初级项目_强化学习算法
任务要求:基于深度学习的强化学习算法实现,提交代码,撰写实验报告
任务分为两部分:
- 用Deep Q-learning Network(DQN)算法完成实验
- 环境:Mountain Car - Gymnasium Documentation (farama.org);
- 任选一种Policy Gradient或Actor-Critic相关算法完成实验
这两个任务的环境不同,前者是离散空间,后者是连续动作空间。
其中代码要求有适当的注释,禁止完全抄袭。实验报告不要粘贴大量源代码,内容至少包括实现方法、实验结果分析和讨论与思考三大部分:
1.实现方法及所采用的算法总结
2.实验结果分析:要求逻辑清晰,语言精炼,粘贴程序的实际运行测试结果并加以文字说明
3.讨论与思考
参考链接:
DQN参考代码:MountainCar-v0_DQN/MountainCar-v0_DQN.ipynb at master · georgepsh/MountainCar-v0_DQN (github.com)(这哥们真的是我的宝藏!!!);
2023/5/29 21:18 现在基本已经把之前做过的强化学习的内容忘完了,包括环境之类的,所以还需要先复习环境相关,然后在网上搜索相关的算法实现(注意这里的算法一定要能够解决gym环境中的问题),结合算法边理解相关知识边理解和修改代码(这个不需要像cv一样训练很久,相对来说比较简单);
2023/5/29 21:37 看了一下,之前的作业几乎没什么参考价值,现在目录下有一个gym环境一个gymnasium环境,到时候找到相关的参考之后这两个环境肯定有一个能跑的,所以也不用再费尽心思去测试环境;
2023/5/30 10:03 网上的代码基本上都是祖传代码,很多语法什么的放到现在都已经不兼容了,很难找到有效的资料,还有一种解决方法就是直接找GPT的帮助;
2023/5/20 10:32 既然在自己的电脑上跑不起来(是否是tf1的原因? – 现在环境直接爆炸了,几乎所有找的代码都跑不起来),不妨试试Kaggle?代码跑不通就换一个代码,不要一直和代码磕 – 我总感觉不是代码的问题,是本身环境就有问题(几乎所有的代码都一直报错说tuple没有reshape,这不是闹着玩吗)
2023/5/30 19:40 网上找的大部分代码都无法运行的原因是环境本身的问题,相同的代码在paddle平台是可以运行的,但是在本地安装要求的环境后就无法执行,不仅仅只是一份代码,几乎所有的代码都在报错说是数据格式的问题,考虑是否与gym版本有问题(或者我们可以尝试不使用gym而是使用gymnasium替代?)。至少现在DQN的可运行代码已经找到,接下来就先训练之后尝试将模型下载到本地运行test可视化。然后再寻找解决连续MountainCar的算法 – 既然最基础的DQN已经解决了,就不要再继续折腾,继续攻克之后的连续MountainCar;
2023/5/30 23:00 现在真的要被搞冒火了,很神奇的就是不管是什么代码始终无法在本地运行,看来现在能够依靠的只有百度的PaddlePaddle平台或者是更广泛的Kaggle平台;
2023/5/31 15:27 破案了,之前找的代码什么的跑不起来纯粹不是因为代码的问题,无论是tf1还是tf2还是pytorch都是同样的原因,也就是gym的版本过高很多命令都不适用,只需要把gym的版本降下来即可。另外一点,不要适用百度的paddle框架,这个框架的版本的差距甚至比gym还要离谱,两个版本之间几乎是不兼容的(真牛逼!)。现在终于成功的解决问题了,然后接下来就是先把DQN的弄完之后弄policy gradient;
2023/5/31 17:14 现在已经把两个作业的代码都找到并且都成功运行了,接下来需要做的就是把两个代码的注释写了之后重构代码,然后开始写实验设计。因为参考的代码和飞浆给的代码有一些区别,所以一切的立足点都是在理解代码基础之上,其他的参考资料结合代码进行解释;
2023/5/31 19:52 这个老兄的代码功底太强了,gpt几乎无法重构他的代码,既然如此的话只能选择按照百度的方法或者在pycharm中将其拆分为多个模块进行编写,先处理DPG算法的代码 – 现在已经将其转换成pycharm的格式,接下来只需要修改过程输出、保存模型、保存输出图像即可;
2023/6/1 10:48 通过不断地经过自己手动修改以及失败之后我明白一件事情,就是对于这种不是特别复杂但是又没办法自己修改的代码,交给GPT才是最好的选择(前提是你得规定让GPT做什么,不然GPT确实没办法给出有效的答复 – 规定工作环境是很有必要的),自己进行手动修改+copilot是一个非常愚蠢的行为,既浪费了时间也根本没有能够提高避免查重的概率。GPT重构完成之后,在pycharm中对self_code中的代码分文件书写类,同时修改输出,做完这些基本上就解决代码的问题了;
2023/6/1 16:37 现在已经成功解决完毕代码问题,运行的相关结果以及代码都在pycharm的对应目录下。接下来只需要结合GPT和百度设计以及其他参考资料对算法进行解释即可(可以先稍微放一放,最近搞这个弄得有点状态不是很好);
一、背景介绍
1.常见问题
Q_1:经典的Q学习算法和DQN的区别是什么?
A:传统Q学习算法&DQN参考链接,DQN(Deep Q-Network)是一种基于深度学习的增强学习算法,它是对经典的Q学习算法的扩展和改进。DQN和传统Q学习算法之间的主要区别如下:
- 近似值函数表示:传统的Q学习算法使用表格来存储和更新每个状态-动作对的Q值。然而,这种表格表示法在状态空间很大时变得不可行,因为需要存储大量的Q值。DQN通过使用深度神经网络来近似Q值函数,将状态作为输入,输出对应于每个动作的Q值。这种近似值函数的表示使得DQN可以处理更大和连续的状态空间。
- 经验回放:传统的Q学习算法在每次迭代中使用当前的经验样本进行更新。然而,这样的更新方式会导致样本相关性和数据效率低下。DQN引入了经验回放机制,它将每个时刻的经验样本存储在一个回放缓冲区中,并从中随机抽取样本进行更新。这样可以打破样本相关性,提高数据的利用效率,并增加算法的稳定性。
- 目标网络:DQN还使用了目标网络(target network)来稳定学习过程。在传统的Q学习中,更新当前的Q值函数会导致目标值的变化。这会引起学习过程中的波动和不稳定性。DQN通过使用一个独立的目标网络来计算目标Q值,该目标网络的参数较为稳定,减少了目标值的变动。目标网络的参数定期更新为当前Q网络的参数,从而保持学习的稳定性。
- 动作选择策略:传统的Q学习算法通常使用ε-greedy策略来选择动作,其中ε是一个小的概率,以便在探索和利用之间进行平衡。DQN在训练初期也使用ε-greedy策略,但随着训练的进行,它逐渐减少探索率,从而更多地利用学习到的Q值来选择动作。
DQN通过引入深度神经网络、经验回放、目标网络和改进的动作选择策略,提高了Q学习算法的性能和适用性,尤其在处理大型状态空间和连续动作空间时具有优势。
Q_2:Policy Gradient和Actor-Critic的区别是什么?
A:Policy Gradient(策略梯度)和Actor-Critic(演员-评论家)是两种常见的强化学习算法,它们在更新策略和值函数时有一些关键的区别:
- 更新方式:
- Policy Gradient:策略梯度方法直接对策略进行参数化,并通过最大化期望回报的梯度来更新策略参数。它通过采样多条轨迹来估计梯度,并使用梯度上升法进行参数更新。策略梯度方法主要关注策略的优化,而值函数的更新是间接通过策略梯度进行的。
- Actor-Critic:Actor-Critic方法包含一个策略网络(Actor)和一个值函数网络(Critic)。策略网络负责选择动作,值函数网络评估状态的值。它们共同协作,策略网络根据值函数的反馈来更新策略参数,而值函数网络则根据实际回报来更新值函数参数。Actor-Critic方法结合了策略优化和值函数估计的优点。
- 更新频率:
- Policy Gradient:策略梯度方法通常使用一整条轨迹(episode)进行参数更新。它在每个轨迹结束后,根据整个轨迹的回报来计算梯度,并更新策略参数。这种方法适合于离散的任务,其中轨迹较短且易于采样。
- Actor-Critic:Actor-Critic方法可以在每个时间步骤进行参数更新。策略网络可以在每个时间步骤选择动作,而值函数网络可以根据每个时间步骤的奖励信号进行更新。这使得Actor-Critic方法适用于连续时间的任务,并能够在每个时间步骤上进行在线学习。
- 值函数估计:
- Policy Gradient:策略梯度方法通常不直接估计值函数,而是通过采样得到的回报来估计策略的优劣程度,并利用梯度上升法更新策略参数。
- Actor-Critic:Actor-Critic方法同时估计策略和值函数。值函数网络用于评估状态的值,提供策略更新的反馈信号。这种值函数估计可以减少策略梯度估计中的方差,并提高学习的稳定性和效率。
Policy Gradient通过直接最大化回报梯度来更新策略,而Actor-Critic通过结合策略网络和值函数网络进行更新。Actor-Critic方法在更新频率和值函数估计方面提供了更大的灵活性和稳定性。
Q_3:Mountain Car Continuous环境和Mountain Car环境的区别?
A:
Mountain Car环境是一个经典的离散动作空间环境。在这个环境中,有一辆小车位于一个山谷中,目标是让小车能够通过施加力来逆向爬上陡峭的山坡。小车的动作可以是向左、向右或者不施加力。初始时,小车几乎无法爬上山坡,但通过连续尝试施加合适的力,小车最终可以积累足够的动量来成功爬上山坡。这个环境的奖励是负的时间步骤,目标是在尽可能少的步骤内到达目标点。
Mountain Car Continuous环境是Mountain Car环境的连续动作版本。在这个环境中,小车的动作空间是一个连续的实数范围,可以施加一个在[-1, 1]之间的力。这使得代理能够以更细腻的方式调整施加的力,从而更有效地爬上山坡。其余的环境设置和奖励函数与Mountain Car环境相似。
Q_4:DDPG算法属于Policy Grandient算法还是Actor-Critic算法呢?
A:DDPG(Deep Deterministic Policy Gradient)是一种强化学习算法,它属于Actor-Critic(AC)方法的一种变种。
Actor-Critic(AC)方法是一类结合了策略(Policy)学习和值函数(Value Function)学习的强化学习算法。在AC方法中,有两个主要组件:一个策略网络(Actor)和一个值函数网络(Critic)。策略网络用于学习生成动作的策略,而值函数网络用于估计状态或状态动作对的值函数。
DDPG是AC方法的一种扩展,它使用深度神经网络来表示策略网络和值函数网络,并且采用了离散动作空间的AC算法(DQN)的思想来处理连续动作空间。DDPG使用了一个确定性的策略(Deterministic Policy),而不是传统的随机策略,这使得它能够直接输出连续动作。
因此,DDPG既包含了策略梯度(Policy Gradient)的思想,也包含了Actor-Critic方法中值函数的学习。它可以被视为一种Policy Gradient算法的变种,同时也是一种Actor-Critic算法。
2.前置知识
2.1 MountainCar
2.1.1 离散MountainCar
MountainCar问题中,小车每次都被初始化在一个山谷的谷底,其目标是以最少的移动次数到达右侧山顶黄色小旗的位置。小车无法直接开到山顶位置,因为其发动机的动力不足。唯一能够成功的方式就是让小车通过左右移动来积蓄足够的动量以冲向山顶。

MountainCar问题中,智能体就是小车,环境是小车所属的运动空间,小车与环境进行交互后会获得当前的状态,状态包括以下两个状态变量
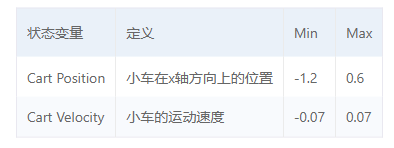
小车会根据当前的状态,依据现有的策略执行相应的动作
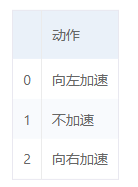
MountainCar中,触发以下两种情况中的任何一种则表示一轮实验终止(注意一轮实验就是一个episode):
- 小车达到右侧小旗的位置
- 小车的移动次数超过200次
小车每次都会根据当前状态执行上述三种动作之一,若没有触发终止条件则小车每移动一次都会获得reward=-1。
2.1.2 DQN算法
DQN算法中,智能体与环境进行交互后,会获得环境提供的状态st。接收到该观测值后,智能体会根据神经网络对当前状态下的不同action的Q值进行预测,同时返回一个选择的行动αt。智能体将该行动反馈给环境,环境会给出对应的奖励rt、新的状态st+1以及一个bool值,代表是否触发终止条件。每次智能体和环境的交互完成后,DQN算法会将(即st,αt,rt,st+1)作为一条经验存储在经验池中,然后随机抽取一批经验作为输入对神经网络进行训练。
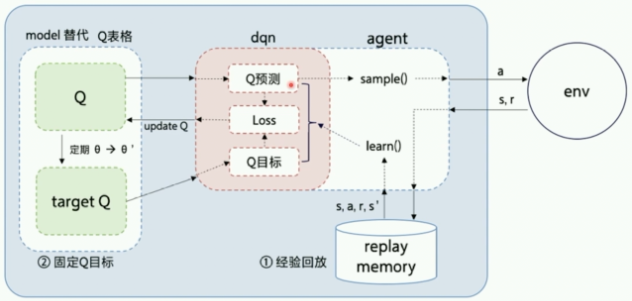
一般的,构建智能体的框架结构如下(智能体与环境交互图)
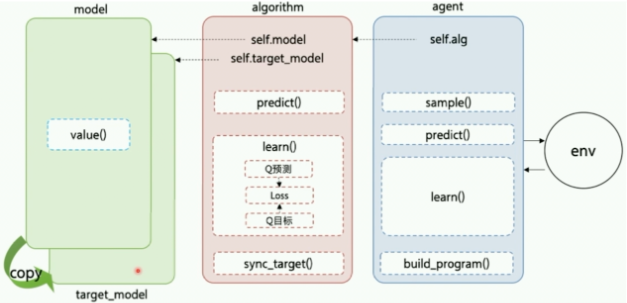
Model:用来定义前向 (Forward) 网络,通常是一个策略网络 (Policy Network) 或者一个值函数网络 (Value Function),输入是当前环境状态。在MountainCar的实验中,将在Model结构中构建一个值函数网络,用于获得在当前环境状态下所有action对应的Q值。
Algorithm:定义了具体的算法来更新前向网络 (Model),也就是通过定义损失函数来更新 Model,与算法相关的计算都可定义在Algorithm中。
Agent:Agent负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型。
DQN算法采用经验回放和目标网络冻结作为创新点:
- 经验回放(Experience Replay):使用一个经验池存储多条经验s,a,r,s’, 再从中随机抽取一批用于训练,很好的解决了样本关联性的问题,同时,因为经验池里的经验可以得到重复利用,也提升了利用效率。
- 目标网络冻结(Freezing Target Networks):复制一个和原来Q网络结构一样的Target Q网络,在一个时间段内固定Target Q网络的参数,用于计算Q目标值,这样在原来的Q网络中,target Q就是一个固定的数值,不会再产生优化目标不明确的问题。
DQN算法的主要流程如下

2.2 MountainCar-Continuous
2.2.1 连续MountainCar
MountainCarContinuous与MountainCar的区别在于,其动作也就是应用的引擎力应当是连续值。
2.2.2 DDPG算法
DDPG(Deep Deterministic Policy Gradient)算法是一种专门用于解决连续控制问题的在线式深度强化学习算法,借鉴了DQN算法中的一些思想。
在求解连续动作空间问题时主要有两种方式,一种是对连续动作做离散化处理后利用强化学习算法如DQN进行求解;另一种是使用Policy Grandient算法如Reinforce直接求解。对于第一种方式,离散化的处理会导致结果不符合实际情况;而对于第二种方式来说,PG算法在求解连续控制问题时效果又不是很好。
DDPG算法是AC框架下的一种在线深度强化学习算法,算法内部包括Actor网络和Critic网络,每个网络分别遵从各自的更新法则进行更新从而使得累计期望回报最大化。
DDPG算法将确定性策略梯度算法和DQN算法中的相关技术结合在一起,具体而言,DDPG算法主要包括以下三个关键技术:
- 经验回放:智能体将得到的经验数据放入经验池中,更新网络参数时按照批量进行采样;
- 目标网络:在Actor网络和Critic网络外再使用一套用于估计目标的Target Actor网络和Target Critic网络。在更新目标网络时,为了避免参数更新过快,采用软更新方式;
- 噪声探索:确定性策略输出的动作为确定性动作,缺乏对环境的探索。在训练阶段,给Actor网络输出的动作加入噪声,从而让智能体具备一定的探索能力;
(1)经验回放
经验回放是一种让经验概率分布变得稳定的技术,可以提高训练的稳定性。经验回放主要有“存储”和“回放”两大关键步骤:
- 存储:将经验以固定形式存储到经验池中;
- 回放:按照某种规则从经验池中采样一条或多条数据;
经验回放的优点:
在训练Q网络时,可以打破数据之间的相关性,使得数据满足独立同分布,从而减小参数更新的方差,提高收敛速度。
能够重复使用经验,数据利用率高,对于数据获取困难的情况尤其有用。
经验回放的缺点:
- 无法应用于回合更新和多步学习算法。但是将经验回放应用于Q学习,就规避了这个缺点。
(2)目标网络
因为DDPG是基于AC框架的算法,因此必然会包含Actor和Critic网络。额外的,每个网络都有其对应的目标网络,因此DDPG算法一共包含四个网络分别是Actor,Critic,Target Actor和Target Critic。
算法更新主要更新的是Actor和Critic网络的参数,其中Actor网络通过最大化累积期望回报来更新,Critic网络通过最小化评估值与目标值之间的误差来更新。在训练阶段,从Replay Buffer中采样一个批次的数据。假设采样得到的一条数据为(s,α,r,s’,done),则Actor和Critic网络的更新过程如下


对于目标网络的更新,主要采取的是软更新的方式,也称为指数平均移动EMA。即引入一个学习率Γ,将旧网络的目标网络参数和新的对应网络参数做加权平均,然后赋值给目标网络
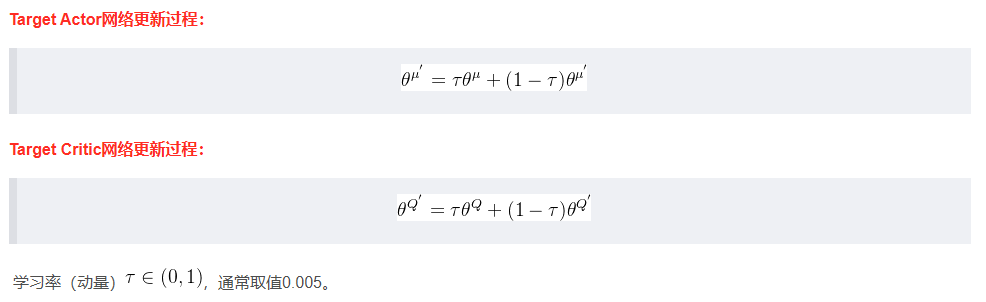
(3)噪声探索
探索对于智能体来说是至关重要的,而确定性策略“天生”就缺乏探索能力,因此需要人为给输出的动作上加入噪声,从而让智能体具备探索能力。DDPG算法中采用Ornstein Uhlenbeck过程作为动作噪声,而实际上OU噪声也可以使用服从正态分布的噪声替代(这就是TD3算法),实现起来更简单。
需要注意的是,噪声只会加在训练阶段Actor网络输出的动作上,推理阶段不要加上噪声,以及在更新网络参数时也不要加上噪声。总的来说就是,只需要在训练阶段让智能体具备探索能力,推理时是不需要的。
二、DQN解决MountainCar
使用Q学习解决MountainCar有很多参考,但实际上该算法在这个任务上的表现不够好,平均需要训练600-700次才能上坡。
而且,实际的Mountain Car的observation上的两个变量是一对连续的float数字,然而因为Q-learning本身的特点(需要构建一个Q-table),因此使用Q学习需要将每个连续的observation都四舍五入强制转换为了int来避免维度爆炸的问题。当state的observation变为离散后,环境中的状态的数量是就变成可数的,这样构建出的Q-table就更简单,更加方便于查找,但是也非常容易导致误差。

实际上在面对一些较为复杂的环境时,也就是连续的state会生成无限多种的状态,这样就会导致Q-table产生维度爆炸的问题,所以针对无限state的环境我们可以使用一种基于神经网络的方法:Deep Q-Network。
DQN与Q学习相比,优点在于使用Network代替Table以减少内存和查找速度。DQN同时拥有两个Q网络,分别是Q和Qtarget。使用Q模拟真实值,Qtarget模拟预测值,通过选定的Loss函数计算出Q与Qtarget之间的loss来更新函数。在算法初始化的时候Q=Qtarget,此处使用了unsupervisor learning的思想,这个方法被称作TargetNet,它一定程度降低了当前Q值和目标Q值的相关性。而Qtarget在训练过程中也会通过公式Qtarget=Q每隔固定的eposide来更新。
1.实验设计
使用DQN算法解决MountainCar问题的主要步骤如下:
- 构建模型:主要包含设计Agent、定义经验回放算法、DQN模型等;
- 训练配置:定义超参数,加载实验环境并实例化模型;
- 训练模型:执行多轮训练,不断调整参数,以达到较好的效果;
- 模型评估:使用训练好的模型进行MountainCar测试,可对其进行可视化观察Agent的表现,同时计算平均reward;
1.1 模型构建
1.1.1 经验回放
为了解决样本的相关性过强并提高数据的使用率,DQN采取经验回放的方法。经验回放算法的核心思想是通过存储和重复使用先前的经验来打破时间上的相关性,提高训练的效率和稳定性。它还可以更好地利用样本数据,减少在环境中采集样本的次数
经验回放算法的基本执行步骤如下:
- 经验存储:使用一个固定大小的经验存储器(experience replay buffer)来存储智能体在环境中的经验。这些经验包括当前状态、采取的动作、获得的奖励、下一个状态以及一个标记,表示该经验是否是终止状态。
- 经验收集:智能体与环境进行交互,根据当前的策略选择动作,并观察环境的反馈。智能体将这些经验(也称为样本)添加到经验存储器中。
- 经验回放:从经验存储器中随机采样一批经验样本。这是与传统的在线学习不同之处,传统方法通常是即时使用新采集的样本进行学习。通过从经验存储器中随机采样,可以打破样本间的相关性,减少梯度下降的方差。
- Q网络更新:使用采样得到的经验样本进行Q网络的更新。对于每个样本,计算目标Q值和当前Q值之间的差异,然后使用梯度下降方法最小化这个差异来更新Q网络的参数。
- 重复训练步骤:重复执行经验收集、经验回放和Q网络更新的步骤,直到达到预设的训练步数或满足停止条件。
下面的代码实现了一个经验回放类,也可以称为经验池类。主要包含以下属性:
memory经验池,用于存储经验对象。capacity表示经验池的容量,即可以存储的经验数量的最大值。Transition是一个转换函数或类,用于将输入的参数组合成经验对象。
经验池类除了包含基本的初始化方法外,还包含以下方法:
push(self, *args): 该方法接受任意数量的参数,并将这些参数作为输入创建一个新的经验对象,并将其添加到经验池中。sample(self, batch_size): 经验采样方法,它从经验池中随机选择指定数量的经验对象进行采样。__len__(self): 返回当前经验池中的经验数量,即self.memory的长度。
经验池类的完整代码如下
1 | |
1.1.2 DQN模型
DQN模型通过估计网络和目标网络的交替更新来实现Q值的逼近和训练,通过最小化估计值和目标值之间的损失来提高模型的性能。实现DQN模型主要需要实现DQN模型的核心功能,DQN模型通过估计网络和目标网络的交替更新来实现Q值的逼近和训练,通过最小化估计值和目标值之间的损失来提高模型的性能等。
DQN模型的主要属性如下:
layers是一个列表,表示神经网络的层结构。lr是超参数学习率,默认为0.0005。optim_method是优化器的选择,默认为Adam优化器。
在DQN类的初始化方法中,调用build_model()方法创建了目标网络(TargetNetwork)和估计网络(EstimateNetwork),并初始化了损失函数(MSELoss)和优化器(optimizer)
1 | |
build_model方法顾名思义,就是用于构建网络模型,其中的辅助方法init_weights用于初始化权重。该方法首先使用nn.Sequential构建EstimateNetwork神经网络,然后初始化其权重。接下来通过深拷贝将EstimateNetwork的参数拷贝给TargetNetwork,最后调用优化器对EstimateNetwork进行优化。
除了初始化方法和build_model方法外,DQN类还有以下类方法:
Q_target(self, inp): 该方法用于计算目标值,接受输入inp并返回目标网络对输入的输出。Q_estimate(self, inp): 该方法用于计算估计值。update_target(self): 该方法用于更新目标网络,将估计网络的参数复制给目标网络,以便更新目标值时使用。update_parameters(self, estimated, targets)用于更新网络参数。该方法计算估计值和目标值之间的损失,在更新网络参数之前还会进行梯度清零和反向传播以及梯度裁剪操作,最后调用优化器的step方法来更新参数。
1.1.3 Agent类
DQN算法中的智能体类负责定义智能体的行为策略、管理经验回放池和执行模型的优化,从而使得智能体能够通过与环境的交互逐渐学习并改进其决策能力。DQN算法中的Agent需要具备如下基本功能:
- 定义动作选择策略:Agent类中的
act方法根据当前状态选择动作。它根据ε-greedy策略,在一定的探索率ε下,以一定概率随机选择动作,以便探索环境;否则,根据当前策略(由DQN模型给出)选择具有最大动作值的动作。这种策略使得智能体能够在探索和利用之间进行权衡。 - 经验回放池管理:Agent类中的
memory对象是一个经验回放池(Replay Memory),用于存储智能体与环境之间的交互经验。它可以存储过去的状态、动作、奖励、下一个状态等,并且支持从中随机采样一批经验用于模型的优化。经验回放池的作用是使得智能体可以从先前的经验中进行学习,打破时间上的相关性,提高样本的有效利用率。 - 模型优化:Agent类中的
optimize方法实现了DQN算法中的优化步骤。它从经验回放池中采样一批经验数据,计算当前状态的动作值估计和下一个状态的目标值,并使用这些值来更新DQN模型的参数。通过不断迭代优化模型参数,智能体可以逐渐提高其在环境中的表现和决策能力。
下面的代码实现了一个名为Agent的智能体类,该类主要有如下属性:
device:模型计算使用的设备。transition:用于定义经验回放池中的转换数据结构。env:交互环境,即智能体进行训练和决策的环境。model:DQN模型,用于估计和优化动作值函数。n_actions:动作空间的大小。goal:目标分数,当智能体达到或超过该分数时,任务被认为是成功的。min_score:最低分数,当智能体的得分低于该分数时,任务被认为是失败的。eps_start:初始的ε-greedy策略中的ε值,用于探索动作空间。eps_end:最终的ε-greedy策略中的ε值,探索策略随时间衰减。eps_decay:ε-greedy策略中ε的衰减率。gamma:折扣因子,用于计算目标值的折扣累积奖励。batch_size:每次优化时从经验回放池中抽样的批次大小。memory_size:经验回放池的最大容量。max_episode:最大训练轮数。upd_rate:目标网络更新频率,表示每经过多少次优化操作后更新目标网络。
Agent类的act方法实现了根据给定状态和探索率选择一个动作的功能,根据随机数与ε值的大小比较对动作进行选择
1 | |
optimize方法用于执行DQN算法中的优化。基本的执行步骤如下:
- 判断经验池中的经验数量大小与批大小的关系:
- 如果经验回放池中的经验数量小于批大小,则不执行优化,直接return结束optimize方法
- 否则执行优化
- 从经验回放池中采样一个批次的经验数据,并进行转换;
- 计算当前状态的估计值和下一个状态的目标值
- 估计值由当前状态和选择的动作对应的Q值估计给出
- 目标值由下一个状态的最大Q值和实际奖励计算得到
- 使用目标值来更新模型的参数
以下是optimize方法的代码实现
1 | |
1.2 训练配置
训练配置的具体流程为:
- 设置超参数、创建模型
- 创建模型
- 实例化Agent代理
本实验需要借助gym库创建MountainCar环境,其常用的API如下所示
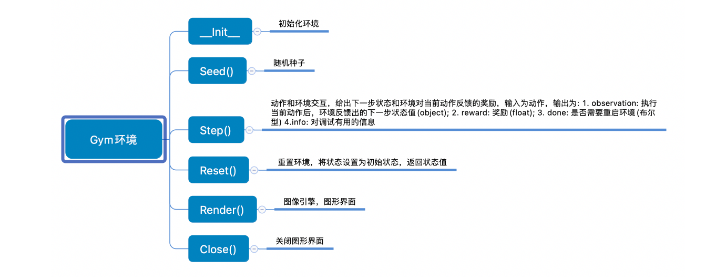
通过gym创建MountainCar训练环境并设置全局变量
1 | |
然后通过自定义的layers传入DQN类实例化模型
1 | |
最后对智能体进行实例化
1 | |
1.3 训练模型
基于DQN算法的在MountainCar环境下进行模型训练的具体步骤如下:
- 初始化训练参数和数据记录:
- 初始化智能体的参数、设备、目标分数和最低分数等。
- 创建空列表,用于记录每个episode的奖励。
- 初始化连续成功的次数。
- 开始训练循环:
- 使用for循环迭代训练的episode次数。
- 重置环境状态,获取初始状态。
- 将初始状态转换为张量,并放入设备中。
- 执行每个episode的动作选择、环境交互和优化过程:
- 使用while循环,直到达到episode结束条件(结束标志done为True)。
- 根据当前状态和探索率选择一个动作。
- 将动作转换为张量,并放入设备中。
- 执行动作,获取下一个状态、奖励、结束标志done和其他信息。
- 计算该步骤的奖励。
- 根据特定公式修改奖励。
- 将next_state、action、modified_reward和done转换为张量,并放入设备中。
- 将状态、动作、下一个状态、奖励和结束标志存储到经验回放池中。
- 更新当前状态为下一个状态。
- 调用agent.optimize()方法进行模型的优化。
- 更新目标网络和探索率:
- 如果当前episode是目标网络更新的步骤(每经过agent.target_update_rate个episode),则更新目标网络的参数。
- 更新探索率,将其乘以衰减率但不会小于最终探索率。
- 记录奖励并检查训练是否成功:
- 将当前episode的奖励添加到all_scores列表中。
- 每50个episode,计算最近50个episode的平均奖励,并输出平均奖励。
- 如果连续5个episode的平均奖励大于等于目标分数,则认为训练成功。
- 如果训练成功,则输出训练成功的episode数,并可以进行模型保存等操作。
- 否则,重置连续成功的次数为0。
- 返回记录的奖励列表all_scores。
具体的代码以及注释参考代码文件。
1.4 模型评估
训练完成后,对模型进行评估,评估模型主要是在一个while循环中,测试指定episodes轮:
- 选择并执行动作,获取下一个状态、奖励和完成标志;
- 累积当前episode的奖励;
- 判断是否达到episode结束条件,若游戏结束则更新计数器和记录奖励,然后重置reward以及状态;
- 输出评估结果;
如下是模型评估的代码
1 | |
2.实验结果分析
模型训练完毕后,可以看到模型训练过程的输出以及对应的可视化图像
1 | |
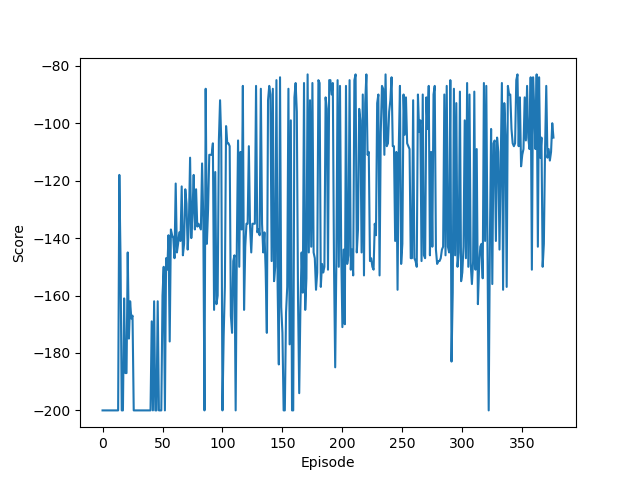
模型训练的最大轮数为2000个episode,目标分数是-110,最低分数是-200。可以看到模型在第377个episode训练完成,这表示连续5个episode的平均奖励大于等于目标分数。
观察训练图像可以看出,随着episode的增加,模型的分数也越来越高,最后可以稳定在-100到-120之间。
这里需要注意选择合适的学习率非常重要,一开始我选择使用的学习率是0.0001,但是因为其过小导致模型一直无法收敛,训练200轮后得分仍然在-190左右。
利用训练好的模型在MountainCar环境下进行测试,其输出如下
1 | |
如果在test函数中设置render为True,还可以看到每次小车的运动轨迹。这里我们对小车进行了50次测试,其平均分数为-116.9,可以看到这个分数与目标分数接近,这也表示模型训练的结果较好。
小车通过DQN算法不断学习和改进,以实现用最少的移动次数快速到达终点。
三、DDPG解决MountainCarContinuous
1.实验设计
与解决MountainCar的DQN算法的设计相同,使用DDPG算法解决MountainCarContinuous问题的具体步骤也分为:
- 模型构建
- 训练配置
- 训练模型
- 模型评估
1.1 模型构建
前面已经介绍过,DDPG算法主要包括三个关键技术:经验回放、目标网络和噪声探索,下面将分别实现。
1.1.1 经验回放
从存储的角度来看,经验回放可以分为集中式回放和分布式回放;从采样的角度来看,经验回放可以分为均匀回放和优先回放。下面这段代码实现的是集中式均匀回放(实际上与DQN中实现的经验回放算法完全一致)
1 | |
1.1.2 噪声探索
在DDPG(Deep Deterministic Policy Gradient)算法中,噪声探索起着关键的作用。它的目的是在训练过程中引入一定程度的随机性,以便智能体能够探索环境并发现更优的策略。
DDPG算法是一种用于解决连续动作空间的强化学习算法。它结合了深度神经网络和确定性策略梯度(DPG)算法的思想。在DPG中,智能体学习一个确定性策略函数,直接输出动作值,而不是输出动作的概率分布。这使得DPG算法在处理连续动作空间时更有效。
然而,确定性策略在探索未知环境时可能会陷入局部最优解。为了解决这个问题,DDPG引入了一种噪声探索方法。噪声可以增加智能体的行动多样性,从而使其有更多机会探索环境中的不同策略,并找到更优的策略。
常用的噪声探索方法之一是OU(Ornstein-Uhlenbeck)噪声。OU噪声是一种具有回归特性的随机过程,它可以产生连续的随机值。在DDPG中,OU噪声被添加到智能体选择的动作上,以产生随机性。OU噪声具有以下特点:
- OU噪声是一种高度相关的噪声,具有回归特性,它会将值推回到平均值附近。这使得智能体的行动不会变得过于剧烈或不稳定。
- OU噪声具有可调节的方差和均值,可以通过调整参数来控制噪声的幅度。这使得智能体可以根据需要在探索和利用之间进行权衡。
- OU噪声的自相关性可以帮助智能体在时间上保持一定的一致性。这对于连续动作空间中的探索非常有用,因为它可以使智能体在执行连续动作时保持平滑性。
下面这段代码实现了一个OU噪声类,用于生成具有回归性质的噪声
1 | |
在类的初始化方法中定义了OU噪声的参数,分别是均值、回归速度、标准差和动作维度,这些参数将用于后续计算噪声。另外一个属性是state,表示噪声状态,在初始化时该属性被设置为长度为action_dim且数组元素都是mu的数组,这表示初始状态下的噪声值都是均值。
类的reset方法用于重置噪声状态,执行该方法后噪声的状态将回到初始状态。
类的make_noise方法用于生成噪声,具体的执行步骤为:
- 计算OU过程的变化量delta,该变化量主要分为噪声向均值回归的速度和随机扰动两部分。
- 接着更新state为当前状态加上delta,使得噪声的值具有一定的回归性质。因为MountainCarContinuous环境的限制,因此需要将状态限制在[0,1]范围内。
- 返回更新后的噪声作为生成的噪声。
1.1.3 目标网络
下面是DDPG中的Actor网络和Critic网络关系
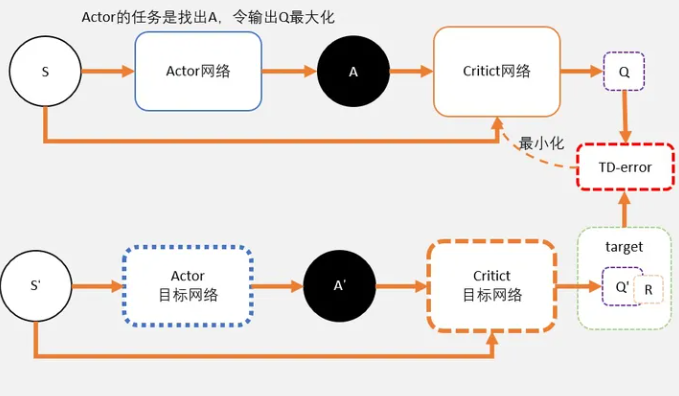
Actor网络
- 和AC不同,Actor输出的是一个动作;
- Actor的功能是,输出一个动作A,这个动作A输入到Crititc后,能够获得最大的Q值。
- 所以Actor的更新方式和AC不同,不是用带权重梯度更新,而是用梯度上升。
Critic网络
- Critic网络的作用是预估Q,虽然它还叫Critic,但和AC中的Critic不一样,这里预估的是Q不是V;
- 注意Critic的输入有两个:动作和状态,需要一起输入到Critic中;
- Critic网络的loss其还是和AC一样,用的是TD-error。这里就不详细说明了,我详细大家学习了那么久,也知道为什么了。
在DDPG算法中,值网络(Critic网络)用于评估给定状态和动作的值函数(Q函数)的估计值,即根据当前策略评估动作的好坏。策略网络(Actor网络)则用于生成确定性的动作值,即根据给定状态选择最优的动作。这两个网络通过交互和优化的方式相互影响和更新,从而达到同时学习值函数和策略函数的目的,以优化智能体的决策和行为策略。
在我们构建的Critic网络中,包含三个线性层的神经网络,输入层的维度为状态的维度,输出层的维度为1,中间隐藏层的维度通过参数指定。Critic网络的的前向传播算法根据输入的状态和动作经过一系列的线性层和激活函数(如ReLU)处理,最终输出值函数的估计值。
1 | |
Actor网络用于近似策略函数,包含三个线性层的神经网络,输入层的维度为状态的维度,输出层的维度为动作的维度,中间隐藏层的维度通过参数指定。Actor网络的前向传播输入状态,经过一系列的线性层和激活函数(如ReLU)处理,最终输出一个确定性的动作值。
1 | |
1.1.4 DDPG模型
我们已经知道DDPG算法的伪代码

DDPG算法的核心逻辑是通过交替进行Critic网络参数更新和Actor网络参数更新,并使用软更新策略来更新目标网络的参数。通过这样的方式逐步优化智能体的策略和值函数的估计,实现在连续动作空间下的强化学习。实现DDPG算法的核心逻辑主要分为如下几个步骤:
- 初始化:
- 定义算法的参数,如网络结构、学习率、优化器等。
- 创建值网络(Critic网络)的估计网络和目标网络,以及策略网络(Actor网络)的估计网络和目标网络。
- 将估计网络的参数复制给目标网络。
- 定义Q函数(值函数)的估计和目标:
- 提供一个状态和动作作为输入,分别通过值网络的估计网络和目标网络计算对应的Q值。
- 定义策略的估计和目标:
- 提供一个状态作为输入,通过策略网络的估计网络和目标网络计算对应的策略动作。
- Critic网络参数更新:
- 根据估计值和目标值计算Critic网络的损失。
- 使用Critic网络的优化器对损失进行反向传播和参数更新。
- 对梯度进行裁剪,防止梯度爆炸。
- 更新Critic网络的参数。
- Actor网络参数更新:
- 根据状态计算Actor网络的损失。
- 使用Actor网络的优化器对损失进行反向传播和参数更新。
- 对梯度进行裁剪,防止梯度爆炸。
- 更新Actor网络的参数。
- 目标网络软更新:
- 通过软更新策略,将估计网络的参数以一定的权重加到目标网络的参数上,实现目标网络的平滑更新。
DDPG类的初始化方法定义了各项参数以及网络结构
1 | |
接着定义了几个函数用于获取网络输出
- Q_estimate函数返回Critic网络估计值。
- Q_target函数返回Critic网络目标值。
- action_estimate函数返回Actor网络估计值。
- action_target函数返回Actor网络目标值。
DDPG类的update_critic_params函数和update_critic_params函数用于更新网络参数:
1 | |
- update_critic_params函数用于更新Critic网络的参数。
- 根据输入的估计值和目标值计算损失。
- 通过优化器将损失进行反向传播和参数更新,同时进行梯度裁剪。
- update_actor_params函数用于更新Actor网络的参数。
- 根据输入的状态计算Actor网络的损失。
- 通过优化器将损失进行反向传播和参数更新,同时进行梯度裁剪。
额外的,actor_loss函数实现计算Actor网络的损失函数。通过调用action_estimate获取Actor网络的估计值,接着返回负的Critic网络估计值的平均值,即最大化Critic网络的Q值。
1 | |
soft_update函数通过迭代估计模型和目标模型的参数,并将目标模型参数进行软更新。
1 | |
1.1.5 Agent类
DDPG算法的Agent类的实现基本与DQN中的Agent实现类似,同样包含初始化方法、act方法以及optimize方法。类的初始化方法主要用于接收并初始化一系列参数,代码中都有注释因此这里不再过多解释。
Agent的act方法用于选择动作,其选择动作的步骤主要如下
- 接收当前状态和一个epsilon值,用于epsilon-greedy策略。
- 使用模型的估计网络基于当前状态选择动作。
- 通过噪声对象生成噪声,并与动作相加。
- 限制动作范围在环境的动作空间内,通过clamp_方法实现。
1 | |
Agent的optimize方法实现了对网络优化,通过更新Critic网络参数和Actor网络参数,以逐步提升智能体的策略和值函数的估计。
1 | |
当执行optimize方法时,它会按照以下方法进行优化:
- 检查经验池中的样本数量是否大于批大小。如果小于批大小,方法将直接返回,不进行优化。
- 从经验池中随机采样一批数据。
- 将采样得到的数据分别提取为状态、动作、奖励、下一个状态和完成标志的张量。
- 使用值网络(Critic网络)的估计网络计算当前状态和动作的值估计。
- 创建一个全零张量作为下一个状态的Q值。
- 对于未完成的样本,使用目标网络计算下一个状态的动作值,并将其赋值给下一个状态的Q值。
- 计算目标值作为当前奖励加上折扣因子乘以下一个状态的Q值。
- 调用模型的方法,更新Critic网络参数和Actor网络参数。
1.2 训练配置
此处的配置过程与DQN算法中的配置过程相同,首先通过gym创建MountainCarContinuous训练环境并设置全局变量
1 | |
然后通过自定义的layers传入DDPG类实例化模型
1 | |
最后对智能体进行实例化
1 | |
1.3 训练模型
基于DDPG算法,在MountainCarContinuous环境下训练一个Agent,其核心在于在主循环中对每个episode进行训练。因为此处的代码大部分和DQN中的训练模型模块重复,因此这里仅介绍不同的地方。
1 | |
在初始阶段,Agent对环境了解有限,还没有收集到足够的经验。如果直接使用当前的策略网络来选择动作,可能会导致Agent陷入局部最优解,无法发现更好的策略。通过引入epsilon-greedy策略,可以以一定的概率选择随机动作,探索环境中不同的动作选择,从而更全面地探索环境,收集更多的经验。
而随着训练的进行,Agent逐渐积累了更多的经验,对环境的了解也逐渐增加。因此,在后面的episode中,可以逐渐减小epsilon的值,让Agent更加倾向于选择当前估计最优的动作,以加快收敛到最优策略的速度。
因为DDPG算法的收敛速度比较快,所以判断成功的标准与DQN不同
1 | |
1.4 模型评估
test函数用于测试训练好的Agent在MountainCarContinuous环境下的表现,其代码如下
1 | |
核心在于测试阶段不需要探索,因此选择动作的时候的epsilon被设为0。通过执行选择的动作获取需要的信息,将下一个状态转换为tensor,并累加奖励到当前episode的reward。
每个eposide都将reward保存到scores列表中,最后输出测试结果。
2.实验结果分析
MountainCar以及MountainCarCountinuous环境本身就是一个具有挑战性的问题,需要更多的探索和学习过程才能找到有效的策略。DQN算法与DDPG算法相比,可能需要更多的训练和调优才能达到较好的性能。这并不意味着DQN算法劣于DDPG算法,在处理离散动作空间的问题上,DQN算法表现出色;而在处理连续动作空间的问题上,DDPG算法更为适用。使用哪种算法取决于具体问题的性质和要求。
以下是DDPG算法在训练过程中的表现
1 | |
对应的训练性能曲线如下
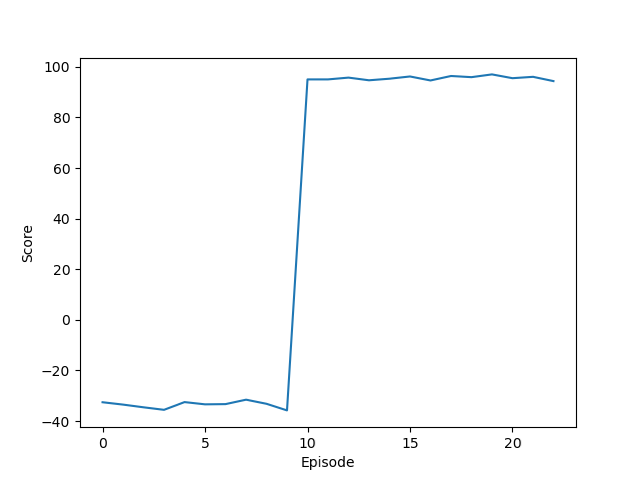
训练好的模型在测试环境下得到的分数如下
1 | |