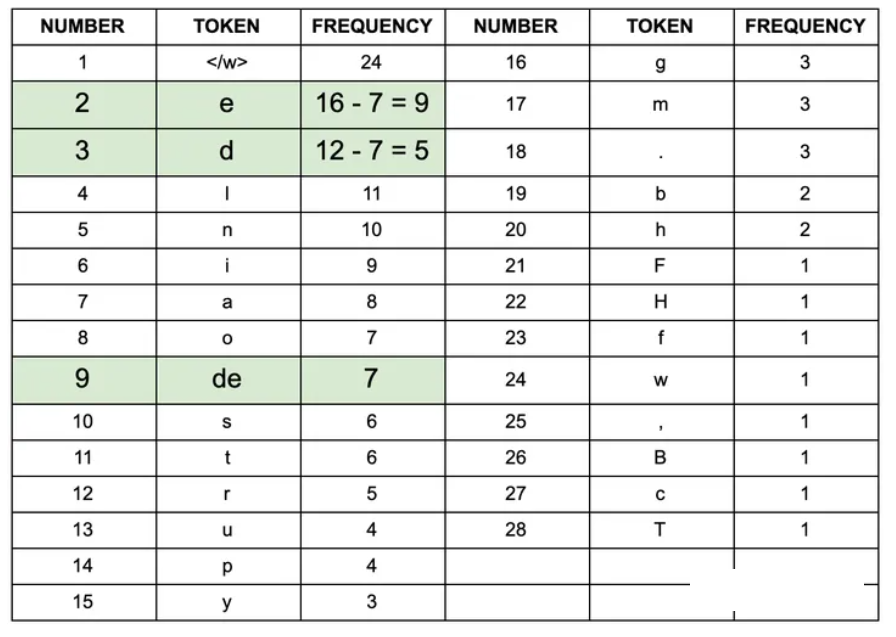
继续迭代直到达到预设的 subwords 词表大小或下一个最高频的字节对出现频率为 1
随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值;
在得到Subword词表后,针对每一个单词,可以采用如下的方式来进行编码:
- 将词典中的所有子词按照长度由大到小进行排序(排序方式多种多样);
- 对于单词w,依次遍历排好序的词典。查看当前子词是否是该单词的子字符串,如果是,则输出当前子词,并对剩余单词字符串继续匹配;
- 如果遍历完字典后,仍然有子字符串没有匹配,则将剩余字符串替换为特殊符号输出,如
<unk>; - 单词的表示即为上述所有输出子词;
解码过程比较简单,如果相邻子词间没有中止符,则将两子词直接拼接,否则两子词之间添加分隔符;
1 | |
总结:
BPE的缺点在于对于同一个句子可能会产生不同的 Subword 序列,这就可能导致最终分词的结果不同(这也是为什么不同的代码对中文分词产生的效果都不同);
对于中文一般不会选择使用BPE编码,因为BPE是一种分词的思想,中文可以直接分字然后向量化或者使用其他更好的方式进行分词
1.4 评价指标
对于分词结果的评价,主要参考五个指标,分别是精确率、召回率、F1值、OOV Recall Rate和IV Recall Rate。
对于二分类问题,真实的样本标签有两类,模型预测的类别有两类,根据二者的类别组合可以划分为四组

上表即为混淆矩阵,其中,行表示预测的label值,列表示真实label值。TP,FP,FN,TN分别表示如下意思:
- TP(true positive):表示样本的真实类别为正,最后预测得到的结果也为正;
- FP(false positive):表示样本的真实类别为负,最后预测得到的结果却为正;
- FN(false negative):表示样本的真实类别为正,最后预测得到的结果却为负;
- TN(true negative):表示样本的真实类别为负,最后预测得到的结果也为负;
综上,TP和TN是预测准确的样本,而FP和FN为预测错误的样本。基于上述混淆矩阵,可以得到如下评价指标:

- 精确率:预测结果中,预测为正样本的样本中,正确预测为正样本的概率;
- 召回率:在原始样本的正样本中,最后被正确预测为正样本的概率;
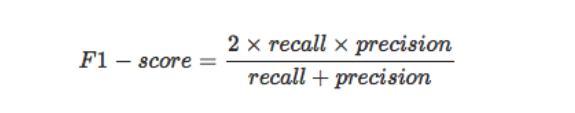
- F1值:为了折中精确率和召回率的结果,引入了F1值,计算公式如上;
但是分词问题并不等价于分类问题,计算上述指标之前需要先做转换。
假设对于一段文本,每个单词在文本中所对应的位置为[a,b],那么标准答案中,所有单词的区间构成一个集合A,而对于某一种切分规则,得到的分词结果的区间构成一个集合B。
则集合A是所有的正确样本,即A 为TP 和 FN的并集,而B是分词器认为的正确样本,即TP和FP的并集,那么 TP 即为 A和B的交集
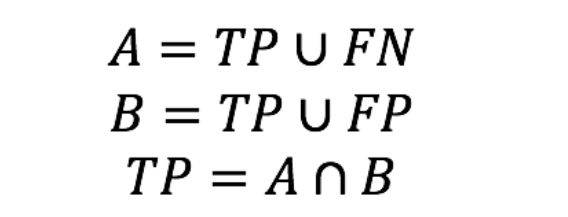
1.4.1 常规指标
使用上述方法进行转换后就可以计算各个评价指标
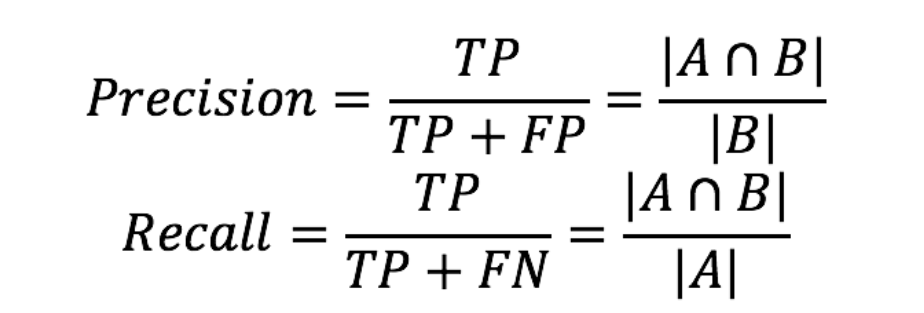
举一个简单的例子来看真实的处理情况

因此精确率和召回率都是3/5,召回率也是3/5;
1.4.2 特殊指标
- OOV Recall Rate:OOV是指未登录词,即未出现在词典中的词。OOV Recall Rate指的就是分词方法能够将未登录词找出来的能力(这意味着我们需要一个标准的词典),其计算方法如下:
- 首先计算正确分词结果中所有未登陆词的个数,作为分母
- 计算基于某种分词方法得到的分词结果中分词正确部分中未登陆词的个数,作为分子(不是基于某种分词方法得到的分词结果中未登陆词的个数,而是分词正确的那部分中未登陆词的个数)
- 分子分母相除,得到OOV Recall Rate
- IV Recall Rate:IV指的是登陆词,相应的IV Recall Rate指的是词典中的词汇被正确召回的概率,其计算方法如下:
- 首先计算所有正确分词结果中所有登陆词的个数,作为分母
- 计算基于某种分词方法得到的分词结果分词正确部分中登陆词的个数,作为分子(这里同样是正确分词部分,而非所有的分词结果)
- 分子分母相除,得到IV Recall Rate
很明显的一点是基于词典匹配进行切分的分词方法是基于子词词典进行的,这意味着它发现新词的能力几乎为0(新词不包含新字),因此OOV这个指标在基于词典的分词中可以不使用。
2.任务陈述
实验要求采用BPE算法对中文文本进行分词处理,整个任务主要分为两个部分:
- 第一个部分是训练部分,即程序通过输入的中文文本train_BPE.txt学习并输出model.pkl文件,该文件就是子词词表(约束子词词表大小为10000);
- 第二个部分是分词部分,即程序通过得到的model.pkl文件,对输入的测试语料test_BPE.txt文件进行中文分词并输出分词结果test_BPE_result.txt;
下面是期望的输入和输出:
train_BPE.txt

model.pkl
test_BPE.txt

test_BPE_result.txt

限制和约束:
- 所有提供的数据均为Unicode(UTF-8)编码,故输出文本也务必采用UTF-8编码;
- 子词词表大小为10000;
3.算法设计
整个算法主要分为两个部分,第一个部分是获取输入训练集并输出词表,第二部分是获取词表和测试数据并输出分词结果,在具体的实现中将其分别在train_BPE.py和test_BPE.py文件中创建两个类BPE_token_train和BPE_token_test,分别在两个类中实现算法的两个部分。utils.py文件主要包含了读取数据、更新数据等工具类函数,main.py是主函数,分别依次执行算法的第一部分和第二部分。
3.1 utils.py
该文件作为工具类函数的汇总文件,主要包含常用的获取数据、初始化数据、更新数据等函数。
3.1.1 读取数据模块
读取数据主要在三个地方:读入训练文本train_BPE.txt、读入词表mpdel.pkl以及读取测试文本test_BPE.txt,借助python内置的pickle库和文件库可以轻松的读取这些文件内部的数据。
1 | |
整个程序主要维护三个重要的数据结构,一个是book,一个是book_freq,另一个是vocabulary,book是经过处理的输入文本语料库(原始语料中存在大量重复的文本,需要进行处理以提高数据质量),book_freq统计了相应的频数(比如原始语料库中“【空军】”出现了6次,则book对应“【空军】”,book_freq对应的就是6),vocabulary是BPE算法依赖book和book_freq生成的词单元词典。
3.1.2 初始化模块
开始训练之前需要初始化这三个数据结构,初始化book和book_freq的函数如下,该函数接受三个参数:line_list、book和book_freq,其中line_list是一个字符串列表,每个字符串表示输入语料库中的一行文本(带换行符'\n')

init_book函数首先删除行末尾的换行符,然后将行中的所有字符连接到一个字符串中(即x)并在每个字符串的末尾添加一个特殊的标记“</w>”,以标记行末尾;
接着函数检查x是否存在于temp_book中(具体方法就是利用temp_book中的key去检查去value,如果value>1表示该key已经存在于book中),如果已存在则在book_freq中增加其相应的频数,反之则将该字单元添加到book中并在book_freq中将其对应频数设置为1。
1 | |
函数返回book和book_freq列表,作为BPE算法的起点,用于创建和更新vocabulary,函数返回的初始化book和book_freq分别如下


对于vocabulary也需要进行初始化创建,借助前面函数返回的book和book_freq列表,通过循环book列表中的每行以及book_freq中对应的频数,将book中每一行的字符串都拆分为单个汉字并统计其出现的频数(具体做法,如果book中的第一行是“人民网”,对应的book_freq中的频数为2,而book中的第二行是“人民”,对应的频数为3,则“人”、“民”、“网”在vocabulary中分别的频数为3,3,2)。
1 | |
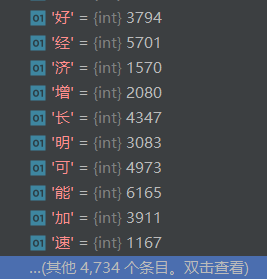
函数返回初始化过后的vocabulary,这是一个键值对的字典,键表示语料中单个的汉字,值表示该汉字在语料中出现了多少次

初始化之后的vocabulary大小为4734
3.1.3 更新模块
根据前面所介绍的BPE算法的基本原理,拥有了基本的book、book_freq以及vocabulary之后,需要不断的迭代合并更新直到达到预设的subwords词表大小或下一个最高频的字节对出现频率为1,因此更新book、book_freq以及vocabulary是BPE算法的核心。
在介绍更新之前,额外介绍一个工具函数get_book_pairs,其代码如下
1 | |
该函数的主要目的是根据book和book_freq构造pairs和pairs_index这两个字典,其中pairs的键是汉字对,值是汉字对出现的频数,pairs_index的键是汉字对,值是该汉字对对应的句子在book中的索引。在之后的更新pairs的过程中可以可以直接利用索引寻找其所来源的语料行,不需要将全部语料遍历一遍。
下面给出pairs和pairs_index字典的结构


更新模块主要包含更新book语料行以及更新pairs和pairs_index字典,首先更新pairs和pairs_index字典,该函数传入的参数为pairs,pairs_index,book,以及出现频率最高的单词对best(best通过max(pairs, key=pairs.get)方法取较大者得到)。
该方法首先从pairs_index字典中获取出现best对的所有行的索引
1 | |
接着对每一行将其单独拆分为汉字进行循环
1 | |
如果正在检查的当前词对与best对相同,则该方法按如下方式修改pairs以及pairs_index:
- 如果词对不是该行中的第一个或最后一个词对,则该方法将最佳的第一个词与前一个词组合以形成新词对,并将最佳的第二个词与后一个词结合以形成另一个新词对。这些新词对的频率在pairs字典中递增,并且当前行的索引被附加到pairs_index字典中对应的值,同时两本词典中的旧单词对均需要被删除。
1 | |
- 如果词对是行中的第一个词对,则该方法将最佳的第二个词与下一个词组合以形成新的词对。这个新词对的频率在pairs字典中递增,并且当前行的索引被附加到其在pairs_index字典中的值,同时旧词对从两本词典中删除。
1 | |
- 如果词对是行中的最后一个词对,则该方法将最佳的第一个词与前一个词组合以形成新的词对。这个新词对的频率在pairs字典中递增,并且当前行的索引被附加到其在pairs_index字典中的值,同时旧词对从两本词典中删除。
1 | |
最后,函数从pairs和pairs_best中删除best对并返回更新后的pairs和pairs_index字典。
在修改完pairs以及pairs_index后,需要对book语料行进行更新。参数为新增的词对,借助book_freq可以快速定位到change所在语料行,进行分词更新
1 | |
借助pycharm的debug我们可以跟踪前几步的更新过程来理解上述代码
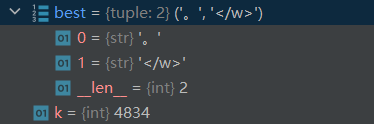


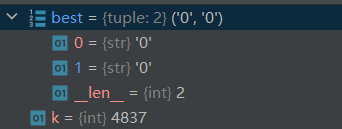
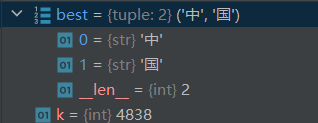
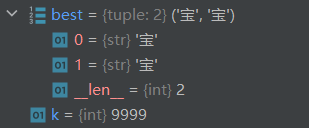
3.2 train_BPE.py
该文件是完成分词第一部分任务的文件,获取输入文件train_BPE.txt,输出模型文件model.pkl,主要定义了一个BPE_token_train类来实现该任务。
BPE_token_train类主要有以下属性
1 | |
book、vocabulary以及book_freq在前面我们已经介绍过,而file是训练语料的路径,line_list列表用于接受从训练语料中读取得到的data,后续将用于book和book_freq的初始化,mac_len指定了词典的最大的长度,这意味着当词典的长度大于max_len的时候程序结束并输出model.pkl文件。
BPE_token_train的train方法流程如下:
1 | |
使用line_list接受来自训练语料train_BPE.txt的data;
初始化book和book_freq;
初始化vocabulary;
初始化pairs和pairs_index;
进入主循环,循环终止条件为词典长度大于max_len
在每次循环的迭代中,选择book中频数最高的一对词对;
使用best词对更新book;
使用best词对更新pairs和pairs_index字典;
将best词对加入vocabulary中;
1 | |
- 退出主循环之后使用内置sort函数对vocubulary排序,排序后的结果存储在一个元组列表sorted_tokens_tuple(优先按照长度排序,齐次按照频数排序)
1
2
3
4
5
6
7
8sorted_tokens_tuple = sorted(self.vocabulary.items(),key=lambda item: (len(item[0]), item[1]),reverse=True)
````
7. 最后将该元组列表写入model.pkl文件中结束第一部分
```py
F = open('model.pkl', 'wb') # 打开模型文件
pickle.dump(sorted_tokens_tuple, F) # 将词典写入模型文件
F.close() # 关闭模型文件
执行完train()方法后将得到长度为10000的vocabulary如下

因为在迭代的过程中会同时更新book和book_pair,可以看到最后book中的单字已经根据besi对的原则组合在一起

待写入的sorted_tokens_tuple在根据长度和频数的排序后结果如下

3.3 test_BPE.py
这是完成BPE中文文本分词第二部分的文件,主要实现了一个BPE_token_test类,该类利用其test方法对测试文件test_BPE.txt进行分词。
BPE_token_test类主要有以下两个属性
1 | |
其中vocabulary就是从model.pkl文件中读取出来的第一部分经过训练得到的词表,line_list列表中保存的是来自测试语料test_BPE.txt文件中的data,可以看到从model.pkl文件中读出来的vocabulary就是在上个部分中的sorted_tokens_tuple去除频数的结果。

在test方法中使用了try…except…finally异常处理结构,目的是避免出现异常导致测试文件无法关闭或被意外修改。如果在测试过程中发生任何异常,except块将捕获它们并打印错误消息。无论是否捕捉到异常,finally块都将始终执行,并且在打开输出文件时将关闭该文件。
1 | |
test()方法在line_list列表中(也就是测试语料)的每一行上循环,并通过相应的词对替换语料行中与vocabulary词典的词对匹配的词对,这也称为BPE的解码,得到的解码行将被写入test_BPE_result.txt的新文件中,同时在解码行的最后加入<\w>以标识边界。
3.4 Compare_Com.ipynb
对于分词结果的评价,前面已经介绍过,这里我们在notebook环境中分模块实现评价指标的计算。
因为并没有找到一个标准的分词答案,所以我选择了现在比较流行的中文分词库jieba的分词结果作为参考答案,使用jieba对测试数据进行分词前需要先将原始测试数据中的空格去除
1 | |
去除空格后便可以直接使用jieba库对文本逐行进行分词处理,并将处理过后的结果存储在standard.txt文件中作为标准答案,文件部分内容如下

直观上看jieba的分词效果的确更符合汉语的使用习惯,因此使用该分词结果作为标准答案有一定道理。
前面分词得到的文本文件中在结尾处为了标识结束因此添加了</w>标志,但是在jieba分词的结果中并没有,因此我们需要对其进行处理,将BPE分词结果中的后缀</w>删除
1 | |
jieba分词文本和BPE分词文本均准备好之后,就可以开始进行指标计算的数据准备工作了。
在计算分词指标的时候我们需要用到标准词典,这个词典的作用在于计算IV(为什么不计算OOV在前面已经说过),这里我们还是借助jieba分词对原始测试数据进行提取,得到标准词典
1 | |
上述代码返回的词典是一个tuple类型的值,第一个数值表示词典中词的值,第二个数值表示该词出现的频数,部分词典内容如下

接着定义区间转换函数,也就是将已经分词了的一句话中的词转换为对应的区间,这一步是必须的,因为这不是分类问题无法直接计算Presicion等指标。
其基本思想也非常简单,即利用空格作为判断依据,从左往右给对应的词赋予区间即可。
1 | |
最后是计算指标的prf函数,其输入是标准答案、预测答案以及标准词典,代码中有详细的解释这里就不再赘述
1 | |
中间的print是为了让我们更加直观的理解评价过程中的计算原理,比如对于这样一段文本
1 | |
基准集合记录了jieba对于文本的分词结果,预测集合记录了BPE对于文本的分词结果,下面是基准集合中的内容
1 | |
A&B表示基准集合和预测集合的交集,也就是BPE分词和jieba分词对于同一段文本做出的相同的分词结果,我们认为这是正确分词的结果
1 | |
IV值的计算方式如下:
- 首先计算所有正确分词结果中所有登陆词的个数,作为分母
- 计算基于某种分词方法得到的分词结果分词正确部分中登陆词的个数,作为分子(这里同样是正确分词部分,而非所有的分词结果)
- 分子分母相除,得到IV Recall Rate
即借助BPE正确分词结果/jieba分词结果。
评价指标的相关函数已经定义完毕,接下来需要将手中的数据格式进行一定的转换以输入prf函数。
将以行为单位将标准答案和BPE分词文本分别加入gt_list和pred_list中,同时将前面tuple类型的词典中的第一个元素提取出来作为标准词典
1 | |
由此我们得到了prf函数的三个输入分别如下



4.结果测评
4.1 原始结果
实验要求输出结果为子词词表和子词切割结果,其中子词词表一行一个,单个字符之间不用空格;子词切割结果和语料格式一样用空格分隔,子词合并。
下面是子词词表的结果,一共10000个子词(仅展示部分)


可以看到子词词表中有很多标点符号,这其实并不是我们想要的结果。一般来说中英文标点一般来说不是词汇的组成部分,因此标点出现在子词词表中不合理,我们将在之后进行处理。
依据上面的子词词表切分得到的结果如下(仅展示部分),切分效果一般,某些较明显的词汇并未合并。

4.2 优化处理
中英文标点一般来说不是词汇的组成部分,因此可以将训练数据中的标点符号全部替换为’#’
1 | |
注意某些标点符号不能删除,可能导致分词不准确,比如’%’或’.’。对标点符号处理过后得到的子词词表如下

与之前的结果相比,明显可以看到减少了无意义的标点符号的组合,应用该词表进行匹配时,因为test文本中几乎不会出现’#’符号与其他字的组合,所以词表中与’#’组合的字以及标点符号都会被作为未知单字处理,这些组合一般也符合单字的划分,比如’的#’、’而#’等。使用上述优化过的词表对test文本进行划分得到如下文本

可以看到,与之前的结果相比,本次划分结果不仅将行结束符</w>与文本划分,同时也将标点符号与文本划分,对于数字如’5.6%’也进行了合理的划分。
4.3 评价指标
借助前面的Compare_Com.ipynb可以对分词的结果做评测,具体函数定义在前面已经介绍过,这里我们直接看结果


第一个是使用原始结果即BPE_v1.txt与标准答案进行比对的结果,第二个是在进行了优化处理过后的BPE_v2.txt与标准答案及逆行比对的结果。可以看到相对于不做任何处理的BPE算法来说,在处理了标点符号之后的分词效果有了明显的提升(尽管提升过后的效果也并不是非常好)。关于指标为什么不是特别好看,一方面因为使用jieba分词的答案作为标准答案其实本身就认为jieba的分词效果比BPE好,同时前面也介绍过BPE常用于英文分词,中文对其有一定的挑战。同时我们的算法还有可以进一步优化的地方,比如数据去重、并行优化计算、增加数据集大小等,这些都是影响最终BPE分词结果的因素。
综上所述,jieba库是专门为中文文本分词而设计,该库经过大量的中文文本数据训练,可以有效地对中文文本进行分词,特别是在处理习惯用语和罕见单词方面。相比之下,BPE是一种用于文本分词的通用算法,需要预定义数量的子单词,并且可能未经过针对中文语言细微差别的优化,无法有效地捕捉语言的重要语言特征。此外,BPE用于中文文本分词的性能取决于用于训练的具体参数,例如合并次数或词汇表大小。因此,单独使用BPE算法解决中文分词问题不是一个推荐的选择。
5.实验总结
BPE字节对编码是NLP中常用的文本分割算法,尽管BPE算法对于英文文本的分词效果更好(因为中文文本缺乏明确的分隔符,只能先划分为单个的字),但在具体进行实验测试后,发现BPE算法还是在一定程度上解决中文文本分词任务。并且经查资料得知,BPE算法与其他两种流行的分割算法即MM最大匹配和条件随机场CRF在进行一个文本分割任务时表现较好,这也表明BPE算法在中文文本分词任务上的潜力。
在本次实验中我们通过编写BPE算法来实现从训练语料中学习得到一个vocabulary词表,对中文来说也就是在训练语料中出现频率较高的词对组成的词典,接着根据这个学习得到的vocabulary对测试语料进行分词处理,具体做法就是逐行比对,如果相邻字组成的词对恰好出现在vocabulary中,则将其组合,最后遍历完所有的测试预料行就得到了最终分词结果。
实验中的难点在于如何将BPE算法思想转换为伪代码或具体的实现,并且大多数BPE算法都是用于解决英文文本分词的,而英文与中文的区别在于英文单词有明确的界限,同时英文单词的个数是固定的即26个,这意味着不能使用常规的BPE算法套用在中文分词任务上,因为BPE算法主要分为编码和解码两部分,对于中文来说不妨直接按照单字初始化词表(因为中文常用字也不过几千个),然后按照文本中词对出现的频率更新词表,最终得到长度为10000的词表,在解码过程中直接按照词表进行“查字典”式的组合替换即可。
分词任务是NLP邻域中最基础也最核心的任务,通过完成本次实验让我对NLP邻域的兴趣更进一步,同时也加强了编写代码以及调试代码的能力。