中级项目_模拟自动驾驶
参考链接:
- 综述:Self Driving Car | Kaggle or Asikpalysik/Self-Driving-Car: Behavioural Cloning Complete Guide (github.com);
- 代码:Self Driving Car - Behavioural Cloning | Kaggle;
- 中文:
- 环境搭建+数据收集:(20条消息) Udacity 无人驾驶仿真环境搭建实现自动驾驶小车_冲啊皮卡丘的博客-CSDN博客;
- Unity下载与安装:【Unity 2019】汉化版下载(附安装教程) (qq.com);
- 模型+代码详细解析:(20条消息) 基于Udacity模拟器的端到端自动驾驶决策_闲看庭前梦落花的博客-CSDN博客;
- 其他技术资料:
2023/4/25 21:59 这整个过程都非常的顺利,基本上没遇到什么卡壳的难点,只需要把剩余的数据处理部分代码解释以及模型训练部分代码的修改完成,写完所有的报告这个项目就基本OK了;
一、项目介绍
1.任务目标
本项目的目的是基于Udacity提供的汽车模拟器环境通过深度神经网络训练的模型作为代理来实现完全自动驾驶。本项目仅使用摄像头图像和深度学习来教汽车如何驾驶,模型需要学会控制转向角、油门和刹车。
自动驾驶汽车在近十年来是一个非常热门的话题,但自动驾驶行业发展形式并没有想象中的那么好,近些年众多自动驾驶公司估值缩水、裁员倒闭,高级别自动驾驶技术迟迟难以商业化落地,且自动驾驶开放测试区域较少、相关政策制定不足、行车安全难以保障等问题在一定程度上阻碍了自动驾驶技术的发展。自动驾驶技术的发展现状引起了我们的关注,因此我们决定通过实际动手操作来掌握和了解自动驾驶技术。
要在模拟器中使用DNN作为代理实现模拟自动驾驶,主要分为以下两个步骤(训练阶段和测试阶段):
- 训练阶段,模拟器通过使用操纵杆或键盘在“训练模式”下驾驶汽车来收集数据,提供驾驶日志(.csv文件)和一组图像形式的所谓“好驾驶”行为输入数据。将这些收集到的数据处理过后,用于训练深度神经网络构建的机器学习模型,本项目使用的CNN模型基于Keras(Tensorflow的高级API)进行开发。
- 测试阶段,模拟器充当服务器Server,传感器收集到的图像和数据日志传输到Python客户端Client。客户端的CNN模型会向服务器(模拟器)提供方向盘角度和油门,以自主驾驶模式驾驶汽车。这些模块或输入数据被传回服务器,并用于在模拟器中自主驾驶汽车,避免汽车从赛道上掉下来;
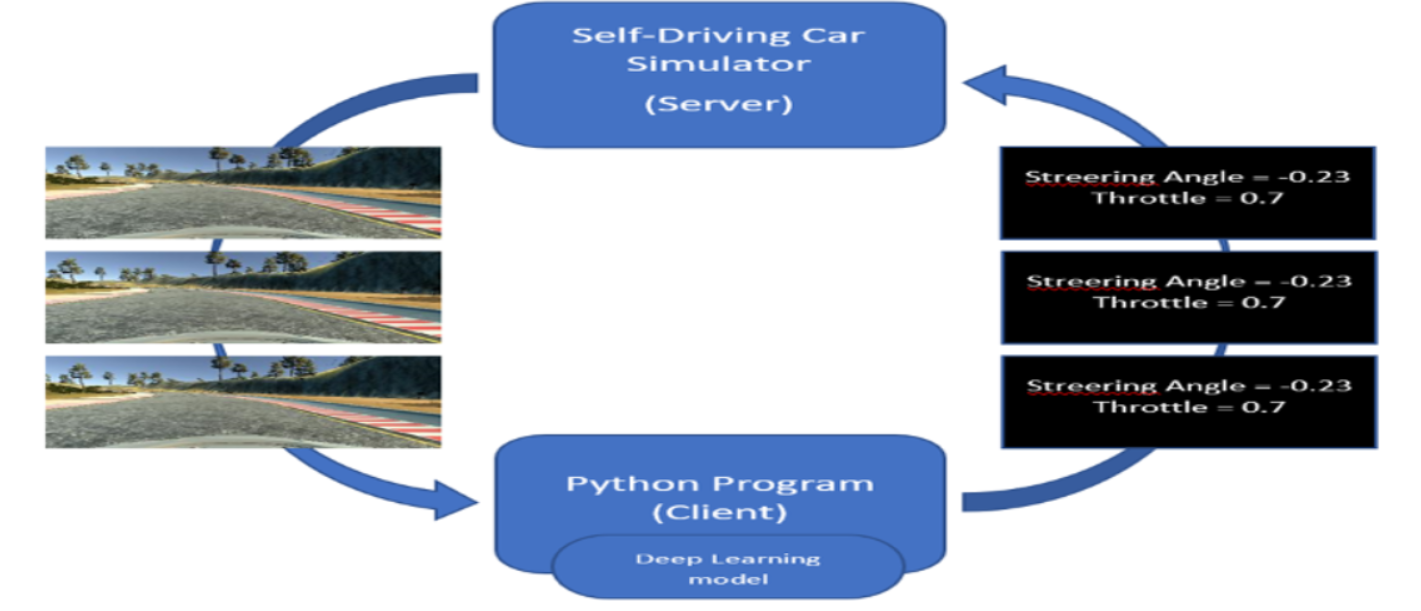
2.Udacity模拟器
本项目使用的Udacity汽车模拟器全称为Udacity self-driving-car-sim(该模拟器的代码是开源的,参考udacity/self-driving-car-sim,可以在基于Unity平台进行二次开发),主要用于自动驾驶模拟仿真实验。该模拟器环境通过Unity内置有车辆模型,该车辆可以通过顶部摄像头来感知周围地图以及角度等关键信息。进入游戏后可以选择“训练模式”或“自动驾驶模式”,“训练模式”需要我们手动驾驶汽车,通过控制车辆的转向、油门和刹车等来保证汽车在道路上安全行驶。在“训练模式”中,汽车在行驶过程中通过车顶的摄像头采集道路信息和车辆行驶信息,将采集的图像以及数据作为原始训练数据存储,在处理过后作为输入数据放入深度神经网络中对模型进行训练。当模型训练完毕后,我们可以将该模型植入自动驾驶汽车中,选择“自动驾驶模式”,汽车将在完全无人操作的情况下实现在道路上安全行驶。

Udacity模拟器除了有两种模式外,还内置有两种不同的地图。第一个为晴天环形公路的简单地图,该地图路面平整无障碍物,且天气晴朗无阴影遮挡。该地图具有较少的弯曲轨迹且容易行驶,我们的数据采集和模型测试都是基于这张简单地图。

第二个为盘山公路的复杂地图,该地图中路面跌宕起伏且急转弯较多,同时伴有阴影、逆光、视线遮挡等强干扰信息。这张地图就算是让玩家手动行驶也存在一定难度,因此在该地图上收集完美数据难度较大(不推荐使用这张地图进行训练和测试,效果会很差)。

3.行为克隆
在本项目中使用的核心技术是行为克隆(Behavior Cloning),行为克隆技术是机器学习和机器人领域常使用的一种方法,用于教授自动驾驶系统如何通过模仿人类的行为来执行特定任务。
该过程包括从执行任务(本项目中为在“训练模式”下驾驶汽车)的人类那里收集数据,然后使用这些数据训练人工智能模型(通常是深度神经网络)来执行相同的任务(即控制转向角、油门和刹车)。人工智能模型通过观察人类的行为并将其映射为在不同情况下可以采取的一系列行动来学习。在“训练模式”下,行为克隆会记录人类驾驶员的驾驶行为,然后使用这些数据训练人工智能模型来识别和响应不同的驾驶场景。一旦模型经过训练,它就可以用来控制自动驾驶汽车,使其能够像人类驾驶员控制一样在道路上行驶。
行为克隆的优点在于它是一种相对简单有效的训练自主系统的方法,因为它依赖于现有的数据,而不需要复杂的算法或传感器。然而行为克隆的局限性也很明显,该模型只能复制它训练过的行为,并且可能难以适应以前从未遇到过的新情况。一种可以想到的解决方式是通过测试不同的场景来识别潜在问题并完善自动驾驶汽车的安全性和可靠性,以确保自动驾驶系统能够处理道路上的各种情况。
4.端到端架构
自动驾驶本质上是一种类人驾驶,也就是计算机通过模拟人类的驾驶行为实现控制车辆,该功能的实现主要分为四个层次:感知、理解、决策和执行,通过各类传感器、电子控制单元(ECU)和执行器来实现。在实现自动驾驶的流程中:
感知层主要依赖激光雷达和摄像头等传感器设备所采集的信息感知汽车周围环境,以硬件设备的精确度、可靠性为主要的衡量标准;
执行层通过汽车执行器,包括油门、转向和制动(刹车)等,实现车辆决策层输出的加速、转向和制动等决策,主要依靠机械技术实现;
AI技术主要应用于理解层和决策层,担任驾驶汽车“大脑”的角色;
车辆的道路行驶环境非常复杂,需要处理大量非结构化数据。深度学习算法能够高效的处理非结构化数据,并自动地从训练样本中学习特征,当训练样本足够大时,算法能够处理遇到的新的状况以应对复杂决策问题。深度学习在自动驾驶领域主要有两种不同的架构:
- 端到端架构:一个深度神经网络模拟了人类
所有的驾驶行为; - 问题拆解架构:每个深度神经网络仅模拟人类驾驶员的
部分驾驶行为;
端对端的架构不需要人工将问题进行拆解,只需要一个深度神经网络,在经过训练后,基于传感器的输入信息(如照片),直接对车辆的加减速和转向等进行控制。
问题拆解的架构需要人工将问题进行拆解,分别训练多个DNN网络,实现诸如车辆识别、道路识别、交通信号灯识别等功能。然后基于各个DNN网络的输出,再对车辆的加减速和转向进行控制。
端到端自动驾驶技术可以认为是自动驾驶技术的终极目标,通过端到端驾驶,整个过程无需人工设计的繁复规则,系统只需要将采集到的图像输入神经网络模型,模型便能直接输出车辆的具体控制。如果预测的控制结果不理想,驾驶员便会对车辆进行干预,形成反馈。在这一过程中,模型可以自适应地学习到相对较好的驾驶方法,而无需各种条条框框的干预、限制。
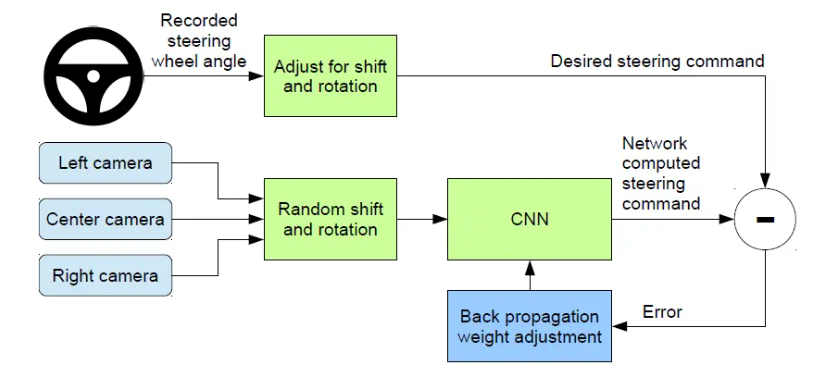
我们使用的深度神经网络模型基于英伟达公司的无人驾驶系统DAVE-2,其训练系统如下。图像输入CNN网络计算出建议的转向操作,根据建议操作(computed command)和期望操作(desired command)的差计算出误差,利用后向传播算法(BP)训练网络
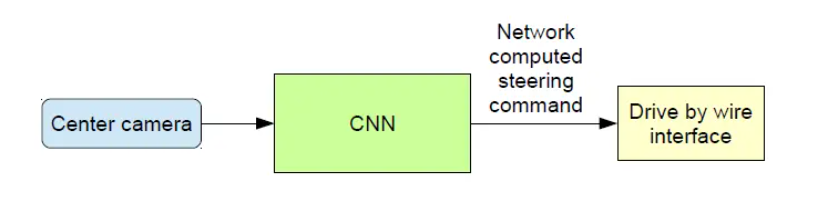
一旦训练完成,仅仅利用中间相机拍摄的视频图像即可使网络输出转向操作,如下所示
CNN是一种前馈神经网络计算系统,可用于从输入数据中学习。通过确定一组权重或过滤器值来实现学习,使网络可以根据训练数据来建模行为。初始化具有随机权重的CNN的期望输出和生成的输出将不同。这种差异(生成的误差)通过CNN的层进行反向传播,以调整神经元的权重,从而减少误差并使我们产生更接近期望输出的输出。
CNN擅长从图像中捕获分层和空间数据。它利用过滤器查看具有定义的窗口大小的输入图像的区域,并将其映射到一些输出。然后,它通过一些定义的步幅将窗口滑动到其他区域,覆盖整个图像。每个卷积过滤器层因此按顺序逐层捕获此输入图像的属性,捕获细节,如图像中的线条,然后是形状,然后是以后的整个对象。CNN可以很好地适应馈送数据集图像并将其分类到它们各自的类别中。
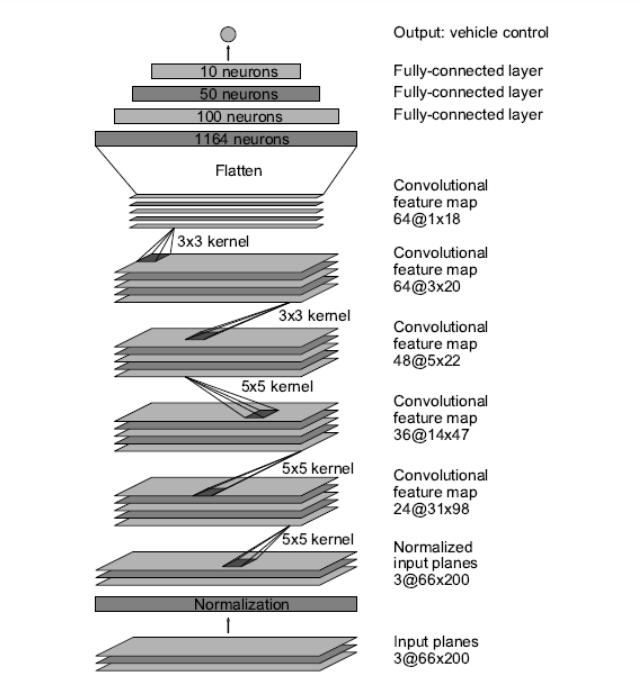
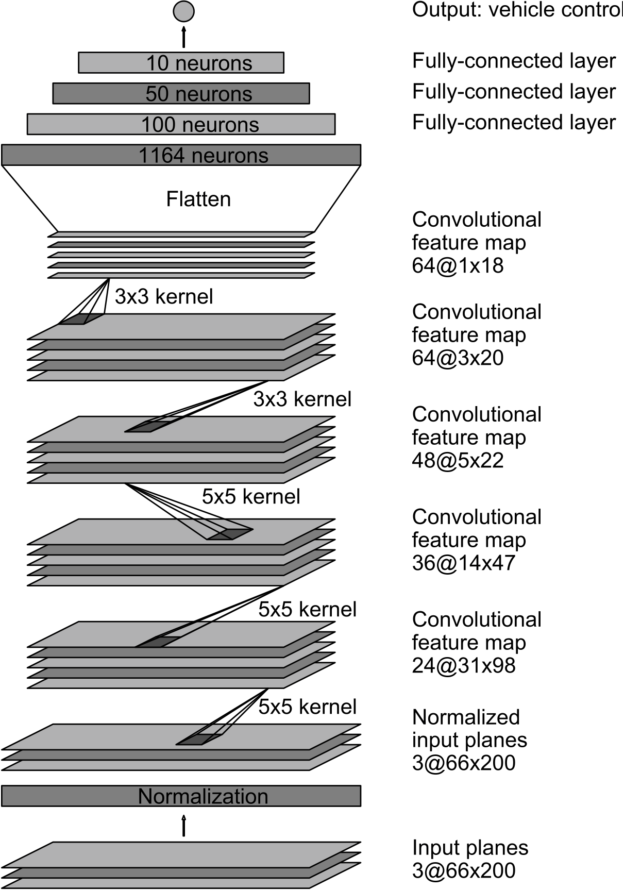
DAVE-2端到端架构中的CNN网络模型如下,网络一共含9层,包括1个归一化层、5个卷积层和3个全连接层,网络输入为YUV格式的图像,网络输出为转向指令(归一化只进行一次,在训练过程中不进行权值调整)
二、环境配置
本次项目需要以下环境:
- Unity+Udacity模拟器(收集数据、测试模型)
- Github仓库+Kaggle平台(上传数据、处理数据、训练模型)
- Conda虚拟环境+drive.py文件(提供Client接口、测试模型)
1.Unity+Udacity
因为Udacity模拟器需要下载Unity才能运行,因此需要先下载安装Unity,Unity的下载安装自行Google(我使用的Ubity版本是2019)。
安装好Unity之后,在udacity/self-driving-car-sim下载Udacity模拟器,注意如果打算修改模拟器的源码则需要Clone和Unity版本兼容的源码,如果没有修改源码的打算则直接点击下方链接选择对应版本下载即可(我下载的是Version 1对应的Windows 64版本)
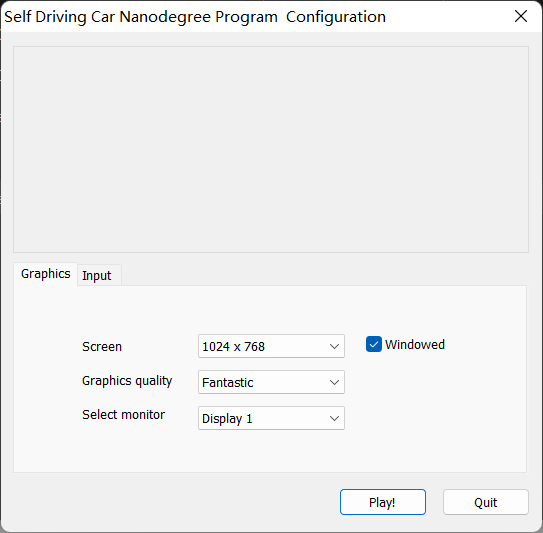
下载完毕后解压文件即可得到一个.exe文件和一个文件夹,双击.exe文件,如果能够成功出现以下界面表示第一部分配置完成
2.Github+Kaggle
Kaggle平台提供了如GPU P100等算力资源(注意这个GPU资源是有限的,每个月30h),同时Kaggle自带的环境几乎包含了当前python所有的库(这意味着我们无需手动创建虚拟环境、面临各种库的安装问题)。一方面我们可以直接在Kaggle的notebook中编写代码,另一方面Kaggle提供的GPU资源可以帮助我们更快的训练模型。
使用Kaggle平台首先需要注册,具体方式自行Google,注册完毕后在主页新建notebook

在notebook的右边会有一个Data列,我们所有的训练数据都只能从此处导入
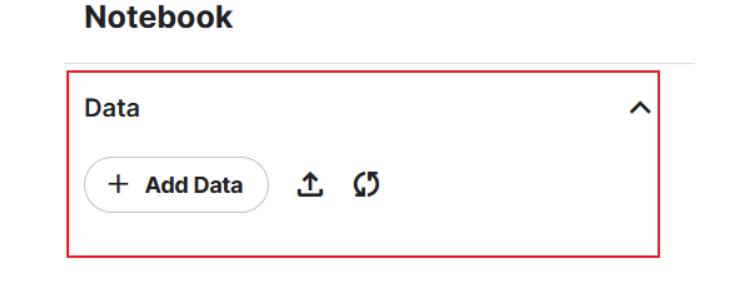
一个方式是直接将本地的训练数据上传,该方法只需要点击Add Data并按照指示上传ZIP文件即可,另一种方式就是在Cell中运行Git命令,从Github的仓库中拉取数据(注意修改clone后的地址为自己仓库的地址)
1 | |
两种方式各有好坏,可自行选择,我选择的是为训练数据单独创建一个Github仓库,每当需要的时候拉取该数据。
如何创建Github仓库以及如何利用Git工具将本地的文件上传到新建的仓库中,网上有很多教程,这里不再赘述。
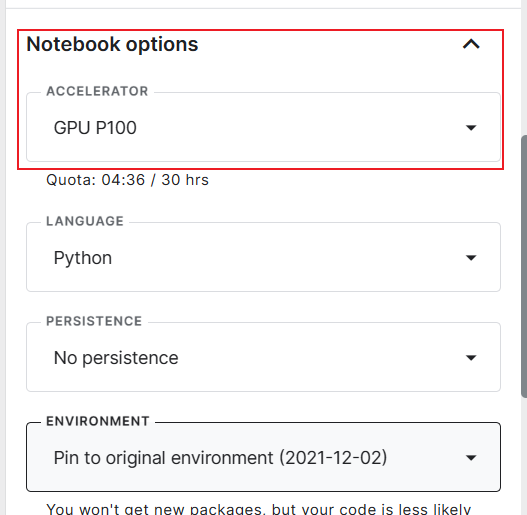
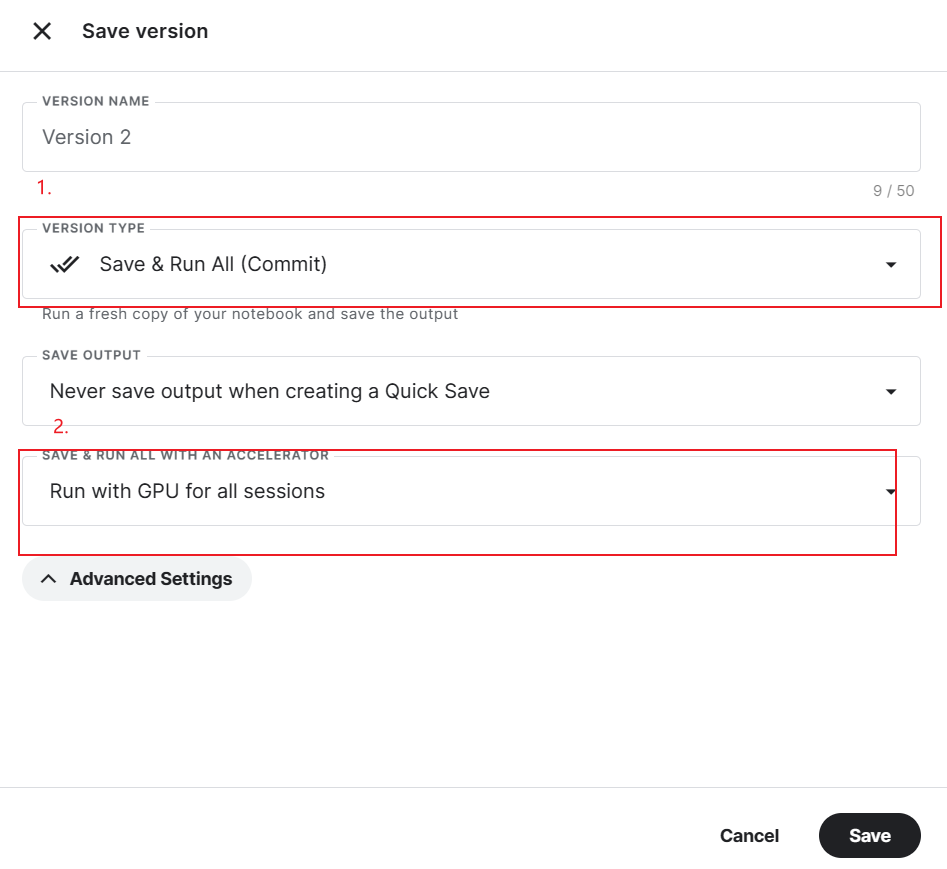
如何调用Kaggle平台的GPU资源?主要有两种方式,一种是直接在notebook网页交互界面的右边Notebook options中选择要使用的Accelerator就行,这种方式不是很推荐,因为每次关闭网页后Cell中的变量以及输出等都会丢失需要重新运行才行。
另一种是保存整个notebook(右上角save version),默认情况下整个notebook会在后台重新run一遍,run完成后即可查看notebook的运行结果和logs以及output等输出,该方式的输出等都会保存在Kaggle上,并不会随着网页的关闭消失(这意味着save后你可以关闭电脑睡一觉起来验收训练成果)。
3.Conda+drive.py
Conda工具可以创建特定的虚拟环境,保证python环境之间互不干扰,现在一般流行的python发行版是Anaconda或miniconda(我选择的是miniconda,相对来说体积较小自由度高)。
借助Conda工具新建一个环境,该环境中包含了如Flask框架、Tensorflow等对模拟运行及其重要的库,新建该环境既可以直接借助我给的environment.yml文件自动安装,也可以自己手动一个一个安装库。这里强调注意每个库的版本,因为该项目中涉及的库的版本及其容易出现不兼容的情况,所以一定要按照对应的版本进行安装。
自动安装的conda命令如下(因为机器版本或使用的Channel不同,所以自动安装可能失败,建议手动安装,environment.yml文件作为一个库版本的参考)
1 | |
手动安装的步骤如下,先创建一个python版本为3.8.12的名为AutoCar的虚拟环境
1 | |
激活该环境并安装需要的库(其他库创建环境的时候就已经装好,无需重复安装)
1 | |
1 | |
创建好了conda环境后,还需要drive.py文件,该文件是一个驾驶小车的脚本文件,可以在udacity/CarND-Behavioral-Cloning-P3获取,在“自动驾驶模式”下,drive.py文件将提供Client端口与模拟器充当的Server进行交互。
三、数据获取
在上述环境配置完毕后,就可以开始采集训练数据。
Udacity模拟器具有自动创建图像数据集的功能,这使得采集数据的行为变得容易:
- 在Simulator中,这辆车的传感器是三个前置摄像头,分别放置在左、中、右三个方向,对周围的环境进行拍摄录制,结果之后会以图片形式保存到电脑;
- 捕获到图像流后,可以设置图像在磁盘上的保存位置,图像数据将保存在IMG文件夹中。图像集以复杂的方式进行标记,带有前缀 center、left 或 right,表示该图像是从哪个摄像头捕获的;
- 除了图像数据集外,Simulator还会生成一个datalog.csv文件,该文件包含图像路径及其对应的方向盘转向角度、油门、制动和车速信息;
具体操作如下。选择“训练模式”和Track1(简单地图),进入游戏,点击右上角“Record”会弹出选择训练数据保存的位置,选择完毕后进入Recording状态,此时只需要使用方向键控制小车移动即可,推荐行驶三到四圈,结束后再次点击“Record”结束录制。为了确保得到的数据质量,在行驶过程中需要遵守以下几点:
- 尽量保持车辆行驶在车道中央;
- 尽量不要做额外的减速、打方向盘行为;
- 在转弯过程中尽量保持丝滑连贯;
结束采集后得到的数据如下

IMG目录中保存了数据集中采集得到的图像

driving_log.csv文件形式如下
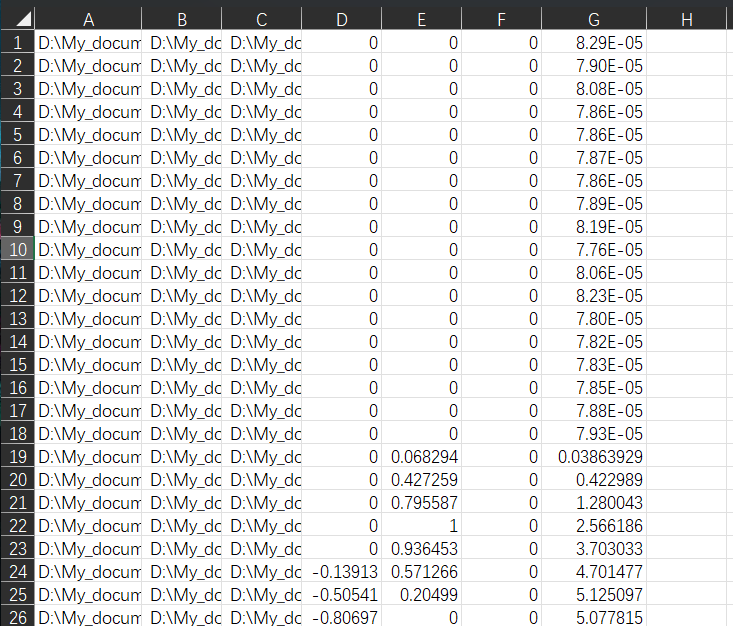
- A,B,C列:对应中心、右和左摄像头拍摄的数据集图像路径;
- D列:转向角度,值为0表示直行,正值为右转,负值为左转;
- E列:该时刻的油门或加速度 ;
- F列:该时刻的刹车或减速度 ;
- G列:车辆当前行驶速度;
四、数据处理
数据处理操作在Kaggle中进行,新建Notebook后按照如下操作进行即可
1.上传&读取数据
为了利用Kaggle平台的计算资源,需要将采集得到的IMG和driving_log.csv文件上传到Kaggle中,在[环境配置](# 2.Github+Kaggle)中已经介绍了两种方式,这里我选择的是上传到Github中再使用Git命令获取

从仓库中下载需要的数据到Kaggle之后,需要将csv文件读取到内存中(csv文件中包含了所有的数据的信息,如同一时刻摄像头拍摄图像的位置、转动角度、加速度等)。使用pandas来完成对csv文件的读取,借助pandas数据格式可以根据具体的情况来给不同的列设置不同的列名。
1 | |
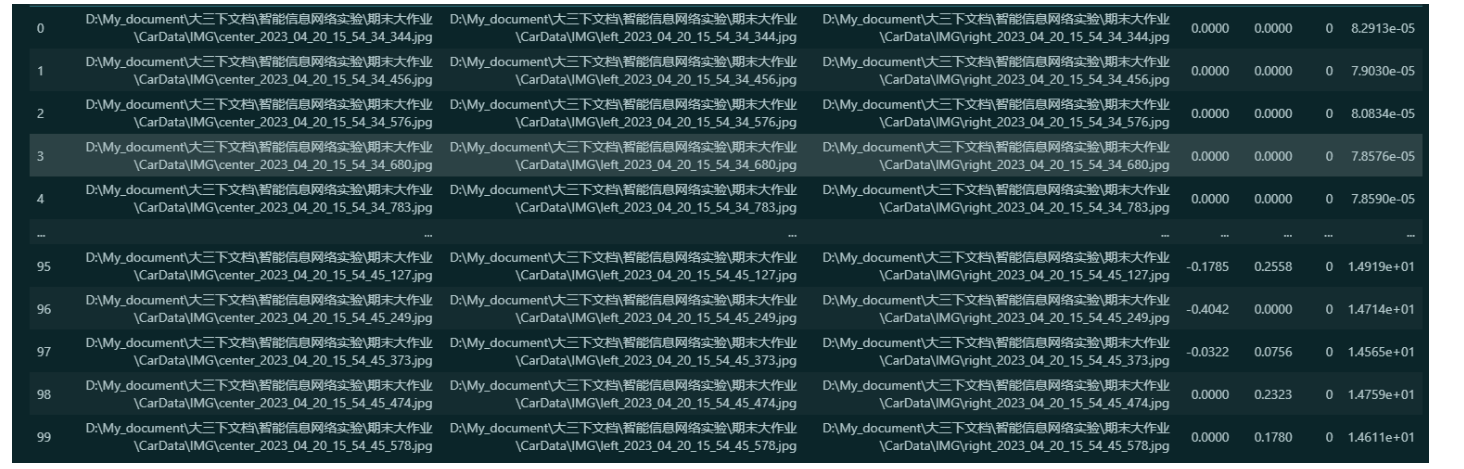
取数据的前100列输出得到以下的结果:
2.数据预处理
2.1 修改路径
本地获取到的csv文件中,第一、二、三列的数据是本地的绝对路径。若使用kaggle来完成训练,除了需要将csv和IMG保存到kaggle上,还需要将绝对路径改成kaggle上的相对路径。
具体的步骤很简单,将data的第一、二、三列数据切分,只保留它们的最后的那一部分即可。
1 | |
2.2 数据瘦身
原始数据是在本地电脑拍下的图片和记录的各参数,实际大部分都是三无数据(无转向、无油门、无刹车),即这些数据都是直行的数据。通常自动驾驶在没有遇到指定的情况的时候也是直行,这意味着将大量这些无用的直行数据用于训练既没有训练效果也浪费训练时间,因此需要适当减少训练数据。
对数据进行清洗之前需要先对数据进行分析,这里先将所有的数据可视化。
1 | |
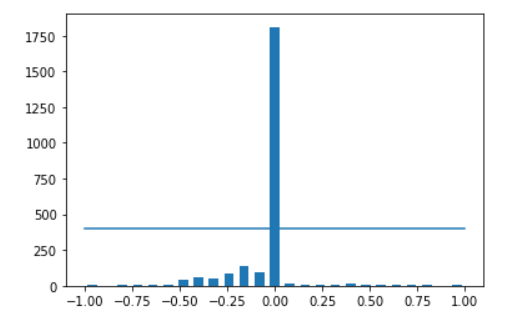
通过设置一个400位置的阈值,可以直观地看到直行的数据占据很大一部分的训练数据
采用随机丢弃的方式丢弃一部分直行数据。使用循环结构指定我们要删除的样本,通过循环获取bins区间的所有数据,然后打乱遍历获得的数据。将打乱之后的数据400之后的元素全部去掉(保留400)
1 | |
处理完后的结果如下
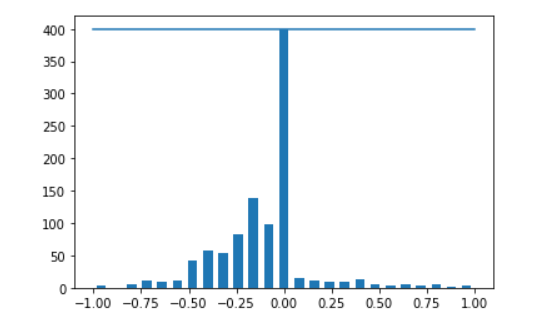
可以看到,相较于之前足足2000个直行的数据,该数据集更加均衡。
2.3 特征数据
通过上面的操作,得到1001个较好的数据。每一个数据都包含了前左右摄像头三个摄像头拍摄的图片以及它们的转向参数。
将每一个摄像头及其参数当做一个数据,即将每一个摄像头看成一个数据来得到特征数据。
1 | |
需要注意的是,对于左摄像头和右摄像头,需要进行特殊的处理。因为每一个摄像机都是看成一样的,故处理左和右摄像头的本质是处理前摄像头。
当车辆直行时,前摄像头拍摄的图像对应的转角是0°,而当前摄像头遇到左转弯(即摄像头前面有障碍但左边没有障碍)的时候,前摄像头对应的转角是左转,也就是-0.xx°。
当前摄像头直行的时候,右摄像头拍摄的其实就是前摄像头遇到左转弯的时候的类似情景(不考虑车辆往后走),同理左摄像头拍摄的就是前摄像头右转弯的情形。
具体情况如下所示:
这是一个直行的车以及它的左、右摄像头。它右摄像头拍摄的图片对应于前摄像头,应该是下面这张图的样子:
也就是左转的情况,所以对于右摄像头拍摄的图片,需要加上左转角。通过将不同的摄像机统一处理,得到统一的数据。
3.划分数据集
将上述特征数据进行划分得到训练数据集和测试数据集,借助sklearn中经典的train_test_split完成数据集的划分
1 | |
可视化如下所示:
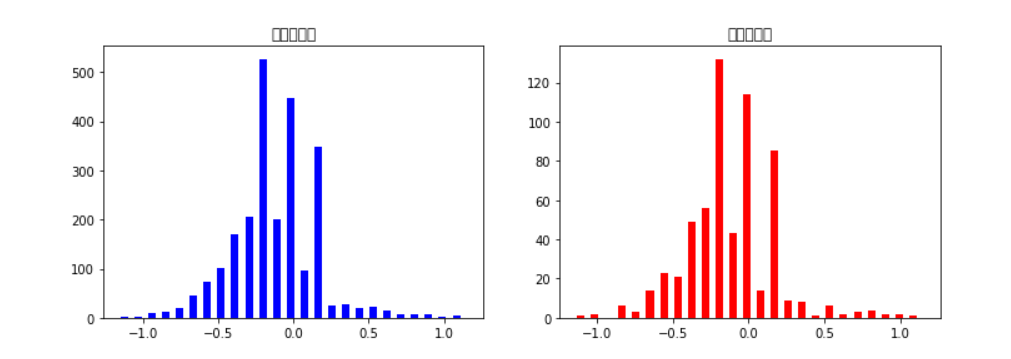
4.泛化处理
收集数据时,只在一个赛道上模拟了驾驶过程。实际情况下的自动驾驶会遇到各种道路以及突发情况,为每个可能的赛道收集数据并训练自动驾驶汽车模型这是不可取的策略。这里只需要借助cv2图像库对已获取的数据进行处理即可获得更多的训练数据,主要分为以下四种情况:裁剪天空、图像错位、亮度变换、镜像变换
4.1 裁剪天空
训练数据中,对模型有用的部分是路面的情况。而图像中天空的背景往往占据很大一部分,因此可以对其进行裁剪以得到对训练更有用的图像。
具体的情况如下所示:
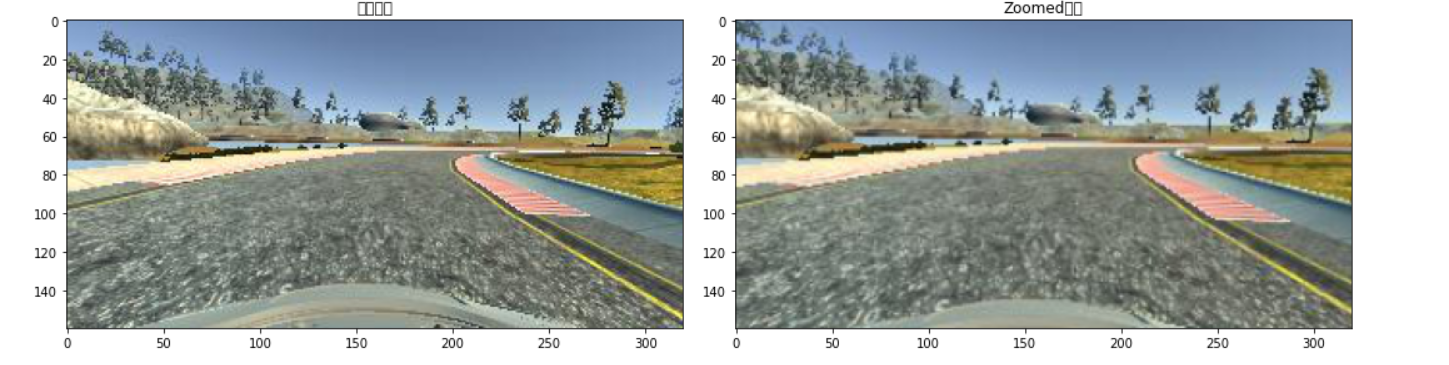
4.2 图像位移
考虑到摄像机的拍摄位置不会完全一致,图像会被稍微地进行位移,有垂直位移和水平位移
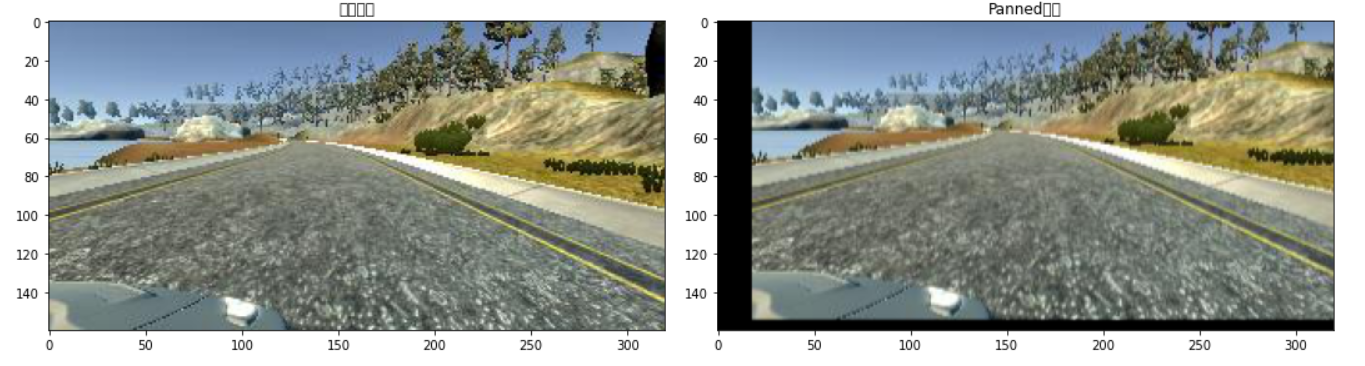
4.3 亮度变换
考虑到汽车的驾驶状况除了道路状况外还有环境因素,如阳光明媚的白天或多云、低光条件等,亮度增强可以证明非常有用。
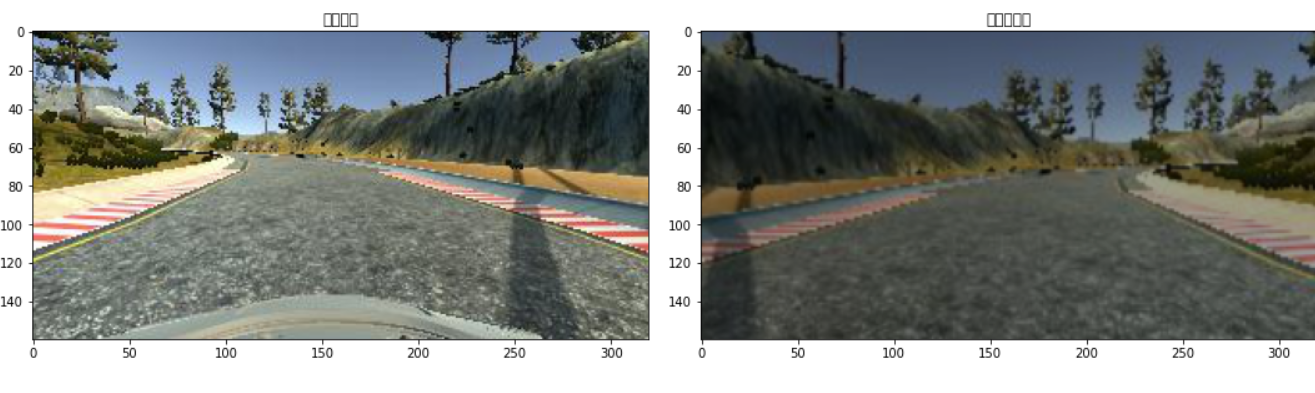
4.4 镜像处理
收集数据时使用的赛道左转的情况比较多,所以原数据集的转角数据大多数都是负的。为了获取右转数据,可以直接对左转的数据进行镜像翻转得到无需额外收集。
对上述四种情况的处理函数进行封装,后续直接调用random_augment即可对图像进行泛化处理。
1 | |
最后,还可以进行一些优化处理,如将图像转换为YUV格式,使用高斯模糊减小图像大小以便更容易处理,对数值进行了归一化等
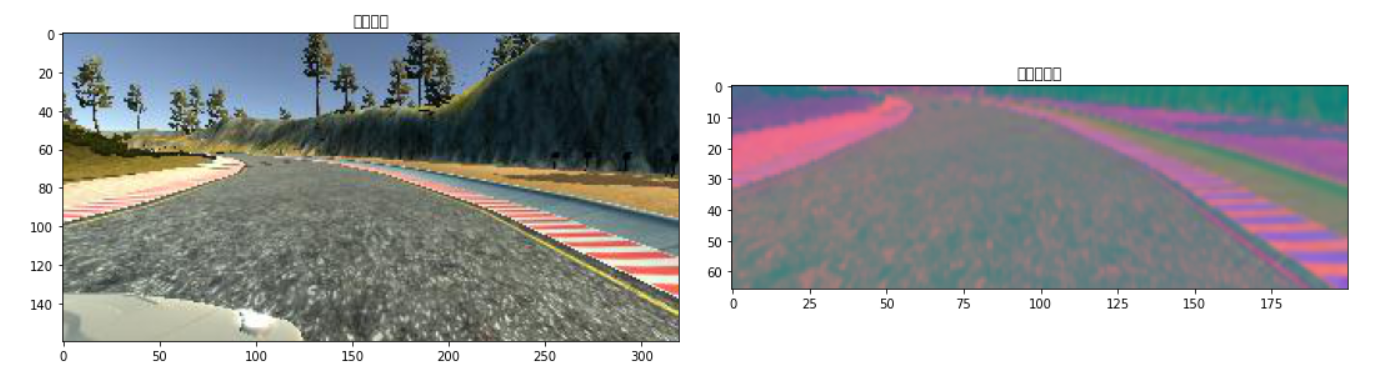
5.数据封装
批量生成器函数 batch_generator用于生成用于训练神经网络的批量数据,该生成器函数允许从训练数据中随机选择图像并生成相应的批次数据,可以用于训练深度学习模型。在训练中,可以设置 istraining 参数为True以执行数据增强,有助于提高模型的泛化能力。
1 | |
通过以下代码调用生成器
1 | |
五、模型训练
在[项目介绍](# 4.端到端架构)中提到过,本项目使用的网络结构基于英伟达的端到端模型,该模型是一个深度卷积网络,非常适用于监督式图像分类/回归问题,原因如下:
通过行为克隆,用于训练的数据集比以往使用的任何数据集都要复杂(需要更高级的模型)
行为克隆代码必须返回适当的转向角度,这是一个回归类型的任务(深度卷积网络适用于回归问题)
当前的数据集有2402张(200,66)大小的图像要训练,而MNSIT大约有6万张图像用于(该模型处理我们的模型完全够用)
该模型已被NVIDIA用于端到端自动驾驶测试(具有实践性)
整个英伟达模型的网络结构如下所示:
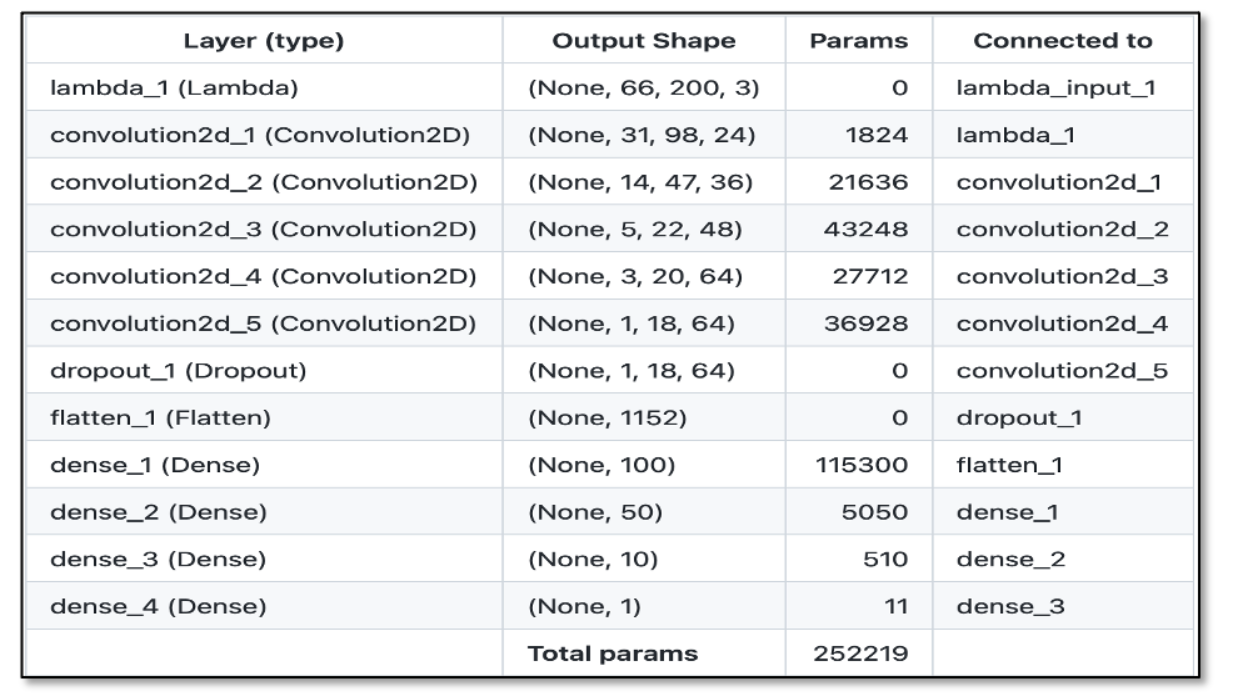
具体网络介绍参考链接:https://developer.nvidia.com/zh-cn/blog/deep-learning-self-driving-cars/
1.模型简介
模型的训练目标是通过训练权重来最小化网络输出的方向角度与真人驾驶时的汽车方向角度的均方误差。即通过训练网络的权值,以使网络输出的转向命令与人类驾驶员的指令或偏离中心和旋转图像的调整后的转向指令之间的均方误差最小化。
下图展示了训练所使用的网络体系结构,它由9个层组成,包括1个归一化层(即输出层)、5个卷积层和3个全连接层(输入层不算作一层,因为输入层的作用通常被认为是固定的,而不是网络架构的一部分)
网络的第一层执行图像标准化。规范化器是硬编码的,在学习过程中不会进行调整。在网络中执行规范化允许标准化方案随网络架构改变,并通过 GPU 处理加速。
卷积层的设计是为了进行特征提取,并通过一系列不同层结构的实验进行经验选择。然后,在前三个卷积层中使用跨步卷积,步长均为2×2,核为5×5,最后两个卷积层使用核大小为3×3的非跨步卷积。
通过五个卷积层和三个全连接层,得到最终输出层的输出控制值,即反向转弯半径。
Q:跨步卷积和非跨步卷积的区别是什么?
A:通常情况下,跨步卷积用于减小输出特征图的尺寸,从而减少模型参数和计算量。非跨步卷积通常用于保持特征图的尺寸或在空间维度上增加分辨率。
2.模型定义
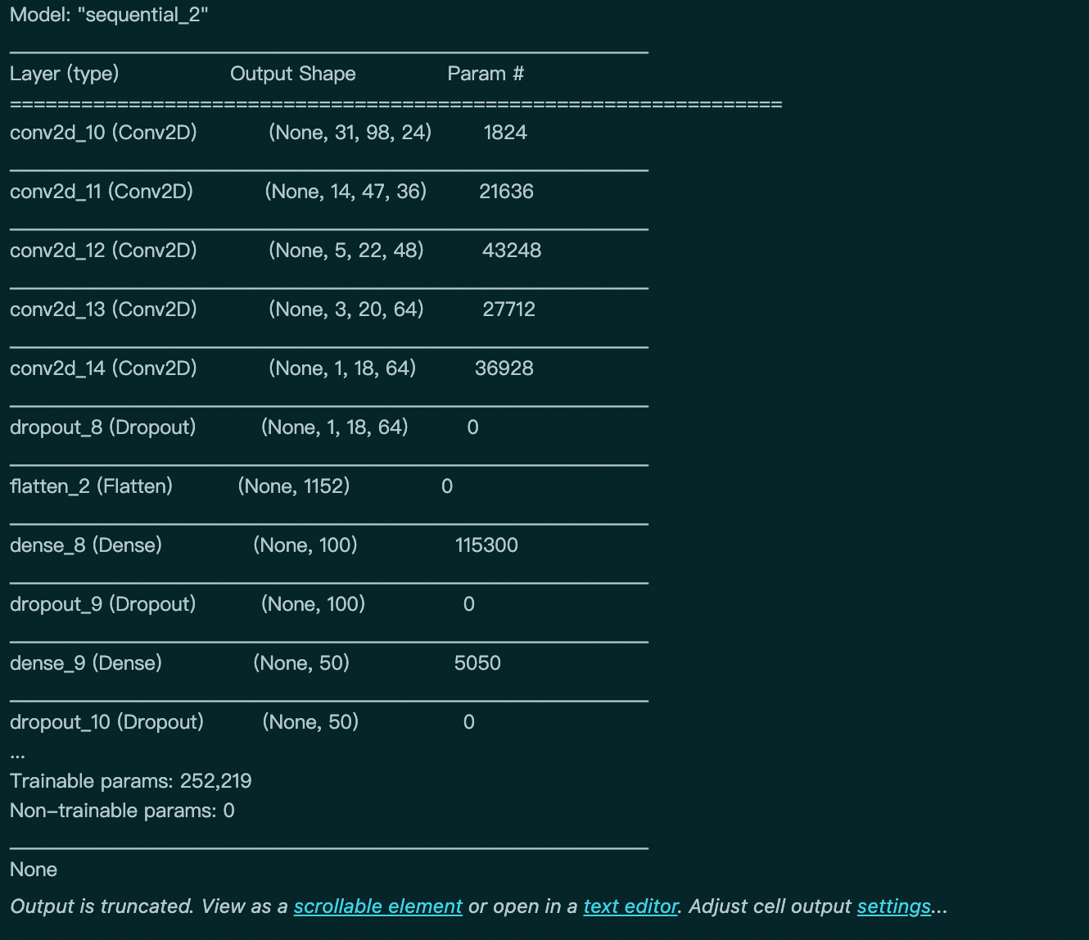
定义英伟达的端到端的自动驾驶的神经网络训练模型如下:
1 | |
输出网络结构如下所示:
Q:为什么激活函数使用elu而不是relu?
A:回答参考Asikpalysik,简单来说就是elu函数可以解决“dead relu”的问题,避免结点只向后面的结点提供零值。
3.模型训练
定义完成之后我们就能够直接使用kaggle来进行训练,训练的情况可以直接通过下面的链接来进行查看(或者查看AutoCar文件夹下的ipynb文件)
https://www.kaggle.com/code/ookanshouoo/unity
训练的过程如下所示:
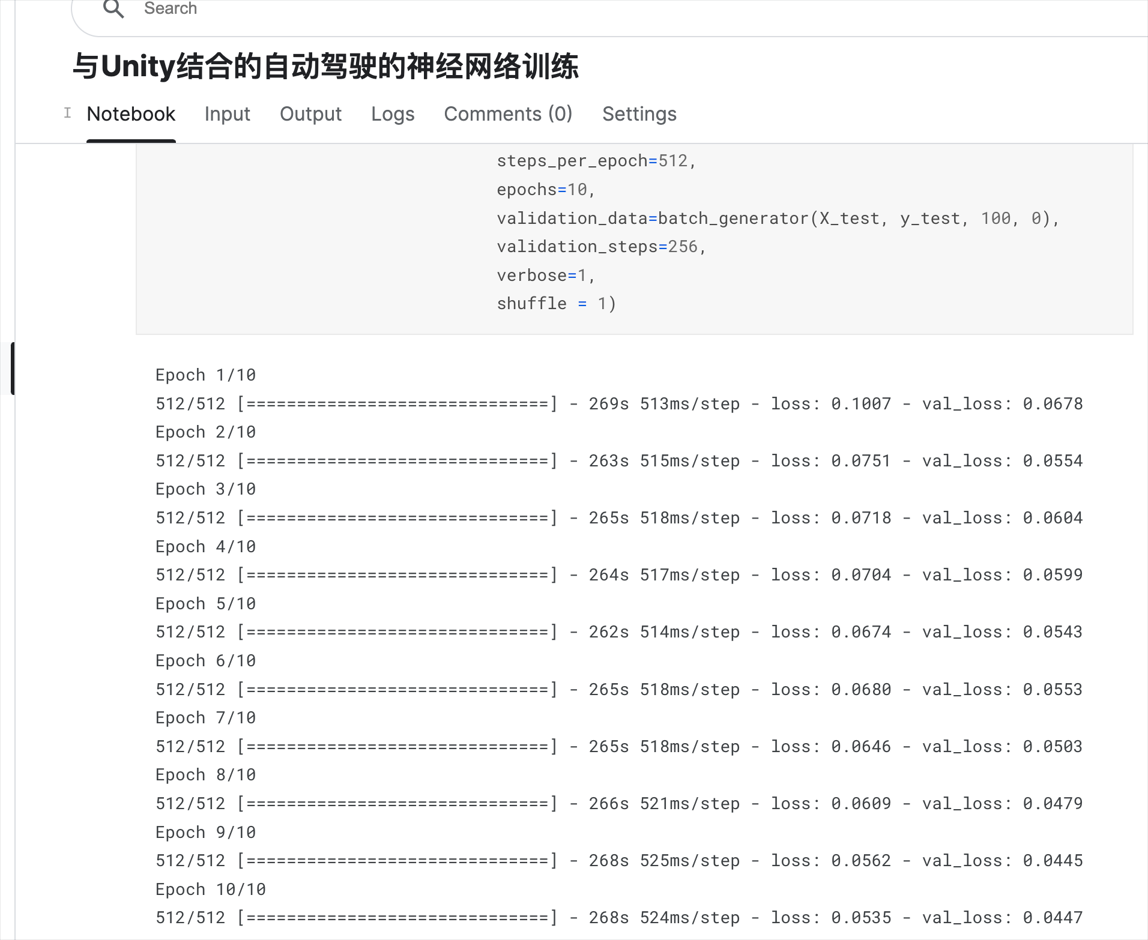
训练时间如下所示:

六、模型测试
在Kaggle中训练完毕后我们会得到一个h5模型文件,我们把这个文件下载到本地,保存到与drive.py文件同级的目录
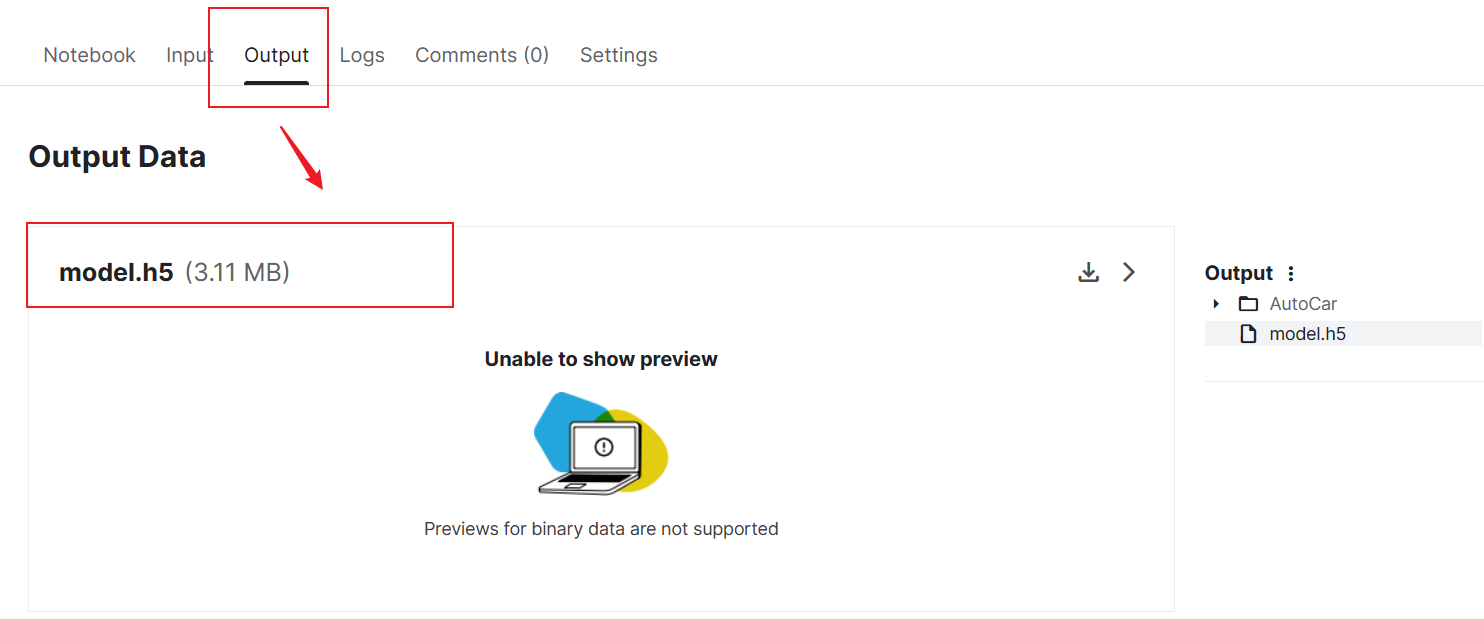
接着在drive.py文件目录下打开shell,进入之前借助conda创建好的AutoCar虚拟环境
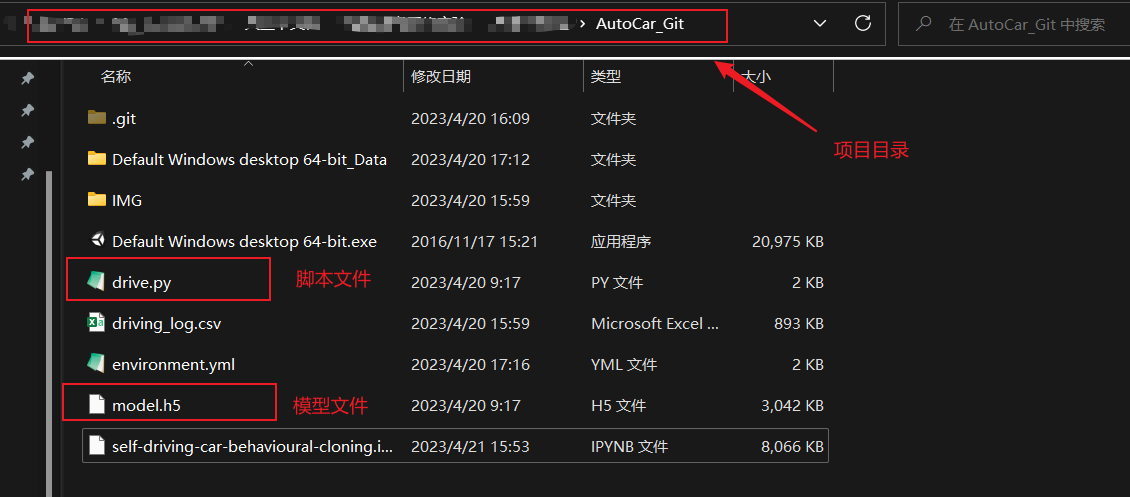
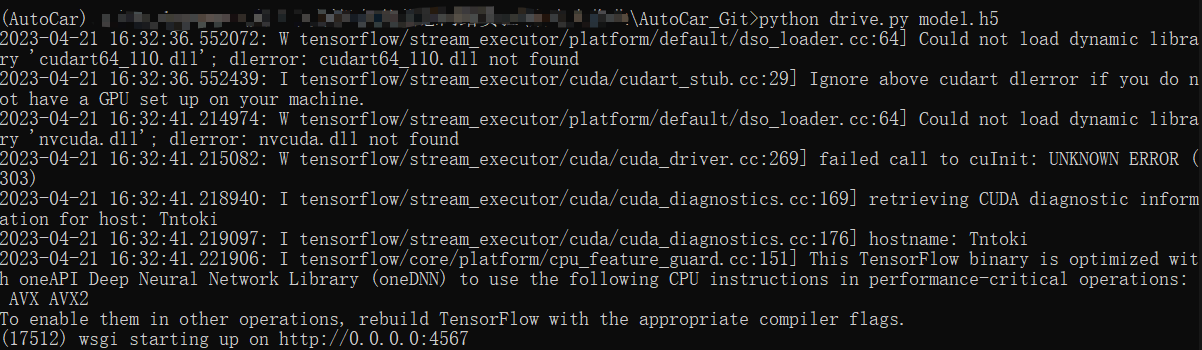
在该环境下使用命令运行drive.py脚本文件
1 | |
出现如下输出表示脚本启动成功
接着在游戏中选择“自动驾驶模式”,等待连接完成后可以看到小车自动开始驾驶
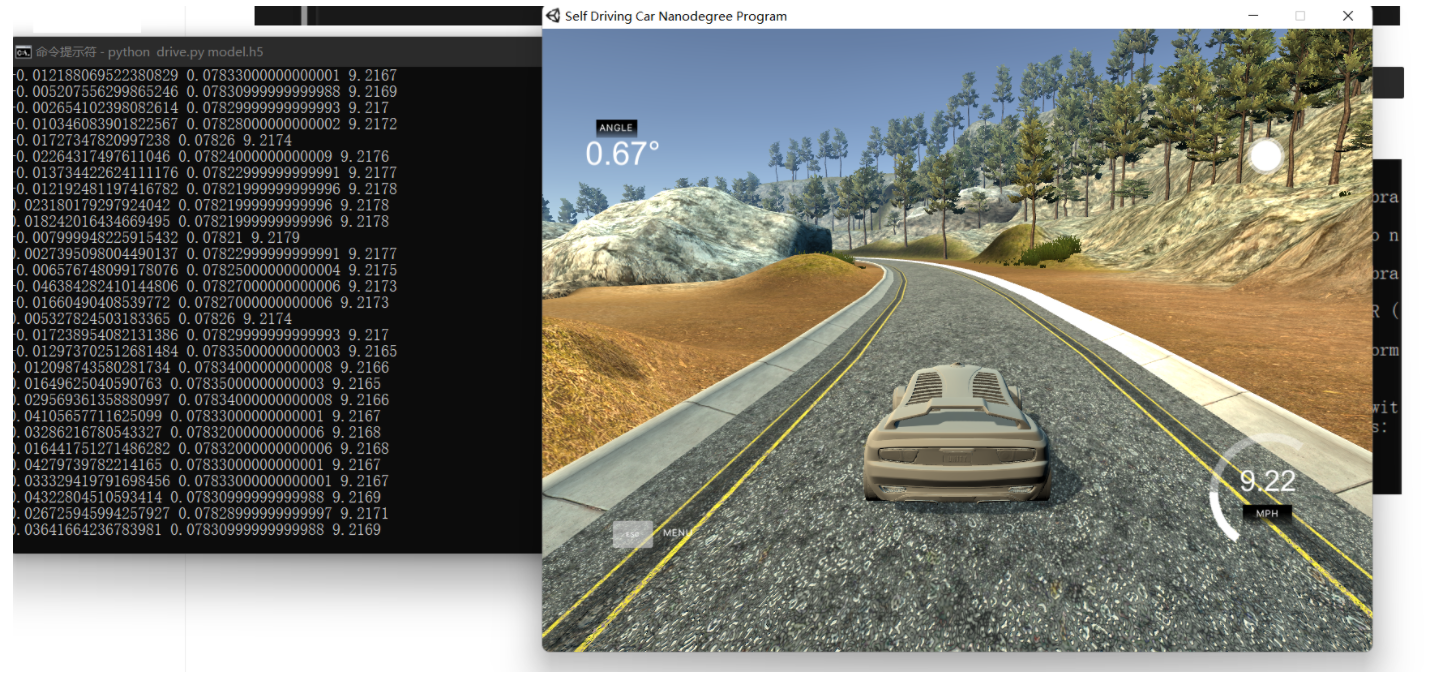
若要终止自动驾驶,在游戏中按下“ESC”,同时在终端中按下”Ctrl+C”停止脚本运行。