初级项目_灾情知识图谱
2023/4/25 21:53 基本上看了相关的教程,明白了如何使用Neo4j图数据库来创建一个知识图谱,但是对于老师给的暴雨洪涝语料知识而言,现在还没有很好的办法进行处理,并且因为老师给的描述比较模糊,所以其实整个作业的流程也不是特别清晰,这个等放一段时间之后看能不能有所顿悟;
2023/5/10 14:26 距离作业截止还有二十天,现在开始要着手构建了,先把老师发的论文看了,该论文有一定的介绍性功能,作为主要参考(因为其他地方实在找不到参考了);
2023/5/10 20:58 无论如何一定要先找一个类似的可以用得上的项目作为参考,纯看论文讲的头头是道实际上没什么用(有些代码根本跑不起来,不要浪费时间去白跑);
2023/5/11 9:04 很遗憾的是根本就找不到参考的代码,这次只能靠论文来作为参考了;
2023/5/11 16:58 看完唐宇迪的视频之后豁然开朗了(这几个小时真的不亏),知识图谱整个构建过程中最难的就是知识抽取模块,而知识抽取中的实体抽取和关系抽取要么使用之前用过的BiLSTM-CRF,要么使用更强的Bert预训练模型,无论哪种模型都需要大量的训练数据来支持,因此一个必要的构建标注的训练数据的代码尤其重要,而唐宇迪介绍的项目中恰好有这个构建标注的代码。回到正文,为什么说看了视频之后豁然开朗呢?因为我们完全不需要自己去微调预训练模型之类的对陌生的数据进行提取…我们仅仅只是做一个作业而已(又不是真的要做一个专业领域的可用的知识图谱,那是研究生论文级别的),老师都已经把所有的实体以及对应的关系的文本给我们了(相当于,老师给了我们标注好的训练数据,我们可以不用这个训练数据去训练模型,我们直接使用这个数据去构建知识图谱),只需要写一个简单的正则表达式或者提取代码就可以形成三元组形式的txt文本。因此接下来的任务只需要分析老师给的语料数据,将其处理成目标txt格式即可(看什么论文或者作业要求都是扯淡的,只是做一个期末作业不是研究生课程OK);
2023/5/11 19:48 很遗憾,你把这个事情想得太简单了,老师给的数据只有实体标注,而且这个实体标注的质量非常差,也就是说你还是需要自己创建一个数据集(不管是创建这个数据集来直接制造知识图谱还是训练模型)。所以现在数据集的创建是我们面临的最大的问题,要么询问老师这个怎么解决,要么就只能等同学的数据集;
2023/5/11 23:53 刚刚突然想到一个非常有用的提取数据的方式(并且证实了是有一定可行性的) – 将文本输入给chatgpt让它帮你完成(实体,关系,实体)三元组的抽取,当然我也询问了它具体使用的是什么方法,它告知我使用的是 “Open Information Extraction” (Open IE)算法,这个算法在github上是开源的(philipperemy),而且这个算法的中文教程说实话也不少,有时间可以看看;
2023/5/12 10:45 有可能是训练语料的问题,Open IE在中文数据上的表现非常的差劲,这里推荐几个中文工具hankcs/HanLP – 这些东西都没法用,甚至连chatgpt的api也没法用(请求次数限制);现在唯一的解决方式就是通过使用chagpt生成一定数量的训练数据,然后将该训练数据放入模型进行训练,最后利用模型自动提取剩余文本的三元组(个人认为这是最low的方法,但是我也想不到其他的方法了);
2023/5/16 8:36 不要使用深度网络或者正则表达式去提取三元组,因为根本没有训练数据,需要做的是直接从纯净无参考的文本中借助外部程序进行实体识别和关系抽取,对句子进行依存句法分析,查找主语-动词-宾语结构,其中主语和宾语是实体,动词表示它们之间的关系,当然还有其他模式,这一切都是基于依存句法分析(关于工具的选择,不要去用那些参考比较少的,尽量选择参考较多的)。
2023/5/16 21:32 现在唯一行得通的就只有依存分析+关系抽取这一条路了,至少现在看来这条路“好像”行得通,网上也有很多代码和参考。今天尝试了使用百度的DDParser进行依存分析效果的确不错,但是找到的参考代码都是基于LTP的(为什么要找参考代码是因为我就算进行了依存分析也不知道怎么提取三元组…),所以可能之后还是需要重新用一用LTP。最后我想说的是,之所以作业那么久没做出来还是因为自己一根筋,关系抽取又不只是只有神经网络这一种方式,提前做好课前准备挺有必要的。今天的状态稍微有点差可能不太能看进去了,明天继续;
2023/5/17 14:15 非常幸运的是,参考老刘的项目使用DDparser居然直接就跑通程序了,而且提取效果也还行(至少比我自己手动提取还要好),鉴于环境配置和时间的原因,这里我就不再尝试ltp版本和jieba版本,现在需要做的就是看看老刘另一个自动化构建知识图谱那个项目看看有没有可以拿来做参考的东西,没有的话我们就直接开始对项目下手了。至于其他两个参考项目我并没有尝试,我也不想尝试了(毕竟ltp的配置实在是太麻烦了,而且相对于我花了半天时间熟悉的DDParser以及环境完美配置好的优势,ltp的项目对我来说不是必须的) – 看完了,除了DDParser的项目其他都不采用,一方面是没有那么多时间去配置环境,另一方面也不太符合我们作业的要求。现在只需要将三元组提取出来然后再进行知识融合等操作(文本预处理那块不知道是否可以参考之前的方式);
2023/5/18 11:18 现在基本上已经把所有的预处理过程处理完毕了,neo4j这个软件真的非常的难用(最终成功的是中文的社区版),而且因为对cyber语句的不熟所以也不太会用,暂时先使用gpt看看能不能熟悉neo4j的基本使用,实在不会再看教程吧 – 这个知识图谱构建好了就别乱改了,理解之后直接写报告,不要再瞎折腾;
2023/5/24 9:41 之前听老师说了之后,发现自己构建的三元组还是有一定不足的。首先就是三元组的实体和关系数量太多,尽管对实体进行了对齐和清理等操作,但是从可视化的方面来说,实体对齐之后的实体应该是老师在实体语料中给出标注的实体的子集。另一方面,关系的类型应该限定,否则会出现很多没有意义的比如纯数字的关系(毕竟使用依存句法分析进行提取也不能保证完全的准确),因此接下来还需要对知识图谱进行改进的地方在于对提取出来的三元组进行优化;
2023/5/25 17:03 现在已经把实体和关系对齐做完了,接下来就是手动处理文件中的不合理的内容(删除或调整),然后生成知识图谱之后写实验报告。实验报告中需要新增的内容无非就是三元组清理过程中的第三步和第四步,其中第三步使用的近义词计算工具可以好好分析一下它的原理。写实验报告的时候多看看notebook,因为当时写代码的时候的全部思想都随手写在notebook上了;
一、背景知识
1.Neo4j图数据库
参考链接:
前置知识点:
- 知识图谱创建完整流程:
- Neo4j教程(W3School):Neo4j构建一个简单知识图谱 - 农夫三拳有點疼 - 博客园 (cnblogs.com);
- Neo4j官方用户手册(汉译英):Candysad/neo4j: neo4j notes in Chinese (github.com);
- Neo4j桌面版使用教程:Neo4j桌面版使用说明 - 知乎 (zhihu.com)(社区版无法批量导入csv数据);
环境配置(在我的电脑上我下载的是英文的桌面版和中文的社区版):
Neo4j英文版:
Neo4j中文版:
- Neo4j中文版下载地址:博客 - 微云数聚 (we-yun.com);
- Neo4j中文版部署指南:Neo4j 5.x 简体中文版指南 (we-yun.com);
问题解决:
neo4j中文版简单启动:Neo4j 5.x 简体中文版指南 (we-yun.com)(登陆密码之前修改过,然后不记得了,但是浏览器自动保存有);
使用
neo4j console启动失败:neo4j启动失败的解决方案 - 一杯明月 - 博客园 (cnblogs.com),直接重装最新版本的Neo4j 5.x版本;
notes:
- 如果电脑安装了社区版和桌面版,尽量同时间只启动并使用一个即可;
- 安装了桌面版Neo4j后,尽量不要update,因为更新后会将安装目录自动改到C盘,所以建议直接卸载后安装最新版本到D盘中;
Neo4j 是一个图形数据库,就像传统的关系数据库中的 Oracel 和 MySQL一样,用来持久化数据。Neo4j 是最近几年发展起来的新技术,属于 NoSQL 数据库中的一种。
知识图谱是一种基于图的数据结构,由节点和边组成。其中节点即实体,由一个全局唯一的 ID 标示,关系(也称属性)用于连接两个节点。通俗地讲,知识图谱就是把所有不同种类的信息连接在一起而得到一个关系网络,提供了从“关系”的角度去分析问题的能力。
而 Neo4j 作为一种经过特别优化的图形数据库,有以下优势:
- 数据存储:不像传统数据库整条记录来存储数据,Neo4j 以图的结构存储,可以存储图的节点、属性和边。属性、节点都是分开存储的,属性与节点的关系构成边,这将大大有助于提高数据库的性能。
- 数据读写:在 Neo4j 中,存储节点时使用了
Index-free Adjacency技术,即每个节点都有指向其邻居节点的指针,可以让我们在时间复杂度为 O(1) 的情况下找到邻居节点。另外,按照官方的说法,在 Neo4j 中边是最重要的,是First-class Entities,所以单独存储,更有利于在图遍历时提高速度,也可以很方便地以任何方向进行遍历。 - 资源丰富:Neo4j 作为较早的一批图形数据库之一,其文档和各种技术博客较多。
- 同类对比:Flockdb 安装过程中依赖太多,安装复杂;Orientdb,Arangodb 与 Neo4j 做对比,从易用性来说都差不多,但是从稳定性来说,neo4j 是最好的。
综合上述以及因素,Neo4j 是做知识图谱比较简单、灵活、易用的图形数据库。
2.知识图谱技术
构建一个知识图谱的完整流程主要分为以下几个步骤
2.1 知识抽取
知识抽取的目的是从非结构化的文本中提取出结构化的三元组数据
知识抽取主要分为:
- 实体抽取:实体抽取也称为命名实体识别,主要有基于规则和词典的方法、基于机器学习的模型预测方法(前面做过的实体抽取项目)
- 关系抽取:关系抽取主要用于判断实体之间的关联关系,主要分为
- 限定领域关系抽取:即根据预设好的关系集合,判断给定实体是否满足某一个关系(类似分类任务,F(实体1,实体2,文本)->关系),对这种有监督的分类任务的训练方式进行细分
- pipeline方式:先对文本中的实体进行抽取,接着再将抽取出的实体和文本作为输入进行关系抽取;
- 联合训练方式:直接将文本中的实体和关系同时抽取出来;
- 开放领域关系抽取:主要是基于序列标注对模型进行训练,使模型具备自动识别并提取关系的能力
- 限定领域关系抽取:即根据预设好的关系集合,判断给定实体是否满足某一个关系(类似分类任务,F(实体1,实体2,文本)->关系),对这种有监督的分类任务的训练方式进行细分
- 属性抽取:实体的属性可以看作是实体与属性值之间的一种关系,因此可以将大部分属性抽取的任务转换为关系抽取的任务;
一个三元组的txt文档形式如下(知识抽取这部分的目标就是构建一个txt文档,该文档中的文本形式如图所示)

- 图中这些三元组不能直接用于Neo4j数据库,还需要将其分为“实体-关系-实体”和“实体-属性-属性值”,因为这两种类型的三元组在建立Neo4j的时候使用的语句是不一样的;
- 直接从网上扒下来的三元组很可能面临上述需要三元组类型拆分的问题,而事实上若我们手动构建三元组,在构建的时候就对三元组的类型进行区分,则无需额外进行拆分;
2.2 知识融合
知识融合的目的是清洗三元组以提升数据质量
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。
知识融合主要分为:
- 实体对齐:将不同来源的知识认定为真实世界中的同一实体(如“万里长城”和“长城”是同一个实体),主要做法是根据不同实体包含的属性之间的相似度来判断是否是同一实体;
- 实体消歧:将同一名称但指代不同事物的实体区分(比如“苹果”既可能是科技公司,也可能是一种水果),主要方式是结合其上下文相关信息来判断,或者根据其特定的属性来判断(“创始人”这个属性几乎就只能指代“苹果”公司)
- 属性对齐:不同数据源对实体的属性记录可能使用不同的词语(比如对“出生日期”、“生日”这些属性实际指代的是同一种属性),一般方式是使用文本相似度来计算,或者借助属性值是否相等、相似来判断;
2.3 知识推理
知识推理的目的是挖掘或补全数据
在已有的知识库(三元组、图谱)基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。
一般方式是使用“规则+句法”,如下

当然也可以基于模型,要么是给出两个实体来推断其关系,要么是给出一个实体一个属性判断另一个实体,或者是直接给出一个三元组判断该三元组是否成立
2.4 知识表示
知识表示的目的是将数据进行向量化表示,方便后续应用
将知识图谱中的实体,关系,属性等转化为向量,进而利用向量间的计算关系,反映实体间的关联性。
3.知识抽取详解
参考链接:
前置知识点:
- 关系抽取:自然语言处理_中级 - Tintoki_blog (gintoki-jpg.github.io);
- 依存句法分析:图文并茂带你了解依存句法分析 (qq.com);
- 开放知识抽取概述:开放知识图谱构建必读:封闭域VS开放知识抽取与4大类开放抽取常用方法概述 (qq.com);
- 基于依存分析的关系抽取(论文):基于依存分析的开放式中文实体关系抽取方法 - 豆丁网 (docin.com);
工具:
DDParser依存分析:(5条消息) 百度DDParser的依存分析_Dawn_www的博客-CSDN博客;
LTP自然语言处理:HIT-SCIR/ltp: Language Technology Platform (github.com);
参考代码(有时间就全看,没时间就选部分看,基本所有基于依存分析的项目都在这里):
- 开放知识抽取项目合集:开放知识抽取实践:开放三元组抽取与文档图谱化开源工具概述 (qq.com);
- 基于LTP的依存分析抽取事实三元组:twjiang/fact_triple_extraction: 使用句法依存分析抽取事实三元组 (github.com);
- 基于LTP的自然语言处理服务器:chapzq77/LTP_Python_Interface: 根据自己搭的 LTP 服务器,实现:分词、词性标注、命名实体识别、依存句法分析、语义角色标、命名实体的抽取:人名,地名,机构名、三元组的抽取:主谓宾,动宾关系,介宾关系,(实体1,关系,实体2) (github.com);
- 数据转化为csv格式:Neo4j基本使用及导入三元组 - 简书 (jianshu.com);
- neo4j导入命令:neo4j如何批量初始化数据库?neo4j-admin导入csv数据 (newsn.net);
3.1 开放知识抽取
知识图谱的构建核心,实际上就是对三元组的构建,当我们拥有处理完成的三元组后,将其放入Neo4j图数据库就可以形成基本的可视化的知识图谱。因此本节我们详细介绍如何从非结构化的文本中提取出(实体,关系,实体)三元组。
我们的原始数据形式(即未标注的暴雨洪涝灾情文本)如下,知识抽取的任务就是从正文文本中抽取出(实体,关系,实体)形式的三元组。

一般的能够很好的建模及其应用的知识抽取都是限定知识抽取,原因也很简单,对于任何一个抽取任务(实体识别ner,实体关系抽取re以及事件抽取ee),其问题的确定性越高则其优化目标越可能被明确。
在限定领域下的实体识别ner,实体关系抽取任务re,以及事件抽取任务ee,都是在预定义schema的范畴下进行的,先定义好实体类型,实体关系/属性类型,以及事件要素,然后采用基于规则、基于模型的方法来进行训练预测。然而这个过程不够灵活,并且定义规范的schema并不是一件容易的事情。因此越来越多的场景会需要我们针对给定的随意文本,抽取出其中的知识元组,也就是开放知识抽取。
开放抽取最大的价值在于海量、起量快,在没有约束的情况下,可以快速生成大量有意义的知识,但没有约束也就成为这种方法在后期处理上较难问题的根源(如果按照限定schema进行抽取,则可以直接使用抽取得到的结果)。
开放知识抽取领域有以OpenIE为代表的多个系统,从技术发展的脉络来看,主要包括基于规则(无监督)的和基于模型(有监督)的几种方法。其中基于规则的方法可细分为基于词性模板、基于依存句法模式;基于模型的可细分为基于序列标注、基于seq2seq生成、基于span的分类。
总的来说,开放抽取的流程,可以理解为给定一个句子,从原文中抽取符合要求的spo的成分,然后再根据要求,对so进行实体标签分类,对p进行关系标准化或者聚类,从而完成规范管理,这与限定域抽取的顺序是有一定颠倒的(如果不进行后续的标准化工作,其效果将大打折扣)
本项目中我们使用的是无监督基于规则的开放知识抽取,因为对于有监督而言问题的关键还是标注数据的获取规模较小(我们手里并没有很好的气象文本标注数据)。
无监督基于规则的开放信息抽取,优点在于不需要标注数据,只需要利用语法或者句法规则识别出特定的成分,筛选出高质量的三元组。无监督基于规则的代表系统有textrunner和srandfordioe,感兴趣可自行Google查看(因不同的系统其详细处理方式不同,故不再详细展开)。
3.2 基于深度学习
这是一开始我尝试使用的方式,但后来经过尝试后发现效果并不好,因此并没有采用该方法。
基于深度学习的三元组提取是指,假设我们拥有一个已经训练好(或微调好)的领域实体-关系抽取模型,它能够完成的任务应该是输入一句话(如“据报道称,新冠肺炎患者经常会发热、咳嗽,少部分患者会胸闷、乏力,其病因包括: 1.自身免疫系统缺陷\n2.人传人”),输出如下形式的内容(即三元组(实体,关系,客体))
1 | |
一般我们都使用的是BilSTM-CRF或Bert预训练模型来进行实体识别与抽取任务以及实体关系的联合抽取,无论使用哪种模型,都需要训练数据。要求的训练数据形式要求也是三元组形式,大致如下
1 | |
简单来说,基于深度学习的三元组抽取就是基于带标注的语料库利用机器学习或深度学习的相关模型实现实体(如时间、地点、经济损失等)和关系(发生于、发生在等)的抽取。
这需要进行手动标注和划分得到训练数据(针对专业领域的知识图谱的三元组除了手动处理数据外没有更好的方法,因为网上根本就没有现成的训练数据)。我们拥有的是部分带实体标注(注意并非关系标注)的数据,主要分为位置实体、承载体实体、人口面积实体、时间实体四类实体,大致形式如下(位置实体),但是这种类型的文本对于当前我们要进行的任务来说没有什么意义。

前面说手动标注和划分训练数据不现实,那么是否可以使用现成的模型进行训练数据的提取呢?这里尝试使用斯坦福大学的OpenIe进行(实体,关系,实体)三元组的提取,其OpenIe服务器的启动命令(如果是中文的话需要额外增加配置命令并下载中文包)
1 | |
经过实测这个工具的效果不是很好(可以说相当差劲,这也证实不进行微调直接应用在专业领域的模型表现明显差强人意)。经过实测,使用其他的一些比如中文的处理工具hanlp、tlp等直接提取三元组的效果也不好,要么就是请求次数有限制,要么是结果太差完全不能使用。
3.3 基于规则
因此我们需要切换处理思路。现在的目标是要构建专业领域的知识图谱,基于深度学习需要先手动提取训练数据(三元组),对模型进行微调后得到可用于专业领域三元组提取的模型。但是因为根本没有用于训练的三元组数据,手动提取的方式也几乎不可能(一方面是数据量要求太大,人工提取完全不可能,另一方面对于这种专业领域的三元组提取也存在知识的界限),因此使用深度学习模型进行三元组的提取的方案被否决。
除了基于机器学习的方式,还有一种最基本的方法就是基于规则。注意此处所说的基于规则并不是传统的基于正则表达式或自定义的规则模式,因为对于我们手里的气象文本来说无论是使用正则表达式还是自定义的规则模式的效果都很差。这里使用的方式是先对句子进行依存句法分析(推荐借助现成工具实现),得到句子成分之间的关系之后,我们可以提取其中的如“主谓宾”或其他依赖关系作为(实体,关系,实体)三元组的成分。
3.3.1 依存句法分析
句法分析的基本任务是确定句子的句法结构或句子中词汇之间的依赖关系,句法分析一般不是语言分析任务的最终目标,但是它往往是实现最终目标的重要环节。句法分析主要分为句法结构分析和依存关系分析(也称依存句法分析)。
相比于 CFG(上下文无关文法),依存关系语法更关注与词语间关系、高度词汇化,能更好的应用于问答系统与关系抽取等场景。另外,这种语法对就这种词语的顺序要求相对比较低,所以在处理一些语法复杂、次序排列更灵活的语言时,依存关系语法比 CFG 更有优势。
依存文法分析考虑的是句子中单词与单词之间的依存关系,而这种依存关系其实就是语法,例如主谓、动宾、形容词修饰名词等。因为构建语法树的时候选择根节点是随机的,所以选择不同的根节点可能得到不同的树结构,依存句法分析的任务就是在所有可能的树结构中选择出最合适的结构,一般依存句法分析的将原来的句子使用箭头标注出关系

(图中增加了一个根节点“ROOT”,使得completed也有依赖对象)
另一种Dependency Structure的表现形式是树状结构
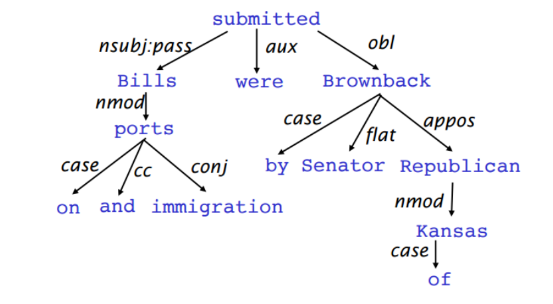
总的来说,依存句法分析旨在通过分析句子中词语之间的依存关系来确定句子的句法结构,其中依存句法分析标注关系集合(此处展示的是DDParser对应的集合,注意不同工具的集合可能不同)如下图所示
在依存句法分析中,考虑某些最有可能形成(实体,关系,实体)三元组的组成成分:
- 名词和名词短语(实体):名词和名词词组通常代表句子中的实体。它们可以是专有名词(人名、地名、组织),也可以是通用名词(物体、概念等);
- 动词和动词短语(关系):动词和动词词组通常表示实体之间的关系或动作。它们描述了实体正在做什么,或者它们是如何相互关联的;
- 至于介词和介词短语、形容词和形容词短语、副词和副词短语等作为实体或关系的修饰,可以不考虑以此降低文本分析的复杂度;
Q:成分句法分析和依存句法分析的区别是什么?
A:成分句法分析相当于考虑广义上的嵌套关系命名实体识别,依存句法分析相当于文本结构化任务中与命名实体识别配合的实体关系抽取任务。
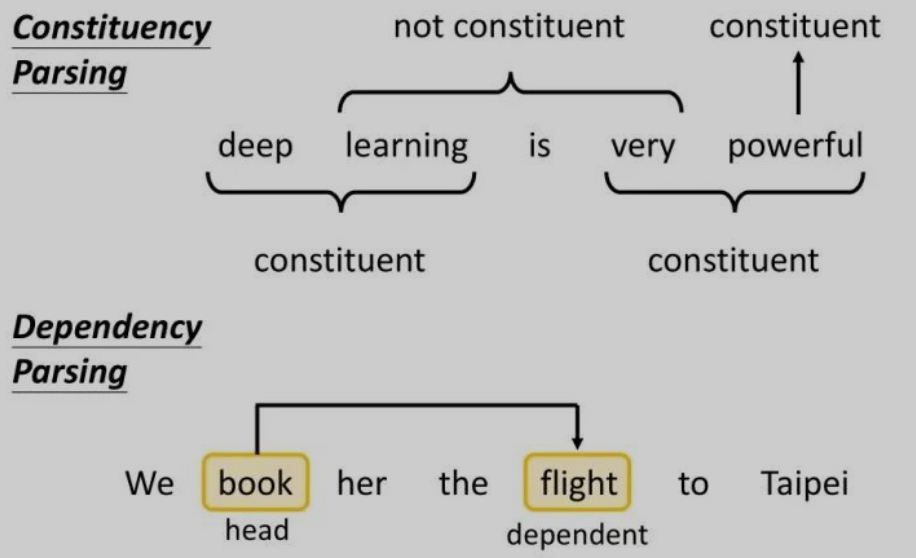
成分句法分析考虑的是,某两个相邻词汇是否能够接在一起构成成分,而依存句法分析考虑的是两个词汇之间的关系。
依存分析不考虑两个词汇是否一定相邻:
- book与flight并不直接相邻,但是flight是book的宾语,book是flight的主语,使用有向箭头来表示这种依存关系,其中箭头的起点称为head,终点称为dependent。
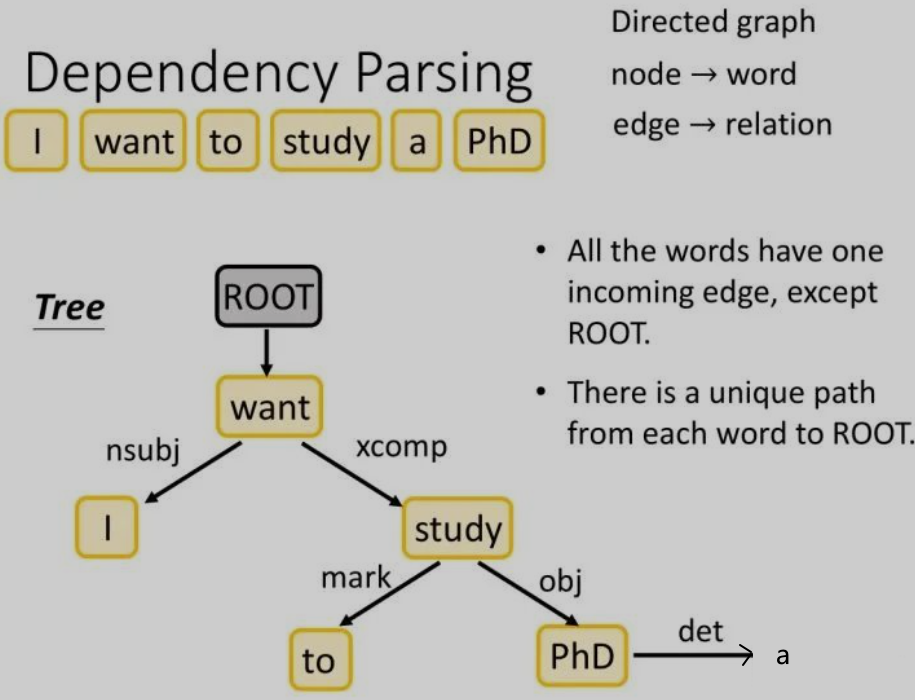
更具体的说,依存分析就是将一个句子变成一个有向图:
- 图中的每个节点是一个词汇,每条边是一种关系;
- 除了根节点(在实际的句子中该根节点不代表任何词汇),每个节点词汇只有一个入度的边,但是每个词汇都可以指向多个其他词汇;
- 依存分析得到的有向图是一个树状结构,其中的每个词汇都有唯一的一条路径回溯到根节点;
依存分析树的构建非常简单,只需要丢给第一个二分类器两个词汇和上下文,该二分类器会首先判断两个词汇之间是否存在依存关系,若存在则第二个多分类器会输出其关系的类别;
对于一个有N个word的句子,整个依存分析模型的输入是ROOT加上N个词汇组成的句子,分析的过程就是取出(N+1)^2^个单词对,逐个丢入分类器进行关系分类;
依存分析有很多方法来完成,这里因为篇幅的原因故不再赘述,感兴趣可自行Google。
3.3.2 DDParser工具
我们选择的依存句法分析工具是百度的DDParser,其Github项目地址为:https://github.com/baidu/DDParser。选择该工具的原因一方面是配置环境较简单;另一方面百度作为最大的中文搜索引擎,其对中文语料的处理会更加合理。配置好环境之后,使用DDParser来进行测试
1 | |
得到的格式化输出如下(可以看到效果还不错,第一列是ID列,ID为0可以认为是虚拟的ROOT根节点)

- DEPREL列
- FORM:当前词语或标点
- POSTAG:当前词语或标点的词性(POSTAG是细粒度词性标注,使用的是百度的LAC,参考链接:https://github.com/baidu/lac,对应的词性和专有类别标签如下表)
- HEAD:当前词语或标点的中心词id
- DEPREL:当前词语或标点与中心词的依存关系
| 标签 | 含义 | 标签 | 含义 | 标签 | 含义 | 标签 | 含义 |
|---|---|---|---|---|---|---|---|
| n | 普通名词 | f | 方位名词 | s | 处所名词 | nw | 作品名 |
| nz | 其他专名 | v | 普通动词 | vd | 动副词 | vn | 名动词 |
| a | 形容词 | ad | 副形词 | an | 名形词 | d | 副词 |
| m | 数量词 | q | 量词 | r | 代词 | p | 介词 |
| c | 连词 | u | 助词 | xc | 其他虚词 | w | 标点符号 |
| PER | 人名 | LOC | 地名 | ORG | 机构名 | TIME | 时间 |
其对应的可视化图形如下(因为长文本输出的CoNLL非常难直接看出关系,所以可视化非常有必要,在线可视化工具:http://spyysalo.github.io/conllu.js/,注意需要在输入框中输入完整的CoNLL格式文本)

通过给出的依存句法分析标注关系集合可以进行对应:
- “有”是整句话的核心;
- “教授”和“有”之间存在主谓关系,“教授”是主语,“有”是谓语;
- “有”与“哪些”之间存在动宾关系;
- “清华大学”、“研究”与“核能”之间存在定中关系,可以认为是“清华大学核能”或“研究核能”;
- “核能”与“教授”之间存在定中关系;
- “核能”的虚词成分是“的”;
从上述分析结果可以提取出如下三元组:
(清华大学,研究,核能)
(教授,研究,核能)
(教授,有,哪些)
现在回到我们要分析的气象文本来,这里拿气象文本中的一个句子做分析
“甘肃省民政厅副厅长徐亚荣说,据初步统计,“8.12”特大暴雨洪涝灾害造成8个市州的农作物受灾面积7.71万公顷,其中成灾5.99万公顷、绝收1.15万公顷,毁坏耕地0.66万公顷”
这是一个非常长的句子,直接使用LLM(大语言模型)提取三元组得到的结果并不稳定(毕竟是生成式模型)。我们先手动提取三元组,然后观察三元组中的实体-关系-实体之间有什么关系。介于研究领域的特殊性,规定实体仅限于“地点”、“承载体”、“人口面积”和“时间”;规定关系包含但不仅限于“发生于”
- (暴雨洪涝,造成,农作物受灾)
- (农作物,受灾面积,7.71万公顷)
- (市州,成灾,5.99万公顷)
- (市州,绝收,1.15万公顷)
- (市州,毁坏耕地,0.66万公顷)
当然上述三元组是根据我们主观意识来进行抽取的,似乎并不存在什么明显的规律。我们来看依存句法分析的结果
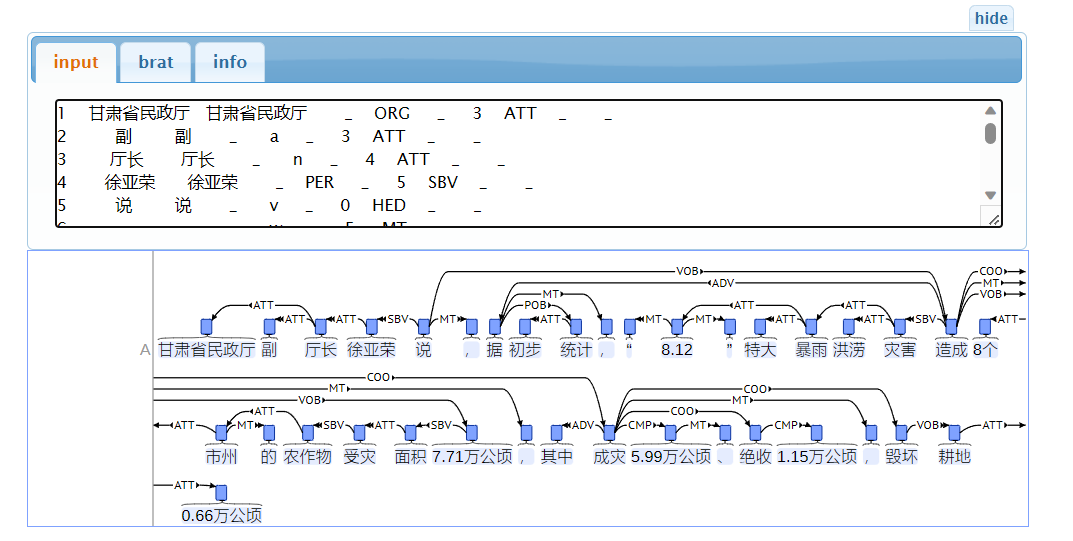
可以看到因为这个句子非常的长,这就导致生成的依存图很复杂。实际上在进行依赖分析以提取三元组之前,删除如形容词和副词等修饰词是一种常见的预处理方法,通过删除这些修饰语,可以更专注于句子中的核心实体和关系(当然删除修饰语可能会导致一些信息的丢失,需要根据具体的任务进行微调)。
二、程序设计
1.需求分析
搜索与推荐是从海量信息中提取感兴趣内容的两种技术手段:
- 相对于主动检索的方式,推荐是一种被动接收的过程,省略了用户主动检索带来的各种问题;
- 但是推荐系统中的稀疏性问题依然严重降低了推荐系统的准确度;
知识图谱因为具有强大的知识互联能力,将知识图谱应用在推荐算法中无疑可以极大的提升推荐系统的性能。
知识图谱一般根据覆盖范围和应用场景大致分为通用知识图谱和领域知识图谱:
- 通用知识图谱依赖常识知识,具有涵盖范围广、实体与实体间关系数量大的特点;
- 领域知识图谱虽然在规模上比通用知识图谱小,但在内容上专业性更强;
本次项目要求基于已有的语料库(亦或使用爬虫爬取)构建气象灾情知识图谱。在已有的数据集基础上,对数据集进行处理,通过知识抽取、知识融合等技术将三元组信息存入Neo4j图数据库中,完成知识图谱的构建,并进行可视化展示。
2.总体设计
2.1 数据预处理
整个项目使用的语料数据是老师给的未标注的暴雨洪涝灾情文本,文本的基本形式如下

文本的第二行和第三行对于提取暴雨洪涝灾情三元组没有意义,因此需要删除。因为标题和正文内容的处理方式略有不同,因此分开介绍。
处理正文内容首先要提取出正文内容,简单认为所有语料的正文内容都是从第四行开始,利用python的readlines方法和if not in判断语句可以删除前面几行。因为正文内容一般都比较长,因此还需要借助句号对内容进行分割,将得到的句子存储在目标文件中,每个文件各占一行。如下是预处理正文内容的代码
1 | |
正文内容经预处理过后得到的文本形式如下

对标题的预处理相对简单,直接提取文本首行内容即可,使用的方法和第一次作业“新闻文本分类”使用的方法相同。将提取到的新闻标题写入目标文件中
1 | |
提取到的新闻标题内容如下

2.2 三元组提取
前面简单的介绍了百度的DDParser工具对句法进行分析,下面我们将利用对句子的分析结果从中提取出三元组。
尽管前面简单的使用句号对长文本进行了分句,但实际上某些划分后的文本长度仍然较长,原因是文本的句子划分并不只是靠句号,其他诸如问号、换行符等都可以作为划分句子的标准,因此需要进一步的进行划分,这里使用正则表达式来实现
1 | |
该方法接受一个名为content的参数,该参数是一个字符串,表示待处理的文本内容。该方法的目的是将字符串进行拆分,将其作为列表返回。
re.split()方法:按照能够匹配的子串将字符串分割后返回列表 – 此模式表示一个字符集,该字符集包括各种标点符号和换行字符,这些标点符号和字符通常用于中文和英文的句子结尾,当函数遇到这些字符时进行拆分
通过列表推导式,迭代从上一步获得的列表中的每个元素句子,将列表中的空字符串去除,确保最后的结果只包含非空语句
最后返回一个语句列表,其中包含了所有的句子
总的来说,该方法根据常见的标点符号和换行符将给定的文本内容拆分为单独的句子,删除了空字符串,最后返回结果列表。
下面的build_parse_child_dict()方法执行句法分析,主要输入参数如下:
words:单词列表
postags:词性标签
rel_id:依存关系id
relation:依存关系
该方法处理所提供的单词、词性和依赖性信息,以生成两个列表:child_dict_list和format_parse_list,前者以字典的形式表示每个单词的子依赖性,后者为每个单词提供格式化信息。
1 | |
我们举一个例子来理解,假设函数的输入如下
1 | |
函数首先会初始化两个空列表,child_dict_list和format_parse_list。
接着在第一个循环中使用索引变量对单词列表的索引进行迭代,在每个循环中都会为每个单词创建一个新的空字典child_dict。
第二个循环使用arc_index变量对rel_id列表的索引进行迭代。它检查arc_index处的rel_id值是否等于index+1(因为rel_id索引从1开始)。如果它们匹配,则意味着依赖关系对应于索引处的当前单词。然后进行判断,如果rel_id值已经作为child_dict中的键存在,则arc_index将被附加到相应的索引列表中。否则,将创建一个新键,并将其值初始化为包含arc_index的空列表。此步骤为每个单词建立子依赖关系。在我们的例子中,child_dict_list将会是如下形式
1 | |
索引0处的字典为空,因为单词“I”没有依赖项。
索引1处的字典(对应于“ate”)有一个依赖项,关系“nsubj”指向索引0处的单词(“I”)。
索引2处的字典(对应于“an”)有一个依赖项,关系“det”指向索引2处(“an”)的单词。
索引3处的字典(对应于“apple”)有一个依赖项,关系“obj”指向索引3处(“apple”)的单词。
接下来构建一个heads列表,该列表将每个依赖关系id与其对应的单词进行匹配,例子中的heads将是[“ate”、“Root”、“apple”、“ate”]。
接着进入下一个for循环,该循环会对每个单词创建一个格式化的表示,这将结合各种信息,我们的例子中得到的format_parse_list将是
1 | |
每个子列表表示一个单词的格式化信息。比如第一个子列表对应具有“nsubj”关系的单词“I”,它的索引为0,词性标签为“PRON”,它的head word是“ate”,head word的词性为“VERB”。
build_parse_child_dict()方法只是一个辅助方法,主要用于辅助构造解析树,而build_parse_child_dict()方法的参数需要使用DDParser对句子进行依存分析得到
1 | |
merge_ATT方法,该方法对解析树中的依存关系进行了合并操作。它识别出连续的 ‘ATT’ 或 ‘ADV’ 依存关系,并将相应的词合并为一个单词。合并后的词被添加到 ATTs 列表中,并且每个合并序列中最后一个词的索引被添加到 retain_nodes 集合中。该方法最终返回输入的 words 列表的修改版本、原始的 postags 列表、修改后的 format_parse_list 列表以及 retain_nodes 集合。
1 | |
到这里可能我们会有一个疑问,为什么需要合并如“ATT”(定语修饰语)和“ADV”(状语修饰语)呢?实际上是为了将多个词汇合并为一个单词,从而更加有效的捕捉它们之间的关系。这里我们可以举个例子,原始句子为“The big red apple on the table is delicious.”,则“big”、“red”和“on the table”作为ATT修饰“apple”,解析树将为每个修饰语建立单独的依存关系,很明显这是一个碎片化的表示,如果将这三个成分合并为一个成分,即“big red on the table”,作为“apple”的ATT修饰,在保留基本信息的同时简化了结构,提高了解析树的可读性。
接下来的extract方法根据词性标注(postags)、依存解析(child_dict_list)和其他语言信息从给定的句子中提取语义三元组(主语-动词-宾语关系)。该方法旨在通过利用词性标注和依存解析信息从句子中提取主谓宾和主谓补关系,提取的三元组提供了关于句子的语义结构和关系的见解。
1 | |
extract方法侧重使用特定的句法模式(主语-动词-宾语和主语-动词-补语)来提取三元组,我们这里介绍一种同样是基于词性标注和依存解析等语言信息提取语义三元组的方法ruler2。ruler2方法可以看作是extract方法的拓展,通过考虑其他模式(如带有形容词修饰的主语-动词宾语)来拓展提取定语后置和介词短语的主动补语(即介宾关系的主谓动补关系),它结合了额外的模式来捕捉句子中更加广泛的语义关系。ruler2的大部分逻辑和extract是相同的,代码注释如下
1 | |
在ruler2方法中,使用到的一个重要的方法是complete_e,该方法根据句子中的词语信息、词性标注和依存解析结果,生成一个完整的实体词语,代码的注释如下
1 | |
这里简单举一个例子来理解complete_e方法的工作原理,假设有这样一个句子”John eats an apple.”,输入complete_e的参数分别为:
- words: [“John”, “eats”, “an”, “apple”]
- postags: [“NNP”, “VBZ”, “DT”, “NN”]([“专有名词”, “动词原形”, “限定词”, “名词”])
- child_dict_list: [{}, {}, {}, {}](在此示例中为空)
- word_index: 1(”eats”的索引)
从单词”eats”开始调用complete_e方法,由于”eats”没有”ATT”(定语)关系,因此prefix的循环不执行。接着由于”eats”是一个动词,因此需要检查child_dict中是否存在”VOB”(动宾关系)关系。在这个例子中”eats”不存在”VOB”关系,因此postfix为空字符串。同样的,”eats”不存在”SVB”(主谓)关系,因此prefix也是空字符串。最后,该方法返回prefix、words[word_index]和postfix的拼接。在这个例子中,它返回”eats”。这表明在调用complete_e方法处理句子”John eats an apple.”中的单词”eats”时,因为”eats”没有额外的修饰词或依赖关系,因此简单的返回”eats”作为完整实体。
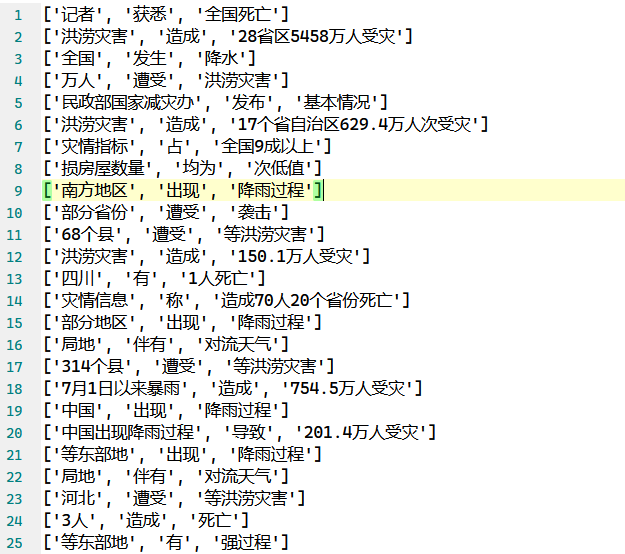
以上就是基于依存分析提取文本中的三元组主要使用的函数,当实例化SVOParser类后,调用triples_main方法对正文文本和标题文本的每一行进行三元组提取,将得到的三元组进行合并(代码比较简单这里就不再展示,详情参见代码文件),最终形成如下形式的原始三元组文件
2.3 三元组清理
参考链接:
近义词工具包:chatopera/Synonyms;
训练并使用自己的Word2Vec:
基本的三元组已经提取完成,但是可以看到存在很多相似的三元组以及一些无用的三元组(比如实体是标点符号)。因此这部分我们主要进行的就是对三元组进行清洗,得到质量较高、可用于构建知识图谱的三元组。
经过对原始三元组的查看,基本确定要清洗的三元组类型如下:
两个完全相同的三元组 [‘东北局部地区’, ‘遭受’, ‘洪涝灾害’] 和 [‘东北局部地区’, ‘遭受’, ‘洪涝灾害’] – 去重
头实体或尾实体是单个字符(包括标点符号)的三元组,如[‘已’, ‘致’, ‘85人死亡’]、[‘,’, ‘致’, ‘85人死亡’]、[‘18人’, ‘死’, ‘4’] – 在中文中要表示一个实体几乎是不可能只用一个字的
头实体或尾实体以“等”开头(这是我们文本的特殊性导致的一个问题),这种三元组不用删除,只需要删除头实体的“等”即可,如[‘等湘省份’, ‘遭受’, ‘洪涝灾害’] – 规范化
头实体或尾实体是以数字开头的(同样是文本特殊性导致),如[‘1.6亿’, ‘投入’, ‘5万人’],这种三元组不具备语义 – 语义角度,灾情文本中两个数字实体之间几乎不会有什么有用的关系(头实体和尾实体都是数字开头),亦或头实体或尾实体以数字开头,往往并不是我们需要的“唯一”实体
头实体或尾实体以“你”、“我”、“他”人称代词开头,不符合作为唯一实体的要求
头实体等于尾实体,自己与自己存在关系,从常理上讲行不通
头实体或尾实体意义接近,可以认为是两个相同的三元组如 [‘两部门’, ‘启动’, ‘四级应急响应’] 和[‘两部门’, ‘启动’, ‘Ⅳ级应急响应’] – 可以用jaccard距离或余弦相似度来判断
2.3.1 重复三元组
首先删除重复的三元组,这里借助了集合元素唯一的特性,很方便的得到了去重之后的三元组
1 | |
2.3.2 非法三元组
接下来删除其他不符合条件的三元组(这里不包括实体相似的三元组,这将放在之后处理),这里使用的逻辑也非常简单,直接利用if语句进行判断即可。
需要注意的是因为我们的三元组尽管看起来像列表,实际上是以字符串的形式在文本中存储的,因此借助ast.literal_eval()函数将字符串转换为列表,进而可以访问三元组中的实体或者关系。
1 | |
2.3.3 实体&关系限定
额外的,还需要限定关系的类型数量以及实体的类型数量。一开始想要基于语料库中已有的实体标签和三元组中存在的实体的交集作为实体,这种效果不会很好,原因是语料中的实体如“人”、“房屋”、“农作物”,这还仅仅只是承载体,如果要算上人口面积(诸如“死亡失踪101人/ADP”,“转移安置18.9万人次/ATP”)、时间标签(如“7月份/DS”,“7月21日/DO”)等,因为本身的标注实体的效果就不好,如果再和我们使用依存分析得到的结果进行一个“负负得正”的操作,最后得到的效果会很差。同时,也不能为了减少实体就刻意的去直接删除某些实体,这是不负责任的表现,比如“江西省”和“江西减灾委”就是两个实体,不能将其作为同一个实体。对于关系也是如此,如果仅仅只想限制关系的数量仅限于“发生在”、“有”这种,不仅不现实,而且会极大的减少三元组的数量。不能从集合的角度来处理实体和关系的话,可以从词嵌入即更高层次的技术来处理。
因为实体和关系现在都可以看作是单独的中文词语,因此处理词语特别是同义词、近义词,比如“出现”、“出现在”、“出现于”这三种关系实际上都是同一种关系,将其融合以减少关系的数量 – 可以使用一种被称为同义词规范化的技术,选择使用最短的同义词或使用频率最频繁的同义词甚至随机的同义词作为规范形式。
注意因为这里需要使用到词嵌入,与后面直接使用TF-IDF向量计算余弦相似度做区分。后面的处理过程没有使用词嵌入是因为这两个步骤处理的视角不同。此处需要考虑为词嵌入是因为考虑到语义方面的不同(这需要深层次的对语言的理解,词嵌入是一个不错的选择);而删除相似三元组是仅仅只需要将汉字看作是普通的集合中的元素,只需要比对集合中元素的个数即可。
现在的任务是寻找并清理中文近义词、同义词,要么使用现成的库(可能在专业邻域的效果不是特别好),要么自己训练word2vec(利用专业邻域文本),此处我们选择借助gensim库和手中已有的语料先训练一个专业领域的word2vec模型。具体代码文件参考word2vec.ipynb。主要步骤分为:
- 创建语料文件:将text_data.txt和title_data.txt合并成一个文件,命名为data.txt;
- 格式转换:将txt文件转化为csv文件便于之后的语料预处理;
- 语料预处理:去除无用字符、分词、过滤通用词;
- 词向量训练:借助gensim.models.word2vec中的LineSentence训练属于自己的词向量,训练完毕后将词向量和模型保存;
训练好的词向量模型可以用于词语的相似性计算,比如我们想要计算“暴雨”和“洪涝”这两个词之间的相似性,可以使用以下代码
1 | |
返回的similarity_score是0.8775766,可以看到效果还是很好的。需要注意进行比较的两个词必须在语料中出现过,否则函数会返回错误。
这里我们不直接使用这个训练好的词向量进行相似性的计算,我们将二进制的模型打包成gz格式的文件,替换掉synonyms库(这是github上的一个中文近义词开源项目)中原本的通用词向量文件。使用synonyms库的好处在于可以处理没有出现在语料库中的词语。

接下来使用synonyms库提供的compare方法同样可以计算两个词语之间的相似性
1 | |
接下来定义替换相似词语的函数,其基本的思想非常简单,就是设置一个相似性门限和unique_words列表。输入的word单词与unique_words列表中的每一个单词进行相似性的计算,如果计算出的相似度similarity大于max_similarity,则记录该similarity以及对应的unique_word。当比较完unique_words列表中的所有单词后,如果最终的max_similarity大于设置的门限,则表示输入的word在unique_words列表中有相似的词语,该词语就是max_similarity对应的unique_word;如果最终的max_similarity小于门限,则表示输入的word在unique_words列表中没有相似的词语,因此该word作为unique_words的新元素被加入。
1 | |
有了替换相似性单词的函数,接下来只需要分别遍历txt文件,提取第一列、第二列、第三列的词语,分别进行replace_similar_words操作,然后再将每一列对应的每一行的词语拼接即可。执行完毕后得到synonyms_triples_data.txt文件。
2.3.4 相似三元组
最后是删除相似三元组的操作,这里既可以使用经典的余弦相似度,也可以使用易于理解的jaccard算法。经过测试,余弦相似度的效果更好,因此这里选择使用余弦相似度进行相似文本的清理。
1 | |
因为上述代码的基本思想是将每个三元组于现有的唯一的三元组进行比较,因此该部分代码在三元组数量较大的时候(实测当三元组数量为3000时需要花费1.5h)将耗费大量时间运行。因此当需要处理的三元组数量较大时可以事先进行切分,比如1000个三元组一组执行上述代码。
经过清洗的三元组如下,可以看到相较于清洗之前的三元组来说,清洗之后的三元组质量更高。

2.4 三元组转化&知识图谱
拥有了用于构建知识图谱的三元组之后,接下来构建知识图谱的流程就相对简单,主要流程如下:
1.识别唯一实体:因为我们的三元组已经是主谓宾的结构,因此可以直接从三元组的主语和宾语位置提取所有唯一的实体,这些实体将成为知识图中的节点
2.创建节点:在知识图谱中为每个识别出的唯一实体创建一个节点,为每个节点分配一个唯一的标识符或标签
3.创建关系:将三元组中的谓词映射到知识图谱中的关系上 – 对于每个三元组,根据谓词在相应的主语和宾语节点之间创建一个关系
(注意,知识图谱与其他数据结构不同的地方就在于两个实体之间是可以存在多种不同的关系的,而传统的图或关系数据库模型中,实体之间的关系通常局限于一种类型)
这里我们使用的数据库是图数据库neo4j,如果要手动一个个导入三元组是不现实的,因此我们借助neo4j提供的admin-import工具导入。但是admin-import工具只能导入csv格式的文件,因此在导入之前还需要对三元组格式进行转化,将txt文本格式的三元组转化为csv格式。以下是转化代码
1 | |
上述程序运行后将会得到entity.csv文件和roles.csv文件,这两个csv文件实际上就是neo4j的三元组数据的另一种组成形式,通过组合这两个文件来组成初始化图数据库的数据。
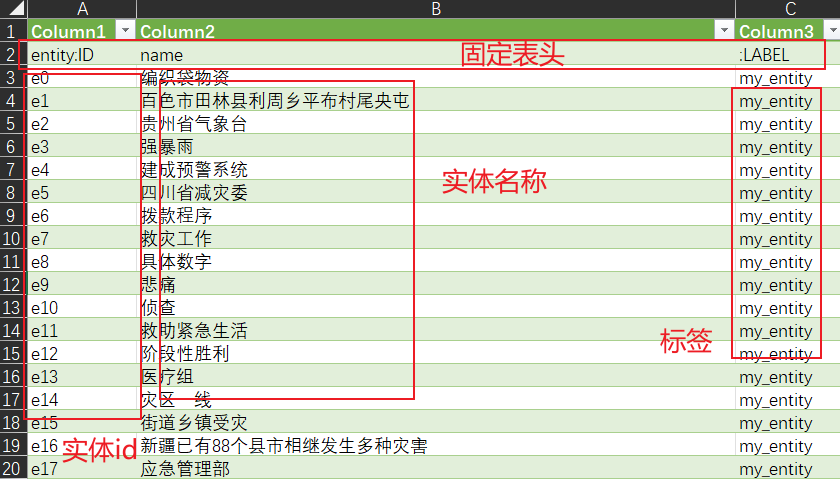
entity.csv是实体文件,这个文件记录了实体的名称以及编号和标签数据。需要注意文件的表头需要固定
- entity:ID:实体id编号,自己生成的不重复数据编号;
- name:实体名称;
- :LABEL:标签,若存在多个标签则使用英文分号’;’分割;
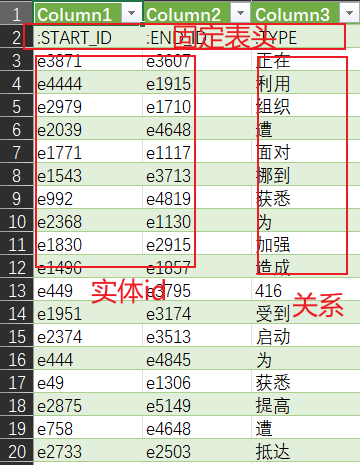
roles.csv文件是关系描述文件,其必须包含的表头如下
- :START_ID:对应于entity.csv中的entity:ID;
- :TYPE:关系文字;
- :END_ID:对应于entity.csv中的entity:ID;
拥有上述两个csv文件后,在批量导入之前先将data目录下的databases和transactions中有关neo4j和system的文件夹全部删除(否则会报错数据库已存在,注意不要误删别的文件!),还需要注意的是桌面版的neo4j不能批量导入(至少我没找到办法),因此推荐使用社区版的neo4j。neo4j批量导入csv文件命令如下(该命令意思是将csv文件的内容全部导入到neo4j数据库中),需要在neo4j-admin文件所在的位置(在我的电脑是’D:\Download_software\My_Neo4j_zh\neo4j-chs-community-5.7.0-windows\bin’)下在终端使用如下命令(注意将yourpath替换为自己的路径)
1 | |
我的电脑中的nodes和relationships中的路径均为’D:/My_code/Pycharm/大三下文档/KGTriples/data’,因此完整的命令为
1 | |
出现如下输出表示导入成功
导入完毕后,在相同目录下使用命令启动neo4j服务
1 | |
出现如下形式的输出表示服务启动成功,此时在浏览器网址栏输入http://localhost:7474/即可进入neo4j内置的可视化界面(首次登录应该需要账号和密码,默认都是neo4j,修改密码后请记住密码,忘记密码可能需要删除整个数据库)

Neo4j Browser提供了一个专用的图形可视化界面,使用户可以以图形形式查看节点、关系和属性。它支持各种功能,如缩放、平移、扩展和折叠节点,以及直接在界面中运行Cypher查询。Neo4j Browser中的可视化是基于存储在Neo4j中的图形数据自动生成的,使其成为探索和分析知识图的方便工具,而不需要额外的转换。相较于并不是专为知识图可视化进行设计的ECharts和Django,Neo4j Browser在使用Neo4j作为底层数据库时是知识图可视化的一个更精简的选项。
这里我们展示部分以“洪涝灾害”为中心的知识图(整个图太大了展示不完)

可以看到以洪涝灾害为中心,与其他的实体之间以不同的关系进行联系。除了上述以某个实体作为中心进行展示以外,也可以以关系网的形式进行展示
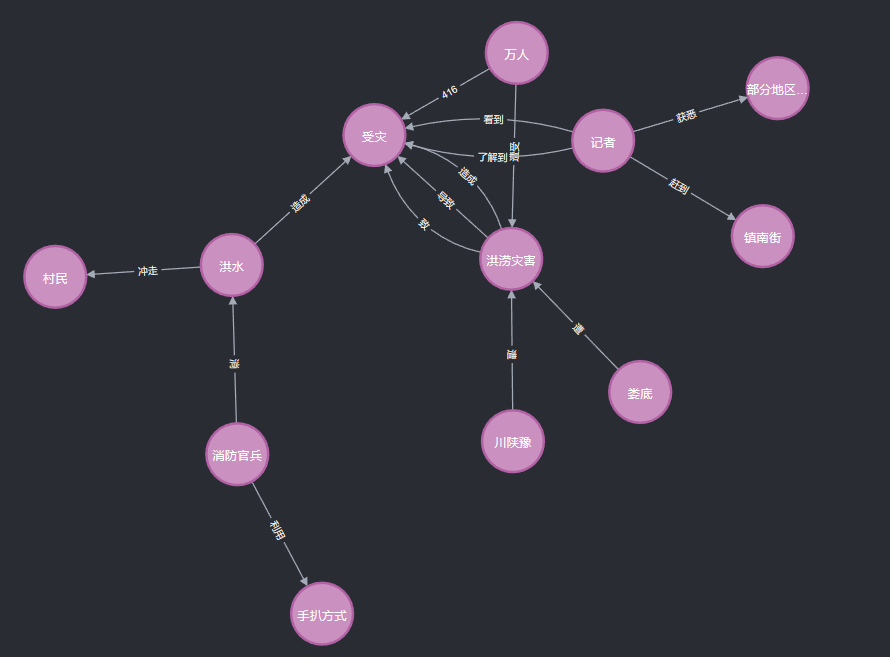
通过关系网,可以进行诸如“娄底遭洪涝灾害,导致受灾”这样简单的知识推理过程。最后我们使用一个gif来简单展示一下neo4j图数据库的魅力

三、实验总结
本次作业的基本要求是构建面向暴雨洪涝灾情的知识图谱。一开始拿到老师给的语料的时候我是不知道应该如何处理的,经过大致的了解后,我确定了基本的工作流程,最重要也是最基础的一个步骤就是获取到三元组。然而获取三元组的过程并不容易,一开始我花费大量时间,尝试使用机器学习模型进行三元组的自动提取。但是使用通用的机器学习模型在中文语料上的效果非常差劲,因此考虑是否可以针对专业领域对模型进行微调,进而使用微调过后的模型进行三元组的自动提取。然而当我兴致勃勃的将预训练模型下载并准备微调的时候才发现我压根就没有能够用于训练的三元组,这非常类似于“鸡生蛋,蛋生鸡”的问题。因此在一段时间内我陷入了迷茫,当我思考是否真的只能使用手动提取这种最原始的方式的时候,我的脑海里突然迸发出自然语言处理领域研究方法的发展过程:基于规则->基于统计->基于机器学习,既然基于机器学习不行,那么是否可以使用类似基于正则表达式匹配的方式?后来经过实验发现正则表达式的表达能力相对较弱,在后续查询资料的过程中我发现了将依存分析和三元组提取结合的方法,这无疑是为我确定了崭新的方向。因此在这之后我依次使用了现有的多种自然语言处理工具如LTP、DDParser、OpenIE等,并最终确定使用百度的DDParser工具。对句子进行依存分析后,不能简单的提取“主谓宾”作为三元组,还需要考虑其他因素,通过阅读大佬的论文和方法使我明白了基于依存分析提取三元组并不比训练模型轻松,当然最后凭借不懈的努力我成功的完成了三元组提取、三元组清洗以及知识图谱构建等全部流程。这也启发我在之后的学习过程中遇到困难应当多方位思考,从不同的角度寻找解决问题的方法。