参考链接:
2023/4/12 10:38 参考代码中有各种各样的解决方式,一些侧重原始数据的分析,一些侧重机器学习以及结果的预测,推荐直接在Kaggle上对代码进行运行(无需额外搭建环境),尽量选择comments数量多的代码参考(对于运行不了的代码适当放弃,没必要在修改原始代码上面花费这么多时间,这么多参考直接找新的就行);
2023/4/12 14:20 这些代码全都跑不起来,真的让人头大,一方面是因为代码的年限太久远了(库更新之后肯定会有不兼容的地方),所以找比赛尽量找时间点较近的比赛;
2023/4/12 14:20 因为之前选择向DataSet太过久远(8 years ago),所以很多代码尽管看起来漂亮但实际上并不能很好的运行,也就没有必要和这种项目磕时间,所以决定放弃MBTI项目转而使用Kaggle上的预训练模型FaceNet,等它的数据全部跑出来之后就可以按照这个模型进行学习和理解;
2023/4/18 7:56 找了那么久的数据库和代码,然而还是没找到一个合适的,反而回过头来看最初的项目是最好的,最后再试试,实在不行就还是回到最初的代码改一改,或者不用Kaggle的那些项目(原因还是远古代码的可行性太低了)重新寻找新的项目;
2023/4/20 9:22 这个项目对于期末大作业来说过于简单了…虽然各方面都符合要求,但是这个难度实在太低了,所以决定放弃,重开一个自动驾驶的博客;
一、数据集介绍 1.背景介绍 新闻是有关当前事件的信息。这可以通过许多不同的媒介提供,例如口头传播、印刷、邮政系统、广播、电子通信或通过观察者和事件证人的证言。
新闻报道的常见主题包括战争、政府、政治、教育、健康、环境、经济、商业、时尚和娱乐,以及体育赛事、古怪或不寻常的事件。自古以来,关于皇家仪式、法律、税收、公共卫生和罪犯的政府公告被称为新闻。
技术和社会发展,通常由政府的通信和间谍网络推动,增加了新闻传播的速度,同时也影响了其内容。我们今天所知的新闻类型与报纸密切相关。在现代,或者说在计算机时代,我们看到了从硬拷贝模式向在线新闻获取模式的大规模转移。
假新闻是被呈现为新闻的虚假或误导性信息。它往往旨在损害某个人或实体的声誉,或通过广告收入牟利。媒体学者诺兰·希格登提供了一个更广泛的假新闻定义,即“被呈现为新闻的虚假或误导性内容,并以口头、书面、印刷、电子和数字通信等各种格式传播”。
假新闻曾经在印刷品中普遍存在,随着社交媒体的兴起,尤其是Facebook新闻订阅功能,假新闻的普及率已经增加。政治极化、后真相政治、确认偏见和社交媒体算法被认为是假新闻传播的原因。有时,敌对的外国行为者特别是在选举期间制造和传播假新闻。匿名托管的假新闻网站的使用使得很难就假新闻源起诉诽谤行为。在某些定义中,假新闻包括被误解为真实的讽刺文章,以及标题耸人听闻或引人点击却在正文中没有支持的文章。
假新闻可以通过与真实新闻竞争来降低真实新闻的影响力;Buzzfeed的一项分析发现,关于2016年美国总统选举的头条假新闻在Facebook上获得的参与度比主要媒体机构的头条新闻更高。假新闻还可能破坏对严肃媒体报道的信任。有时,这个词汇被用来质疑合法的新闻,美国总统唐纳德·特朗普因使用它来形容任何关于他自己的负面新闻报道而受到赞誉。由于特朗普的误用,这个术语越来越受到批评,英国政府决定避免使用这个术语,因为它“定义不清”,“混淆了从真正的错误到外国干涉的各种错误信息”。
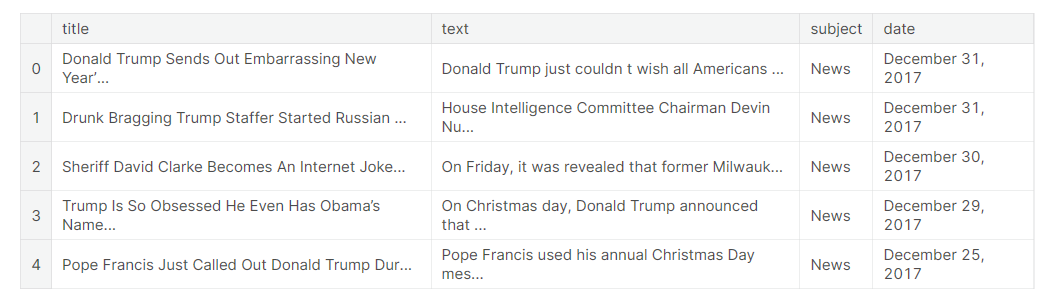
2.Fake news分析 借助pandas工具可以读取Fake.csv文件中的内容
1 2 fake_news = pd.read_csv("/kaggle/input/fake-and-real-news-dataset/Fake.csv" )
下面展示的是Fake.csv文件中前五条数据,主要分为四列:title,text,subject和dae
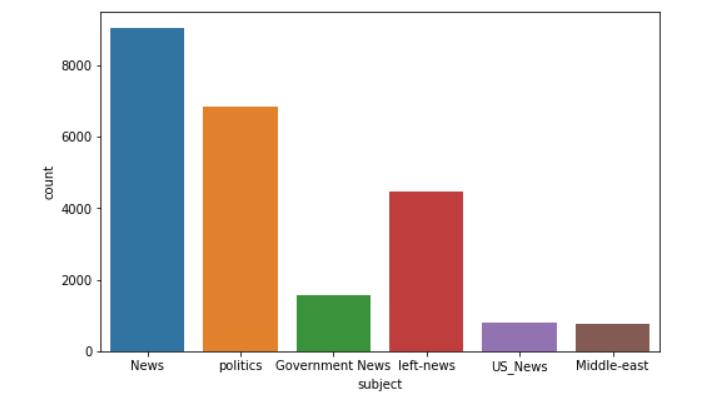
其中subject列指的是新闻的主题,经过统计主要有23481条数据,使用迭代subject的方式对所有主题计数
1 2 for key,count in fake_news.subject.value_counts().iteritems():print (f"{key} :\t{count} " )
可以得到不同主题对应的fake news的数量
1 2 3 4 5 6 News: 9050 politics: 6841 left-news: 4459 Government News: 1570 US_News: 783 Middle-east: 778
借助matplotlib以及seaborn库可以更直观的得到不同主题的新闻的数量分布
1 2 3 plt.figure(figsize=(8 ,5 ))"subject" , data=fake_news)
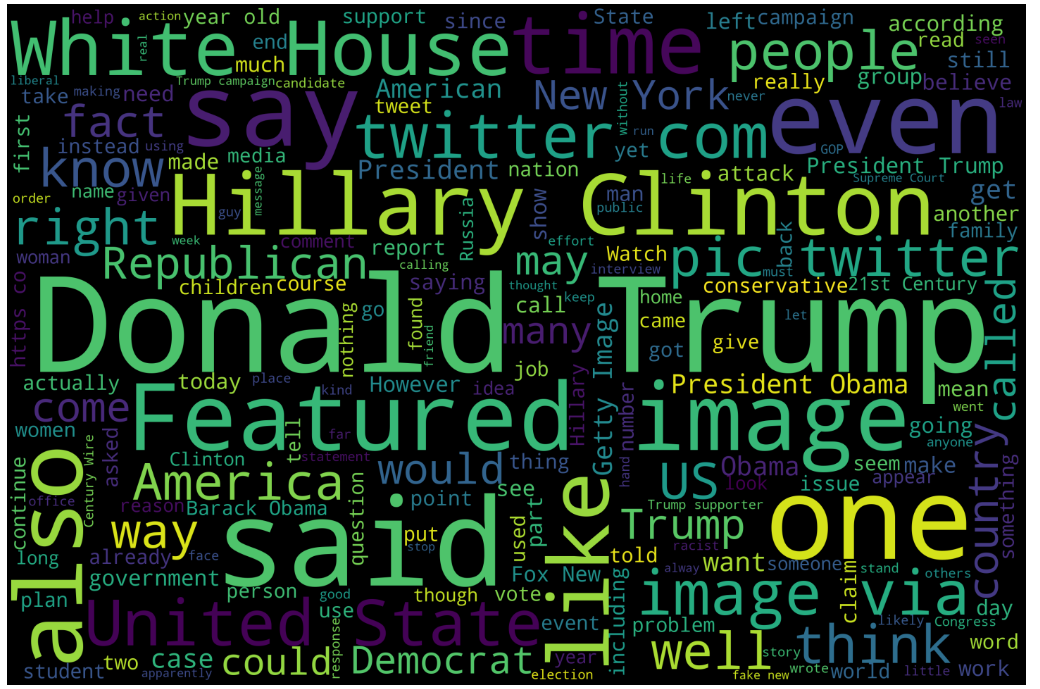
词云是这样的一种技术手段,它可以将一段文本中使用的单词进行图像化表示,其中每个单词的大小表示其在文本中的频率或重要性(因此常用单词比不常用单词更大、更引人注目),单词通常以随机或半随机的方式排列。词云可以用于快速可视化大量文本中最常见的主题,是数据分析、营销和视觉交流的有用工具。
下面借助词云来对fake news数据集中所有文本的text列进行图形化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 text = '' for news in fake_news.text.values:f" {news} " 3000 ,2000 ,'black' ,set (nltk.corpus.stopwords.words("english" ))).generate(text)40 , 30 ),'k' ,'k' )'bilinear' )'off' )0 )del text
有意思的是,排除一些停用词以外,词云中最显眼的几个单词是Donald Trump,White House,Twitter等,这意味着在fake news中这些单词的占比较大(另一方面这也很符合现实情况),在后续分析中将起到重要作用。
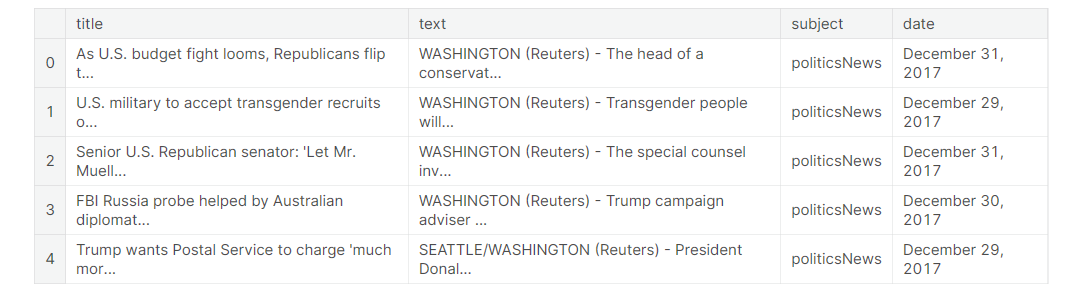
3.Real news分析 同样地,借助pandas工具读取True.csv文件中的信息
1 2 true_news = pd.read_csv("/kaggle/input/fake-and-real-news-dataset/True.csv" )
观察text列,发现real news的text列中的文本都有发布源比如“WASHINGTON (Reuters)”,这点与fake news的text有所区别,除了来自路透社的新闻以外,另外的一些text则是来自推特的推文,real news中很少有不包含任何发布信息的text。
下面我们对real news的信息做一个统计
1 2 3 4 5 6 print (f"Total Records:\t{ture_news.shape[0 ]} " )for key,count in ture_news.subject.value_counts().iteritems():print (f"{key} :\t{count} " )
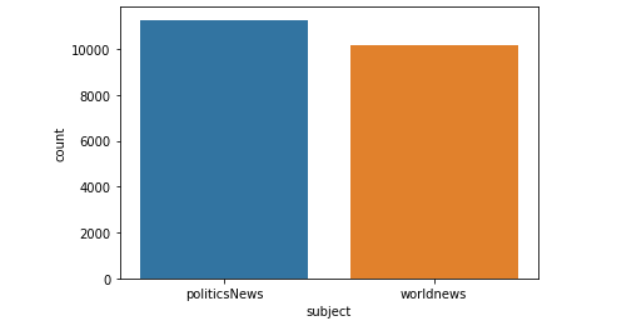
1 2 3 Total Records: 21416 politicsNews : 11271 worldnews : 10145
将上述信息进行可视化展示得到
1 2 sns.countplot(x="subject" , data=ture_news)
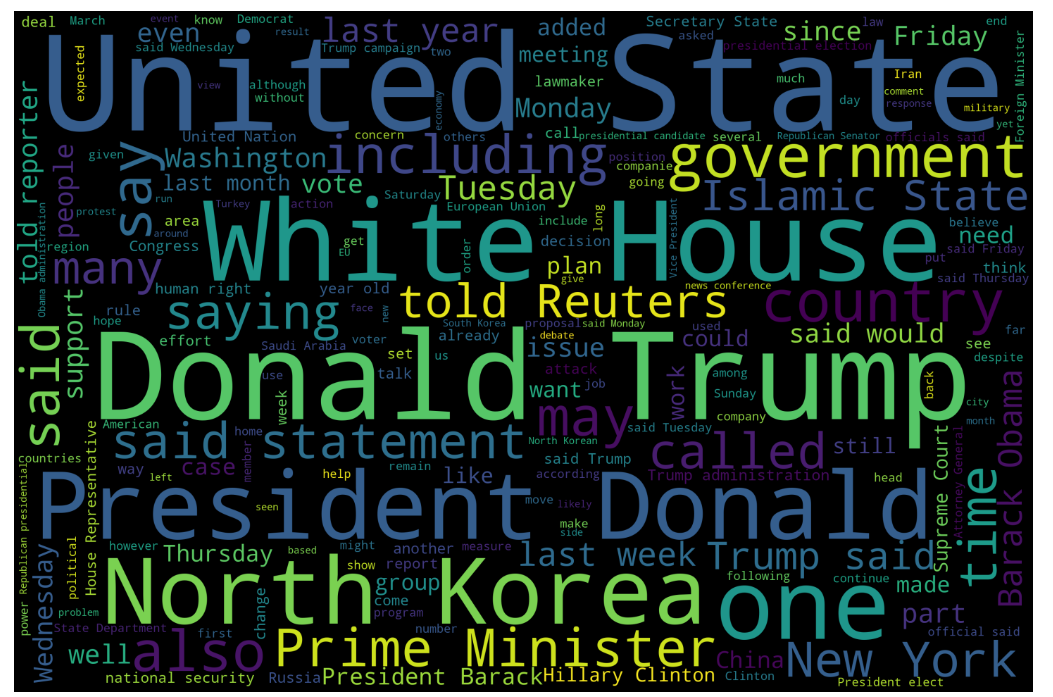
与fake news相同,借助词云对real news的单词做统计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 text = '' for news in ture_news.text.values:f" {news} " 3000 ,2000 ,'black' ,set (nltk.corpus.stopwords.words("english" ))).generate(str (text))40 , 30 ),'k' ,'k' )'bilinear' )'off' )0 )del text
比较显眼的几个单词分别是United State,White House,Donald Trump,President Donald以及North Korea等。
4.综合数据分析 我们将fake news和real news合并,同时分别给real news和fake news打标签1,0(具体表现为增加news_class列),将合并得到的结果进行输出(分别展示合并的结果的前五条和后五条)
1 2 true_news["news_class" ], fake_news["news_class" ] = 1 , 0
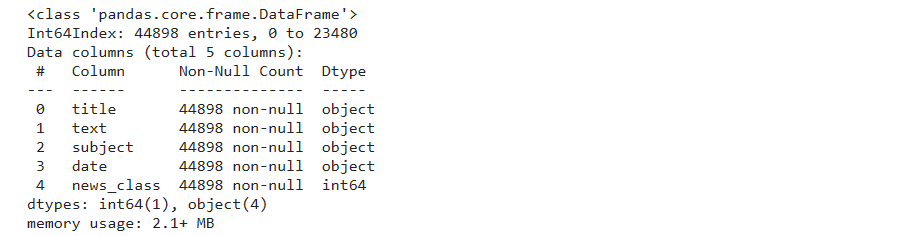
对合并后的数据集进行统计,得到的统计信息如下,结果表明一共有44898条数据,每条数据都有五列,分别是title(新闻标题),text(新闻文本),subject(新闻主题),date(发布时间),news_class(新闻类别)
1 2 True , verbose = True )
在对后面的数据进行探索性分析之前,需要先简单对合并后的数据进行去重和去除空值的处理以避免冗余、无效数据的干扰
检查数据集中是否存在重复的值(经检查,存在209条重复值),如果有则删除这些重复值
1 2 3 4 5 sum ()True )print (colored("\nDUPLICATED VALUES WERE SUCCESFULLY DROPPED..." , "green" ))
除了删除重复值外,还需要检查是否存在空值(实际结果是不存在空值),若存在则将其删除,最终剩余数据数量为44689条
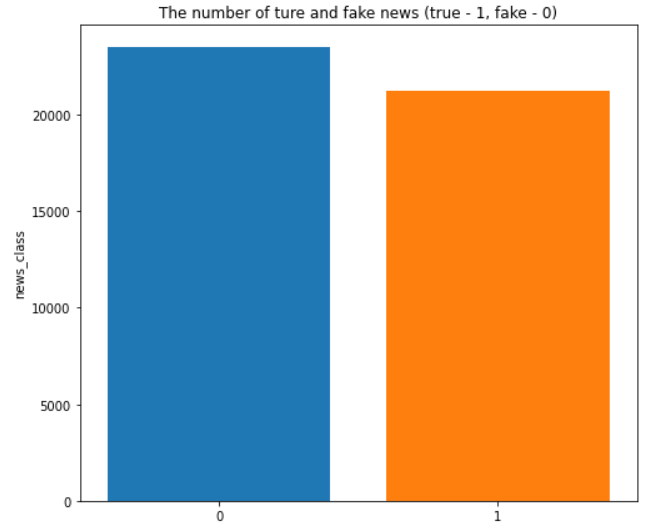
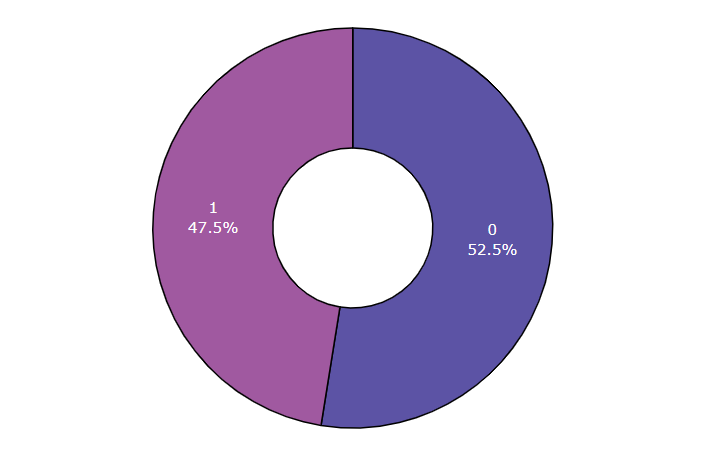
matplotlib以及seaborn库对处理完毕后的数据集的real news和fake news的数据进行可视化,可以看到两者的数量分布相对均匀,并没有出现某个类别的新闻数量明显多于另一个类的现象
1 2 3 4 5 6 7 8 9 10 11 12 8 , 7 ], clear = True , facecolor = 'white' )"news_class" ].value_counts().index,"news_class" ].value_counts(),1 ).set (title = "The number of ture and fake news (true - 1, fake - 0)" );"news_class" , hole = 0.4 , title = "counts in news_class" ,1000 , height = 500 , color_discrete_sequence = px.colors.sequential.Sunset_r)"inside" , textinfo = "percent+label" ,dict (line = dict (width = 1.2 , color = "#000000" )))0.5 , title_font = dict (size = 30 ), uniformtext_minsize = 25 )
查看处理完毕的news数据的主题列subject,即不同主题类型的新闻分布
1 2 "subject" ].value_counts()
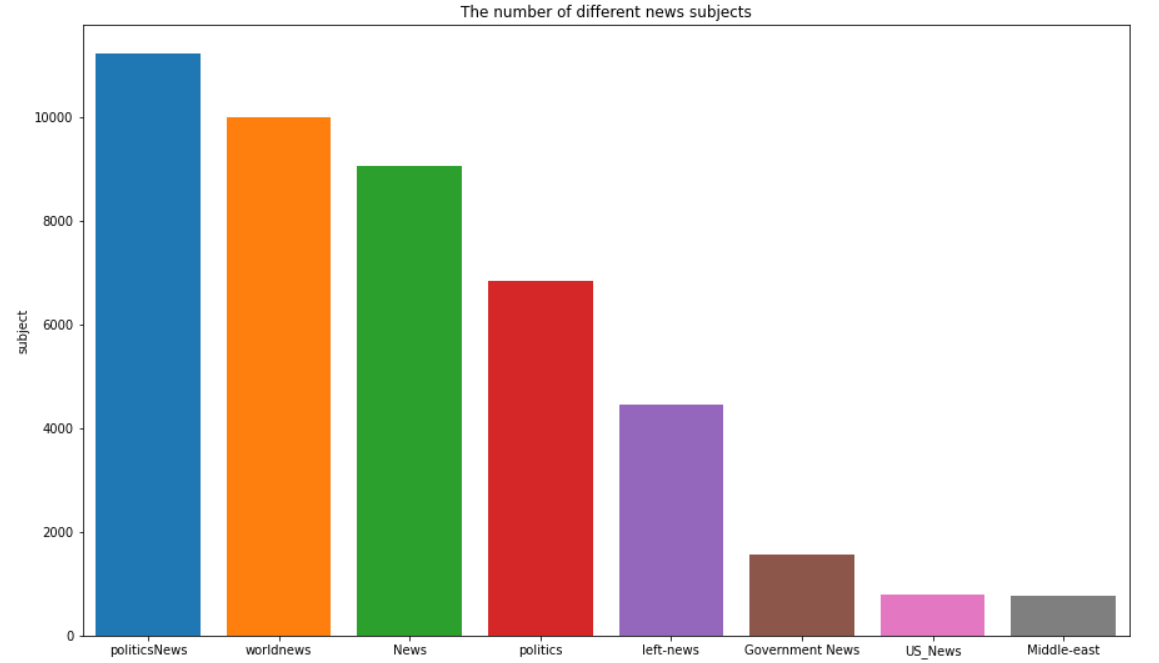
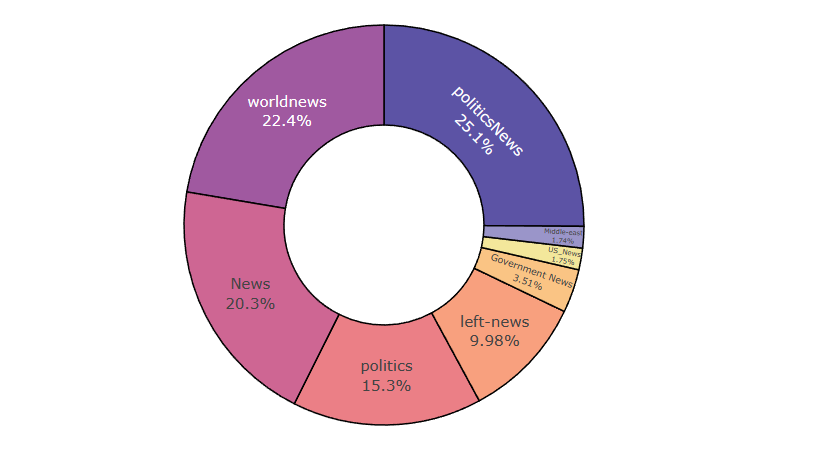
1 2 3 4 5 6 7 8 9 politicsNews 11220 worldnews 9991 News 9050 politics 6838 left -news 4459 Government News 1570 US_News 783 Middle -east 778 Name : subject, dtype: int64
对上述数据进行可视化,可以看到政治类新闻是数量是数量最多的,而中东主题和美国本土的新闻数量较少
1 2 3 4 5 6 7 8 9 10 11 12 15 , 9 ], clear = True , facecolor = 'white' )"subject" ].value_counts().index,"subject" ].value_counts(),1 ).set (title = "The number of different news subjects" );"subject" , title = "counts in news_class" , hole = 0.5 ,1000 , height = 500 , color_discrete_sequence = px.colors.sequential.Sunset_r)"inside" , textinfo = "percent+label" ,dict (line = dict (width = 1.2 , color = "#000000" )))0.5 , title_font = dict (size = 30 ), uniformtext_minsize = 25 )
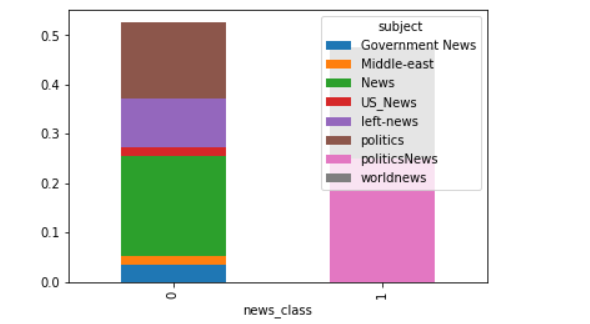
最后分别查看real news和fake news中不同主题类型的news占比
1 pd.crosstab(news["news_class" ], news["subject" ],normalize = True ).plot(kind = "bar" , backend = "matplotlib" ,legend = True , stacked = True );
可以看到在real news中只有两种类型的新闻,而在fake news中politics以及News类占比较大。