中级项目_目标检测系统
参考链接:
- 论文:《Robust Real-Time Face Detection》
- 目标检测概述:(5条消息) 目标检测(Object Detection)_图像算法AI的博客-CSDN博客;
- 目标检测算法汇总:本仓库不再维护,最新内容前往:https://github.com/zjykzj;
YOLOv5系列YOLOv5目标检测展示:番外. 电脑是如何学会瞬间识别物体的 图像识别专家Joseph Redmon为你解读研发之路_哔哩哔哩_bilibili;
YOLOv5网络模型详解:
YOLOv5目标检测:
R-CNN系列- R-CNN算法复现代码:object-detection-algorithm/R-CNN: 目标检测 - R-CNN算法实现 (github.com);
- 项目文档:R-CNN;
- 项目视频讲解:RCNN全系列详解及代码实现_哔哩哔哩_bilibili;
- R-CNN代码解读:
- Make Sense标注工具:(9条消息) make-sense | 图像标注工具_YawQinse的博客-CSDN博客;
- 数据集的制作:自制数据集及训练_哔哩哔哩_bilibili;
2023/4/22 9:50 课设题目选择的是目标检测系统,基本的步骤就是先按照肆十二的几个YOLO检测算法全部过一遍,然后把论文看了(可以同步看),最后把核心代码以及可视化界面修改一下即可;
2023/4/25 10:31 简单过了一下肆十二的视频前半部分,也下载了源码,进行了相关的环境配置,现在的问题就是数据集的收集,直接使用COCO肯定是不行的过于庞大,所以先暂时下载了一些较小的数据集;
2023/4/25 21:10 基本上了解了目标检测的相关知识,关于选择的网络模型(YOLOv5)确实需要看视频好好理解(这玩意不能直接调库,需要手动实现),纯看文本的话的确会出现看不懂的情况(关于YOLOv5的详细信息等到时候确定了选择什么样的网络模型后再深入研究)。另外数据集的话已经下载在E盘中,是关于Traffic检测的数据集,可以选择适当的时间测试是否可行;
2023/5/8 11:37 距离上次接触这个项目已经很长一段时间了,为了方便回顾,这里我先做一下进度总结。前面所作的工作一句话总结 – “啥也没做”,这也透露出一个优质的工作日志是多么的重要,不过没关系,那我们就当这个项目是一个全新项目来开始做。首先是代码和数据库以及环境都准备完毕,只需要放在Kaggle上先跑一遍验证代码可行性(在此之前先看视频把整个代码结构理顺,博主这个代码结构看的我头疼)。然后因为使用的是预训练模型,所以下面一个重要的工作就是自己写代码训练出一个预训练模型出来(或者说直接拿traffic来训练一个直接的模型?)。可视化界面小小的修改一下就行,毕竟前面学过的pyqt也能用上;
2023/5/8 16:14 肆十二的代码过于扯淡(完全就没什么理解意义,只是为了好看交差),而且直接使用的是预训练模型进行微调,这与老师让我们自己实现检测算法背道而驰,另外一点,Kaggle跑不起来那个代码(应该是YOLOv5的版本问题)。所以现在需要重新寻找合适的参考资料进行参考,宁愿多花时间考察也不要拿到代码就开干;
2023/5/8 16:55 YOLOv5是一个开源的代码,所以直接实现YOLOv5代码不是一个明智的选择,因此可以根据原始的YOLOv5写一个阉割版的检测算法。或者是不使用YOLOv5用其他算法(好处就是不需要自己重写YOLOv5)…现在要找一个项目真的麻烦(不过在这个过程中学到了很多其他的知识点也挺好)…
2023/5/9 0:19 现在已经找到新的参考代码了,然后开始从数据集入手根据教程慢慢将模型训练出来,训练完毕后对代码进行理解即可。这个教程比较粗糙可能需要在过程中参考其他资料,同时配套代码可能有些错误的地方,需要小小的修改即可运行(现在已经处理到“创建微调数据集”);
2023/5/10 20:28 经过长久的租借云GPU等操作,终于在此时此刻完成了对代码功能的检验上面,接下来的工作就是对代码进行结构的梳理和理解;
2023/5/11 20:29 参考文章做的是一个汽车的检测器,这里我们来实现一个cat的检测器,首先就需要获取新的数据集,因此对数据集的获取代码需要重新编写;
2023/5/11 22:16 现在已经把新的代码文件写好了,主要是预测cat(本质上就是换了数据集),接下来就只需要理解代码并编写代码的注释即可(顺便可以看作者推荐的论文和参考,但是论文全英文的是真的难以理解,还是先找视频入门)。经过询问gpt,它告知我可以既检测图像中的车辆也可以检测图像中的猫(大概思路就是先使用第一个模型检测车辆,之后用该模型在cat数据集上进行训练后即可检测猫咪)
2023/5/13 15:52 功夫不负有心人,本来今天早晨以为这个项目要黄了(因为我做的是图像目标检测而实际上需要我们做的是视频目标检测),但是经过gpt的配合成功的将用于图像检测的R-CNN应用到了视频中,因此可以继续该项目。现在还剩下的工作就是可视化界面的设计和代码重构,完成这两部分之后就可以直接写最后的设计文档;
2023/5/14 17:02 今天已经把代码重构完毕,整个项目也能够跑起来了(除了某些瑕疵比如检测框大小、检测分数为1等),剩下的工作就是写设计文档分析项目、以及进行源码注释即可;
2023/5/27 16:19 今天已经把那些小问题处理完毕,检测其余视频并没有尝试过,但是至少现在这个作业能交,可能泛化能力不是特别强,接下来把最后的设计文档好好完成就行,代码部分不用再修改;
一、背景介绍
Q:目标检测和目标跟踪的区别?
A:回答链接https://cloud.tencent.com/developer/news/40338
- 目标检测是指在图像或视频(一系列的图像)中扫描和搜索目标,即在一个场景中对目标进行定位和识别;
- 目标跟踪是实时锁定一个/一些特定的移动目标,跟踪是一系列的检测;
1.基本概念
计算机视觉中关于图像识别有四大任务:
(1)分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标;
(2)定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置;
(3)检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么;
(4)分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题;
详细来说,目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。可以认为目标检测是分类和回归问题的叠加。
目标检测的核心问题主要有以下几个:
(1)分类问题:即图片(或某个区域)中的图像属于哪个类别。
(2)定位问题:目标可能出现在图像的任何位置。
(3)大小问题:目标有各种不同的大小。
(4)形状问题:目标可能有各种不同的形状。
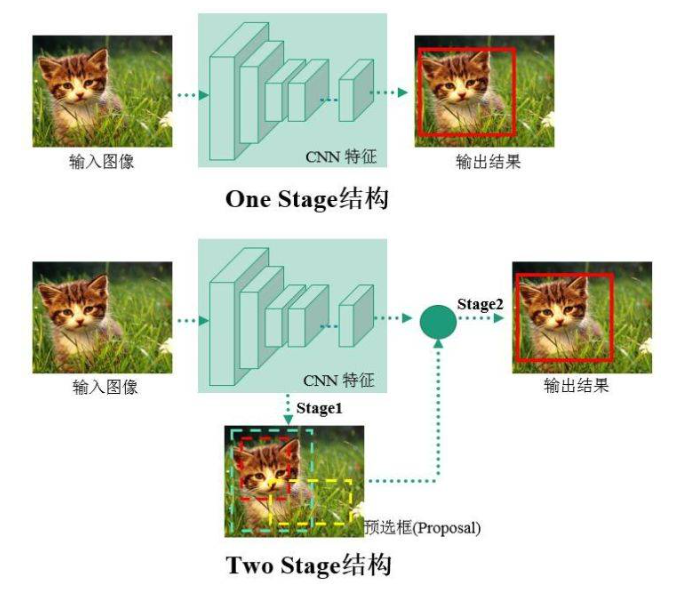
基于深度学习的目标检测算法主要分为Two stage和One stage:
- Two stage的检测流程为先首先进行区域生成,该区域称之为region proposal(简称RP,一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。常见tow stage目标检测算法有:R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN等;
- One stage的检测流程中不需要RP,直接在网络中提取特征来预测物体分类和位置。常见的one stage目标检测算法有:OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet等;
目标检测的主要应用有:人脸检测、行人检测、车辆检测和遥感监测。
2.算法原理
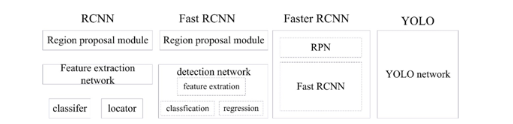
目标检测分为两大系列 – R-CNN系列和YOLO系列,RCNN系列是基于区域检测的代表性算法,YOLO系列是基于区域提取的代表性算法,著名的SSD是基于前两个算法的改进。
2.1 R-CNN系列
2.1.1 R-CNN
R-CNN(全称Regions with CNN features) ,是R-CNN系列的第一代算法,并没有过多的使用“深度学习”思想,而是将“深度学习”和传统的“计算机视觉”的知识相结合。比如R-CNN pipeline中的第二步和第四步就属于传统的“计算机视觉”技术,分别使用选择搜索selective search提取region proposals,使用SVM实现分类。
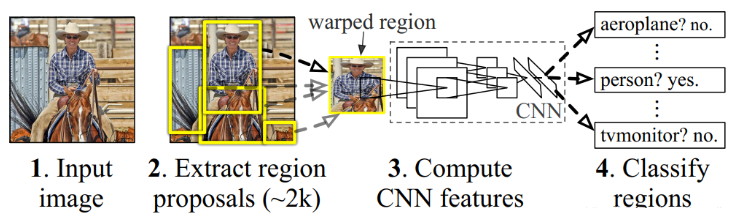
训练R-CNN模型的基本流程如下:
- 预训练模型:选择一个预训练(pre-trained)的神经网络(如AlexNet、VGG);
- 重新训练全连接层:使用需要检测的目标重新训练(re-train)最后的全连接层(connected layer);
- 提取 proposals 并计算CNN 特征:利用选择性搜索(Selective Search)算法提取所有proposals(大约2000幅images),调整(resize/warp)为固定大小,以满足CNN输入要求(因为全连接层的限制),然后将feature map 保存到本地磁盘;
- 训练SVM:利用feature map 训练SVM来对目标和背景进行分类(每个类对应一个二进制SVM);
- 边界框回归(Bounding boxes Regression):训练将输出一些校正因子的线性回归分类器;
R-CNN的缺点很明显:
- 每个region proposal都需要经过一个AlexNet特征提取,而这些region proposal可能出现大量重复的区域,产生大量重复的计算;
- R-CNN的训练过程不是连续的,三个模块(提取、分类、回归)是分别训练的,并且在训练时候,对于存储空间消耗较大;
2.1.2 Fast R-CNN
Fast R-CNN是基于R-CNN和SPPnets进行的改进。SPPnets的创新点在于只进行一次图像特征提取(而不是每个候选区域计算一次),然后根据算法,将候选区域特征图映射到整张图片特征图中。
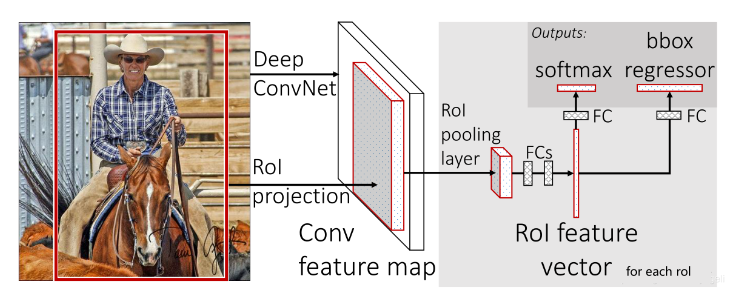
SPPnets的基本流程如下:
- 使用selective search生成region proposal,大约2000个左右区域候选框;
- (joint training)缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔;
- (joint training)对于每个scale的每个ROI,求取映射关系,在conv5中剪裁出对应的patch。并用一个单层的SSP layer来统一到一样的尺度(对于AlexNet是6*6);
- (joint training) 继续经过两个全连接得到特征,这特征又分别共享到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个平滑的L1-loss;
- 测试时需要加上NMS处理:利用窗口得分分别对每一类物体进行非极大值抑制提出重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口;
2.1.3 Faster R-CNN
Faster R-CNN在结构上将特征抽取、region proposal提取, bbox regression,分类都整合到了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
其中的Region Proposal Network(RPN)取代了selective search生成待检测区域,一定程度上减少了训练时间,真正实现了一个完全的End-To-End的CNN目标检测模型。
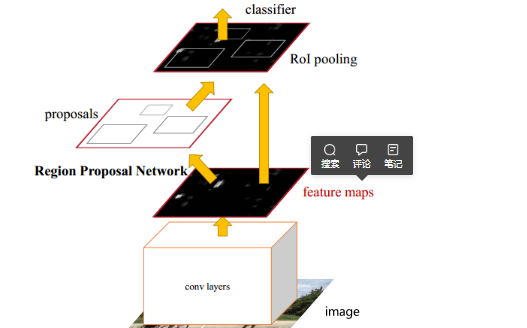
Faster R-CNN的网络结构和对应基本流程如下:
- Conv Layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的卷积/激活/池化层提取图像的特征,形成一个特征图,用于后续的RPN层和全连接层;
- Region Proposal Networks(RPN)。RPN网络用于生成候选区域,该层通过softmax判断锚点(anchors)属于前景还是背景,在利用bounding box regression(包围边框回归)获得精确的候选区域;
- RoI(Region of Interest) Pooling。该层收集输入的特征图和候选区域,综合这些信息提取候选区特征图(proposal feature maps),送入后续全连接层判定目标的类别;
- Classification。利用取候选区特征图计算所属类别,并再次使用边框回归算法获得边框最终的精确位置;
尽管Faster R-CNN的效果已经提升很大,但是因为需要获取region proposal,再对每个proposal分类这个过程需要大量时间,因此Faster R-CNN还是无法很好的实现实时检测。
Q:R-CNN系列究竟有什么不同?
A:R-CNN是物体检测领域的早期方法,而Fast R-CNN和Faster R-CNN分别引入了RoI池化层和RPN来提高速度和准确性。Faster R-CNN是这三者中性能最好的算法,通常被认为是物体检测的基准方法之一
- R-CNN(Region-CNN):
- R-CNN是一种早期的物体检测方法,首先将图像中的候选区域(RoI)提取出来,然后对每个RoI进行单独的卷积神经网络(CNN)处理,以提取特征。
- 这个方法存在明显的缺点,即处理速度非常慢,因为每个RoI都需要单独的CNN前向传播,计算非常耗时。
- Fast R-CNN:
- Fast R-CNN是对R-CNN的改进,它引入了RoI池化层,将所有RoI的特征提取过程合并成一个前向传播,从而显著加速了处理速度。
- Fast R-CNN还使用了共享的特征提取层,而不是为每个RoI单独构建CNN,进一步提高了效率。
- Faster R-CNN:
- Faster R-CNN是对Fast R-CNN的进一步改进,它引入了一个称为”区域提案网络”(Region Proposal Network,RPN)的组件,用于生成RoI。这意味着不再需要手动选择或提取RoI,RPN可以自动提出候选区域。
- Faster R-CNN将RPN与Fast R-CNN的特征提取网络一起使用,形成一个端到端的物体检测架构。这使得物体检测更加高效和精确。
2.2 YOLO系列
2.2.1 YOLOv1
YOLO(You Only Look Once )是继R-CNN系列之后,针对DL目标检测速度问题提出的另一种框架,其核心思想是生成RoI+目标检测两阶段(two-stage)算法用一套网络的一阶段(one-stage)算法替代,直接在输出层回归bounding box的位置和所属类别。
R-CNN系列的物体检测方法需要产生大量可能包含待检测物体的先验框, 然后用分类器判断每个先验框对应的边界框里是否包含待检测物体,以及物体所属类别的概率或者置信度,同时需要后处理修正边界框,最后基于一些准则过滤掉置信度不高和重叠度较高的边界框,进而得到检测结果。这种基于先产生候选区再检测的方法虽然有相对较高的检测准确率,但运行速度较慢。
YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置。
实际上,YOLO并没有真正去掉候选区,而是采用了预定义候选区的方法,也就是将图片划分为7*7个网格,每个网格允许预测出2个边框,总共49*2个bounding box,可以理解为98个候选区域,它们很粗略地覆盖了图片的整个区域。YOLO以降低mAP为代价,大幅提升了时间效率。
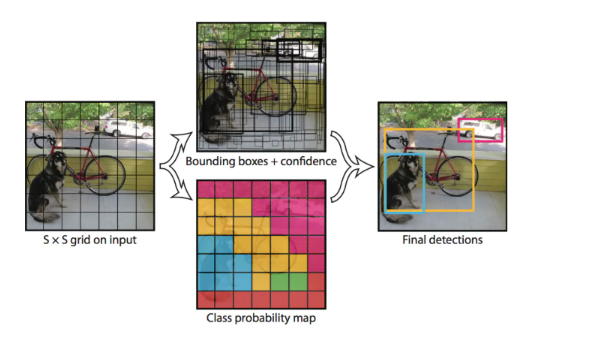
每个网格单元预测2个边界框和置信度分数。这些置信度分数反映了该模型对框是否包含目标的可靠程度,以及它预测框的准确程度。如果该单元格中不存在目标,则置信度分数应为零。否则,我们希望置信度分数等于预测框与真实值之间联合部分的交集(IOU)。
每个边界框包含5个预测:x,y,w,h和置信度。(x,y)坐标表示边界框相对于网格单元边界框的中心,宽度和高度是相对于整张图像预测的,置信度表示预测框与实际边界框之间的IOU。
每个边界框还预测C个条件类别概率,这些概率以包含目标的网格单元为条件。每个网格单元只预测的一组类别概率,而不管边界框的的数量是多少。
YOLOv1网络的结构如下,包含24个卷积层+2层全连接层
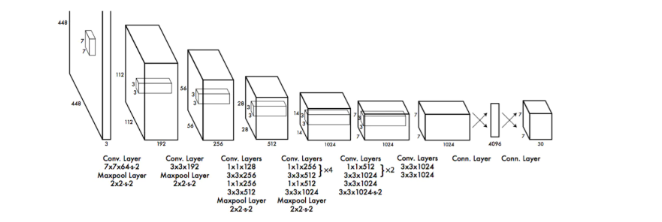
3.数据集
3.1 MS COCO
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集(COCO在目标检测中的地位与ImageNet在图片分类中的地位类似),主要用于目标检测,图像分割,姿态估计等。该数据集收集了大量包含常见物体的日常场景图片,并提供像素级的实例标注以更精确地评估检测和分割算法的效果,致力于推动场景理解的研究进展.
相比ImageNet,COCO更加偏好目标与其场景共同出现的图片,即non-iconic images。这样的图片能够反映视觉上的语义,更符合图像理解的任务要求。而相对的iconic images则更适合浅语义的图像分类等任务。
COCO数据集分大类有12个,分别是:[‘appliance’, ‘food’, ‘indoor’, ‘accessory’, ‘electronic’, ‘furniture’, ‘vehicle’, ‘sports’, ‘animal’, ‘kitchen’, ‘person’, ‘outdoor’]。
COCO数据集分小类有80个,分别是:[‘person’, ‘bicycle’, ‘car’, ‘motorcycle’, ‘airplane’, ‘bus’, ‘train’, ‘truck’, ‘boat’, ‘traffic light’, ‘fire hydrant’, ‘stop sign’, ‘parking meter’, ‘bench’, ‘bird’, ‘cat’, ‘dog’, ‘horse’, ‘sheep’, ‘cow’, ‘elephant’, ‘bear’, ‘zebra’, ‘giraffe’, ‘backpack’, ‘umbrella’, ‘handbag’, ‘tie’, ‘suitcase’, ‘frisbee’, ‘skis’, ‘snowboard’, ‘sports ball’, ‘kite’, ‘baseball bat’, ‘baseball glove’, ‘skateboard’, ‘surfboard’, ‘tennis racket’, ‘bottle’, ‘wine glass’, ‘cup’, ‘fork’, ‘knife’, ‘spoon’, ‘bowl’, ‘banana’, ‘apple’, ‘sandwich’, ‘orange’, ‘broccoli’, ‘carrot’, ‘hot dog’, ‘pizza’, ‘donut’, ‘cake’, ‘chair’, ‘couch’, ‘potted plant’, ‘bed’, ‘dining table’, ‘toilet’, ‘tv’, ‘laptop’, ‘mouse’, ‘remote’, ‘keyboard’, ‘cell phone’, ‘microwave’, ‘oven’, ‘toaster’, ‘sink’, ‘refrigerator’, ‘book’, ‘clock’, ‘vase’, ‘scissors’, ‘teddy bear’, ‘hair drier’, ‘toothbrush’]
3.2 ImageNet
ImageNet是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。ImageNet是美国斯坦福的计算机科学家,模拟人类的识别系统建立的。能够从图片识别物体。ImageNet数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。ImageNet数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
3.3 Google Open Image
Open Image是谷歌团队发布的数据集。最新发布的Open Images V4包含190万图像、600个种类,1540万个bounding-box标注,是当前最大的带物体位置标注信息的数据集。这些边界框大部分都是由专业注释人员手动绘制的,确保了它们的准确性和一致性。另外,这些图像是非常多样化的,并且通常包含有多个对象的复杂场景(平均每张图像8个对象)。
3.4 PASCAL VOC
参考链接:目标检测数据集PASCAL VOC简介 | arleyzhang;
VOC数据集是目标检测经常用的一个数据集,自2005年起每年举办一次比赛,最开始只有4类,到2007年扩充为20个类,共有两个常用的版本:2007和2012(因为二者互斥不相容)。学术界常用5k的train/val 2007和16k的train/val 2012作为训练集,test 2007作为测试集,用10k的train/val 2007+test 2007和16k的train/val 2012作为训练集,test2012作为测试集,分别汇报结果。
虽然近期的目标检测或分割模型更倾向于使用MS COCO数据集,但是这丝毫不影响 PASCAL VOC数据集的重要性,毕竟PASCAL对于目标检测或分割类型来说属于先驱者的地位。
下面介绍PASCAL VOC数据集在几个关键时间点的调整:
- 2005年只有4个类别:bicycles, cars, motorbikes, people。其Train/validation/test共有图片1578 张,包含2209个已标注的目标;
- 2007年类别扩充到20类。其Train/validation/test共有9963张图片,包含24640个已标注的目标(07年之前的数据集中test部分都是公布的,但是之后的都没有公布);
- 2009年之前,虽然每年的数据集都在变大(08年比07年略少),但是每年的数据集都是不一样的,也就是说每年的数据集都是互斥的,没有重叠的图片。从2009年开始,PASCAL VOC通过在前一年的数据集基础上增加新数据的方式来扩充数据集。如09年的数据集包含08年的数据集,也就是说08年的数据集是09年的一个子集,以后每年都是这样的扩充方式,直到2012年;
- 从09年到11年,数据量仍然通过上述方式不断增长,11年到12年,用于
分类、检测和person layout任务的数据量没有改变。主要是针对分割和动作识别,完善相应的数据子集以及标注信息;
对于分类和检测任务来说(分割任务以及其他任务的数据集不多介绍),可以绘制PASCAL VOC数据集的发展历程,其中相同颜色表示相同的数据集

VOC 2012用于分类和检测的数据包含 2008-2011年间的所有数据,并与VOC2007互斥;
截止2012年,最终用于分类和检测的数据集规模为:train/val :11540 张图片,包含 27450 个已被标注的 ROI annotated objects ;
PASCAL VOC 数据集的20个类别及其层级结构如下:

- 从2007年开始,PASCAL VOC每年的数据集都是这个层级结构
- 总共4个大类:vehicle,household,animal,person
- 总共20个小类,预测的时候只输出图中黑色粗体的类别(上标表示每个类别加入挑战赛的年份)
- 该数据集主要关注分类和检测,即分类和检测用到的数据集相对规模较大。关于其他任务比如分割,动作识别等,其数据集一般是分类和检测数据集的子集(规模较小)。
3.4.1 VOC 2007
VOC 2007数据集中的部分样本可以在此处查看:PASCAL VOC2007 Example Images (ox.ac.uk);
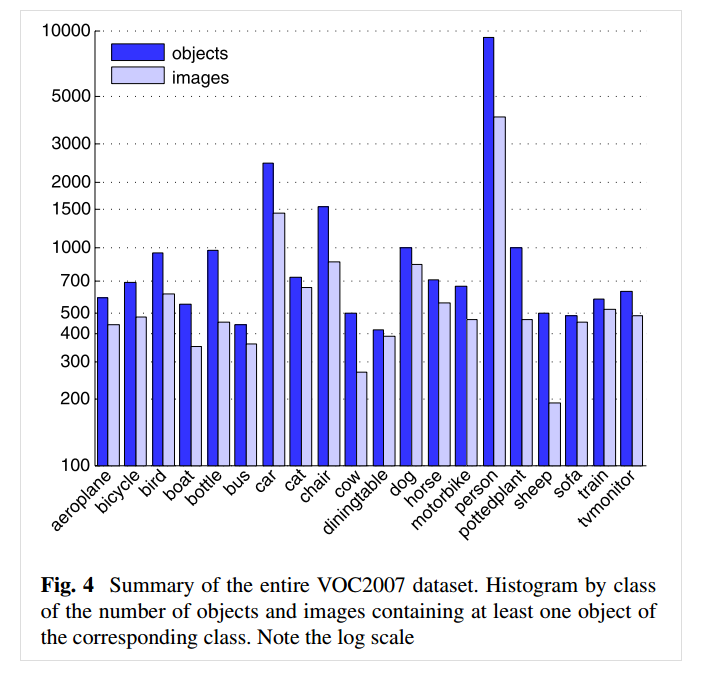
数据集总体统计情况(包含测试集),可以看到person类最多
训练集,验证集,测试集的划分情况如下
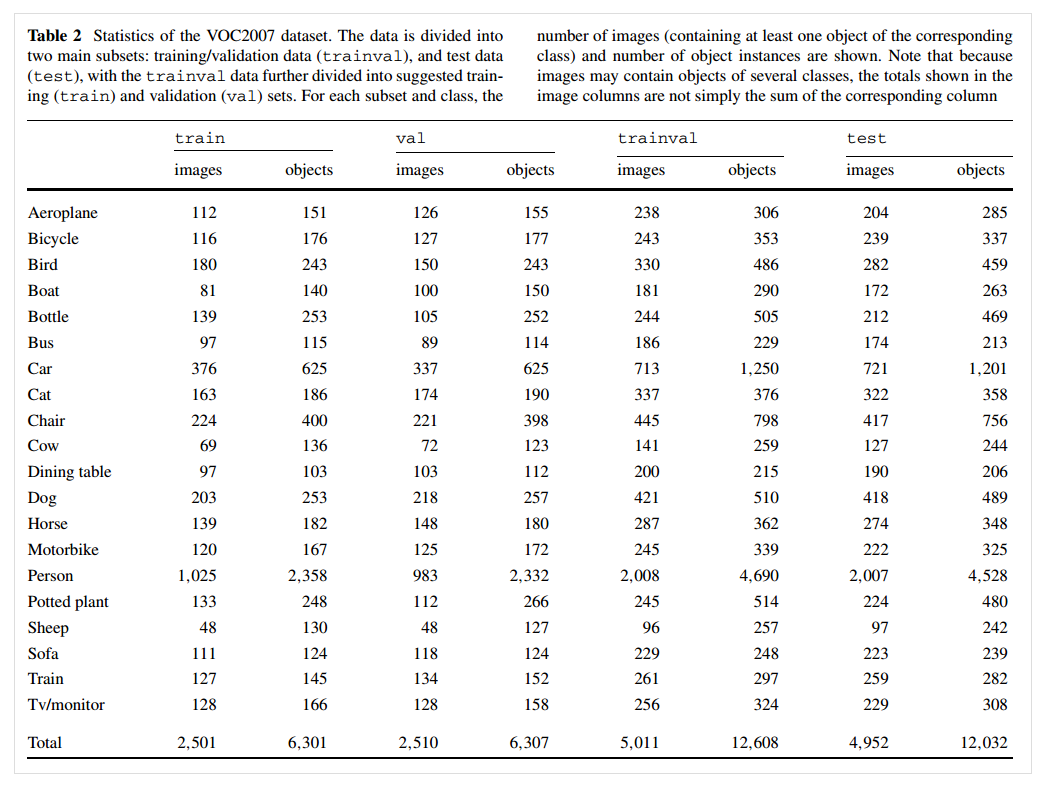
- VOC 2007数据集被分为两个子集:trainval和test,两者各占数据总量的约50%。其中trainval又分为两个子集:train和val,二者分别各占trainval的50%;
- 对于其中任何一张图像来说,都至少包含一个object(该object与该图像的class是相关的,更多的,图中的其他objects可以是其他类别);
3.4.2 VOC 2012
VOC 2012数据集中的部分样本可以在此处查看:PASCAL VOC2011 Example Images (ox.ac.uk);
数据集总体统计情况(不包含测试集),可以看到仍然是person类最多
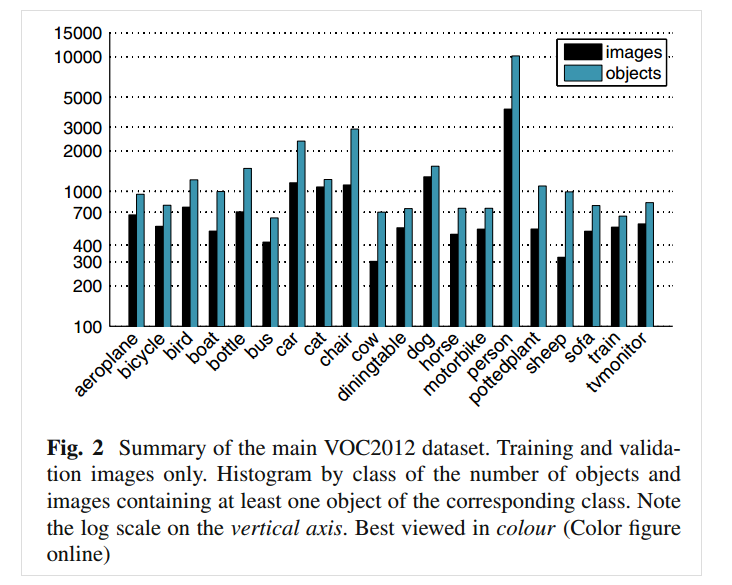
因为VOC 2012的test部分没有公布,因此仅展示trainval部分的数据统计
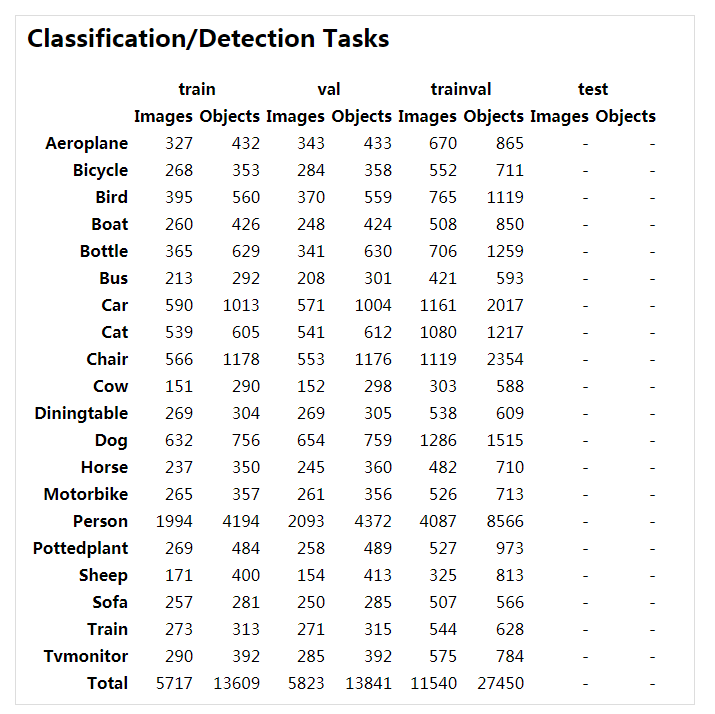
3.4.3 2007 VS. 2012
VOC 2007 与 2012 数据集及二者的并集数据量对比

黑色字体所示数字是官方给定的,由于VOC2012数据集中 test 部分没有公布,因此红色字体所示数字为
估计数据,按照PASCAL 通常的划分方法,即 trainval 与test 各占总数据量的一半
3.4.4 VOC结构
因为本项目使用的是VOC 2007的数据集,因此下面我们下载并分析VOC 2007的数据集格式(VOC2012 的数据集组织结构是类似的,不一样的地方在于VOC2012 中没有 test类的图片和以及相关标签和分割文件,因为这部分数据 VOC2012没有公布)
VOC 2007的下载链接如下:
- 2007 trainval:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar (450MB tar file)
- 2007 test:http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar (430MB tar file)
另一种下载方式就是在镜像网站Pascal VOC Dataset Mirror (pjreddie.com)中复制下载链接进入迅雷下载,该方式下载速度非常快;
下载完毕后对文件进行解压(注意直接解压会被解压到同一个目录下无法区分,可以设置解压路径以区分),无论是trainval还是test解压后都将得到如下形式的目录结构
1 | |
- Annotation 文件夹存放的是xml文件,该文件是对图片的解释,每张图片都对应一个同名的xml文件
- ImageSets 文件夹存放的是txt文件,这些txt将数据集的图片分成了各种集合。如Main下的train.txt中记录的是用于训练的图片集合
- JPEGImages 文件夹存放的是数据集的原图片
- SegmentationClass以及SegmentationObject 文件夹存放的都是图片,且都是图像分割结果图
(1)Annotation
Annotation文件夹的内容如下
其中xml主要介绍了对应图片的基本信息,如来自哪个文件夹、文件名、来源、图像尺寸以及图像中包含哪些目标以及目标的信息等等
1 | |
- filename :文件名
- source,owner:图片来源及拥有者
- size:图片大小
- segmented:是否分割
- object:表明这是一个目标,里面的内容是目标的相关信息
- name:object名称,20个类别
- pose:拍摄角度:front, rear, left, right, unspecified
- truncated:目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
- difficult:检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断
- bndbox:bounding box 的左上角点和右下角点的4个坐标值
difficult 标签示例:图中白色虚线,被标记为 difficult,被标记为difficult的示例不参与evaluation

(2)ImageSets
mageSets存放数据集的分割文件,包含三个子文件夹 Layout,Main,Segmentation,其中Main文件夹存放的是用于分类和检测的数据集分割文件,Layout文件夹用于 person layout任务,Segmentation用于分割任务

Main文件夹中主要的几个文件如下
1 | |
以train.txt为例,其存放的内容形式如下

实际上就是对数据集的分割,train.txt部分的内容用于train,其他的用于val和test等
Main中剩下的文件是每一类别在train或val或test中的ground truth,这个ground truth是为了方便classification 任务而提供的;如果是detection的话,使用的是Annotation中的xml标签文件
1 | |
以diningtable_trainval.txt为例,其存放的内容形式如下

前面一列是训练集中的图片名称,这一列跟trainval.txt文件中的内容是一样的,后面一列是标签,即训练集中这张图片是不是diningtable,是的话为1,否则为-1。其他所有类似的 (class)_(imgset).txt 文件均是如此:
- (class)_train 存放的是训练使用的数据,每一个class都有2501个train数据;
- (class)_val 存放的是验证使用的数据,每一个class都有2510个val数据;
- (class)_trainval 将上面两个进行了合并,每一个class有5011个数据;
- (class)_test 存放的是测试使用的数据,每一个class有4952个test数据;
所有文件都指定了正负样本,每个class的实际数量为正样本的数量,train和val两者没有交集。
4.相关技术
4.1 迁移学习
实际训练的时候很少能够拥有足够大的数据集进行训练,因此迁移学习在实际的卷积网络训练的过程中非常重要(除了训练数据集的原因,cv领域的训练时间很长也是一个原因)。
迁移学习简单来说就是先将模型在大数据集如Imagenet上进行预训练,然后将训练完成的模型作为指定数据集的初始化或固定的特征提取器。
迁移学习主要有以下用途(即两种不同的权重处理方式):
将预训练的卷积网络作为固定特征提取器。除了预训练模型最后的全连接层外,将会冻结所有网络的权重。最后的全连接层将会被一个新的随机初始化的全连接层替代,并且仅训练该层。微调预训练的卷积网络。不使用随机初始化而是用一个预训练网络来初始化网络,剩下的训练过程与普通卷积网络训练相同。可以微调卷积网络的所有层,或者可以保持一些早期的层固定不变(避免过拟合),只微调网络的一些较高层部分。这是因为观察到卷积网络的早期的层包含更多通用特征(例如,边缘检测器或颜色斑点检测器),这些特征对许多任务都通用,但是卷积网络的顶层对于原始数据集中包含的类的细节随着层数的升高逐渐具体(例如训练犬类,可能早期的层能够提取到的特征是体型,但是高层提取到的特征是毛发特征、瞳孔颜色等)。
什么情况下应该使用迁移学习呢?主要有两个因素:
- 新数据集的规模;
- 新数据集与原数据集的相似程度;
根据以上两个因素将迁移学习的应用场景分为四类:
新数据集很小,与原始数据集相似。由于数据集很小,存在过拟合的问题,所以微调卷积网络不是一个好主意;由于数据与原始数据相似,卷积网络中的高级特征与此数据集相关,因此使用固定特征提取器的方式,再训练一个线性分类器是最好的选择;新数据集很大,与原始数据集相似。因为有更多的数据,所以对整个网络进行微调不会产生过拟合;新数据集很小,与原始数据集非常不同。因为数据很小,所以使用固定特征提取器的方式,再训练一个线性分类器。但是由于数据集有很大的不同,所以不能直接从包含更多数据集特定特征的网络顶部来训练分类器,而是固定网络早期权重,微调网络顶部权重的方式来训练线性分类器;新数据集很大,与原始数据集非常不同。由于数据集非常大,能够从头开始训练一个卷积网络。但是在实践中,用来自预训练模型的权重初始化仍然非常有效,这种情况下对网络进行微调的效果将会非常好;
4.2 Hard Negative Mining
参考链接:
Hard Negative Mining又称为难例挖掘,其中hard是指困难样本,negative是指负样本(目标检测任务中,定义样本为图像中的各种检测区域(一般是矩形框),正样本是指包含检测目标的区域,负样本是指不包含或仅包含部分检测目标的区域(具体正负样本的标签需要人为进行标注,也就是说包含多少目标信息的区域可以被标注是正样本是人为主观判定的)。注意负样本和背景的区别,背景不包含任何检测目标,而负样本可以包含部分检测目标),而hard negative是指对负样本进行分类的时候loss较大(即预测标签和真实标签的差别较大)的那些负样本,换句话说,hard negative就是容易将负样本分类为正样本的那些负样本。
- easy negative:在ROI(region of interest)中,没有目标全是背景,则分类器很容易将其分类为负样本(该ROI的真实标签是负样本);
- hard negative:在ROI中,有很大一部分都是目标,造成极大的干扰,因此分类器很容易将其分类为正样本(该ROI的真实标签是负样本,这就是假阳性);
而hard negative mining是指在负样本集中多加入一些hard negative,这样会比单纯的easy negative组成的负样本集的训练效果好(可以认为hard negative是错题集)。
如何在训练过程中选择并使用困难负样本?原理非常简单,先用初始样本集去训练网络(为了平衡数据,此时使用的负样本也只是所有负样本的子集),再用训练好的网络去预测负样本集中剩余的样本,选择其中最容易被判断为正样本的负样本作为困难样本将其加入负样本集中,并重新训练网络,如此循环可以发现网络的分类性能越来越强。
hard negative mining的缺点在于因为它需要迭代训练,因此很难用到end-to-end的检测模型中,如果非要用到end-to-end的卷积模型中,需要每次都将网络冻结一段时间来生成hard negative,但这种做法和线上优化会产生冲突,例如使用SGD(随机梯度下降)来训练网络需要上万次的对网络的更新,如果每迭代几次就冻结网络一段时间,则整个网络的训练时间会相当大。在fast rcnn和faster rcnn中都没有使用hnm,原因就是如此,一般只有使用svm的时候才会使用该方法(svm分类器和hnm交替训练)。
Q:为什么使用了hnm的效果会更好?hnm出现的原因是什么?
A:难例挖掘hnm和非最大抑制nms都是为了解决目标检测领域的经典问题 – 正负样本不平衡+低召回率。
目标检测任务和图像分类任务的不同在于,图像分类往往只有一个输出,而目标检测的输出个数是未知的(除了标注数据ground-truth以外,模型无法知道自己在一张图上要预测多少物体,也就是需要在图像上给出多少个检测框)。在目标检测领域,召回率定义为所有标注的真实边界框(检测目标)有多少被检测出来(更直白的说recall就是所有某类物体中被检测出来的概率)。
为了提高召回率,基本的思想就是“宁可错杀一千,绝不放过一个”(不管检测了多少次,只要能检测出目标就行。如图像中有一只cat和一个car,最理想的效果就是图像上被给出两个检测框分别框出了cat和car;退一步,图像上给出了很多个检测框,这其中有检测出cat和car的框也可以),因此模型往往会提出远高于真实边界框数量的区域建议region proposal(例子中我们期望输出cat和car两个检测框,模型一般会给我们几十个甚至几百个建议检测框)。这样会导致一个问题,这些提出的区域建议往往大部分都是负样本(即包含少量目标信息甚至不包含目标信息的区域)。
为了让模型能够正常训练,需要通过某种方法抑制大量的easy negative,同时尽可能多的挖掘hard negative。
Q:如何更通俗的理解hnm?
A:选自知乎评论
“首先要做一个目标检测器,那第一个目标就是把应该检测到的检测出来,即高recall,因为你的目的就是把那些前景比如车啊,人啊检测出来,然后再去谈你的precision,你的目标检测器可能会有一些误检之类的,比如把树当成了人。而想要达到高的recall,就应该放置更多的anchor,因为越多你才能覆盖图像上的每个区域,才能把每个区域的物体检测出来。但是呢,一张图片上的前景毕竟是少数,大部分是背景,这就导致大部分的anchor都是负例,并且还是非常容易区分的负例,因为大部分的anchor与前景根本就不相交。如果都所有的anchor都参与训练,大量的容易区分的anchor的梯度会覆盖掉难区分的负例和正例的梯度,让检测器称为一个检测背景的检测器。怎么解决容易区分的负例带来的这种影响,那就是难负例挖掘,只让比较难的参与训练。”
4.3 PyTorch数据加载
参考链接:
- 一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系 - marsggbo - 博客园 (cnblogs.com);
- (2条消息) 【pytorch】|Dataloader dataset sampler torchvision_rrr2的博客-CSDN博客;
- (1条消息) Pytorch笔记:DataLoader,Dataset和Sampler_valueerror: dataset attribute should not be set af_硝烟_1994的博客-CSDN博客;
pytorch的五大模块为:数据、模型、损失函数、优化器和迭代训练。其中的数据模块可细分为如下四个部分:
- 数据收集:收集样本和标注标签;
- 数据划分:将收集到的数据划分为训练集、验证集和测试集;
- 数据读取:该部分对应pytorch的Dataloader,而Dataloader包括Sampler和Dataset,其中Sampler的功能是生成索引index,Dataset的功能是根据生成的index读取样本及标签;
- 数据预处理:对应pytorch的transforms;
Dataset、Dataloader和Sampler三个类都是torch.utils.data 包下的模块(类),torch/utils/data下面一共含有4个主文件
1 | |
- Dataset是数据集的类,主要用于定义数据集
- Sampler是采样器的类,用于定义从数据集中选出数据的规则,比如是随机取数据还是按照顺序取等等
- Dataloader是数据的加载类,Dataset和Sampler会作为参数传递给Dataloader。Dataloader是对于Dataset和Sampler的进一步包装,用于实际读取数据,而Dataset和Sampler则负责定义。模型训练、测试所获得的数据是Dataloader传递的。
pytorch 的数据加载到模型的操作顺序是这样的:
- 创建一个 Dataset 对象;
- 创建一个 DataLoader 对象;
- 循环这个 DataLoader 对象,通过dataset、sampler参数将img和label加载到模型中进行训练;
假设数据集中的数据是一组图像,每张图像都有一张对应的index,则读取数据只需要获取index即可。获取index的方式有多种,有顺序也有乱序,由Sampler完成。获取到index后,只需要根据index对Dataset中的数据进行读取即可,因此Dataloader、Dataset和Sampler三者的关系如下
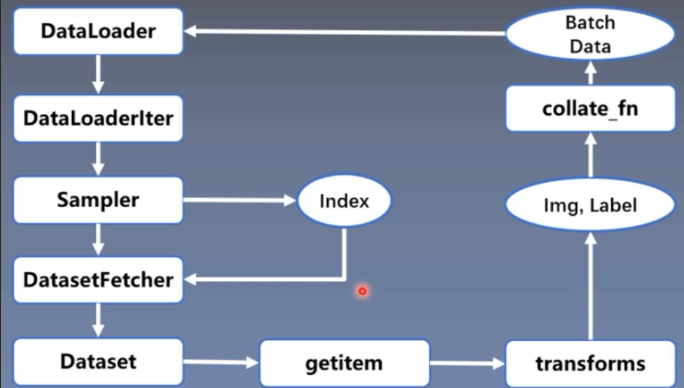
简单来说,用一个Dataset类抽象地表示数据集,在训练时Dataloader作为迭代器,每次产生一个batch大小的数据用于训练以节省内存。
4.3.1 DataLoader
Dataloader对Dataset(和Sampler等)打包,完成最后对数据的读取的执行工作,一般不需要自己定义或者重写一个Dataloader的类(或子类),直接使用即可,通过传入参数定制Dataloader,定制化的功能在Dataset(和Sampler等)中完成。
Dataloader的参数及其含义如下
1 | |
- dataset(Dataset): 传入的数据集
- batch_size(int, optional): 每个batch有多少个样本
- shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
- sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
- batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥 – Mutually exclusive)
- num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
- pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
- collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
- drop_last (bool, optional): 这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,如果设置为True,那么训练的时候后面的36个就被扔掉了…
如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点 - timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
- worker_init_fn (callable, optional): worker初始化函数,如果该参数非空则在每个worker子进程上与worker id作为输入
- multiprocessing_context:多道处理
4.3.2 Sampler
Sampler的作用在于生成相应的索引。在DataLoader类的初始化参数里有两种Sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。
Sampler类是一个抽象父类,其主要用于设置从一个序列中返回样本的规则,即采样的规则。所有的采样器(无论是pytorch中已经实现的还是自定义的采样器)都继承自Sampler类
1 | |
Sampler是一个可迭代对象,使用step方法可以返回下一个迭代后的结果,因此其主要的类方法就是 iter 方法,定义了迭代后返回的内容。
无论是自定义的Sampler还是pytorch已经实现的Sampler,每次都只会返回一个索引,而在训练时是对批量的数据进行训练,该工作需要BatchSampler来完成。BatchSampler的作用就是将前面的Sampler采样得到的索引值进行合并,当数量等于一个batch大小后就将这一批的索引值返回
1 | |
DataLoader的部分初始化参数之间存在互斥关系:
- 如果自定义了batch_sampler,那么这些参数都必须使用默认值:batch_size,shuffle,sampler,drop_last.
- 如果自定义了sampler,那么shuffle需要设置为False
- 如果sampler和batch_sampler都为None,那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:
- 若shuffle=True,则sampler=RandomSampler(dataset)【使用较多】
- 若shuffle=False,则sampler=SequentialSampler(dataset)
4.3.3 Dataset
作用:保存数据集的图片和相应的标签,通过索引能够完成图片的加载以及预处理、标签的加载以及预处理。Datasets是后续构建Dataloader工具函数的实例参数之一。
Dataset 是抽象类,所有自定义的 Dataset 都需要继承该类,并且重写__getitem()__方法和__len__()方法(不覆写这两个方法会直接返回错误) 。__getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。__len__()方法是返回所有样本的数量。
二、R-CNN论文详解及实现
R-CNN阅读地址:《Rich feature hierarchies for accurate object detection and semantic segmentation》
1.选择性搜索算法
选择性搜索算法在R-CNN中用于获取图像中大量的候选目标框,其相关论文于2012年发表于IJCV会议,论文名为Selective Search for Object Recognition。
在R-CNN架构的第一步就是寻找推荐区域(Region Proposal),推荐区域也被称为ROI(Region Of Interest)。获取推荐区域的方法主要有滑动窗口、规则块和选择性搜索:
- 滑动窗口:本质上就是穷举法,利用不同的尺度和长宽比把所有可能的大大小小的块都穷举出来,然后送去识别,识别出来概率大的就留下来。很明显,这样的方法复杂度太高,产生了很多的冗余候选区域,在现实当中不可行。
- 规则块:在穷举法的基础上进行了一些剪枝,只选用固定的大小和长宽比。但是对于普通的目标检测来说,规则块依然需要访问很多的位置,复杂度高。
- 选择性搜索:规则块的问题在于无法有效去除冗余的候选区域,考虑到冗余候选区域大多是发生了重叠,选择性搜索自底向上合并相邻的重叠区域从而减少冗余。
选择性搜索的算法流程如下

选择性搜索输入的是彩色图像,输出为候选的目标边界框集合。选择性搜索主要流程分为以下几个步骤:
- 利用felzenszwalb分割算法获取初始区域集合R,同时初始化相似性度量集合S;
- 遍历整个区域集合S,得到所有的相邻区域对(r
i,rj)集合; - 遍历所有区域对(r
i,rj)集合,计算区域ri和rj的相似性度量,同时将该相似性度量加入集合S; - 在S不为空的情况下,进行循环处理,在循环中
- 找到相似性度量最大对应的区域对(r
i,rj); - 将区域r
i和rj合并,记作rt; - 从集合S中删除与区域r
i相邻的其他区域的相似性度量; - 从集合S中删除与区域r
j相邻的其他区域的相似性度量; - 计算区域r
t与其相邻区域之间的相似性度量,将其加入集合S中; - 将区域r
t加入区域集合R;
- 找到相似性度量最大对应的区域对(r
论文中的相似性度量主要使用了颜色相似度、纹理相似度、大小相似度和吻合相似度,具体的每个相似度的计算参考相似性度量。
Q:如何通俗理解选择性搜索算法?
A:想象一下你要在一大堆拼图中找到一只猫的图案。你不知道猫在哪里,但你知道它在某个地方。为了找到它,你可以选择使用选择性搜索策略:首先观察整个拼图,并注意到一些可能包含猫的区域,比如一些颜色或纹理突出的地方。然后,你只检查那些可能有猫的区域,而不是每个拼图块。这样,你可以更快地找到猫,并且不需要检查每个拼图块。
2.边界框回归
目标检测相较于传统的图像分类,不仅需要实现对目标的分类,还需要解决目标的定位问题(即获取目标在原始图像中的位置信息),R-CNN利用边界框回归来预测物体的目标检测框。
输入到边界框回归的数据集为{(P^i^,G^i^)}i=1,…,N,其中P^i^=(P^i^x,P^i^y,P^i^w,P^i^h),G^i^=(G^i^x,G^i^y,G^i^w,G^i^h):
- P^i^表示第i个待预测的候选目标检测框即Region Proposal,在R-CNN中P^i^利用选择性搜索算法进行获取;
- P^i^
x表示候选目标框的中心点在原始图像中的x坐标; - P^i^
y表示候选目标框的中心点在原始图像中的y坐标; - P^i^
w表示候选目标框的长度; - P^i^
h表示候选目标框的宽度;
- P^i^
- G^i^表示第i个真实目标检测框即ground-truth
- G^i^的四维特征的含义与P^i^相同;
边界框回归需要做的是利用某种映射关系,使得候选目标框Region Proposal的映射目标框无限接近真实目标框ground-truth。边界框回归过程的图像表示如下
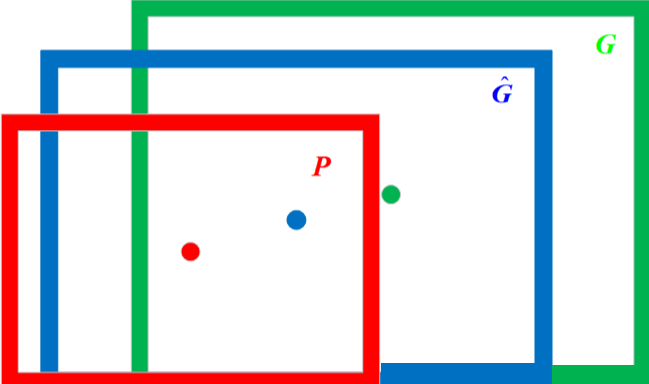
- 红色框代表候选目标框,红色圆圈代表选候选目标框的中心点;
- 绿色框代表真实目标框,绿色圆圈代表选真实目标框的中心点;
- 蓝色框代表边界框回归算法预测目标框,蓝色圆圈代表选边界框回归算法预测目标框的中心点;
R-CNN论文指出,边界框回归利用平移变换和尺度变换来实现映射,更进一步的,边界框回归要设计4个不同的Ridge回归模型分别求解wx,wy,ww,wh。
Tips:
- IoU较大时(论文中认为IoU大于0.6),边界框回归可视为线性变换;
- 深度神经网络的基本作用是分类,而在目标检测中设计的深度网络一般是全卷积网络,目的是为了保持目标的尺度不变性。候选框到真实框的映射也是基于目标尺度不变性,生成的候选框region proposal要求必须在真实框的附近。基本做法是随机生成大量框,用CNN剔除非目标的框后剩下的就是候选框,候选框经过微调进一步向目标框逼近,最后执行回归得到预测框。
Q:如何通俗的理解边界框回归?
A:想象一下你正在玩一个抓娃娃机游戏,你的目标是用抓手捉住一个玩具。你只有一次机会,而玩具的位置可能会在你抓取之前稍微移动。为了增加成功的机会,你需要非常准确地控制抓手的位置和方向。
现在,假设你有一个机器学习模型,它要帮助你自动控制抓手。这个模型需要知道两个重要的事情:
- 玩具的大致位置:首先,它需要知道玩具大致在哪里,以便将抓手移动到正确的地方。这就是目标检测的任务,找出图像中的物体位置。
- 如何精确抓住玩具:但仅知道物体的位置不足够,因为你需要准确控制抓手来抓住它。这就是边界框回归的任务。边界框回归告诉模型如何微调抓手的位置和方向,以确保最终能够精确抓住玩具。
所以,边界框回归可以理解为一种帮助模型在目标检测后更精确地定位物体的技术。它通过调整目标物体的边界框(通常是矩形框),使其更准确地包围物体,从而提高目标检测的精度。这就像在抓娃娃机游戏中,你的模型不仅告诉你玩具在哪里,还告诉你应该如何微调抓手来确保成功捉住玩具。
3.IoU与非极大抑制
在RCNN中,候选框主要是由选择性搜索算法获取的。为了涵盖每张图片中对各个目标,选择行搜索算法会返回将近2000个候选框,因此带来大量重叠率较高的目标框。因此在分类和定位任务结束后,利用非极大抑制算法删除多余重复候选框很有必要。
IoU是描述两个矩形框之间重合程度的指标,在RCNN中常用于衡量边界框回归算法得到的预测目标框与真实目标框之间的重合程度。
非极大抑制算法(Non-Maximum Suppression,NMS)用于去除大量重复的候选目标框。
IoU交并比全称为Intersection over Union,假设两个目标框分别为A和B,则两个目标框的交并比计算公式为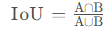 ,实际上就是两个目标框的交集与并集的比值。
,实际上就是两个目标框的交集与并集的比值。
非极大抑制(Non-Maximum Suppression,NMS)就是抑制最大值,也可以将其理解为搜索局部最大值(R-CNN中的NMS特指目标检测领域中搜索分类概率最大的目标框的非极大抑制算法而非通用的非极大抑制)。
通常采用分类概率与IoU作为指标来实现目标框的非极大抑制,算法流程如下:
- 按照目标框对应的分类概率进行排序,选取分类概率最大的目标框,记作current_box;
- 计算current_box与剩余目标框之间的IoU;
- 将IoU大于阈值的目标框舍弃;
- 在剩余的目标框中再选出最大分类概率的目标框,按照上述流程循环直至条件结束;
从上述流程可以看出,非极大抑制是一种贪心算法,其主要目的就是消除多余的重叠比例较高的目标框。
4.R-CNN详解
R-CNN主要有如下两个特点:
- 层次化的多阶段特征:在候选区域(Region proposal)上自下而上使用大型卷积神经网络(CNNs)进行提取图像特征,之后用于定位和分割物体;
- 迁移学习:当带标签的训练数据不足时,先针对辅助任务进行有监督预训练,再进行特定任务的调优,即微调(fine-tuning),就可以产生明显的性能提升;
R-CNN的模型架构如下所示
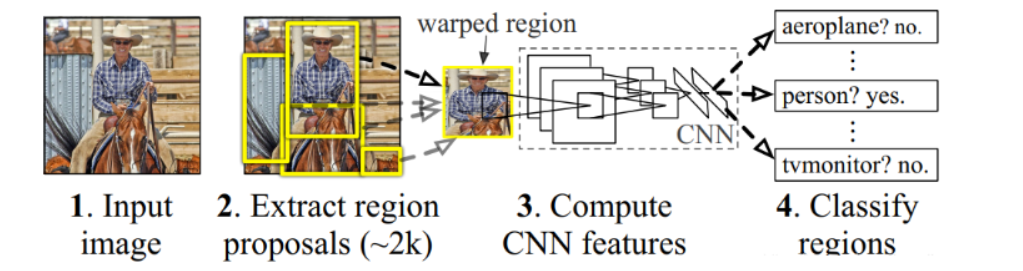
- 推荐区域提取:R-CNN首先在输入图像中提取接近2000个目标框区域 – R-CNN使用选择性搜索算法生成推荐区域Region proposals;
- 特征提取:利用选择性搜索算法得到原始图像的推荐区域后,R-CNN将这些区域送入CNN中提取深度特征 – R-CNN采用alexnet作为提取图像特征的主干网络;
- 一般将alexnet的最后专用于Imagenet的1000-way分类层丢弃,采用新的分类层;
- alexnet要求输入图像必须是
227*227的RGB彩色图像,因此需要将选择性搜索算法得到的推荐区域的图像尺寸转换为227*227;
- 最后利用这些深度特征进行目标的分类与定位两大任务;
因为上述模型结合了推荐区域Region proposals和CNN,因此取名为R-CNN:Region with CNN features。
4.1 训练阶段
R-CNN的训练阶段和测试阶段有所区别,这里先介绍训练阶段
- 训练阶段alexnet模型采用的是有监督预训练和特定领域内参数微调的训练方式;
- 提取特征完成后,还需要训练每个类别的svm分类器,完成分类任务;
- 除了分类任务,R-CNN还需要完成定位任务,将alexnet获得的特征向量按照类别分别送入x,y,w,h这四个分量回归器,利用梯度下降计算每个分量回归器的权重。注意在这里特征向量的选择必须是与真实框(Ground Truth)之间IoU大于0.6的对应推荐区域提取出来的特征向量;
R-CNN的训练流程如图所示
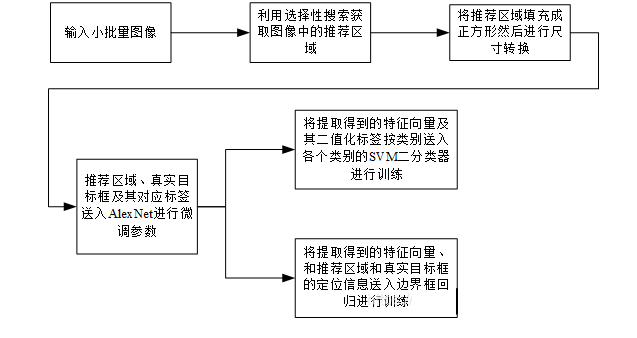
4.2 测试阶段
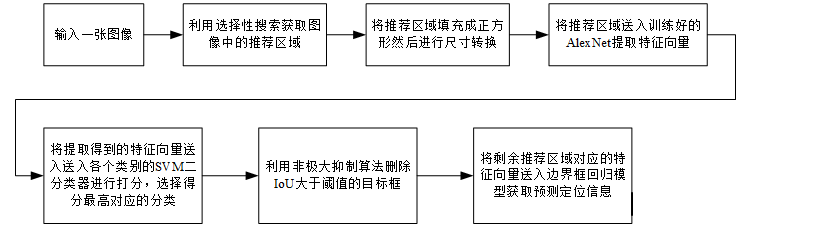
测试阶段可以理解为使用训练好检测器检测图像中的目标,其基本流程如下:
- 先利用选择性搜索算法获取目标检测框,同时将目标框填充为正方形并转换为尺寸大小
227*227; - 通过alexnet提取图像特征;
- 利用每个类别训练好的svm二分类器对alexnet提取得到的特征向量的每个类别进行打分,选择最高分为预测类别;
- 将每个类别的特征向量送入每个类别的边界回归器进行定位预测,此时可能产生目标框重叠,故使用NMS删除IoU大于阈值的重复目标框;
R-CNN的测试流程如图所示
4.3 核心问题
Q:为什么微调和训练svm使用的正负样本的阈值不同?
A:
微调阶段,因为CNN对小样本容易过拟合,因此需要大量的训练数据,因此对IoU的限制比较宽松:
- Ground Truth+与Ground Truth相交IoU>0.5的建议框为正样本,否则为负样本
而svm属于强分类器,适用于小样本训练,故对样本IoU的限制比较严格:
- Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本
Q:为什么不直接在微调结束后,在alexnet后直接加上softmax进行分类,而是采用svm进行分类?
A:因为微调使用的训练数据中的正样本并不强调精准的位置,且微调阶段的负样本是随机抽样的,因此直接使用softmax会导致mAP降低;
5.RNN算法实现
实现一个R-CNN算法来进行目标检测的完整过程主要包括如下步骤(这里以检测图像中的cat为例):
1.准备数据集,本项目使用PASCAL VOC 2007数据集
- 每张图片的大小可能不一样;
- 每张图片都有相应的标注信息,这个标注信息可以作为监督学习的标准。bonding box 图像数据集中明确给出,因此可以作为标注;
- 更多关于VOC 2007数据集的信息参考[背景介绍](# 3.4.1 VOC 2007);
2.数据集预处理
- 从VOC数据集种提取cat类别数据(pascal_voc_cat.py):抽取数据集中的任何一个类别的数据,作为此次训练对象(R-CNN并不是一次就能够训练出能够识别出所有类别的模型,它的基本原理是将这种训练的过程重复进行N次,N就是数据集的类别数量,训练完毕后R-CNN即可识别N种类别的物体);
- 创建微调数据集(create_finetune_data.py):针对其中一个类别(cat)的数据,进行2分类的数据处理,为之后对Alexnet进行微调作准备
- 标注边界框:选择voc数据集中某一类别的图片的真实框体(在标注文件中给出)
- 候选建议:使用区域候选方法(选择性搜索算法)选择多个候选框
- 计算候选框与标注边界框的Iou
- 正样本:IoU大于等于0.5;
- 负样本:剩余的候选区域中,IoU大于0,小于0.5且其大小必须大于标注框的1/5;
- 创建分类器数据集(create_classifier_data.py):为进一步进行svm二分类器的模型训练提供数据
- 标注边界框:选择voc数据集中某一类别的图片的真实框体(在标注文件中给出)
- 候选建议:使用区域候选方法(选择性搜索算法)选择多个候选框
- 计算候选框与标注边界框的Iou
- 正样本:标注边界框;
- 负样本:IoU大于0,小于0.3且其候选建议的大小必须大于标注框的1/5(为了减少负样本的数量);
- 创建边界框回归数据集(create_bbox_regression_data.py):利用微调数据集的正样本(IoU>=0.5),再进一步提取IoU>0.6的候选建议(数据集都是正例,故loss都是0)
3.区域候选建议(selectivesearch.py):使用选择性搜索算法实现
- 实例化gs;
- 配置gs的区域候选方式;
- 使用gs的process方法取候选框;
4.创建自定义数据集合(custom_finetune_dataset.py)和迭代器(custom_batch_sampler.py)用于形成input数据送入网络;
5.卷积神经网络训练(finetune.py):
- 使用finetune的方法继承alexnet的网络模型和参数,微调alexnet网络使其能够实现2分类,使网络模型能够确定一张图像中是否有car或cat(取决于训练数据);
6.分类器训练:R-CNN完成alexnet卷积模型的微调后,额外使用svm二分类器,采用负样本挖掘的方法进行模型训练(linear_svm.py)
- 先取得和正例相同数目的负例作为训练样本;
- 进行第一轮训练并计算出准确率和loss,根据验证集准确率表现,同时判断是否可以存储为最好的模型参数;
- 进行难分辨负样本挖掘,将挖掘好的难分辨负样本数据加到负样本总数据中,进行下一轮训练;
- 经过多轮训练,存储一个最好的二分类器;
7.边界框回归器训练(bbox_regression.py):使用svm对候选建议进行分类后,使用对应类别的边界框回归器预测其坐标偏移值,进一步提高检测精度
通过提高IoU阈值(>0.6)过滤正样本候选建议,将候选建议和标注边界框之间的转换看成线性回归问题,并通过岭回归(ridge regression)来训练权重w;
在读取alexnet的网络的基础上,冻结住alexnet的网络,并且取得alexnet中feature层的输出,送入一个线性的计算的模型,计算出4个输出,用于衡量偏移情况;
进行框体的非极大抑制的处理;
8.目标检测器实现(cat_detector.py):
- 输入图像;
- 使用选择性搜索算法计算得到候选建议;
- 逐个计算候选建议:
- 使用alexnet模型计算特征
- 使用线性svm分类器计算得到分类结果
- 对所有分类为cat的候选建议执行非最大抑制;
整个项目主要分为如下五个模块:
- 区域建议生成:借助选择性搜索算法selectivesearch实现,生成类别独立的区域建议;
- 特征提取:借助卷积神经网络alexnet实现,从每个区域建议中提取固定长度的特征向量;
- 线性svm实现:输入特征向量,输出每个类别的成绩;
- 边界回归:使用每个类指定的边界框回归器计算候选建议的坐标偏移;
- 非最大抑制:对候选建议做非最大抑制,得到最终的候选建议;
R-CNN项目结构如下所示(该项目结构是对github上的一个论文复现项目的结构梳理,仅理解用)
1 | |
三、目标检测系统
题目:目标检测系统
说明:构建一套实时目标检测系统,界面显示实时视频同时展示检测结果(需要注意的是视频检测而不是简单的图像检测)
设计文档内容:
- 系统功能描述;
- 系统设计:系统框图及其组成模块描述;
- 核心算法设计:该部分需要自行理解消化后撰写;
- 系统实现:算法实现、界面实现;
- 系统实践:
- 核心算法评估:实验数据集、实验参数、算法性能展示与问题分析;
- 系统测试:界面功能介绍,系统工作过程及结果展示;
- 实验总结:系统的优势与缺点;
(本项目是基于对上述R-CNN论文的理解所作的实践,在实现使用R-CNN对图像进行检测后,进一步实现了基于R-CNN的视频检测)
1.系统功能描述
本项目是一个基于R-CNN目标检测算法的实时目标检测系统,该系统可以检测并识别视频中的猫咪,只需在可视化界面中输入需要检测的视频路径并点击“start”即可开始进行目标检测
该系统具有简洁美观的可视化界面,并且操作简单易上手。可将本系统作为组件嵌入到流浪猫搜寻系统、猫咪看护机器人等,可极大的提升这些系统的性能。

2.系统设计
整个项目的项目结构如下
1 | |
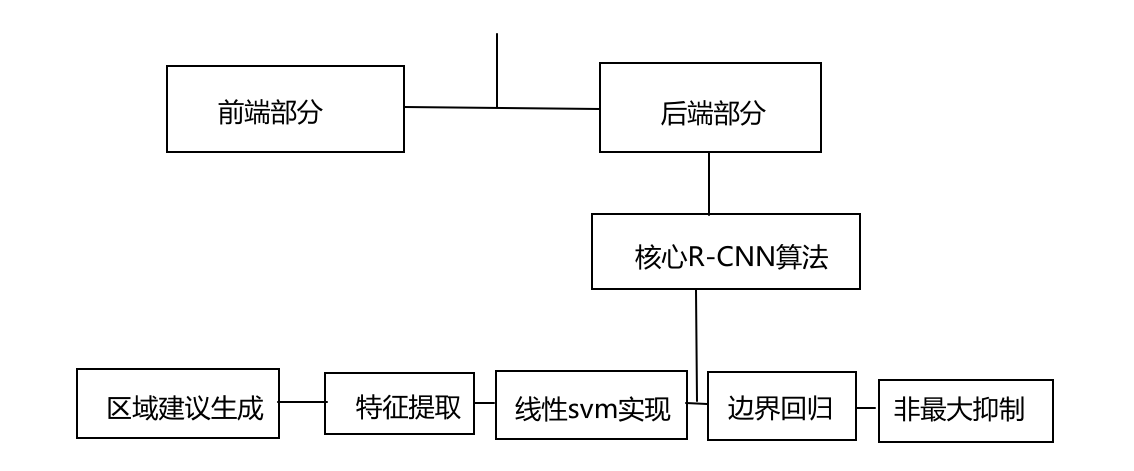
系统从整体上来说分为两个部分:前端可视化部分和后端逻辑处理部分。
整个项目的核心部分(R-CNN目标检测算法)主要分为如下五个模块:
- 区域建议生成:借助选择性搜索算法selectivesearch实现,生成类别独立的区域建议;
- 特征提取:借助卷积神经网络alexnet实现,从每个区域建议中提取固定长度的特征向量;
- 线性svm实现:输入特征向量,输出每个类别的成绩;
- 边界回归:使用每个类指定的边界框回归器计算候选建议的坐标偏移;
- 非最大抑制:对候选建议做非最大抑制,得到最终的候选建议;
如下是整个系统的框图
前端可视化部分使用PyQt5搭建,为用户提供了基本的输入框、启动程序、最小化、最大化以及关闭按钮。核心部分是前端与后端的交互,前端通过input_box获取待检测视频路径。当用户按下start按钮触发start_function()事件进而调用cat_detector检测器的cat_detector.vedio_detect()方法,该方法将input_box获取到的路径作为参数传递,对目标路径下的视频进行目标检测。
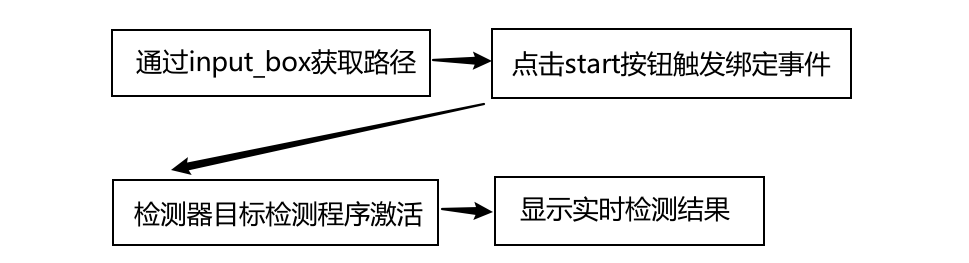
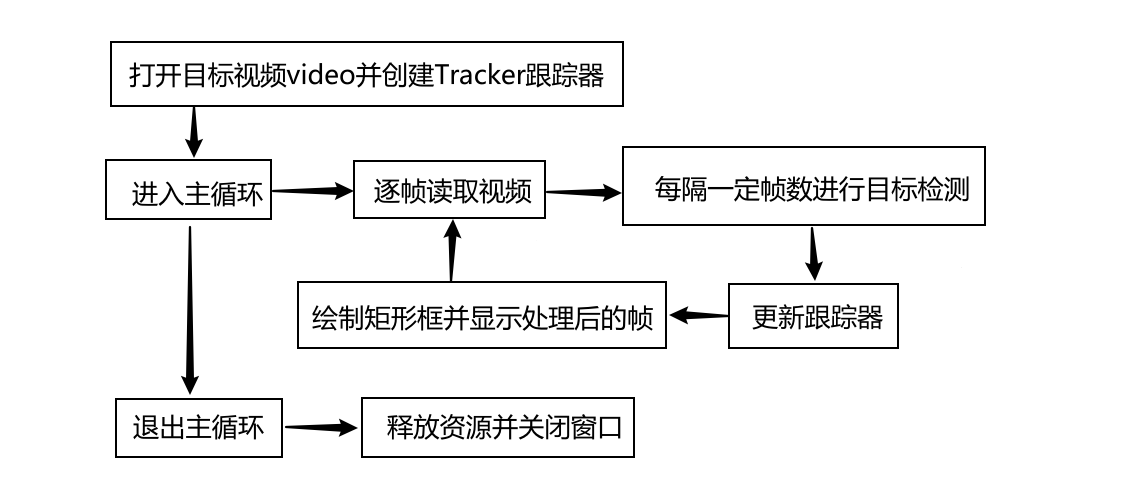
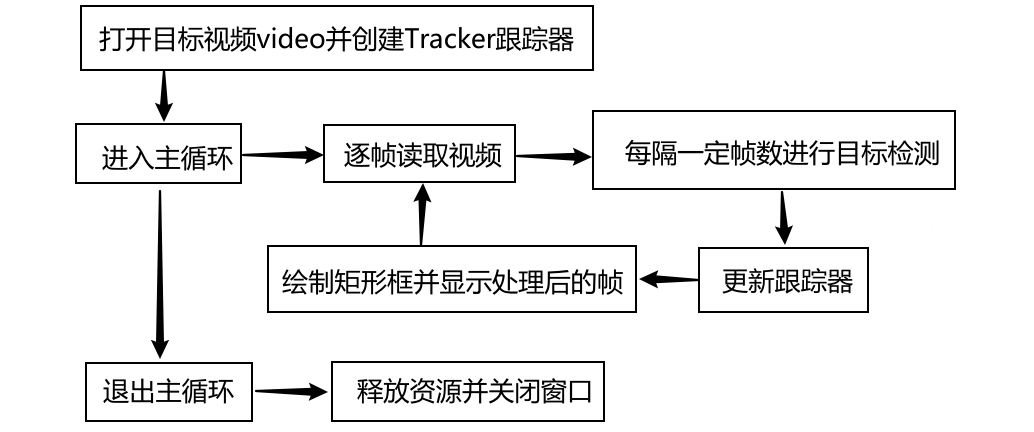
后端逻辑处理部分相对前端较复杂,主要实现对视频中猫的检测和跟踪,核心部分是基于一个while循环,用于逐帧读取视频并进行处理。当cat_detector.vedio_detect()方法被激活后,首先按照传入路径找到并打开目标视频,同时创建一个Tracker对象用于跟踪猫的位置。进入主循环后,逐帧读取视频,由于R-CNN算法本身速度以及电脑GPU性能的影响,一般选择每隔一定帧数进行一次猫的检测而非每帧都进行检测。检测之前需要先将待检测图像存储到指定路径,然后调用目标检测算法pic_detect检测其中猫的位置,如果成功检测到猫的位置则将第一个检测到的猫的位置作为跟踪目标,同时初始化跟踪器。接下来使用跟踪器来更新猫的位置,如果更新成功则根据猫的位置在帧上绘制矩形框进行标记,最后显示处理后的帧并继续循环。
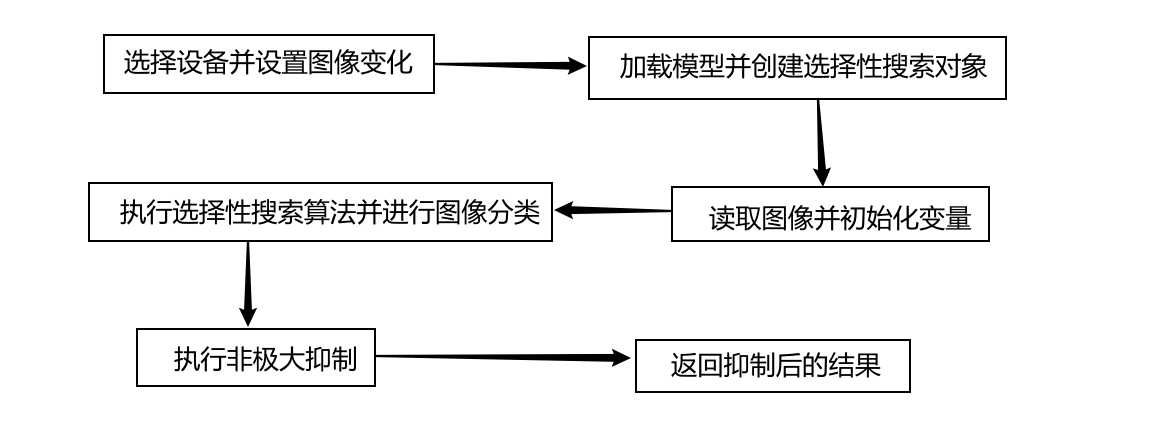
目标检测算法pic_detect是整个后端逻辑处理部分的核心。简单来说,目标检测算法pic_detect通过selective search获取候选框,然后将每个候选框输入到预训练的模型中进行分类,最后使用非极大值抑制来筛选出最终的猫的位置。
3.核心算法设计
整个项目的核心算法是R-CNN目标检测算法,基于该算法整个项目得以实现对图像或视频中猫的检测。R-CNN算法最初只是一个图像检测算法,但是使用一定的技巧可以使得R-CNN应用于一些简单的视频检测。
R-CNN的训练流程如下
- 训练阶段alexnet模型采用的是有监督预训练和特定领域内参数微调的训练方式;
- 提取特征完成后,还需要训练每个类别的svm分类器,完成分类任务;
- 除了分类任务,R-CNN还需要完成定位任务,将alexnet获得的特征向量按照类别分别送入x,y,w,h这四个分量回归器,利用梯度下降计算每个分量回归器的权重。注意在这里特征向量的选择必须是与真实框(Ground Truth)之间IoU大于0.6的对应推荐区域提取出来的特征向量;
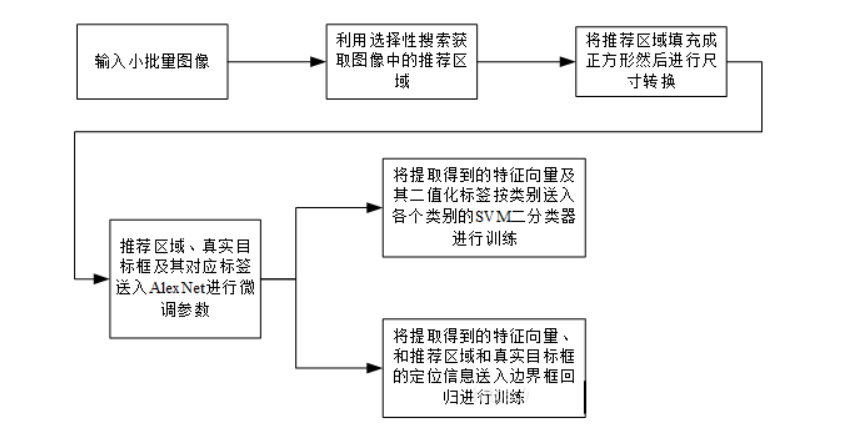
R-CNN的测试流程(即利用训练好的模型进行图像目标检测)如下
- 先利用选择性搜索算法获取目标检测框,同时将目标框填充为正方形并转换为尺寸大小
227*227; - 通过alexnet提取图像特征;
- 利用每个类别训练好的svm二分类器对alexnet提取得到的特征向量的每个类别进行打分,选择最高分为预测类别;
- 将每个类别的特征向量送入每个类别的边界回归器进行定位预测,此时可能产生目标框重叠,故使用NMS删除IoU大于阈值的重复目标框;
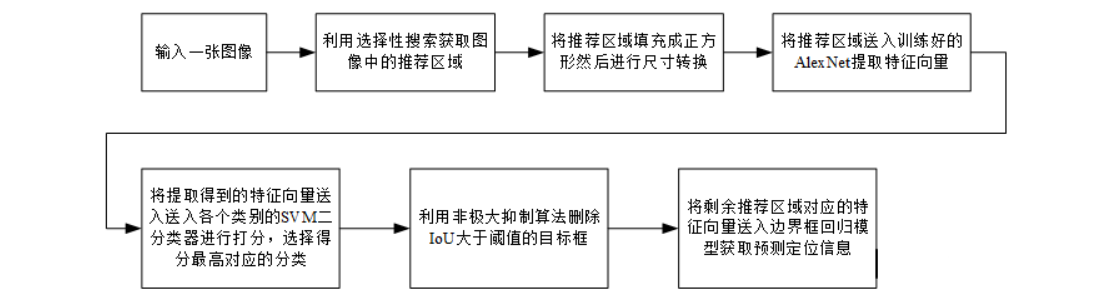
综上,要使用python实现一个完整的基于R-CNN算法对图像中猫进行目标检测的详细流程如下:
1.准备数据集,本项目使用PASCAL VOC 2007数据集
2.数据集预处理
3.区域候选建议:使用选择性搜索算法实现
4.创建自定义数据集合和迭代器用于形成input数据送入网络;
5.卷积神经网络训练:
6.分类器训练:R-CNN完成alexnet卷积模型的微调后,额外使用svm二分类器,采用负样本挖掘的方法进行模型训练
7.边界框回归器训练:使用svm对候选建议进行分类后,使用对应类别的边界框回归器预测其坐标偏移值,进一步提高检测精度
8.目标检测器实现:利用训练好的R-CNN对输入图像进行检测:
本部分将按照上述设计流程依次介绍本项目中的用于检测图像中cat的R-CNN算法原理。
3.1 辅助函数
3.1.1 区域候选算法
在R-CNN架构的第一步就是寻找推荐区域(Region Proposal),推荐区域也被称为ROI(Region Of Interest)。获取推荐区域的方法主要有滑动窗口、规则块和选择性搜索:
- 滑动窗口:本质上就是穷举法,利用不同的尺度和长宽比把所有可能的大大小小的块都穷举出来,然后送去识别,识别出来概率大的就留下来。很明显,这样的方法复杂度太高,产生了很多的冗余候选区域,在现实当中不可行。
- 规则块:在穷举法的基础上进行了一些剪枝,只选用固定的大小和长宽比。但是对于普通的目标检测来说,规则块依然需要访问很多的位置,复杂度高。
- 选择性搜索:规则块的问题在于如何有效去除冗余的候选区域,考虑到冗余候选区域大多是发生了重叠,选择性搜索自底向上合并相邻的重叠区域从而减少冗余。
选择性搜索输入的是彩色图像,输出为候选的目标边界框集合。选择性搜索主要流程分为以下几个步骤:
- 利用felzenszwalb分割算法获取初始区域集合R,同时初始化相似性度量集合S;
- 遍历整个区域集合S,得到所有的相邻区域对(r
i,rj)集合; - 遍历所有区域对(r
i,rj)集合,计算区域ri和rj的相似性度量,同时将该相似性度量加入集合S; - 在S不为空的情况下,进行循环处理,在循环中
- 找到相似性度量最大对应的区域对(r
i,rj); - 将区域r
i和rj合并,记作rt; - 从集合S中删除与区域r
i相邻的其他区域的相似性度量; - 从集合S中删除与区域r
j相邻的其他区域的相似性度量; - 计算区域r
t与其相邻区域之间的相似性度量,将其加入集合S中; - 将区域r
t加入区域集合R;
- 找到相似性度量最大对应的区域对(r
本项目中实现区域候选算法借助的是opencv库,主要分为三部分
使用get_selective_search()获取选择性搜索算法对象
使用config()配置选择性搜索算法
使用get_rects()获取候选区域
1 | |
在调用时先使用get_selective_search()创建selective search对象,然后使用对象的config()方法配置selective search对象(可选模式’s’,’q’,’f’),最后使用对象的get_rects()方法获取selective search返回的候选框列表rects。
3.1.2 批量采集器类
pytorch的五大模块为:数据、模型、损失函数、优化器和迭代训练。其中的数据模块可细分为如下四个部分:
- 数据收集:收集样本和标注标签;
- 数据划分:将收集到的数据划分为训练集、验证集和测试集;
- 数据读取:该部分对应pytorch的Dataloader,而Dataloader包括Sampler和Dataset,其中Sampler的功能是生成索引index,Dataset的功能是根据生成的index读取样本及标签;
- 数据预处理:对应pytorch的transforms;
Dataset、Dataloader和Sampler三个类都是torch.utils.data 包下的模块(类):
- Dataset是数据集的类,主要用于定义数据集
- Sampler是采样器的类,用于定义从数据集中选出数据的规则,比如是随机取数据还是按照顺序取等等
- Dataloader是数据的加载类,Dataset和Sampler会作为参数传递给Dataloader。Dataloader是对于Dataset和Sampler的进一步包装,用于实际读取数据,而Dataset和Sampler则负责定义。模型训练、测试所获得的数据是Dataloader传递的。
Sampler的作用在于生成相应的索引。在DataLoader类的初始化参数里有两种Sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。
Sampler类是一个抽象父类,其主要用于设置从一个序列中返回样本的规则,即采样的规则。所有的采样器(无论是pytorch中已经实现的还是自定义的采样器)都继承自Sampler类。
Sampler是一个可迭代对象,使用step方法可以返回下一个迭代后的结果,因此其主要的类方法就是 iter 方法,定义了迭代后返回的内容。
无论是自定义的Sampler还是pytorch已经实现的Sampler,每次都只会返回一个索引,而在训练时是对批量的数据进行训练,该工作需要BatchSampler来完成。BatchSampler的作用就是将前面的Sampler采样得到的索引值进行合并,当数量等于一个batch大小后就将这一批的索引值返回
CustomBatchSampler类是一个自定义的批量采集器类,主要用于生成用于训练的批量样本。批量采集器根据给定的正样本数量、负样本数量以及正负样本的批量大小,生成相应的样本索引列表,并提供一个迭代器用于按批次获取样本。每个批次由一定数量的正样本和负样本组成,并且在迭代过程中,批量样本的顺序是随机的,有助于增加训练的随机性和多样性,从而提高模型的泛化能力。
1 | |
其中的__iter__(self)迭代方法在每次迭代中都会生成一个新的批量样本,最后返回一个迭代器对象。该方法首先生成正样本的索引列表,并随机化顺序,然后从负样本中随机选择一定数量的索引。然后将正样本和负样本索引列表合并成一个批量样本列表,并对其进行随机打乱。最后将批量样本列表扩展到一个总的样本索引列表中,并返回该列表的迭代器。
3.2 数据集创建
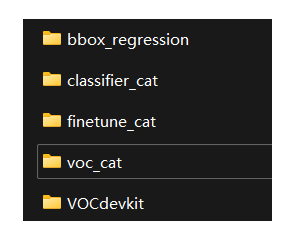
本部分需要实现一个能够检测图像中cat的目标检测器,在开始训练之前需要依次准备如下数据集:
- PASCAL VOC 2007数据集
- 从VOC数据集种提取cat类别数据
- 创建微调数据集
- 创建分类器数据集
- 创建边界框回归数据集
最终的data目录下应该有以下形式的内容
3.2.1 cat类别数据集
VOC 2007数据集可以在PASCAL VOC的官网上下载,下载之后执行create_voc_cat.py文件得到数据集voc_cat,其格式如下
1 | |
目录文件名与VOC数据集的目录文件名意义相同:
- Annotation 文件夹存放的是xml文件,该文件是对图片的解释,每张图片都对应一个同名的xml文件;
- JPEGImages 存放 .jpg格式的图片文件
该部分的核心代码如下,主要用于抽取数据集中的cat类别的数据,作为此次训练对象
1 | |
其中:
- 主函数中先解析了训练集和验证集的样本列表,然后对于每一个集合,创建了一个对应的数据集目录,并调用save_cat函数来保存cat类别的样本图片和标注文件。
- save_cat函数将cat类别的样本图片和标注文件保存到指定的目录中。在这个函数中,首先遍历样本列表,对于每一个样本,将其标注文件和图片文件复制到指定的目录中。这里使用了shutil模块来完成文件复制的操作,同时还使用np.savetxt函数来将cat类别的样本列表保存到CSV文件中。
3.2.2 微调数据集
执行create_alex_dataset.py文件得到finetune_cat数据集,其格式如下
1 | |
这部分主要是针对其中一个类别(cat)的数据,进行2分类的数据处理,为之后对Alexnet进行微调作准备
- 标注边界框:选择voc数据集中某一类别的图片的真实框体(在标注文件中给出)
- 候选建议:使用区域候选方法(选择性搜索算法)选择多个候选框
- 计算候选框与标注边界框的Iou
- 正样本:IoU大于等于0.5;
- 负样本:剩余的候选区域中,IoU大于0,小于0.5且其大小必须大于标注框的1/5;
该部分的核心代码比较简单,在代码文件中有注释故此处不再给出。需要注意的是,在复制文件之后,主函数会调用get_selective_search获取一个选择性搜索器,通过选择性搜索算法提取特征以便用于目标检测模型的训练和测试。
3.2.3 分类器数据集
执行create_svm_dataset.py文件得到classifier_cat数据集,其格式如下
1 | |
分类器数据集为进一步进行svm二分类器的模型训练提供数据,其中
- 标注边界框:选择voc数据集中某一类别的图片的真实框体(在标注文件中给出)
- 候选建议:使用区域候选方法(选择性搜索算法)选择多个候选框
- 计算候选框与标注边界框的Iou
- 正样本:标注边界框;
- 负样本:IoU大于0,小于0.3且其候选建议的大小必须大于标注框的1/5(为了减少负样本的数量);
这部分的整体代码逻辑和微调数据集的代码逻辑类似,其中需要注意:
- parse_annotation_jpeg函数:解析JPEG图片和对应的标注文件,并获取正负样本。该函数会首先读取JPEG图片,并使用选择性搜索算法获取候选建议。然后遍历标注文件中的边界框,对于每一个边界框,计算其与候选建议的IoU值,并根据IoU值的大小将其分类为正样本或负样本。其中,正样本是标注边界框,负样本是IoU大于0,小于等于0.3,且大小必须大于标注框的1/5的候选建议。
3.2.4 边界框回归数据集
利用微调数据集的正样本(IoU>=0.5),再进一步提取IoU>0.6的候选建议(数据集都是正例,故loss都是0)。执行create_bbox_dataset.py文件得到bbox_regression数据集,其格式如下
1 | |
主函数主要通过遍历样本列表,将每一个样本的标注文件和JPEG图片复制到指定的目录中,并从训练集正样本中提取IoU大于0.6的边界框。程序的输出是一个边界框回归器数据集,可以用于训练边界框回归器模型。
3.3 卷积神经网络训练
3.3.1 微调数据集类
Dataset的作用是保存数据集的图片和相应的标签,通过索引能够完成图片的加载以及预处理、标签的加载以及预处理。Datasets是后续构建Dataloader工具函数的实例参数之一。
Dataset 是抽象类,所有自定义的 Dataset 都需要继承该类,并且重写__getitem()__方法和__len__()方法(不覆写这两个方法会直接返回错误) 。__getitem()__方法的作用是接收一个索引,返回索引对应的样本和标签,这是我们自己需要实现的逻辑。__len__()方法是返回所有样本的数量。
CustomFinetuneDataset类继承自Dataset,主要用于加载和处理用于微调alex模型的数据集。CustomFinetuneDataset根据给定的数据集根目录,读取图像和标注文件,提取出目标的坐标和数量,并提供索引方法用于获取图像和目标。通过这个自定义数据集类,可以方便地加载和使用用于微调的数据集,并在训练过程中进行数据增强等操作。
CustomFinetuneDataset类有以下方法和属性
__init__初始化方法,在初始化的过程中,依次解析csv文件以获取所有样本的名称,并读取每个样本的图像以及相应的正负样本标注文件的路径。同时解析标注文件,提取出每个样本中目标的数量和坐标,并计算出正负样本的总数
1 | |
_parse_annotation方法用于解析标注文件。该函数接收标注文件路径列表作为输入,在解析过程中遍历所有样本的标注文件,读取坐标信息,并将坐标存储在rects列表。根据样本中目标数量的不同分别对目标的坐标和数量进行处理,最后返回目标数量和坐标的列表
1 | |
__getitem__索引方法,主要用于获取指定索引位置的样本和目标。该索引方法根据索引的大小与正样本的总数进行比较,确定是正样本还是负样本。如果是正样本,它通过索引获取正样本的坐标索引和图像索引,并从正样本坐标列表中获取相应的坐标。如果是负样本,它通过索引计算负样本的索引,并获取负样本的坐标索引和图像索引,然后从负样本坐标列表中获取相应的坐标。最后,它根据图像索引从图像列表中获取相应的图像,并根据坐标裁剪出目标区域,同时对数据进行增强操作。
1 | |
__len__:返回数据集的总样本数量,即正样本和负样本的总和。get_positive_num:返回正样本的数量。get_negative_num:返回负样本的数量。_get_rect_index_and_image_id方法,用于根据索引获取坐标索引和图像索引,在遍历过程中根据索引的范围确定目标所在的样本和目标在样本中的索引,然后返回目标的坐标索引和样本的图像索引
1 | |
3.3.2 微调实现
微调模型采用的是pytorch提供的alexnet预训练模型,使用finetune的方法继承alexnet的网络模型和参数,微调alexnet网络使其能够实现2分类。
本项目中对alexnet预训练模型进行微调的主要步骤如下:
- 加载模型及数据
- 确定训练设备(CPU or GPU)
- 加载数据集,返回dataloader和dataset_size;
- 加载预训练alexnet模型;
- 获取分类器最后一层的输入特征数,这个特征数将作为全连接层的输入尺寸;
- 将分类器的输出特征数改为2,以适应微调的新任务,其中2是新任务的类别数;
- 转移模型到第一步选择的设备上;
- 定义参数
- 定义交叉熵损失函数;
- 定义随机梯度下降优化器并设置学习率和momentum,用于更新模型参数;
- 定义StepLR调度器学习率调度器,用于动态调整学习率;
- 训练模型并将训练好的最佳模型参数保存到文件中;
微调部分有两个主要的函数,load_data数据加载函数和train_model模型训练函数。
其中load_data数据加载函数接收数据集的根目录路径以及批量大小和工作线程,返回训练和验证数据加载器以及它们各自的数据集大小。通过应用数据转换、创建自定义数据集和批次采样器,并使用DataLoader创建数据加载器,实现了数据的加载和准备,为训练和验证提供了经过预处理的数据,并通过采样器平衡了正负样本的数量。
1 | |
train_model模型训练函数就是常见的训练流程:在每个epoch中遍历训练集和验证集,通过遍历数据加载器中的数据,将输入数据和标签移动到指定设备上(GPU/CPU),通过前向传播获得模型的输出。根据是否为训练阶段,计算损失、进行反向传播和参数更新,同时累加损失和正确预测的样本数。然后计算当前阶段的平均损失和准确率并输出。
1 | |
3.4 分类器训练
在完成对alexnet预训练模型的微调后,额外使用svm二分类器,采用负样本挖掘的方法进行模型训练(linear_svm.py)
- 先取得和正例相同数目的负例作为训练样本;
- 进行第一轮训练并计算出准确率和loss,根据验证集准确率表现,同时判断是否可以存储为最好的模型参数;
- 进行难分辨负样本挖掘,将挖掘好的难分辨负样本数据加到负样本总数据中,进行下一轮训练;
- 经过多轮训练,存储一个最好的二分类器;
3.4.1 二分类数据集类
__init__方法用于创建svm数据集类,加载图像和对应的正负样本标注。主要设计流程如下
- 使用parse_cat_csv函数解析包含猫样本信息的CSV文件,获取样本列表;
- 初始化存储图像、正样本和负样本的空列表;
- 遍历样本列表,对每个样本进行处理;
- 通过样本名称拼接图像路径,并借助OpenCV的imread函数读取图像,将图像添加到jpeg_images列表中;
- 构建正样本标注路径,加载标注信息到positive_annotations数组中;
- 检查正样本标注数组的形状
- 如果是一维数组且长度为4,则表示只有一个正样本标注。创建包含边界框和图像ID的字典,将其添加到positive_list列表中;
- 如果正样本标注数组的形状是二维数组,则表示有多个正样本标注。对于每个正样本标注,创建包含边界框和图像ID的字典,将其添加到positive_list列表中;
- 类似地,处理负样本标注,将负样本的边界框和图像ID添加到negative_list列表中;
- 完成样本列表的遍历和处理后,数据集类的实例就包含了图像和对应的正负样本标注,可以在训练或测试中使用;
其相关代码实现如下
1 | |
二分类数据集类的__getitem__方法根据给定的索引从数据集中获取对应的图像和标签,核心算法原理如下:
函数接收index索引,首先对索引进行判断:
- ```py
if index < len(self.positive_list): # 如果索引小于正样本数量
target = 1 # 标签为1
positive_dict = self.positive_list[index] # 获取正样本
cache_dict = positive_dict # 缓存字典
else:
target = 0 # 标签为0
idx = index - len(self.positive_list) # 获取负样本索引
negative_dict = self.negative_list[idx] # 获取负样本
cache_dict = negative_dict # 缓存字典1
2
3
4
5
6
7
8
9
10
11
12
13
- 如果索引小于正样本的数量,则表示要获取的是正样本。依次将目标标签设置为1并获取对应索引的正样本字典并将其存储在缓存字典中;
- 否则,表示要获取的是负样本,处理同上;
2. 接着从缓存字典中获取图像id和标注框的坐标。使用获取到的id和坐标从jpeg_images列表中获取对应的图像片段
- ```py
image_id = cache_dict['image_id'] # 获取图片id
xmin, ymin, xmax, ymax = cache_dict['rect'] # 获取标注框
image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax] # 获取图片
- ```py
如果有transform操作则进行transform,否则返回图像、目标标签和缓存字典
3.4.2 难例挖掘数据集类
自定义的难例挖掘类CustomHardNegativeMiningDataset继承自Dataset,主要用于难例挖掘任务中构建难例挖掘的Dataset。
类的构造函数__init__接收负样本列表、JPEG图像列表以及bool类型的transform,并将其存储在实例变量中。其中最核心的__getitem__方法根据给定的索引来获取数据集中的样本。
1 | |
依次从负样本列表中获取对应索引的负样本字典、从负样本字典中获取负样本矩形框的坐标和负样本图像的id、使用负样本图像ID和矩形框的坐标从JPEG图像列表中获取对应的负样本图像,最后将获取到的负样本图像、目标标签以及负样本字典作为样本结果进行返回。
3.4.2 分类器实现
线性svm分类器包含线性回归和折页损失hinge_loss,其中hinge_loss根据模型的输出和真实的标签来计算折页损失。它首先获取正确类别的得分,然后计算得分与模型输出的差值加上边界间隔,最后取所有样本的最大间隔项并计算平均值作为折页损失。
1 | |
线性svm分类器的训练采用了难例挖掘的方法,其实现流程如下:
- 设置初始训练集,正负样本数比值为
1:1(以正样本数目为基准) - 每轮训练完成后,使用分类器对剩余负样本进行检测,如果检测为正,则加入到训练集中
- 重新训练分类器,重复第二步,直到检测精度开始收敛
训练过程的核心部分对训练和验证过程进行了迭代,根据当前是训练还是验证阶段,设置模型为训练模式或验证模式。
然后使用一个循环迭代数据加载器中的每个batch。在每个batch中,将输入数据和标签移动到设备(如GPU)上,并执行前向传播、计算损失、反向传播和参数更新等操作,同时记录损失和正确的样本数。
在每个epoch的末尾,计算平均损失和准确率,并打印结果。如果当前是验证阶段,并且当前的验证准确率超过了之前保存的最佳准确率,则更新最佳准确率和最佳模型权重。
1 | |
下面这部分代码用于进行难例挖掘(负样本挖掘)。获取了训练集、剩余负样本列表、训练数据集的图像和transform后,使用剩余负样本列表构建一个新的数据集,并创建一个数据加载器用于遍历这个数据集的batch。在每个batch中,执行前向传播,计算预测结果,并记录正确的样本数。然后根据预测结果和缓存字典获取困难负样本和容易负样本,并将困难负样本添加到训练数据集的负样本列表中。最后计算剩余负样本的准确率并打印,同时更新训练数据集的负样本列表,并相应地更新训练数据集的大小。
1 | |
Q:什么是折页损失?
A:简单来讲,折页损失是混淆矩阵的一部分,主要用于那些在不同类型错误(假正例和假负例)之间有不同代价的分类问题。例如,在医学诊断中,将一个患者错误地诊断为健康(假负例)和将一个健康患者错误地诊断为患病(假正例)可能会有不同的严重后果。因此,可以使用折页损失来权衡这些不同类型的错误。
3.5 边界回归训练
目标检测相较于传统的图像分类,不仅需要实现对目标的分类,还需要解决目标的定位问题(即获取目标在原始图像中的位置信息),R-CNN利用边界框回归来预测物体的目标检测框。
3.5.1 边界回归数据集类
BBoxRegressionDataset数据集类同样继承自Dataset类,用于加载图像和边界框数据,并提供了对应的图像裁剪和边界框回归目标的计算。
BBoxRegressionDataset类主要有以下几个类函数、
__init__构造函数用于初始化类实例,根据接收的根目录和transform加载图像、边界框和正样本数据。__len__函数返回数据集的样本数量。__getitem__函数获取数据集中的索引为index的样本。- 根据索引从self.box_list中获取图像ID、正样本和边界框
- 根据图像ID获取对应的图像,同时借助正样本的坐标从图像中裁剪出对应的区域
- 计算正样本和边界框之间的平移比例和尺度比例,并返回处理后的图像和边界框回归目标
1 | |
get_bndbox函数根据正样本和边界框计算IOU分数- 如果边界框是一维数组,则直接返回边界框;
- 如果边界框是二维数组,则计算每个边界框与正样本的IOU分数,返回具有最高分数的边界框;
- 如果边界框是一维数组,则直接返回边界框;
这个函数用于在存在多个边界框时选择最匹配的边界框
1 | |
3.5.2 边界回归实现
使用svm对候选建议进行分类后,使用对应类别的边界框回归器预测其坐标偏移值,进一步提高检测精度
通过提高IoU阈值(>0.6)过滤正样本候选建议,将候选建议和标注边界框之间的转换看成线性回归问题,并通过岭回归(ridge regression)来训练权重w;
在读取alexnet的网络的基础上,冻结住alexnet的网络,并且取得alexnet中feature层的输出,送入一个线性的计算的模型,计算出4个输出,用于衡量偏移情况;
进行框体的非极大抑制的处理;
边界框回归训练使用的优化器和损失函数分别是Adam优化器和均方误差损失函数,基本的训练步骤为:
- 调用load_data加载bbox_regression数据集的数据加载器;
- 选择训练设备;
- 调用get_model函数加载CNN模型;
- 计算输入特征的维度并设置输出特征的维度(用于边界框回归);
- 创建线性模型、均方误差损失函数、Adam优化器、学习率衰减器;
- 开始训练,训练完毕后绘制损失曲线
3.6 检测器实现
利用已经实现的R-CNN目标检测算法遵循以下步骤可以实现一个对图像中猫的检测:
- 输入图像;
- 使用选择性搜索算法计算得到候选建议;
- 逐个计算候选建议:
- 使用alexnet模型计算特征
- 使用线性svm分类器计算得到分类结果
- 对所有分类为cat的候选建议执行非最大抑制;
这部分主要对应于cat_detector中的pic_detect部分,在流程图中也就对应R-CNN的测试流程。检测器代码的执行步骤主要为:
- 准备阶段
- 选择设备并将加载好的模型放在设备上;
- 加载图像;
- 创建并配置selective search对象,将其用于图像获取候选框列表
- 对于每个候选框,从原图像中截取对应的区域并使用transform进行转换
- 将处理后的图像输入模型,获取输出结果
- 设置svm阈值并创建空列表,用于存储检测到的目标框和对应的分类score
- 如果输出结果中最大值的索引为1,表示猫的概率最高,加入positive_list列表
- 执行非极大值抑制,对positive_list中的矩形框进行非极大值抑制
1 | |
4.系统实现
通过前面的介绍,我们已经得到了一个可用于图像中cat检测的目标检测器cat_detector,下面我们介绍系统的其他部分的实现。最后通过组合本部分介绍的其他组件,可以得到完整的实时目标检测系统。
4.1 视频检测器
要基于图像检测器实现一个能对视频中的猫做检测的视频检测器,基本的思想是将视频中的帧抽取出来,对帧中的物体进行图像检测后将检测结果返回,使用tracker跟踪器持续更新检测出物体的位置。
这里需要注意tracker的选择,一开始选择使用cv2的TrackerCSRT_create对象发现效果并不好,绘制的矩形框与实际图像检测出的矩形框大小和位置都不同,后来切换为TrackerKCF_create后检测效果有明显的提升。
1 | |
实现视频检测器的核心就是在while循环中逐帧读取视频并进行处理
1 | |
4.2 前端可视化
前端可视化界面的实现基于Pyqt5,关于可视化界面的搭建可以使用designer设计师拖拽组件实现,难点在于绑定按钮的激活函数
1 | |
start_function函数与start按钮绑定
1 | |
当检测到clicked行为被触发后,相应的start_function函数会开始执行。start_function函数主要检测从输入框中输入的检测函数是否符合标准,如果不合规则向用户提示相应错误并要求重新输入,仅当用户输入合法的视频文件路径时,调用cat_detector类的vedio_detect视频检测函数进行视频检测,并将结果返回在屏幕中
5.实验
5.1 单元测试
5.1.1 批量采集器类
test用于演示一个数据集的自定义批量采样器的用法和功能
1 | |
分别输出了批量采集器的长度、数量以及单批量中正样本的个数
1 | |
test2演示了如何使用transforms.Compose()对数据集进行转换,创建一个带有自定义采样器的DataLoader对象,并从DataLoader中检索成批的数据
1 | |
分别输出标签targets以及输入张量的形状
1 | |
5.1.2 微调数据集类
test演示如何使用CustomFinetuneDataset类来访问数据集中的特定项目,检索其目标标签,并将图像转换为PIL图像对象
1 | |
输出如下
1 | |
5.1.3 二分类数据集类
如下代码使用CustomClassifierDataset类来访问数据集中的特定项目,检索它们的目标标签,检索相关的字典,并将图像转换成PIL图像对象
1 | |
输出如下
1 | |
5.1.4 边界回归数据集类
类似的,下面使用BBoxRegressionDataset类来访问数据集中的特定项目,检索图像和目标值,并使用transforms.Compose()应用数据转换,并输出关于数据集的长度以及检索的图像和目标的形状和数据类型。
1 | |
输出如下
1 | |
接着测试Dataloader的使用
1 | |
输出如下
1 | |
5.1.5 难例挖掘数据集类
1 | |
输出如下
1 | |
5.1.6 区域候选算法
区域候选算法输入的是彩色图像,输出为候选的目标边界框集合
1 | |
将输出框绘制在原图上

5.2 核心算法评价
5.2.1 卷积神经网络
微调部分的参数设置如下:
- load_data:批量大小128,工作线程数8,即每次训练128个图像,其中32个正样本,96个负样本
- SGD优化器:学习率为0.001,动量为0.9
- 学习率调度器: step_size=7,gamma=0.1,即每经过7个epoch,将学习率乘以0.1
- 训练epoch:25轮
先来看一下训练结果,可以看到模型在训练过程中出现了过拟合的情况,有条件的话可以尝试减小学习率、添加L2权重衰减或使用其他优化器进行优化(因为训练一次需要的时间太长了,所以我后面使用的还是此处训练好的模型并没有额外进行优化训练)
1 | |
5.2.2 SVM分类器
本部分的训练参数设置如下:
- load_data:每次训练128个图像,其中32个正样本,96个负样本
- 优化器:学习率1e-4、动量0.9
- 学习率调度器:每隔4轮衰减一次,参数因子α=0.1
- 训练epoch:10
训练结果如下,可以看到,从第二个epoch开始,分类器的损失开始收敛
1 | |
5.2.3 边界回归
边界回归的训练结果如下(边界框回归的训练效果相对来说不是很好,可能是数据的问题)
1 | |
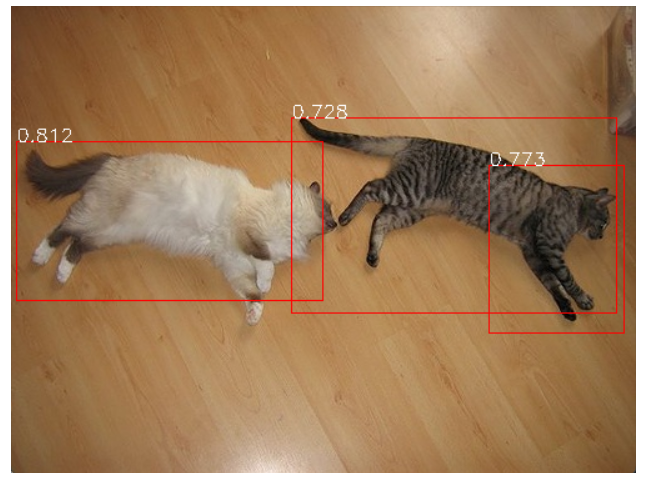
5.2.4 目标检测器
目标检测器主要分为两个部分,第一个部分是对图片进行检测,第二个部分是将对图片进行检测的函数与tracker跟踪器结合实现对视频的检测
1 | |
测试阶段同样分为对图片的检测和对视频的检测,测试结果会以图片以及视频帧的形式分别返回

5.3 系统测试
Cat_Detector目标检测系统启动后的可视化界面如下
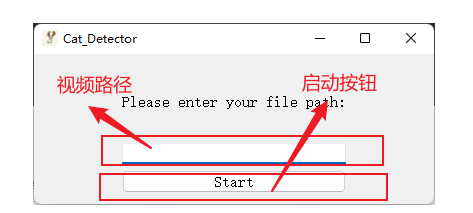
左上角分别是该系统的图标(吉祥物“鹿哥”)以及该系统的名称“Cat_Detector”,右上角分别是“最小化”、“最大化”和“关闭程序”按钮。
界面的中间有一个“视频路径”输入框和Start“启动按钮,系统要求在“视频路径”输入框输入合法的视频路径。假如不输入任何视频路径点击“Start”,会提醒输入文件路径
假如输入的视频路径不存在,会提示文件不存在
假如输入的文件路径不是视频文件,会提示错误并要求重新输入
仅当输入完整并且正确的视频路径时,点击“Start”按钮会开始进行视频检测(程序的响应速度取决于电脑性能),点击“Start”按钮之后系统的运行逻辑如下
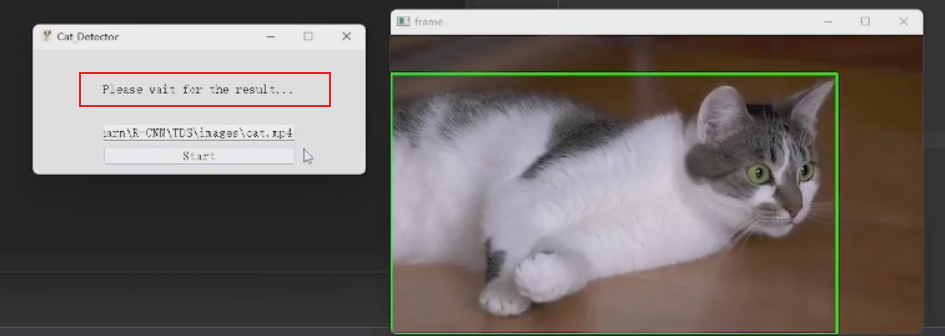
程序响应后会弹出检测视频以及在检测视频中使用矩形框标注出猫的位置(检测视频参考根目录下的.mp4文件)
6.结论
从整体上看,我们的Cat_Detector目标检测系统能够实现基本的实时目标检测,并且上手简单没有技术门槛,这是相对于当前市面上众多实时检测系统的一大优势。但是从开发者的角度来说,我认为这套系统还存在一定的不足。首先是用户界面功能不够完善,如保存历史识别信息、进行摄像头实时监测等。其次是因为底层使用的检测算法是R-CNN,这个算法的速度较慢,一般用于对图像的检测,不是特别适合用于对视频进行检测,可以考虑使用YOLO系列的检测算法或Faster-RCNN等升级算法实现更快速、更精确的视频检测。另一方面,因为网络参数设置以及训练算力的限制,本系统使用的R-CNN模型并没有发挥出全部的实力。最后,本系统可以进一步的延展,考虑不仅仅是对猫进行检测,也可以对其他更多的物体进行检测,这需要更多的训练数据以及更多的训练时间。这些都是系统还可以改进的地方。总之,本次实现的Cat_Detector目标检测系统具备基本的功能,但还需再接再厉。