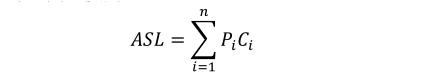2023/8/1 20:16 本篇博客主要整理考研数据结构中需要着重背诵且的基本数据结构和算法相关代码,由C和C++语言构成。关于这些算法的解释在另一篇笔记中非常详细,这里尽量给出简洁可背的代码,不让整个笔记看起来杂糅。
另外,这里给的代码也并不是说万精油(没有哪个数据结构给的资料可以说是完全适用,毕竟数据结构是应用学科),更多的是需要我们去理解其内部核心思想(比如顺序表的删除的实质就是移动元素)并学习代码写作风格,这样遇到由特定要求的题目不至于一筹莫展。
额外的还给出了某些常用算法的时间复杂度分析(对于某些简单的算法不给出时间复杂度),一方面加深对算法的理解,另一方面保证在解题的时候可以直接背诵使用。
2023/9/12 20:38 本来想的是把这个博客写成纯代码博客,但是随着后面学习的深入,这篇博客开始总结越来越多的除代码外其他必背考点。所以这里稍微做一个转型,之后也把刷题总结以及另一个数据结构上面的重要内容移到这个博客中,相比于之前那个博客这篇更加精简适合背诵 – 初学新知识还是整理到之前那个文档(专业课_数据结构)中,那个文档并不是不使用,而是不作为背诵的材料;
一、线性表 1.基本数据结构定义 1.1 顺序表结构体定义 因为一维数组可以是静态分配也可以是动态分配,所以顺序表结构体定义也有两种(ElemType表示任意元素类型,天勤习惯使用int,王道习惯使用ElemType)
1 2 3 4 5 #define maxSize 100 typedef struct Sqlist {int data[maxSize];int length;
1 2 3 4 typedef struct Sqlist {int *data; int maxSize,length;
1.2 单链表结点定义 1 2 3 4 typedef struct LNode {int data;struct LNode *next ;
1.3 双链表结点定义 1 2 3 4 5 typedef struct DLNode {int data;struct DLNode *prior ;struct DLnode *next ;
1.4 静态链表定义 与顺序表相同,静态链表也需要预先分配一块连续的内存空间,静态链表以next==-1作为结束标志
1 2 3 4 5 6 #define maxSize 50 typedef struct Slinklist {int next;
静态链表的插入、删除操作与单链表相同,只需要修改指针不需要移动元素
2.顺序表的基本操作 2.1 初始化 1 2 3 void initList (Sqlist &L) {0 ;
2.2 按位查找 1 2 3 4 5 6 int getElem (Sqlist L,int p,int &e) {if (p<0 || p>L.length-1 )return 0 ; return 1 ;
顺序表具有随机存储特性,因此其按值查找的时间复杂度为O(1)
2.3 按值查找 1 2 3 4 5 6 7 int findElem (Sqlist L, int e) {for (int i=0 ;i<L.length;i++){if (e==L.data[i])return i; return 0 ;
最好情况:查找元素就在表头,只需要比较一次,时间复杂度为O(1)
最坏情况:查找元素在表尾或不存在,比较n次,时间复杂度为O(n)
平均情况:平均比较次数为(n+1)/2,时间复杂度为O(n)
2.4 插入元素 1 2 3 4 5 6 7 8 9 int insertElem (Sqlist &L;int p;int e) {if (p<0 || p>L.length || L.length == maxSize)return 0 ; for (int i=L.length-1 ;i>=p;i--)1 ]=L.data[i];return 1 ;
最好情况:表尾插入,元素不用后移,时间复杂度为O(1)
最坏情况:表头插入,元素后移语句执行n次,时间复杂度为O(n)
平均情况:平均移动次数为n/2,时间复杂度为O(n)
2.5 删除元素 1 2 3 4 5 6 7 8 9 int deleteElem (Sqlist &L,int p,int &e) {if (p<0 || p>L.length-1 )return 0 ;for (int i=p;i<=L.length-2 ;i++)1 ]; return 1 ;
最好情况:删除表尾元素,时间复杂度为O(1)
最坏情况:删除表头元素,移动除表头元素外的所有元素,时间复杂度为O(n)
平均情况:平均移动次数为(n-1)/2,时间复杂度为O(n)
3.单链表的基本操作 3.1 尾插法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void creatlistR (LNode *&C,int a[],int n) { malloc (sizeof (LNode)); NULL ;for (int i=0 ;i<n;i++){malloc (sizeof (LNode)); NULL ;
尾插法生成的链表中结点的次序和输入数据的顺序一致,因为有尾指针r的存在因此时间复杂度为n*O(1)=O(n)
3.2 头插法 1 2 3 4 5 6 7 8 9 10 11 12 13 void createlistF (L Node *&C,int a[],int n) {malloc (sizeof (LNode)); NULL ;for (int i=0 ;i<n;i++){malloc (sizeof (LNode));
头插法建立单链表时,读入数据的顺序与生成的链表中的元素的顺序是相反的。每个结点的插入时间为O(1),因此长度为n的单链表的建表时间复杂度为O(n)
3.3 按序查找 1 2 3 4 5 6 7 8 9 10 11 int GetElem (LNode *C,int i) {if (i<1 )return NULL ;int j = 1 ;while (p!=NULL && j<i){return p;
按序查找的时间复杂度显然为O(n)(没有说明具体什么复杂度的时候统一认为是最坏时间复杂度)
3.4 按值查找 1 2 3 4 5 6 7 int findElem (LNode *C,int x) {while (p!=NULL && p->data!=e){return p;
很明显按值查找的时间复杂度为O(n)
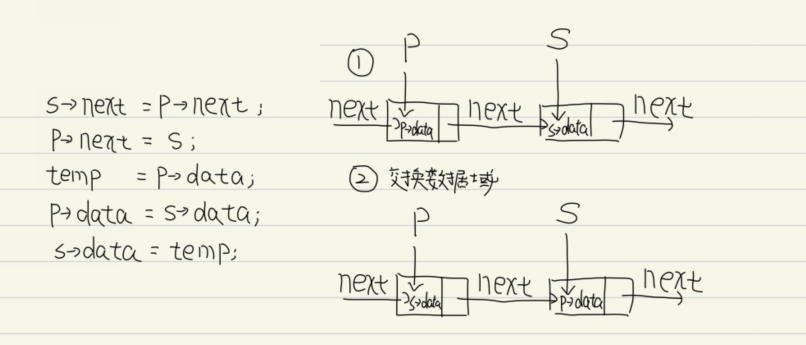
3.5 插入元素 3.5.1 后插操作 核心是找到插入结点的前一个结点,所以需要首先调用按序查找,再执行下面的代码片段
1 2 s->next = p->next;
算法的主要时间开销在查找元素,时间复杂度为O(n),若直接给定结点在后面插入新结点则时间复杂度为O(1)
3.5.2 前插操作 任何前插操作都可以转换为后插操作,但后插操作时间复杂度为O(n),下面这种方式实现了以时间复杂度为O(1)的方式进行前插操作
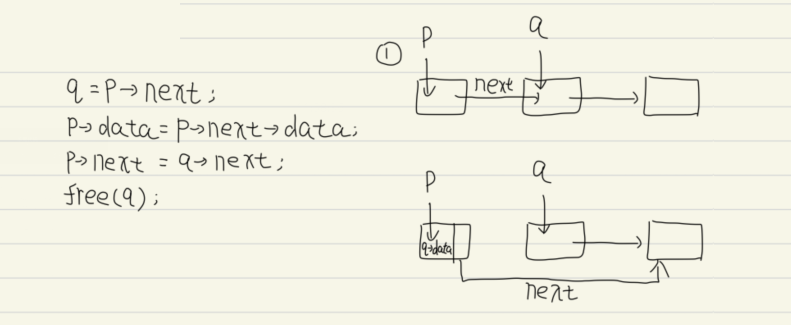
3.6 删除元素 核心是找到被删除结点的前一个结点,与插入操作相同需要先使用按序查找,然后执行下面代码
1 2 3 q=p->next;free (q);
因此其时间复杂度同样为O(n),但是,删除结点还有一种时间复杂度为O(1)的算法,本质上就是将其后继节点的值赋予本身然后删除后继节点
4.双链表的基本操作 双链表在单链表的结点中增加了一个指向其前驱的prior指针,因此双链表中的按值查找和按序查找与单链表相同,但双链表在插入和删除操作的实现上与单链表有较大的不同。因为双链表可以很方便的找到其前驱结点,因此双链表的插入、删除操作的时间复杂度仅为O(1)
4.1 尾插法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void createDlistR (DLNode *&L,int a[],int n) {malloc (sizeof (DLNode));NULL ;NULL ;for (int i=0 ;i<n;i++){malloc (sizeof (DLNode));NULL ;
4.2 插入元素 在p结点后插入s结点
1 2 3 4 s->next = p->next;
4.3 删除元素 删除p结点后的q结点
1 2 3 4 5 q = p->next; free (q);
二、栈和队列 1.基本数据结构定义 1.1 顺序栈结构体定义 1 2 3 4 typedef struct sqStack {int data[maxSize]; int top;
1.2 链栈结点定义 1 2 3 4 typedef struct LNode {int data; struct LNode *next ;
1.3 顺序队列结构体定义 1 2 3 4 5 typedef struct sqQueue {int data[maxSize];int front; int rear;
1.4 链队列结点定义 队结点类型定义
1 2 3 4 typedef struct QNode {int data; struct QNode *next ;
链队类型定义
1 2 3 4 typedef struct LiQueue {
2.顺序栈的基本操作 顺序栈的基本图示结构如下
2.1 初始化 初始化操作的实质就是将栈顶指针置为-1
1 2 3 void initStack (sqStack &st) {-1 ;
2.2 判空操作 1 2 3 4 5 6 int isEmpty (sqStack st) {if (st.top == -1 )return 1 ; else return 0 ;
2.3 进栈操作 进栈操作可以简写为stack[++top]=x;,其时间复杂度为O(1)
1 2 3 4 5 6 7 int push (sqStack &st,int x) { if (st.top == maxSize-1 ) return 0 ;return 1 ;
2.4 出栈操作 出栈操作可以简写为x=stack[top--];,其时间复杂度为O(1)
1 2 3 4 5 6 7 int pop (sqStack &st,int &x) {if (st.top == -1 ) return 0 ;return 1 ;
3.链栈的基本操作 链栈的基本图示结构如下
3.1 初始化 1 2 3 4 void initStack (LNode *&lst) {malloc (sizeof (LNode));NULL ;
3.2 判空操作 1 2 3 4 5 6 int isEmpty (LNode *lst) {if (lst->next == NULL )return 1 ; else return 0 ;
3.3 进栈操作 链栈的入栈和出栈时间复杂度同样为O(1)
1 2 3 4 5 6 7 8 void push (LNode *lst,int x) {malloc (LNode *)malloc (sizeof (LNode));NULL ;
3.4 出栈操作 出栈一般需要将出栈元素保存在x中
1 2 3 4 5 6 7 8 9 10 int pop (LNode *lst,int &x) {if (lst->next == NULL ) return 0 ;free (p);return 1 ;
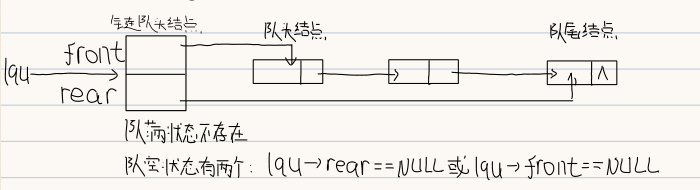
4.顺序队列的基本操作 因为顺序队列存在“假溢出”的情况,所以实际使用意义不大,一般都选择使用循环队列替代。循环队列的基本图示如下
4.1 初始化 1 2 3 void initQueue (sqQueue &qu) {0 ;
4.2 判空操作 1 2 3 4 5 6 int isQueueEmpty (sqQueue qu) {if (qu.front == qu.rear)return 1 ; else return 0 ;
4.3 进队操作 1 2 3 4 5 6 7 int enQueue (SqQueue &qu,int x) {if ((qu.rear+1 )%maxSize == qu.front) return 0 ;1 )%maxSize; return 1 ;
4.4 出队操作 1 2 3 4 5 6 7 int deQueue (sqQueue &qu,int &x) {if (qu.front == qu.rear) return 0 ;1 )%maxSize; return 1 ;
5.链队的基本操作
5.1 初始化 1 2 3 4 void initQueue (LiQueue *&lqu) {malloc (sizeof (LiQueue)); NULL ;
5.2 判空操作 1 2 3 4 5 6 int isQueueEmpty (LiQueue *lqu) {if (lqu->rear == NULL ||qu->front == NULL )return 1 ; else return 0 ;
5.3 入队算法 1 2 3 4 5 6 7 8 9 10 void enQueue (LiQueue *lqu,int x) {malloc (sizeof (QNode));NULL ; if (lqu->rear == NULL ||lqu->front == NULL )else
5.4 出队操作 1 2 3 4 5 6 7 8 9 10 11 12 13 int deQueue (LiQueue *lqu,int &x) {if (lqu->next==NULL ||lqu->front==NULL ) return 0 ;else if (lqu->front==lqu->rear)NULL ; else free (p);return 1 ;
三、串 1.基本数据结构定义 串的两种最基本的存储方式是链式存储和顺序存储,但一般情况下使用的都是顺序存储,顺序存储分为堆存储(变长顺序存储)和数组存储(定长顺序存储)
1.1 定长顺序存储结构体 1 2 3 4 typedef struct Str {char str[maxSize+1 ]; int length;
1.2 变长顺序存储结构体 变长存储表示方法有顺序存储结构的有点,同时操作中串的长度可以根据需要来进行设定更加灵活,因此更加常用,其形象的表示如下
其代码表示如下
1 2 3 4 typedef struct Str {char *ch; int length;
2.串的基本操作 2.1 赋值操作 赋值操作的本质是数组赋值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int strassign (Str &str,char *ch) { if (str.ch) free (str.ch);int len = 0 ; char *c = ch; while (*c){ if (len == 0 ){ 0 ;NULL ;return 1 ; else { char *)malloc (sizeof (char )*(len+1 ));if (str.ch == NULL )return 0 ; else {for (int i=0 ;i<=len;i++,c++){return 1 ;
2.2 取串长操作 1 2 3 int strlength (Str str) {return str.length;
2.3 串比较操作 1 2 3 4 5 6 7 int strcompare (Str s1,Str s2) {for (int i=0 ;i<s1.length && i<s2.length;i++){if (s1.ch[i]!=s2.ch[i]) return s1.ch[i]-s2.ch[i]; return s1.length-s2.length;
2.4 串连接操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int contact (Str &str,Str str1,Str str2) { if (str.ch){free (str.ch);NULL ; char *)malloc (sizeof (char )*(str1.length+str2.length+1 ));if (str.ch == NULL )return 0 ; while (int i<str1.length){while (int j<=str2.length){ return 1 ;
2.5 求子串操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int substring (Str &substr,Str str,int pos,int len) { if (pos<0 || pos>=str.length || len<0 || len>str.length-pos) return 0 ;if (substr.ch){free (substr.ch); NULL ; if (len = 0 ){ NULL ;0 ;return 1 ;else {char *)malloc (sizeof (char )*(len+1 ));int i =pos;int j=0 ;while (i<pos+len){'\0' ; return 1 ;
2.6 串清空操作 1 2 3 4 5 6 7 8 int clearstr (Str &str) {if (str.ch){free (str.ch);NULL ;0 ;return 1 ;
3.串的模式匹配 这里为了理解的方便,串中对应的字符对应下标1~length而非前面数组存储中的0~length-1
3.1 朴素模式匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int BF (Str str,Str substr) {int i=1 ,j=1 ,k=1 ;while (i<=str.length&&j<=substr.length){if (str.ch[i]==substr.ch[j]){else { 1 ; 1 ;if (j>substr.length)return k; else return 0 ;
假设主串长度为n模式串长度为m,并且进行多次匹配后匹配成功
最好情况:每一趟匹配时比较的第一个字符不同,平均比较次数为(n+m)/2,一般n远大于m故时间复杂度为O(n)
最坏情况:每一趟匹配比较到最后一个字符时两字符不同,平均比较次数为(n-m+2)*m/2,时间复杂度为O(nm)
如果匹配失败按照匹配成功的最坏情况分析,时间复杂度为O(nm)
3.2 KMP模式匹配 3.2.1 KMP匹配算法 KMP实际就是基于朴素模式匹配的改进,所以在代码风格上与之类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int KMP (Str str,Str substr,int next[]) {int 1 =1 ,j=1 ; while (i<=str.length&&j<=substr.length){if (j==0 || str.ch[i]=substr.ch[j]){else if (j>substr.length)return i-substr.length;else return 0 ;
代码中的j==0的理解只是一种正确性上的理解,实际上j==0那一句的作用是当主串的第i个位置和模式串的第一个字符不匹配的时候,从主串的i+1个位置开始匹配;
KMP算法的时间复杂度为O(n+m)
3.2.2 next数组构造* next数组的构造仅依赖模式串,这部分内容网上几乎没有讲的很直观的视频,这里我给出最权威也最简单的算法描述:前缀和后缀进行比较,如果前缀和后缀没有相同前缀,则为0+1,如果相同,则相同的字符个数+1。下面是一个标准的next数组的构造示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 序号j: 1 2 3 4 5 6 7 8 9 10 11 12 b a b a a a b a b a a0 1 1 .next[1 ],next[2 ]无论是什么模式串数组,永远都是0 和1 。2 .next[3 ]:如上,序号j[3]对应的模式串s[3],那么我们就看模式串s[3]前面的字符即可,即为a b,那么s[3]的前缀为a,后缀为b,a和b不相同,则next[3]为0+1=1; 3 .next[4 ]:序号j[4]对应的s[4],找s[4]的前面字符,为a b a,字符前缀为a、ab;后缀为ba, a4 .next[5 ]:序号j[5]对应的s[5],找s[5]的前面字符,为a b a b,字符前缀为a、ab、aba三个,后缀为bab、ab、b三个,进行比较,有字符串ab相同,则next[5]=2+1=3 5 .next[12 ]:序号j[12]对应的模式串字符为s[12],取前n-1个字符,为a b a b a a a b a b a,前缀为:ababaaabab、ababaaaba...后缀为babaaababa、abaaababa...可看出前缀中 ababa与后缀中ababa5个字符相同,则next[12 ]=5 +1 =6 ;j: 1 2 3 4 5 6 7 8 9 10 11 12 b a b a a a b a b a anext: 0 1 1 2 3 4 2 2 3 4 5 6 (next数组的值对应了每个位置的最长相同前缀和后缀的长度)
上述算法描述对应的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void getnext (Str substr,int next[]) { int i=1 ,j=0 ; 1 ]=0 ; while (i<substr.length){ if (j==0 || substr.ch[i] == substr.ch[j]){ else {
为了更进一步理解代码,这里结合上述例子对next数组构造
1 2 3 4 5 6 7 8 9 1 .初始化 i=1 和 j=0 ,并设置 next[1] =0 2 .进入循环,比较 substr.ch [i] 和 substr.ch [j] ,即 s[1] 和 s[0] ,它们分别是字符 "a" 和 "a" 。因为它们相等,所以执行以下操作:i 和 j,现在 i=2 和 j=1 [2] 为 j,即 next[2] = 1 3 .比较 s[2] 和 s[1] ,即字符 "a" 和 "b" ,它们不相等。这时候执行 else 分支,将 j 设置为 next[j] ,即 j 变成 1 4 .比较 s[2] 和 s[1] ,仍然不相等。继续执行 else 分支,将 j 设置为 next[j] ,这时 j 变成 0 5 .比较 s[2] 和 s[0] ,即字符 "a" 和 "a" ,它们相等。因此,执行以下操作:i 和 j,现在 i=3 和 j=1 [3] 为 j,即 next[3] = 1
3.2.3 nextval数组构造* nextval数组可以看作是对next数组的改进,在使用时直接将KMP算法重点的next数组换为nextval数组即可。同样这里分别介绍手动求解nextval数组和代码实现nextval数组,手动求解的算法思想如下:
若对应字符不同,直接填入next的值;
若对应字符相同,填入该值对应的序号的next的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 序号 : 1 2 3 4 5 6 7 8 9 10 11 12 0 1 1 2 3 4 2 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 10 11 12 0 1 1 2 3 4 2 2 3 4 5 6 0 1 0 1 0 4 2 1 0 1 0 4
下面是代码实现(实在理解不了就硬背,这部分几乎不会考代码几乎都是手动计算。花费大量时间记忆不是一个明智的选择)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void getnextval (Str substr,int nextval[]) { int i=1 ,j=0 ;1 ]=0 ;while (i<substr.length){if (j==0 || substr.ch[i]==substr.ch[j]){if (substr.ch[i]!=substrch[j])else else
四、矩阵 1.矩阵的定义 1 2 3 # define m 4 #define n 5 int A[m][n];
2.矩阵的转置 1 2 3 4 5 6 void trsmat (int A[][maxSize],int B[][maxSize],int m,int n) { for (int i=0 ;i<m;i++){ for (int j=0 ;j<n;j++)
3.矩阵相加 1 2 3 4 5 6 7 void addmat (int C[][maxSize],int A[][maxSize],int B[][maxSize],int m,int n) {for (int i=0 ;i<m;i++){for (int j=0 ;j<n;j++){
4.矩阵相乘
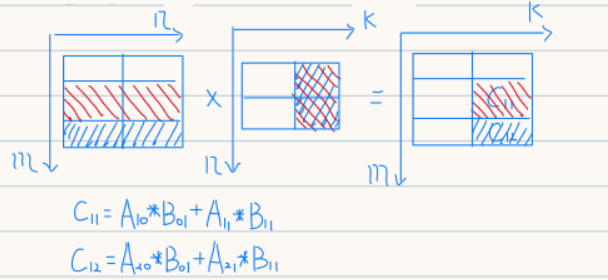
1 2 3 4 5 6 7 8 9 void mutmat (int C[][maxSize],int A[][maxSize],int B[][maxSize],int m,int n,int k) { for (int i=0 ;i<m;i++){for (int j=0 ;j<k;j++){0 ;for (int h=0 ;h<n;h++)
五、树和二叉树 1.基本数据结构定义 1.1 二叉链表结点定义 二叉树的顺序存储结构不便于存储任意形态的二叉树(顺序结构一般存储完全二叉树),更常使用二叉链表存储
1 2 3 4 5 typedef struct BTNode {char data;struct BTNode *lchild ;struct BTNode *rchild ;
1.2 线索二叉树结点定义 1 2 3 4 5 6 typedef struct TBTNode {char data; int ltag,rtag; struct TBTNode *lchild ;struct TBTNode *rchild ;
其中ltag和rtag是标识域:
ltag=0表示lchild为指针指向结点的左孩子;ltag=1表示lchild为线索指向结点的直接前驱;
rtag=0表示rchild为指针指向结点的右孩子;rtag=1表示rchild为线索指向结点的直接后继;
1.3 并查集定义 1 2 #define SIZE 13 int UFSet[SIZE];
2.二叉树的遍历
二叉树的深度优先包括前、中、后序三种遍历方式,广度优先即指层序优先遍历
无论是哪种遍历方式,每个结点都访问一次且仅访问一次,故时间复杂度均为O(n)
2.1 前序遍历 2.1.1 前序遍历的递归实现 1 2 3 4 5 6 7 8 void preoder (BTNode *p) { if (p!=NULL ){
2.1.2 前序遍历非递归实现 前、中、后序的非递归实现都是使用自定义的栈来替代系统栈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void preorderNonrecursion (BTNode *bt) {if (bt != NULL ){int top=-1 ; while (top != -1 ){ if (p->rchild != NULL ) if (p->lchild != NULL )
2.2 中序遍历 2.2.1 中序遍历递归实现 1 2 3 4 5 6 7 8 void inoder (BTNode *p) { if (p!=NULL ){
2.2.2 中序遍历非递归实现 中序非递归遍历的执行步骤如下:
根结点入栈;
循环执行:若栈顶结点左孩子存在,则左孩子入栈;若栈顶结点左孩子不存在,则出栈并输出栈顶结点,再检查其右孩子是否存在,若存在则右孩子入栈;
栈空时结束算法;
基本算法思想为:使用了一个栈来模拟递归过程,首先向左遍历树的最深的左子树,然后出栈并访问节点,然后再转向右子树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void inorderNoncursion (BTNode *bt) {if (bt != NULL ){int top=-1 ; while (top !=-1 || p!=NULL ){ while (p!=NULL ){ if (top!=-1 ){
2.3 后序遍历 2.3.1 后序遍历递归实现 1 2 3 4 5 6 7 8 void postoder (BTNode *p) {if (p!=NULL ){
2.3.2 后序遍历非递归实现 后序遍历的非递归实现可以看作是如下两个步骤的结果:
将先序遍历的左右子树遍历顺序交换得到逆后序遍历序列;
对逆后序遍历序列进行逆序操作得到后序遍历序列;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 void postorderNonrecursion (BTNode *bt) {if (bt != NULL ){int top1 =-1 ;int top2 =-1 ;NULL ;while (top1!=-1 ){ if (p->lchild != NULL )if (p->rchild != NULL )while (top2!=-1 ){
2.4 层序遍历 层序遍历借助一个循环队列实现。先将头结点入队,然后出队,对该结点执行访问操作
若该结点有左子树,则将左子树的根结点入队
若该结点有右子树,则将右子树的根结点入队
然后出队,继续对出队的结点进行访问
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void level (BTNode *p) { int front,rear;0 ;if (p!=NULL ){1 )%maxSize;while (front != rear){ 1 )%maxSize; if (q->lchild != NULL ){1 )%maxSize;if (q->rchild != NULL ){1 )%maxSize;
3.线索二叉树的遍历 线索二叉树的意义在于,二叉树被线索化后近似一个线性结构,分支结构的遍历操作因此转换为近似线性结构的遍历操作,通过线索的辅助使得寻找当前结点的前驱或后继的平均效率大大提高。
3.1 中序线索二叉树 3.1.1 线索化 基本思想很简单,即采用二叉树中序递归遍历算法,在遍历过程中连接上合适的线索即可。当整颗二叉树遍历完成,线索化也随之完成
左线索指针指向当前结点在中序遍历序列中的前驱结点
右线索指针指向后继结点
1 2 3 4 5 6 7 8 9 void CreateInThread (TBTNode *root) {NULL ;if (root != NULL ){NULL ; 1 ;
其中的核心函数InThread如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void InThread (TBTNode *p,TBTNode *&pre) { if (p!=NULL ){if (p->lchild==NULL ){ 1 ;if (pre!=NULL && pre->child==NULL ){ 1 ;
3.1.2 遍历 中序线索二叉树的结点中隐含了线索二叉树的前驱和后继信息。在对其进行遍历时,只要先找到序列中的第一个结点,然后依次找结点的后继,直至其后继为空。
在中序线索二叉树中找结点后继的规律是:若其右标志为“1”,则右链为线索,指示其后继,否则遍历右子树中第一个访问的结点(右子树中最左下的结点)为其后继。
1 2 3 4 5 void Inorder (TBTNode *root) { for (TBTNode *p=First(root);p!=NULL ;p=Next(p)){
1 2 3 4 5 TBTNode *First (TBTNode *p) { while (p->ltag==0 )return p;
1 2 3 4 5 6 TBTNode *Next (TBTNode *p) {if (p->rtag==0 )return First(p->rchild); else return p->rchild;
3.2 前序线索二叉树 3.2.1 线索化
代码结构与中序线索化相似,区别在于将连接线索的代码提前到两个递归入口的前面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void preThread (TBTNode *p,TBTNode *&pre) {if (p!=NULL ){if (p->lchild==NULL ){1 ;if (pre!=NULL && pre->rchild==NULL ){1 ;if (p->ltag==0 ){if (p->rchild==0 ){
3.2.2 遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 void preorder (TBTNode *root) {if (root!=NULL ){while (p!=NULL ){while (p->ltag==0 ){
3.3 后序线索二叉树 3.3.1 线索化
代码结构与中序线索化相似,区别在于将连接线索的代码放到两递归入口的后面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void postThread(TBTNode *p,TBTNode *&pre){if (p!=NULL ){if (p->lchild ==NULL){lchild =pre;tag =1;if (pre!=NULL && pre->rchild ==NULL){rchild =p;tag =1;pre =p;
4.并查集的基本操作 4.1 初始化 1 2 3 4 void initial (int S[]) {for (int i=0 ;i<SIZE;i++)-1 ;
4.2 原始操作 4.2.1 原始查找 该函数返回x所属的根结点,时间复杂度为O(n)(即树的高度)
1 2 3 4 5 int Find (int S[],int x) {while (S[x]>0 )return x;
4.2.2 原始合并 无论是原始还是优化后的合并操作的时间复杂度均为O(1),主要影响的是查找操作的时间复杂度
1 2 3 4 5 void Union (int S[],int Root1,int Root2) {if (Root1==Root2)return ;
若要合并两个非根结点,则先使用Find找到对应的根结点后,再对两个根结点执行Union操作
4.3 优化操作 4.3.1 优化合并 使得树高不超过[logn]+1,使Find操作的复杂度降低为O(logn)
1 2 3 4 5 6 7 8 9 10 11 12 void Union (int S[],int Root1,int Root2) {if (Root1==Root2)return ;if (S[Root2]>S[Root1]){ else {
4.3.2 优化查找(压缩路径) 压缩路径后,Find操作的时间复杂度低于O(logn)(甚至可能为常数级别)
1 2 3 4 5 6 7 8 9 10 11 int Find (int S[],int x) { int root=x;while (S[root]>=0 )while (x!=root){ int t=S[x];return root;
六、图 1.基本数据结构定义 1.1 邻接矩阵定义 邻接矩阵是图的顺序存储结构
1 2 3 4 5 6 7 8 9 10 typedef struct Vertextype {int no; char info; typedef struct MGraph {int edges[maxSize][maxSize]; int n,e;
1.2 邻接表定义 邻接表是图的链式存储结构,由顶点表和边表两部分组成
顶点表结点存储顶点信息和指向第一个边表结点的指针
边表结点存储与当前顶点邻接的顶点序号以及指向下一边表结点的指针
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct ArcNode {int adjvex; struct ArcNode *nextarc ;int info; typedef struct VNode {char data; typedef struct AGraph {int n,e;
2.图的遍历 2.1 深度优先(DFS) 图的深度优先类似二叉树的先序遍历。二叉树的先序遍历对每个结点需要递归访问两个分支,图的深度优先需要递归访问多个分支。
算法执行过程如下:
任取一个顶点访问;
检查这个顶点的所有邻接顶点,递归访问其中未被访问的顶点
以邻接表为存储结构的DFS如下
1 2 3 4 5 6 7 8 9 10 11 12 int visit[maxSize]; void DFS (AGragh *G,int v) { 1 ; while (p!=NULL ){ if (visit[p->adjvex]==0 )
2.2 广度优先(BFS) 图的广度优先类似树的层序遍历,同样需要借助队列实现。算法执行流程如下:
任取图中一个顶点访问,将该顶点入队并标记为已访问;
队列非空时执行遍历循环:出队,依次检查出队顶点的所有邻接顶点,访问没有被访问过的邻接顶点并将其入队;
队列空时跳出循环表示遍历完成;
以邻接表为存储结构的广度优先搜索算法如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void BFS (AGraph *G,int v,int visit[maxSize]) {int que[maxSize].front=0 ,rear=0 ; int j;1 ;1 )%maxSize; while (front!=rear){ 1 )%maxSize; while (p!=NULL ){ if (visit[p->adjvex]==0 ){ 1 ;1 )%maxSize;
2.3 非连通图的遍历 上述遍历代码针对的是连通图,针对非连通图直接暴力遍历每个顶点即可
2.3.1 深度优先 1 2 3 4 5 6 void dfs (AGrapg *g) {for (int i=0 ;i<g->n;i++){if (visit[i]==0 )
2.3.2 广度优先 1 2 3 4 5 6 void bfs (AGraph *g) {for (int i=0 ;i<g->n;i++){if (visit[i]==0 )
3.最小生成树 普里姆和克鲁斯卡尔算法都是针对无向图的最小生成树算法
3.1 普里姆算法 从树中某个顶点v0开始,构造生成树的算法执行过程如下:
将v0到其他顶点的所有边作为候选边;
重复以下步骤n-1次使得其他n-1个顶点被归入树中:
从候选边中挑选出权值最小的边输出,并将与该边另一端相连的顶点v并入树中;
考察所有甚于顶点vi,若(v,vi)的权值比lowcost[vi]小则更新该值
以邻接矩阵为图的存储结构的普里姆算法如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Prim (MGraph g,int v0,int &sum) {int lowcost[maxSize],vset[maxSize],v; int i,j,k,min;for (i=0 ;i<g.n;i++){ 0 ; 1 ; 0 ; for (i=0 ;i<g.n-1 ;i++){ for (j=0 ;j<g.n;j++){ if (vset[j]==0 && lowcost[j]<min){1 ;for (j=0 ;j<g.n;j++){if (vset[j]==0 && g.edges[v][j]<lowcost[j])
该算法的核心部分是双重循环,因此该算法的时间复杂度为O(n^2^)
3.2 克鲁斯卡尔算法 算法思想非常直接:每次找出侯选边中权值最小的边,将该边并入生成树中,重复该操作直到所有边都被检测完
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 typedef struct Road {int a,b; int w; void KrusKal (MGraph g,int &sum,Road road[],int v[]) { int N=g.n; int E=g.e; 0 ; for (int i=0 ;i<E;i++)-1 ; for (int i=0 ;i<E;i++){ int a=Find(road[i].a);int b=Find(road[i].b);if (a!=b){
算法的时间花费主要在sort和单层循环,更一般的,克鲁斯卡尔算法的时间复杂度由所选取的排序算法决定。排序算法处理的数据规模由图的边数决定,与图的顶点数无关,该算法适用于稀疏图。
4.最短路径 以下两个算法均针对有向图的最短路径
4.1 迪杰斯特拉算法 该算法需要三个辅助数组:
dist[vi]表示从源顶点到vi的最短路径长度
path[vi]表示从源顶点到vi的最短路径上vi的前一个结点
set[vi]标记了顶点vi是否已经被归入最短路径中
该算法的执行流程如下:
从当前dist[]数组中选出最小值并将该顶点vu的set设置为1;
以vu为中间顶点更新源顶点到剩余未被归入的顶点的路径长度;
对1、2执行n-1次得到源顶点到其余n-1个结点的最短路径;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void Dijstra(MGraph g,int v,int dist [],int path[]){ int set[maxSize]; for (int i=0 ;i<g.n ;i++){ dist [i]=g.edges [v][i];0 ;if (g.edges [v][i]<INF)else 1 ;1 ;1 ;for (int i=0 ;i<g.n -1 ;i++){int min=INF;for (int j=0 ;i<g.n ;j++){ if (set[j]==0 && dist [j]<min){int u=j;dist [j];1 ; for (int j=0 ;i<g.n ;j++){ if (set[j]==0 &&dist [u]+g.edges [u][j]<dist [j]){dist [j]=dist [u]+g.egdes [u][j];
因为是嵌套双层循环,所以可以得出时间复杂度为O(n^2^)
利用path数组可以输出源顶点到目标顶点的路径,借助栈实现
1 2 3 4 5 6 7 8 9 10 void printfPath (int path[],int a) { int stack [maxSize],top=-1 ; while (path[a]!=-1 ){stack [++top]=a;stack [++top]=a;while (top!=-1 )cout <<stack [top--]<<" " ;
4.2 弗洛伊德算法 迪杰斯特拉是求解图中某一顶点到其他顶点的最短路径,弗洛伊德可以求解图中任意两个顶点之间的最短路径(并且算法更加简单,只是时间复杂度较高)
需要使用两个辅助数组:
A用于记录当前任意两个顶点最短路径的长度
Path用于记录当前两个顶点最短路径上的中间顶点
算法流程如下:
初始化两个矩阵,将图的邻接矩阵赋值给A,将Path中的所有元素设置为-1;
以顶点k为中间顶点,对图中所有顶点对的路径进行更新;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void Floyd (MGraph *g;int path[][maxSize],int A[][maxSize]) { for (int i=0 ;i<g->n;i++){ for (int j=0 ;j<g->n;j++){ -1 ;for (int k=0 ;k<g->n;k++){ for (int i=0 ;i<g->n;i++){for (int j=0 ;j<g->n;j++){if (A[i][j]>A[i][k]+A[k][j]){
因为主要部分是三层循环,故该算法的时间复杂度为O(n^3^)
借助矩阵A和矩阵Path可以输出任意两个顶点间的最短路径序列
1 2 3 4 5 6 7 8 9 10 11 12 13 void printPath (int u,int v,int path[][maxSize],int A[][maxSize]) { if (A[u][v]==INF)return ; else {if (path[u][v]==-1 )else {int mid=path[u][v];
5.拓扑排序 5.1 顺拓扑排序 在一个有向图无环图中找到拓扑排序的基本流程如下:
从有向图中找到入度为0的顶点输出;
删除1中的顶点以及从该顶点出发的全部边;
重复上述两步直到图中不存在入度为0的点;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 int topSort (AGraph *G) {int i,j,n=0 ;int stack [maxSize].top=-1 ; for (i=0 ;i<G->n;i++){ if (G->adjlist[i].count==0 )stack [++top]=1 ; while (top!=-1 ){ stack [top--];cout <<i<<" " ; while (p!=NULL ){if (G->adjlist[j].count==0 ) stack [++top]=j; if (n==G->n)return 1 ;else return 0 ;
5.2 逆拓扑排序 在一个有向图无环图中找到逆拓扑排序的基本流程如下:
从有向图中找到出度为0的顶点输出;
删除1中的顶点以及到达该顶点的全部边;
重复上述两步直到图中不存在出度为0的点;
逆拓扑排序可以借鉴顺拓扑排序的算法思想,但更常考的是利用深度优先实现逆拓扑排序,只需要修改深度优先代码中的Visit(v);代码段的位置即可
1 2 3 4 5 6 7 8 9 10 11 12 int visit[maxSize];void DFS (AGraph *G,int v) {1 ;while (p!=NULL ){if (visit[p->adjvex]==0 )
七、内部排序
若没有特殊说明,本章所有排序算法都默认是非递减排序。
1.插入类排序 1.1 直接插入排序 算法思想:每趟排序都将一个待排序的关键字按照其大小插入到有序序列的适当位置,直到所有待排序关键字都被插入到有序序列中
1 2 3 4 5 6 7 8 9 10 void InsertSort (int R[],int n) { int temp;for (int i=1 ;i<n;i++){ for (int j=i-1 ;j>=0 &&temp<R[j];j--){ 1 ]=R[j]; 1 ]=temp;
时间复杂度分析:
空间复杂度分析:算法所需辅助空间不随无序序列的规模变化而变化(常量),故空间复杂度为O(1)
1.2 折半插入排序 折半插入排序算法是对直接插入排序算法的一种改进,它通过减少比较次数来提高排序的效率。这个算法与直接插入排序算法的不同之处在于,在寻找插入位置时使用了二分查找,这样可以减少比较的次数,从而提高了排序的效率。在实际应用中,折半插入排序通常比直接插入排序更快,特别是对于大型数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void BinaryInsertSort (int R[],int n) {int i,j,low,high,mid,temp;for (int i=1 ;i<n;i++){0 ;-1 ;while (low<=high){ 2 ;if (temp<R[mid])-1 ;else 1 ;for (j=i-1 ;j>=low;j--){ 1 ]=R[j];
时间复杂度分析:
最好情况:O(nlogn)
最坏情况:O(n^2^)
平均情况:O(n^2^)
空间复杂度仍然为O(1)
1.3 希尔排序 希尔排序又称为缩小增量排序,是对直接插入排序的一种改进(直接插入排序适用于序列基本有序的情况)。希尔排序的每趟排序都会使得序列整体更加有序,减少了元素的移动次数提升效率。
其代码类比直接插入排序,相当接近
1 2 3 4 5 6 7 8 9 10 11 12 void ShellInsert (int arr[],int n) { int temp;for (int gap=n/2 ;gap>0 ;gap/=2 ){ for (int i=gap;i<n;i++){ for (int j=i-gap;j>=0 &&temp<arr[j];j-=gap){
希尔排序的时间复杂度和增量的选取相关(无论怎么选,增量的最后一个值一定取1):
增量从n/2开始,每次都除以2向下取整,此时时间复杂度为O(n^2^);
另一种情况是选取增量为2^k^+1<=n,此时时间复杂度为O(n^1.5^);
希尔排序的空间复杂度为O(1)
2.交换类排序 2.1 起泡排序 每趟起泡排序都会使得无序序列中最大的关键字被交换到最后,起泡排序算法的结束条件是在一趟排序过程中没有发生关键字的交换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void BubbleSort (int R[],int n) { int i,j,flag;int temp;for (i=n-1 ;i>=1 ;i--){ 0 ; for (j=1 ;j<=i;++j){ if (R[j-1 ]>R[j]){ -1 ];-1 ]=temp;1 ;if (flag=0 )return ;
时间复杂度分析:
最坏情况:待排序列逆序,基本操作总的执行次数为n(n-1)/2,时间复杂度为O(n^2^)
最好情况:待排序列有序,内层循环不执行,时间复杂度为O(n)
平均情况:时间复杂度为O(n^2^)
空间复杂度:辅助数组仅有temp一个,空间复杂度为O(1)
2.2 快速排序 一趟快速排序的过程实际就是对无序序列进行一次划分的过程,划分后比枢轴小的关键字都在枢轴左边,比枢轴大的关键字都在枢轴右边。每趟快速排序结束后都会有一个关键字到达最终位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void QuickSort (int R[],int low,int high) { int temp;int i=low,j=high;if (low<high){ while (i<j){ while (i<j && R[j]>=temp)if (i<j){while (i<j && R[j]<temp)if (i<j){-1 ); 1 ,high);
时间复杂度分析(快速排序的排序趟数与初始序列有关,待排序列越无序算法效率越高,待排序列越有序算法效率越低):
最好情况:O(nlogn)
最坏情况:O(n^2^)。当初始序列有序或基本有序时,快速排序退化为冒泡排序
平均情况:O(nlogn)
3.选择类排序 3.1 简单选择排序 算法思想:从头到尾顺序扫描无序序列,选择最小的关键字与第一个关键字交换,接着从剩下的无序序列的关键字中继续这种选择和交换,最终使得序列有序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void SelectSort (int R[],int n) {int i,j,k;int temp;for (i=0 ;i<n;i++){for (j=i+1 ;j<n;j++){ if (R[k]>R[j])
时间复杂度分析:简单选择排序的双层循环的执行次数和初始序列没有关系,基本操作执行总次数为n(n-1)/2,时间复杂度为O(n^2^)
空间复杂度分析:O(1)
简单选择排序有两个版本,数组使用交换版(不稳定),链表使用插入版(稳定)
3.2 堆排序 堆排序也称为快速选择排序,它在借助堆的性质可以很快选出序列中的最值。堆排序整个过程就是不断调整堆,使得不符合堆定义的完全二叉树变为符合堆定义的完全二叉树(下面代码假设完全二叉树从下标1开始存储,若从0开始存储则某些规则会有小变动)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Sift (int R[],int low,int high) { int i=low,j=2 *i; int temp=R[i]; while (j<=high){if (j<high && R[j]<R[j+1 ]) if (temp<R[j]){ 2 *i; else break ;
1 2 3 4 5 6 7 8 9 10 11 12 13 void heapSort (int R[],int n) {int i,temp;for (int i=n/2 ;i>=1 ;i--){ for (i=n;i>=2 ;i--){ 1 ]=R[i];1 ,i-1 );
时间复杂度分析(适用于关键字个数非常多的情况下的排序):
平均时间复杂度:对于函数Sift()即对每个结点调整的时间复杂度为O(logn);对于函数heapSort,其基本操作总次数为两个并列for循环的基本操作次数之和,第一个for循环的基本操作次数为n/2*O(logn),第二个for循环的基本操作次数为(n-1)*O(logn),故最终时间复杂度为O(nlogn)
最坏时间复杂度:O(nlogn)
空间复杂度分析:算法所需辅助空间不随待排序列规模变化而变化,故空间复杂度为O(1)(是所有时间复杂度为O(nlogn)中空间复杂度最小的)
4.二路归并排序 归并排序可以看作是分治法的具体使用:先将整个序列分为两半,对每一半分别进行归并排序得到两个有序序列,将这两个有序序列归并为一个有序序列即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void merge (int arr[],int low,int mid,int high) {int i,j,k;int n1=mid-low+1 ; int n2=high-mid; int L[n1],R[n2]; for (i=0 ;i<n1;i++){ for (j=0 ;j<n2;j++){1 +j];0 ;0 ;while (i<n1 && j<n2){ if (L[i]<R[j]) else while (i<n1) while (j<n2)
1 2 3 4 5 6 7 8 9 void mergeSort (int A[],int low,int high) {if (low<high){int mid=(low+high)/2 ;1 ,high);
时间复杂度分析:选择merge内的归并操作为基本操作,其执行次数为要归并的两个子序列中关键字之和,整个归并排序总的基本操作执行次数为nlogn,时间复杂度为O(nlogn)。归并排序时间复杂度和初始序列无关,即最好、最坏以及平均时间复杂度均为O(nlogn)
空间复杂度分析:归并排序需要转存整个待排序列,故空间复杂度为O(n)
5.基数排序 基数排序的算法代码不做要求,假设n为待排序列中关键字的个数,d为待排关键字的位数,rd为关键字基的个数(桶的个数)。
时间复杂度分析(适用于关键字很多但关键字的基较小):一趟“分配”和“收集”需要的时间为n+rd,整个排序需要d趟“分配”和“收集”,故时间复杂度为O(d(n+rd))
空间复杂度分析:每个桶实际都是一个队列,共rd个桶故空间复杂度为O(rd)
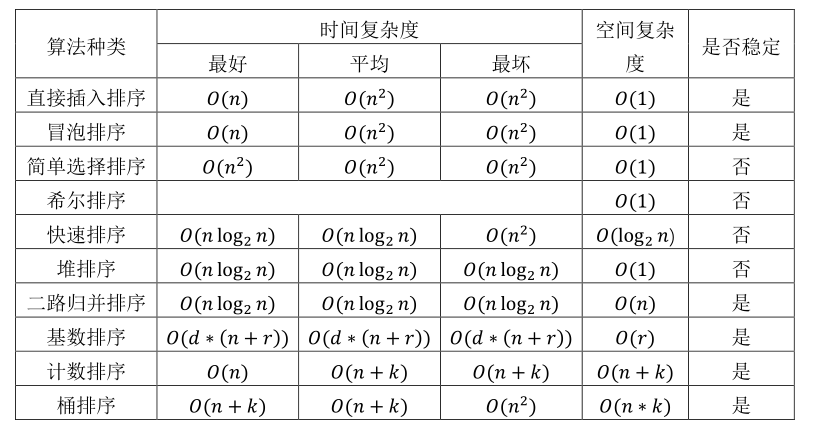
6.排序算法助记 6.1 时间复杂度与稳定性 下图是常见内部排序的时间复杂度与稳定性总结,需要记忆的是平均时间复杂度以及稳定性
“村里有两只动物,一只叫插帽龟(插入、冒泡、归并),一只叫做统计鸡(桶、计数、基数),它两做事情非常稳重(稳定)。
统计鸡喜欢做数学运算(加法和乘法,对应桶、计数、基数排序的平均时间复杂度)。某一天,插帽龟在选择帽子插的时候,恩姓长老慌了(选择、冒泡、插入,时间复杂度为n^2^),恩老大喊:“快点归还给堆”(快速、归并以及堆的时间复杂度为nlogn)。
”
最坏情况下,桶排序和快速排序的时间复杂度为O(n^2^),其他与平均情况下相同(最好情况下的时间复杂度意义不大)
6.2 算法思想 下面这张表格帮助速记算法思想(仅仅针对我下面给出的代码,对其他书写风格的代码可能不适用)
算法
思想
插入排序(直接插入、折半、希尔)
前有序,后无序,无序逐个插有序(每趟无序第一个成为有序)
冒泡排序
前无序,后有序,无序换大到有序(每趟无序最后一个成为有序)
快速排序
j往左,i往右,j小i大换i,j,指针相遇填枢轴
简单选择排序
前有序,后无序,无序选小到有序(每趟无序第一个成为有序)
堆排序
前无序,后有序,无序选首到有序(每趟无序最后一个成为有序)
二路归并排序
从前往后两两归并(每个归并后的子序列分别内部有序)
6.3 常见结论
直接插入在“容易插”的情况下是O(n),起泡“起得好”的情况下是O(n),此处的“容易插和起得好”都指初始序列有序;快速排序反着来,“待排序列越无序算法效率越高,待排序列越有序算法效率越低”;
交换类(起泡、快速)和选择类(简单选择、堆)经过一趟排序,能够保证一个关键字到达最终位置
交换类排序,其排序趟数和原始序列相关
简单选择和折半插入,其关键字比较次数与原始序列无关(即比较次数一定)
八、查找 查找算法的基本操作是关键字的比较,而关键字的比较次数与待查找的关键字有关(即对同一个查找表中的不同关键字进行查找,关键字的比较次数一般不同)。因此一般将关键字的平均比较次数(也称为平均查找长度)作为衡量查找算法的指标。平均查找长度ASL的定义如下
其中n是查找表中记录的个数,pi是查找第i个记录的概率(一般取1/n),ci是找到第i个记录所需比较的次数,即查找长度。本章的算法没什么难度,难度主要就在ASL的分析上,针对每个查找算法给出详细的ASL计算步骤。
1.线性存储结构 1.1 顺序查找 1 2 3 4 5 6 7 8 int Search (int arr[],int n,int key) {for (int i=0 ;i<n;i++){if (arr[i]==key)return i; return -1 ;
1 2 3 4 5 6 7 8 9 10 11 Search (LNode *head,int key) {while (p!=NULL ){if (p->data==key){return p;return NULL ;
1.2 折半查找 1 2 3 4 5 6 7 8 9 10 11 12 13 int Bsearch (int R[],int low,int high,int k) {int mid;while (low<=high){2 ;if (R[mid]==k)return mid;else if (R[mid]>k)-1 ;else 1 ;return -1 ;
2.排序二叉树 2.1 查找 二叉树的查找算法思想与折半查找非常类似,直接看代码就可以理解,需要注意的是如果最后指向空指针域则表示查找失败。
非递归实现如下
1 2 3 4 5 6 7 8 9 10 11 BTNode *BSTSearch (BTNode *p,int key) {while (p!=NULL ){if (key==p->key)return p;else if (key<p->key)else return NULL ;
递归实现如下
1 2 3 4 5 6 7 8 9 10 11 12 BTNode *BSTSearch (BTNode *p,int key) {if (p==NULL )return NULL ;else {if (p->key==key)return p;else if (key<p->key)return BSTSearch(p->lchild,key);else return BSTSearch(p->rchild,key);
2.2 插入 二叉排序树的本质就是一个查找表,因此插入一个关键字首先需要找到插入位置,对于一个不存在于二叉排序树中的关键字,其查找不成功的位置就是该关键字的插入位置(插入已有的关键字视为违规操作)。代码方面只需要对查找操作修改,来到空指针域时插入即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int BSTInsert (BTNode *&p,int key) {if (p==NULL ){ malloc (sizeof (BTNode));NULL ; return 1 ;else {if (key==p->key)return 0 ; else if (key<p->key)return BTSInsert(p->lchild,key);else return BTSInsert(p->rchild,key);
2.3 构造 借助上述插入操作,只需要建立一棵空树,然后将关键字逐个插入到空树中即可构建一棵二叉排序树
1 2 3 4 5 void CreateBST (BTNode *&bt,int key[],int n) {NULL ;for (int i=0 ;i<n;i++)