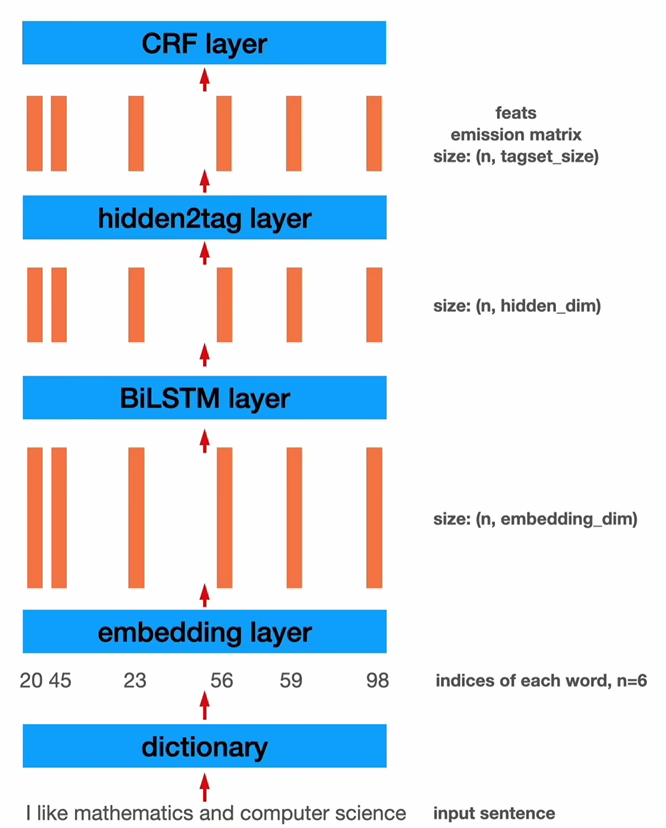
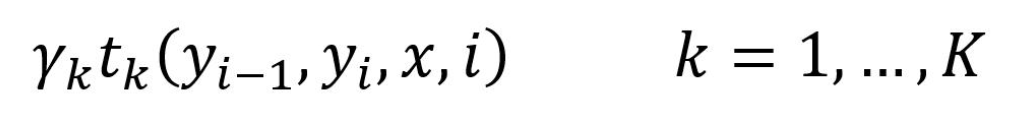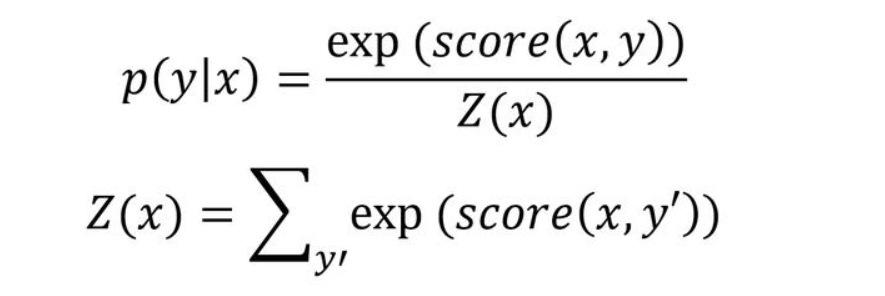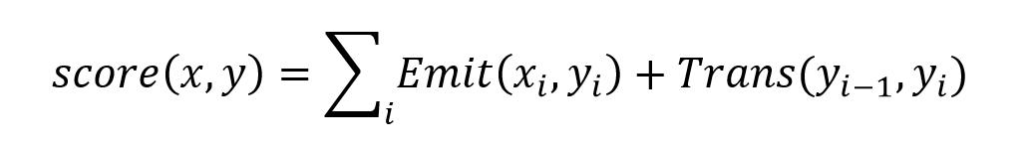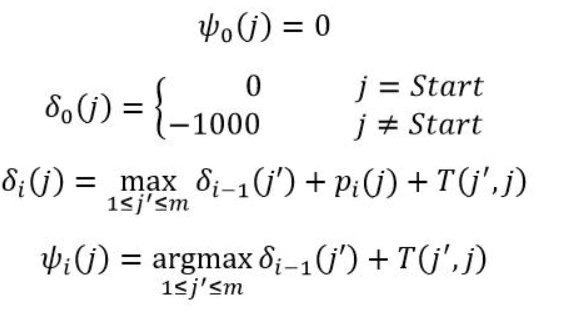2023/5/19 15:04 先简单说一下,自然语言处理这个课程作业和先前知识图谱的课程作业几乎是相同的,但是知识图谱的那次作业的时间距离已经过去了两个月,而且我今天在查看的时候发现当时做的笔记不是特别的好。因此趁着这次完成自然语言处理作业的时间来对命名实体识别这一任务做一个复盘和深化理解。关于参考,网上找来找去实际上也就那么几份参考代码,因此现在暂时使用的还是之前知识图谱参考的代码(毕竟别人是手动进行实现的,环境为电脑上的tf1环境,具体训练模型的时候记得丢到Kaggle上进行训练);关于参考代码中的数据集,github作者提供的三个数据集实际上和我们需要处理的数据都相差较大,而知识图谱那次作业中数据处理作为参考是相当可以的(毕竟那是我经过精挑细选之后确定的方案);
2023/5/20 14:40 调整了很久也没有调好之前的参考模型,直接重开 – tmd找不到其他代码,重开都没法重开啊(硬着头皮用原来那个项目);
2023/5/20 21:36 人家代码一点问题都没有,是你自己没有搞清楚标注的情况,稀里糊涂的使用别人的代码,这才造成了无限循环的情况;
2023/5/22 10:02 说实话我都没想过这次这个作业可以花费这么长时间,本来觉得这是知识图谱做过的作业,可能可以节约很多时间直接运行完毕就行了,没想到正是因为是知识图谱做过的作业,导致我过度依赖之前做作业时候的笔记以及思想,进而丢失了自己对于不同任务的理解,因此在一些很显而易见的错误问题上折腾了非常多的时间。另一方面,对于资料的整理需要更加细心,越细心的对于资料的整理能够在未来为你带来越多的便利。好在现在几乎一切都解决完毕,只需要最终将训练好的模型下载下来并进行对test文本进行标注即可;
2023/5/22 11:26 写完实验报告之后,检查一下这次作业涉及的所有资料,然后把需要上交的资料打包上交;
一、背景介绍 1.NER概述 知识抽取是实现自动化构建大规模知识图谱的重要技术,其目的在于从不同来源、不同结构的数据中进行知识提取并存入知识图谱中(详情参考知识图谱 - Tintoki_blog (gintoki-jpg.github.io) );知识抽取同样属于NLP的研究领域,指自动化地从文本中发现和抽取相关信息,并将多个文本碎片中的信息进行合并,将非结构化数据转换为结构化数据;
非结构化数据的知识抽取包括命名实体识别、关系抽取及事件抽取,本项目主要针对其中的命名实体识别;
命名实体识别是指从文本中检测出命名实体,并将其分类到预定义的类别中,例如人物、组织、地点、时间等;一般情况下,命名实体识别是知识抽取其他任务的基础;
想要从文本中进行实体抽取,首先需要从文本中识别和定位实体,然后再将识别的实体分类到预定义的类别中去 – 这也是本项目需要实现的,即实体的识别和抽取;
实体抽取的方法分为三类:基于规则的方法、基于统计模型的方法和基于深度学习的方法,因为规定使用深度学习,所以我们这里仅介绍该类方法,另外两类可参考小知识 | 知识图谱:知识抽取之命名实体 (qq.com) ;
1.1 基于深度学习的方法 与传统统计模型相比,基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征;
目前,用于命名实体识别的神经网络主要有卷积神经网络(ConvolutionalNeural Network, CNN)、循环神经网络(Recurrent Neural Network, RNN)以及引入注意力机制(AttentionMechanism)的神经网络;一般地,不同的神经网络结构在命名实体识别过程中扮演编码器的角色,它们基于初始输入以及词的上下文信息,得到每个词的新向量表示;最后再通过CRF模型输出对每个词的标注结果;
一些比较经典的用于实体识别抽取的模型有
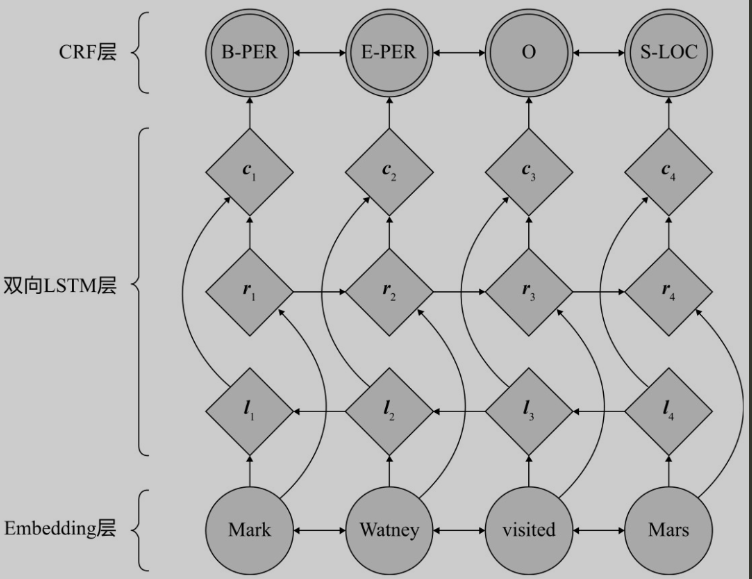
LSTM-CRF命名实体识别模型
该模型使用了长短时记忆神经网络(Long Shot-Term Memory NeuralNetwork, LSTM)与CRF相结合进行命名实体识别。
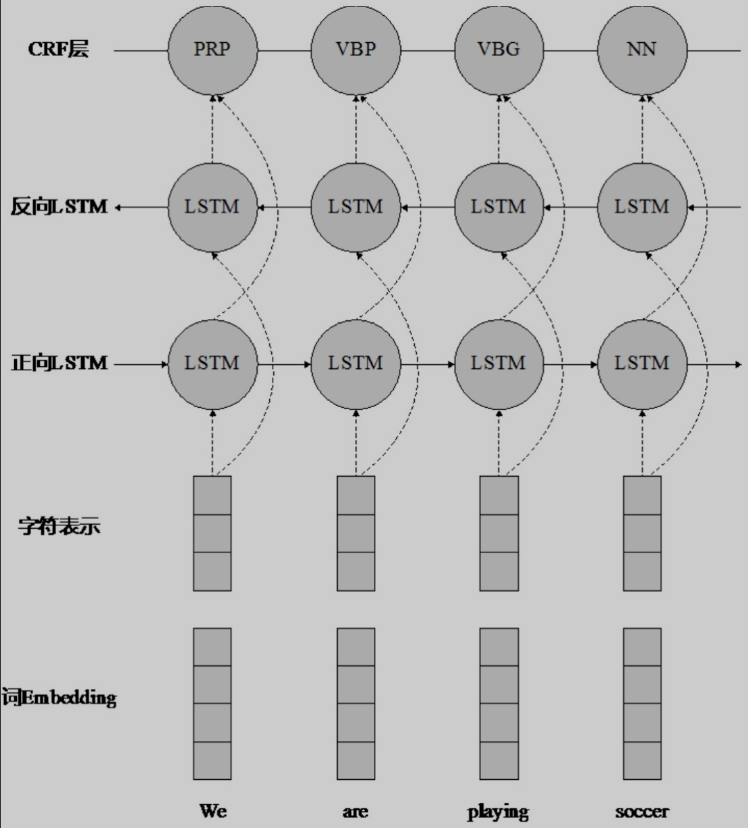
LSTM-CNNs-CRF序列标注模型框架
该模型与 LSTM-CRF 模型十分相似,不同之处是在Embedding 层中加入了每个词的字符级向量表示。
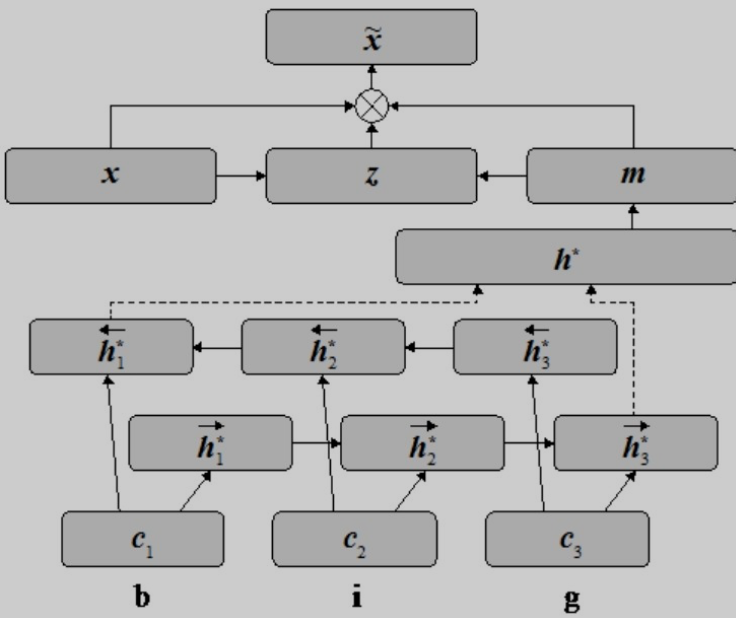
基于注意力机制的词向量和字符级向量组合方法
注意力机制可以帮助扩展基本的编码器-解码器模型结构,让模型能够获取输入序列中与下一个目标词相关的信息。
基于注意力机制的词向量和字符级向量组合方法认为除了将词作为句子基本元素学习得到的特征向量,命名实体识别还需要词中的字符级信息。因此,该方法除了使用双向 LSTM 得到词的特征向量,还基于双向LSTM计算词的字符级特征向量。
2.中文命名实体识别 2.1 中文分词 中文命名实体抽取需要先了解基于字标注的中文分词,简单的中文分词我们知道形式如下
基于字标注的中文分词结果如下
基于字标注的意思就是给每个字都进行标注,上述标注的类型主要有四种
词首即一个词的开始,词尾即一个词的结束,词中表示词中间的词,假如该词只有一个字则用单字表示;
注意,序列标注任务首先需要确定的就是,定义标注策略,即使用什么样的格式对序列进行标注。常见的序列标注有
BIO格式:B表示一个命名实体的开始,I表示一个命名实体的其他部分,O表示一个非命名实体单元;
BMEWO格式:B表示命名实体的开始,M表示中间部分,E表示结束,O表示非命名实体单元,W表示整个单词是一个命名实体(上面例子中的标注使用的就是没有W的BMEOW格式标注);
不同的标注策略对后续任务的影响不同,需要注意使用不同的标注策略时,相应的处理方法也需要改变。
2.2 数据处理 实体识别和中文分词类似,就是将不属于实体的字用O标注,把实体用BME规则标注,最后按照BME规则将实体提取出来即可;
下面是一个实体识别的例子
每个实体用都用大括号括了起来,并标明实体类别(标注方式并不需要严格遵守这样的键值格式,只要能将实体识别并提取出来即可)
因为下面的例子都是基于玻森数据提供的命名实体识别数据,与我们项目本身提供的数据集可能存在一些差别,所以先简单介绍一下玻森数据集,主要包含以下6个实体类别
数据处理首先要做的就是把原始数据按照BMEO的规则变成字标注的形式便于模型训练,上述文本按字标注后的结果如下(可以看出这不仅仅只是简单的字标注分词,同时结合了实体类别)
接着习惯性的,按照标点符号将一个长句子分为多个短句子(逗号、句号、双引号等),结果如下
与先前新闻文本分类相同,因为无法直接将文本类型的数据放入模型训练,因此需要先建立一个word2id词典,将每个汉字转换成id(最直观的做法就是按照数据集中中汉字出现的次数进行排序后赋id,id从1开始)
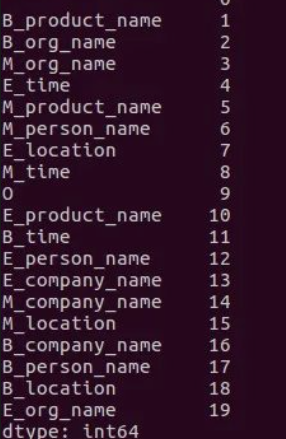
将汉字转换为id后,再建立一个tag2id词典,将每个字标注的类型转换成id(这里的id从1开始,顺序可以自定义,因为3*6+1所以一共19个tag对应的id)
拥有了word2id和tsg2id之后,就可以将先前按照标点切分的短句以一一对应的顺序将汉字和每个字的标签转换为id,分别存放在两个数组中,将该数组保存在同一个pkl文件中,这样模型使用时候就可以直接读取,不用每次都处理数据了;
这里习惯把每一句话都转换成一样的长度(这与先前新闻文本分类是一个道理),这个长度可以自定义(最好统计后再确定),比它长的就把后面舍弃,比它短的就在后面补零。
比如下面是长度为10的文本对应的word2id和tag2id,将这两个数组保存在同一个pkl文件中,作为训练模型时的输入数据
1 2 [132,45,0 ,456,432 ,8,654,3 ,0 ,0 ]1,2,2,2 ,3,4,5,5 ,0 ,0 ]
Q:为什么这里是按照字的粒度而不是词的粒度划分?词向量和字向量的区别在哪里?
A:词向量和字向量都是自然语言处理中常用的表示文本的方式,但它们的表示粒度不同。
词向量(Word Embedding)是将每个单词表示为一个向量(因此使用词向量之前需要进行分词),这个向量通常是一个固定长度的实数向量,每个维度代表着该单词在不同语义维度上的分布情况。词向量的好处是能够捕捉到单词之间的语义关系,例如在词向量空间中,语义相近的单词的向量距离较近。常用的词向量算法有word2vec、GloVe等。
字向量(Character Embedding)则是将每个字母或字符表示为一个向量。相比于词向量,字向量的表示粒度更细,可以更好地捕捉词语的构成和形态等信息,特别适用于中文和其他一些没有明确词汇边界的语言。常用的字向量算法有FastText、CharCNN等。
因此,词向量适用于处理基于单词的任务,如文本分类、情感分析、机器翻译等,而字向量适用于处理基于字符的任务,如中文分词、命名实体识别等。
综上,对于本次任务使用字向量更合适。
3.BiLSTM-CRF介绍 参考链接:彻底了解 BiLSTM 和 CRF 算法-pytorch bilstm crf (51cto.com) ;
BiLSTM-CRF是一种序列标注模型,常用于自然语言处理领域的命名实体识别、词性标注等任务。其全称为Bidirectional Long Short-Term Memory - Conditional Random Field,结合了双向长短时记忆网络(Bidirectional LSTM)和条件随机场(CRF)两个模型的优点,能够克服单向LSTM模型无法处理双向上下文信息的问题,同时能够利用CRF模型的全局标注优化策略来提高模型的准确性。
BiLSTM模型是一种递归神经网络,它可以学习长文本序列中的特征,具有前向和后向两个方向的传播。与传统的单向LSTM模型相比,它能够捕捉到上下文中的更多信息,有利于提高模型的准确性。而CRF模型则是一种概率图模型,能够通过考虑全局标注的约束条件来优化模型的输出结果,进一步提高模型的准确性。
在BiLSTM-CRF模型中,BiLSTM用于学习上下文特征,将上下文特征序列作为CRF的输入,CRF则用于学习标签之间的转移概率,从而能够更好地对标注序列进行建模,从而实现更准确的序列标注任务。
为什么不单独使用 BiLSTM 进行标注?BiLSTM 可以预测出每一个字属于不同标签的概率,然后使用 Softmax 得到概率最大的标签,作为该位置的预测值。这样在预测的时候会忽略了标签之间的关联性,例如 BiLSTM 在作分词任务时,将某句话的第一个词预测为动词,紧接着的第二个动词同样被预测为动词,而实际上动词后面不能直接跟动词,因此 BiLSTM 没有考虑标签间联系。此时需要 在 BiLSTM 的输出层加上一个 CRF,使得模型可以考虑类标之间的相关性,标签之间的相关性就是 CRF 中的转移矩阵,表示从一个状态转移到另一个状态的概率。
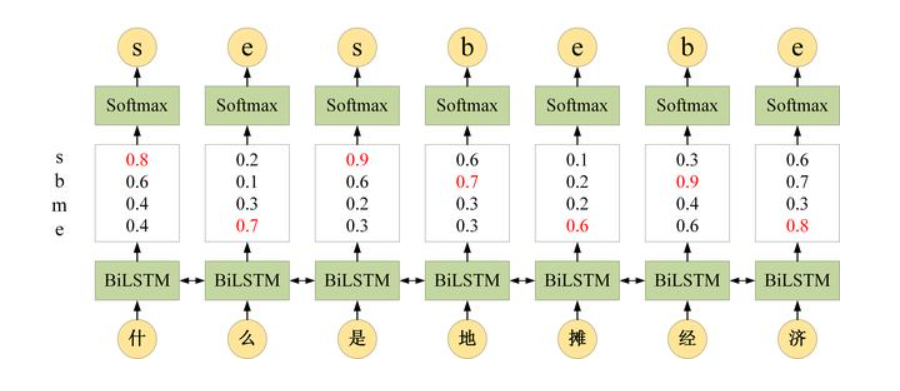
参考如下分词任务,每个字对应的标签可以是s,b,m,e四种中的任意一个。给定一个句子“什么是地摊经济”,其正确的分词方式应该是“什么/是/地摊/经济”,对应的分词标签应该是“be/s/be/be”
单独使用BiLSTM时,BiLSTM 可以预测出每一个字属于不同标签的概率,然后使用 Softmax 得到概率最大的标签,作为该位置的预测值。但是单独使用BiLSTM进行预测会忽略标签之间的关联性,上图中BiLSTM将“什”预测为“s”,“么”预测为“e”,但是从语法角度来说,“s”标签的字后面是不会出现“e”标签的字的。如果在使用BiLSTM进行预测的同时加入这种考虑标签之间联系的信息,得到的效果必然会比单独使用BiLSTM要好。因此将BiLSTM的特征抽取及拟合能力与CRF模型的全局标注优化策略结合
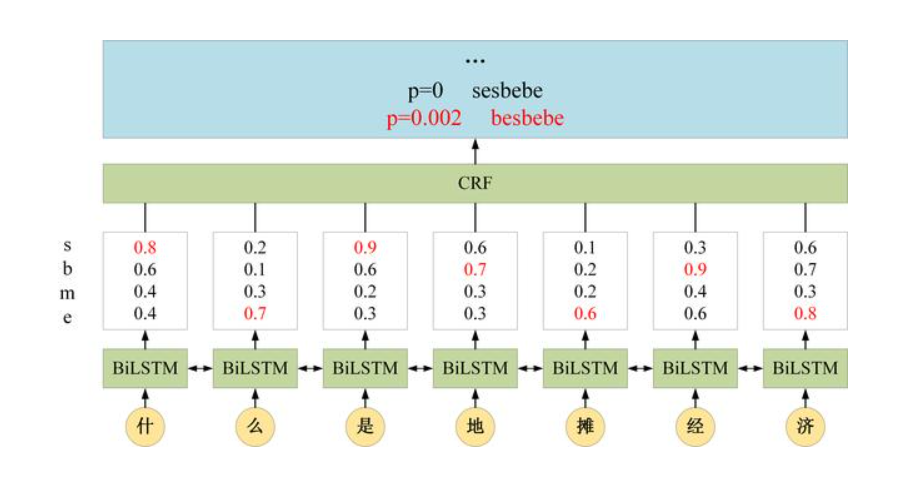
对于前两个字“什么”,其标签为“se”的概率为0.8*0.7*0=0(具体为什么在下面的CRF状态转移矩阵中会介绍),而标签为“be”的概率为0.6*0.5*0.7=0.21,因此最终输出概率最大的预测标签为“be”。
可以看到,BiLSTM+CRF 考虑的是整个类标路径的概率而不仅仅是单个类标的概率。在最终所有的路径中,标签“besbebe”的概率最大,这对应BiLSTM-CRF的预测结果为“besbebe”。
3.1 CRF特征函数 CRF包含两种特征函数,第一个特征函数是状态特征函数,也称为发射概率,表示字 x 对应标签 y 的概率
在 BiLSTM+CRF 中,这一个特征函数 (发射概率) 直接使用 LSTM 的输出计算得到,LSTM 可以计算出每一时刻位置对应不同标签的概率(如’什’对应“s”“b”“m”“e”标签的概率分别为0.8,0.6,0.4和0.4)
CRF 的第二个特征函数是状态转移特征函数,表示从一个状态 y1 转移到另一个状态 y2 的概率
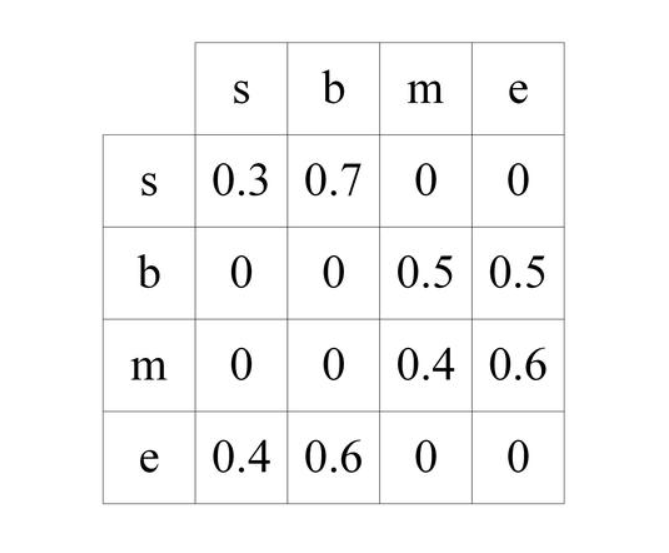
CRF 的状态转移特征函数可以用一个状态转移矩阵表示,在训练时需要调整状态转移矩阵的元素值,前面例子分词任务中的CRF转移矩阵就可以表示为
这个转移矩阵就是让模型能够考虑标签之间的相关性的关键,表示从一个状态转移到另一个状态的概率。
3.2 BiLSTM-CRF架构 一个最基本的BILSTM-CRF网络模型框架如下
1 2 3 4 5 6 7 8 9 10 11 12 class BiLSTM_CRF (nn.Module): def __init__ (self, vocab_size, tag2idx, embedding_dim, hidden_dim ): 2 , 1 , bidirectional=True ) len (tag2idx), len (tag2idx))
其结构可以表示为
给定一个句子x,其标签序列为y的概率使用如下公式计算
公式中的Z(x)表示所有标签序列打分的指数和,假如序列的长度为i,标签的个数为k,则序列的数量为k^i^,这无法直接计算,需要使用前向算法进行计算
公式中的score需要使用下面的式子计算,其中的Emit对应发射概率,即LSTM的输出概率,Trans对应了转移概率即CRF状态转移矩阵中对应的数值
BILSTM-CRF采用最大似然法进行训练,其对应的损失函数如下
公式中的logZ(x)需要使用前向算法计算,这里不再赘述,详情参考彻底了解 BiLSTM 和 CRF 算法-pytorch bilstm crf (51cto.com) 损失函数的计算;
3.3 viterbi算法 训练好模型后,预测过程需要用 viterbi 算法对序列进行解码,一些使用的符号意义如下
基于上述符号,viterbi算法的递推公式如下
基于上述递推式计算得到的δi(j)和ψi(j)向前标注序列
二、算法设计 1.数据预处理 整个项目可以认为分为数据预处理部分和训练模型、测试模型三部分。我单独将数据预处理部分作为一个notebook的形式来写一方面是为了直观的分析、理解每一步做了什么,另一方面notebook的形式便于发现和解决在处理数据过程中出现的问题。
首先数据预处理的目标是将四个原始文件train.txt,train_TAG.txt和dev.txt-dev,TAG.txt对应结合,然后按照标点符号进行分句处理。处理完成的效果是文本中的每一行是一个短句,短句的形式如下(字之间以空格分开)
1 记/O 者/ O 2 /O 日/ O 从/O 国/ O 家/O 防/ O 汛/O 抗/ O 旱/O 总/ O 指/O 挥/ O 部/O 办/ O 公/O 室/ O 获/O 悉/ O
处理数据的第一步应该先将文本文件及其对应的标注文件结合,因为这一步处理训练集文件和测试集文件的方式相同,因此这里只给出处理训练集文件的代码(数据预处理这部分如果只给出处理训练集的代码默认处理测试集的方式相同)
1 2 3 4 5 6 7 8 9 10 11 with open ("./data/train.txt" , "r" ,encoding='utf-8' ) as f1, open ("./data/train_TAG.txt" , "r" ,encoding='utf-8' ) as f2, open ("./data/train_combined_file.txt" , "w" ,encoding='utf-8' ) as output_file:for word, annotation in zip (file1_content, file2_content):"/" + annotation + " " print ("Combination complete" )
得到的train_combined_file.txt文件内容部分如下
下一步将按照常见的标点符号对长句进行切分,在此之前需要先进行标点符号清洗的工作。
为什么需要清洗某些标点符号?比如在双引号存在“你好,我是小明”这种情况下,按照逗号切分句子,会出现“你好,我是小明”这种切分错误。即这种情况下短句“你好在丢入模型训练的时候,最开始的双引号因为没有对应的结束双引号,会在一定程度上给模型带来干扰。因此这种类似的符号需要先清理掉。但是清理这种符号也不能随便清除,如书名号这种,因为这种符号一般用于《鲁滨逊漂流记》这种用于表示书名,书名号中间的内容不会有分隔符号如逗号、句号不会影响分句。而另一种需要清除的符号是类似‘ 卡 拉 什 尼 科 夫 ' 或 [ 新 闻 网这种本来应该成对出现但是只出现了一个的符号。最后,类似[/B_LOC 这种,作为BIO标注的一部分,这种符号是有意义的,不能删除!!!
因此最终确定要删除的符号有
清理train_combined_file.txt中的“无用”符号及其标签和空格代码如下
1 2 3 4 5 6 with open ('./data/train_combined_file.txt' ,'r' ,encoding='utf-8' ) as input_file,open ('./data/train_clean.txt' ,'w' ,encoding='utf-8' ) as output_file:'“”\'"‘’[]【】' '[' + re.escape(special_symbols) + '][^/ ]*/O ' '' , texts)
清理完成后就可以按照常见的分短句标点符号对长文本进行切分
1 2 3 4 5 6 7 8 with open ('./data/train_clean.txt' ,'r' ,encoding='utf-8' ) as inp:'[??!!。;;::,,]/[O]' .encode('utf-8' ,texts).decode('utf-8' ), texts) open ('./data/train_wordtagsplit.txt' ,'w' ,'utf-8' )for sentence in sentences:if sentence != " " :'\n' )
切分完毕的train_wordtagsplit.txt文件形式如下
因为作为模型训练时候的数据,直接使用txt文本不是好的选择,因此最后一步我们将训练集和测试集的数据借助pickle工具打包在Data.pkl文件中。
下面这段代码的目的是将文本数据转换为计算机可以处理的数字表示形式,以便后续进行机器学习或深度学习模型的训练和预测,整体逻辑比较简单。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 import pandas as pdimport numpy as npimport picklefrom sklearn.model_selection import train_test_splitdef data2pkl ():list ()list ()list ()list ()set ()with open ('./data/train_wordtagsplit.txt' , 'r' , encoding='utf-8' ) as train_file:for line in train_file.readlines():0 for word in line:'/' ) if label != 'O' : 1 if numNotO != 0 :with open ('./data/dev_wordtagsplit.txt' , 'r' , encoding='utf-8' ) as test_file:for line in test_file.readlines():0 for word in line:'/' )if label != 'O' :1 if numNotO != 0 :for line in datas_train + datas_test for word in line] range (1 , len (set_words) + 1 ) for i in tags]range (len (tags)) "unknown" ] = len (word2id) + 1 60 def X_padding (words ):list (word2id[words])if len (ids) >= max_len:return ids[:max_len]0 ] * (max_len - len (ids)))return idsdef y_padding (tags ):list (tag2id[tags])if len (ids) >= max_len:return ids[:max_len]0 ] * (max_len - len (ids)))return ids'words' : datas_train, 'tags' : labels_train}, index=range (len (datas_train)))'x' ] = df_data_train['words' ].apply(X_padding) 'y' ] = df_data_train['tags' ].apply(y_padding) 'words' : datas_test, 'tags' : labels_test}, index=range (len (datas_test)))'x' ] = df_data_test['words' ].apply(X_padding) 'y' ] = df_data_test['tags' ].apply(y_padding) list (df_data_train['x' ].values)) list (df_data_train['y' ].values)) list (df_data_test['x' ].values)) list (df_data_test['y' ].values)) 0.2 , random_state=43 )with open ('./data/Data.pkl' , 'wb' ) as outp:print ('** Finished saving the data.' )
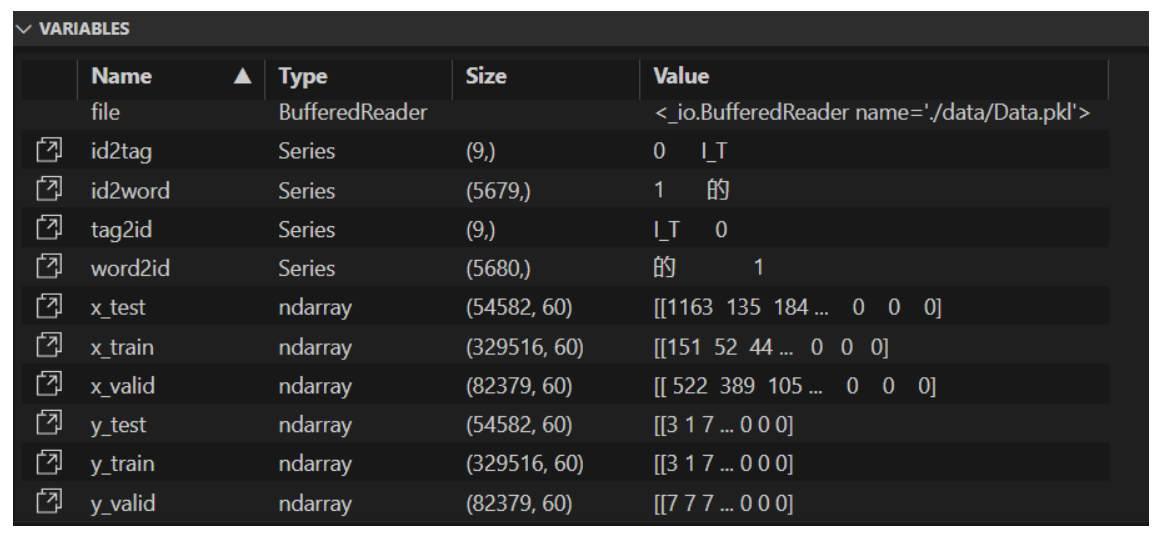
pkl文件中的内容如下,这里使用变量的形式展示出来
这里重点说一下tag2id(9,),这个变量是对训练文本和测试文本中所有标签的统计(也就是常说的标注集),可以看到一共有9个标签。使用的序列标注策略是最经典的BIO序列标注,这一点在后面设计训练程序和测试程序的时候尤其需要注意。标注集中的PER表示人名实体,LOC表示位置实体,ORG表示机构实体,T表示时间实体,O表示非命名实体。
2.BiLSTM-CRF 经过数据预处理过后,得到模型的训练文件Data.pkl,接下来就是构建模型并训练模型。
2.1 model模块 该模块中定义了一个名为BiLSTM_CRF的类,主要借助tensorflow来完成整个模型的搭建。该类表示一个包含双向LSTM层和CRF层的神经网络模型,主要用于序列标注任务。模型接受输入数据和标签,通过训练优化器进而对参数进行更新,使得模型能够预测输入数据的正确标签序列。本模块主要分为以下几个部分:
1.类初始化:在类的初始化方法中,将配置信息和dropout参数作为输入。配置信息包括学习率、批大小、词嵌入大小、词嵌入维度、句子长度和标签数量等。
1 2 3 4 5 6 7 self.lr = config["lr" ]"batch_size" ]"embedding_size" ]"embedding_dim" ]"sen_len" ]"tag_size" ]
2.占位符定义:定义输入数据、标签和词嵌入的占位符。
1 2 3 4 self.input_data = tf.placeholder(tf.int32, shape=[self.batch_size, self.sen_len], name="input_data" ) "labels" ) "embedding_placeholder" )
3.构建网络:使用_build_net方法在bilstm_crf变量作用域内定义网络结构。首先创建词嵌入变量word_embeddings,并使用tf.nn.embedding_lookup将输入数据嵌入到词嵌入空间中。然后对输入嵌入进行dropout处理。接着创建双向LSTM单元,使用tf.nn.bidirectional_dynamic_rnn对输入嵌入进行双向动态RNN处理。将前向和后向LSTM单元的输出拼接起来得到BiLSTM的输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 word_embeddings = tf.get_variable("word_embeddings" , [self.embedding_size, self.embedding_dim]) 1.0 , state_is_tuple=True )1.0 , state_is_tuple=True )False ,None )2 )
4.构建CRF层:在CRF层中,创建可训练的变量W和b,用于对BiLSTM的输出进行线性变换。对BiLSTM的输出进行tanh激活函数处理,并使用矩阵乘法和加法操作进行变换。
1 2 3 4 5 6 7 "W" , shape=[self.batch_size, 2 * self.embedding_dim, self.tag_size],"b" , shape=[self.batch_size, self.sen_len, self.tag_size], dtype=tf.float32,
5.CRF损失:使用tf.contrib.crf.crf_log_likelihood函数计算给定输入序列和转移参数的标签的对数似然。这里使用CRF来捕捉标签之间的依赖关系。然后使用tf.reduce_mean对负对数似然进行平均,得到损失。
1 2 3 4 5 6
6.解码和推断:进行解码和推断。使用tf.contrib.crf.crf_decode函数对BiLSTM的输出进行解码,得到最可能的标签序列。
1 2 3 4
7.优化器:创建优化器,使用Adam优化器进行模型训练,最小化损失。
1 2 optimizer = tf.train.AdamOptimizer(self.lr)
2.2 batch模块 该模块主要定义了一个批量生成器(BatchGenerator)类,用于生成批量的训练数据。批量生成器类提供了一种方便的生成批量训练数据的方法,它根据指定的batch_size生成相应大小的数据批次,并在每个epoch结束时对数据进行可选的打乱。下面介绍主要的类方法(一些返回数据属性的方法因为比较简单这里略过)
在类的初始化方法中,接受输入数据x和标签y以及一个可选的shuffle参数。如果输入数据x和标签y不是ndarray类型,则将它们转换为ndarray类型。将x和y保存为类的属性,并初始化一些变量(如epochs、index和num_examples)来跟踪数据的状态。如果shuffle参数为True,则对数据进行打乱。使用np.random.permutation函数生成一个新的索引顺序,并将x和y按照这个新的索引顺序重新排列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def __init__ (self, x, y, shuffle=False ):if type (x) != np.ndarray: if type (y) != np.ndarray: 0 0 0 ] if self.shuffle:
next_batch方法用于生成批量的训练数据。它接受一个batch_size参数,表示每个批次的样本数量。方法首先确定起始位置start,并将索引index增加batch_size来确定结束位置end。如果结束位置超过了样本数,表示一个epoch结束,epochs计数加1。如果shuffle参数为True,再次对数据进行打乱。然后重新设置起始位置为0,并将索引index重新设置为batch_size。同时,使用断言来确保batch_size小于等于样本数。最后,返回从起始位置到结束位置的x和y数据作为一个批次的训练数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def next_batch (self, batch_size ): if self.index > self.num_examples: 1 if self.shuffle: 0 assert batch_size <= self.num_examples return self.x[start:end], self.y[start:end]
2.3 train模块 该模块用于训练和评估BiLSTM-CRF模型,该模块主要负责训练模型、保存模型、评估模型性能并绘制损失和测试集性能的曲线图。
初始化阶段,根据训练数据和测试数据的样本数以及批次大小,计算训练和测试数据的批次数量(batch_num和batch_num_test)。然后创建两个空列表training_loss和development_performance,用于保存训练过程中的损失和测试集的性能。
1 2 3 4 batch_num = data_train.y.shape[0 ] // batch_size 0 ] // batch_size
使用嵌套的循环进行训练。外层循环遍历每个epoch,内层循环遍历每个训练批次。
1 2 3 4 5 6 7 x_batch, y_batch = data_train.next_batch(batch_size) if batch % 1000 == 0 : print ("batch:" , batch, " ====> train acc:" , train_acc)
注意,因为训练batch较多,因此选择每隔1000个batch打印一次训练集的准确率。同时因为模型在后期每个epoch提升的性能较缓慢(后面会作解释),因此选择每隔3个epoch保存一次模型
1 2 3 4 5 6 7 8 if epoch % 3 == 0 : if not os.path.exists("./model" ): "./model" )"./model/model" + str (epoch) + ".ckpt" print ("model has been saved in" , path_name)
在每个epoch结束后,使用测试数据进行评估。遍历每个测试批次,获取到x_batch和y_batch后,使用sess.run()方法运行模型的viterbi_sequence节点,得到预测序列pre。然后,使用calculate()函数根据预测序列和标签序列计算实体识别的指标,并将结果存储在entityres和entityall列表中。接着调用calculate_metrics()函数计算实体识别的精确率precision、召回率recall和F1值f1_score,并将F1值添加到development_performance列表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 entityres = []for batch in range (batch_num_test):0 ] print ("precision:" , precision) print ("recall:" , recall) print ("F1:" , f1_score)
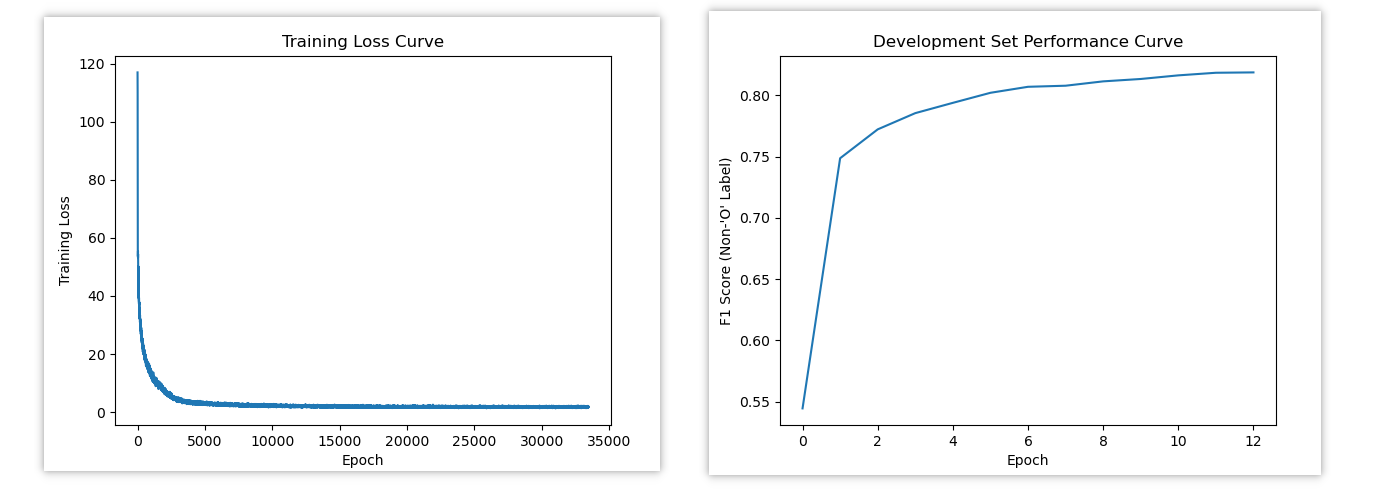
最后,在训练结束后,绘制训练损失曲线图以及development_performance曲线图。
其中训练损失曲线图中,横坐标为epoch,纵坐标为训练损失值。development_performance曲线图中,横坐标为epoch,纵坐标为F1值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 os.makedirs("images" , exist_ok=True )range (len (training_loss)), training_loss)"Epoch" )"Training Loss" )"Training Loss Curve" )"./images/training_loss_curve.png" ) range (len (development_performance)), development_performance)"Epoch" )"F1 Score (Non-'O' Label)" )"Development Set Performance Curve" )"./images/development_performance_curve.png" )
2.4 test模块 模型训练完毕后,通过test模块调用模型来对输入文本进行序列标注。简单来说,test模块就是一个用于文本标注的模块,主要定义了文本标注函数annotate_text。该函数的作用是读取输入文件中的文本行,将其按照常见标点符号分割为短句,并使用给定的模型和映射来对短句进行标注,然后将标注结果写入输出文件。
该函数首先打开文件并按行读取内容,然后循环遍历读取的每一行,对每一行的文本都应用删除首尾及其行内空格、应用正则表达式按照常见标点符号对文本进行分割(将长句分割为短句,短句的长度需要小于max_len)。
1 2 3 4 5 6 line = line.replace(' ' , '' ) 'utf-8' ).decode('utf-8' ) u'[??!!。;;::,,]' , text)
接着对分句后的短句依次进行处理。将每个句子中的单词转换为对应的id,并将转换后的句子添加到text_id列表中。如果单词不在word2id映射中,将其替换为”unknown”对应的id。
1 2 3 4 5 6 7 8 9 10 11 text_id = []for sen in text:list (sen)for word in sen:if word in word2id:else :"unknown" ])
处理完成文本的所有句子后,使用0填充将text_id填充到batch_size的长度(保证输入在批处理中具有一致大小)
1 2 3 zero_padding = []0 ] * max_len)len (text_id)))
然后创建一个feed_dict字典,将model.input_data占位符映射到text_id列表。然后使用sess.run()运行模型,其中model.viterbi_sequence用于获取目标,pre变量存储输入文本的预测实体标签。
1 2 feed_dict = {model.input_data: text_id}
get_BIO函数是整个test模块的核心,主要通过遍历每个句子中的每个字来组合其预测标签,然后将其加入BIO_list列表中,最后返回整个句子的BIO_list列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def get_BIO (x, y, id2tag ):for i in range (len (x)):for j in range (len (x[i])):if j >= len (y[i]):continue str (x[i][j])+'/' +str (id2tag[y[i][j]]))return BIO_list
拿到返回的列表后,调用translate_BIO函数对列表进行翻译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def translate_BIO (list_labels,text ): for char in characters:False for label in list_labels:if char == label.split('/' )[0 ]:'/' )[1 ])True break if not found:'O' )' ' .join(new_text)return new_text
此处举一个例子对上述translate_BIO函数做解释,假设输入如下list_lables和text
1 2 list_labels = ['记/O' , '者/O' , '1/B_T' , '月/I_T' , '1/I_T' , '5/I_T' , '日/I_T' ]text = "记 者 , 1 月 1 5 日"
通过遍历text,首先会找”记”在list_lables中是否有对应,发现第一个’记/O’对应,因此分离出’O’同时删除’记/O’。以此类推,如果在list_lables中没有找到对应,这是因为先前使用文本中的标点符号进行了切分导致标点符号缺失,因此缺失的都是标点符号,而标点符号对应的标签都是’O’,因此直接补’O’即可。最后,之所以要删除已经匹配好的列表中的元素,是为了避免从左到右匹配的时候出现干扰,比如上述例子中的’1/B_T’和’1/I_T’就完全不一样,但是仅仅使用’1’去匹配是分不清楚两者的,所有需要每次删除以避免重复。
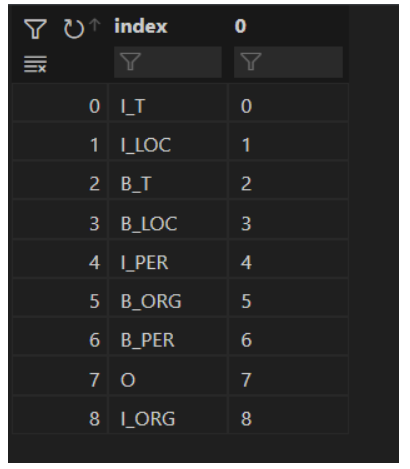
三、实验结果 1.实验说明 序列标注的标签集是训练集中所有不同的标签组成的集合,经过统计,本项目的标注集如下
序号
标签
0
O
1
B_T
2
I_T
3
B_LOC
4
I_LOC
5
B_PER
6
I_PER
7
B_ORG
8
I_ORG
BiLSTM-CRF的训练既可以使用预训练的词向量,也可以不使用,进而模型会从头开始学习词嵌入。通常,使用预训练的词向量通常会获得更好的结果,因为它们捕捉了从大型文本语料库中学习的单词之间的语义关系。但是在本次实验中,考虑到训练语料足够大,我并没有选择使用预训练的词向量。模型的自行学习使用词向量维数为100维,词典大小为word2id的大小加1,在本实验中词典大小为5681。
关于BiLSTM-CRF网络结构,默认dropout是1即不使用dropout,但是在训练模式下使用的dropout为0.5。BiLSTM中使用的是双向LSTM单元(lstm_fw_cell和lstm_bw_cell),其指定嵌入维度均为100。网络使用的激活函数是tanh激活函数,同时对结果使用了tf.matmul和加法操作进行变换。模型的损失是对负对数似然进行平均得到。模型的优化器使用的是Adam优化器。
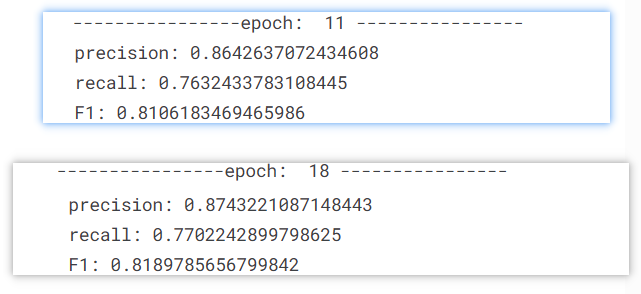
关于训练超参数的选择,因为直接在原始训练语料Data.pkl上训练需要大量时间,因此我根据手中训练集和测试集文本数量按比例创建了一个mini_data.pkl,用于选择超参数。max_len规定为60,即短句的最大长度,该长度在数据预处理的时候规定,此处需要保持一致,之后使用test模块对短句进行序列标注的时候的文本最大长度同样是60。batch_size指定为128,实际上最开始指定的batch_size为32,之后设置batch_size为64,在同样的条件下,32最终的F1值达到0.8332585723845312而64的F1值只有0.8106183469465986。但是无论是哪个batch_size,在test模块中对文本进行处理的时候都会遇到一个报错为tensor的shape不匹配,出现该报错的原因是在test.txt中有一个超长文本,通过常见标点符号划分为长度小于60的短句后,短句的数量多达92,因此无论是batch_size为32还是64的BiLSTM-CRF模型都无法接受这个超长的输入,无奈最终选择了batch_size为128,该模型最终的F1值为0.8186130795409343,相对来说还行。关于学习率,先后尝试了使用0.0001和0.002,但是最终的效果都没有学习率为0.001好,因此最终确定的学习率为0.001。最后是epoch训练轮次的选择,先后尝试了12轮和19轮,如下分别是两个轮次的最后训练输出
可以看到随着训练epoch的增加最终的F1值略有提升,但实际上在19个epoch的训练过程中已经出现了过拟合的现象,并且随着epoch为19的训练时间几乎是epoch为12的2倍。因为保存模型是保存的3的整数倍的epoch的模型,综上所述,最终选择的epoch为13。
以下给出在max_len为60,batch_size为128,学习率为0.001,epoch为13的情况下的模型训练输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 ----------------epoch: 0 ---------------- batch: 0 ====> train acc: 0.1234375 batch: 1000 ====> train acc: 0.94375 batch: 2000 ====> train acc: 0.948046875 model has been saved in ./model/model0.ckpt precision: 0.7157447577729573 recall: 0.4394866458550121 F1: 0.5445839887906061 ----------------epoch: 1 ---------------- batch: 0 ====> train acc: 0.971484375 batch: 1000 ====> train acc: 0.9828125 batch: 2000 ====> train acc: 0.9838541666666667 precision: 0.809712874642909 recall: 0.696066597294485 F1: 0.748601101213125 ----------------epoch: 2 ---------------- batch: 0 ====> train acc: 0.9846354166666667 batch: 1000 ====> train acc: 0.984375 batch: 2000 ====> train acc: 0.9828125 precision: 0.8331244778613199 recall: 0.7194866458550121 F1: 0.7721469040120906 ----------------epoch: 3 ---------------- batch: 0 ====> train acc: 0.9845052083333333 batch: 1000 ====> train acc: 0.9822916666666667 batch: 2000 ====> train acc: 0.98046875 model has been saved in ./model/model3.ckpt precision: 0.8412386491497758 recall: 0.7364967048213666 F1: 0.7853908977925076 ----------------epoch: 4 ---------------- batch: 0 ====> train acc: 0.9854166666666667 batch: 1000 ====> train acc: 0.9833333333333333 batch: 2000 ====> train acc: 0.984375 precision: 0.8491786171676127 recall: 0.7451682275407562 F1: 0.7937807599651202 ----------------epoch: 5 ---------------- batch: 0 ====> train acc: 0.9890625 batch: 1000 ====> train acc: 0.9848958333333333 batch: 2000 ====> train acc: 0.9880208333333333 precision: 0.8541725468059084 recall: 0.75579604578564 F1: 0.8019786674911115 ----------------epoch: 6 ---------------- batch: 0 ====> train acc: 0.9861979166666667 batch: 1000 ====> train acc: 0.9859375 batch: 2000 ====> train acc: 0.9859375 model has been saved in ./model/model6.ckpt precision: 0.8552825820086087 recall: 0.7636489767603191 F1: 0.8068724895182806 ----------------epoch: 7 ---------------- batch: 0 ====> train acc: 0.9846354166666667 batch: 1000 ====> train acc: 0.987890625 batch: 2000 ====> train acc: 0.98515625 precision: 0.8605358935742972 recall: 0.7610683315990288 F1: 0.8077514927955588 ----------------epoch: 8 ---------------- batch: 0 ====> train acc: 0.9889322916666666 batch: 1000 ====> train acc: 0.9893229166666667 batch: 2000 ====> train acc: 0.9876302083333334 precision: 0.864353064842561 recall: 0.7643843218869233 F1: 0.8113007495545378 ----------------epoch: 9 ---------------- batch: 0 ====> train acc: 0.990234375 batch: 1000 ====> train acc: 0.9846354166666667 batch: 2000 ====> train acc: 0.988671875 model has been saved in ./model/model9.ckpt precision: 0.8669116723206433 recall: 0.7658411377037808 F1: 0.8132481749136261 ----------------epoch: 10 ---------------- batch: 0 ====> train acc: 0.9893229166666667 batch: 1000 ====> train acc: 0.9865885416666667 batch: 2000 ====> train acc: 0.98515625 precision: 0.8678451967863954 recall: 0.7703503295178633 F1: 0.8161966292547757 ----------------epoch: 11 ---------------- batch: 0 ====> train acc: 0.9873697916666667 batch: 1000 ====> train acc: 0.9899739583333333 batch: 2000 ====> train acc: 0.9875 precision: 0.8681785636459858 recall: 0.7738744363510233 F1: 0.8183185275929608 ----------------epoch: 12 ---------------- batch: 0 ====> train acc: 0.987109375 batch: 1000 ====> train acc: 0.9881510416666667 batch: 2000 ====> train acc: 0.989453125 model has been saved in ./model/model12.ckpt precision: 0.8725796573438653 recall: 0.7709330558446064 F1: 0.8186130795409343
最后是训练损失图像和发展集性能随时间变化的曲线