三维重建基础
参考视频:
- 计算机视觉之三维重建篇(精简版) 北京邮电大学 鲁鹏_哔哩哔哩_bilibili(与机器视觉那门课中的三维重建部分不同,这个视频介绍的更简洁、更易懂,强推!);
- CV-xueba的个人空间-CV-xueba个人主页-哔哩哔哩视频 (bilibili.com)(这部分属于三维重建的应用,前半部分和上面是重合的,直接看后面部分就行);
参考笔记:
- 机器视觉基础 - Tintoki_blog (gintoki-jpg.github.io)(该笔记整理自机器视觉的三维重建部分,比较详细但0基础可能看不懂,推荐看完本博客的基础部分再看这个链接);
2023/10/13 10:15 三维重建基础实际上在机器视觉基础那门课程中就已经介绍过,但是因为当时课程时间比较紧张并没有细致进行学习(特别是最后面的运动恢复结构),只是囫囵吞枣式的总结了相关笔记。本篇博客将用通俗易懂的语言将三维重建中涉及的基础知识以及核心内容进行展现;
这篇博客中可能会看到一些机器视觉基础那篇博客的重复知识点,但更多的是在此基础上的再理解,推荐先过一遍基础知识再看本篇博客;
前面给出的视频链接讲的非常好,特别是有之前机器视觉的基础过后,二刷有完全不同的理解。听完之后适当做整理;
2023/10/14 15:15 影消点和影消线这部分属于新内容,刚开始第一遍听迷迷糊糊的不是很懂,可适当参考别的教程,一定要手写做笔记理解(感觉三维重建本质上就是对数学的综合应用);
当然对有些概念之间的变换可能存在疑惑,只需要用自己能够理解的方式理解即可(现在不是复现论文阶段);
2023/10/17 10:02 截止目前,鲁鹏三维重建基础篇过完,接下来就是三维重建的应用篇。再说一遍不要钻牛角尖也不要一遍又一遍的审查自己是否遗漏了某个知识点(既然这个点可以不被记住说明它不重要),学习的过程说白了就是一遍又一遍复习巩固的过程,现阶段就只是为了刷脸熟为后面的阅读文献打基础,到时候不懂的再回头看或者重新学也行;
2023/10/26 10:18 本来都打算把SLAM的知识点直接忽略掉的,但是还是放不下要完善这篇文章的冲动,因此决定跟着鲁鹏的课把这篇文章完善(也作为后续复习巩固的一个参考);
2023/11/14 22:44 今天终于把一直搁置的SLAM部分整理完了,之前其实是花大量时间学习了的,但是因为没有及时整理和回顾导致几乎已经遗忘了…这次的整理也只是简单的梳理了SLAM的大致流程,具体如果以后要深入SLAM这个领域的话还需要阅读大量的论文和代码(参考光度法三维重建的自学入门道路);
一、三维重建基础
三维重建基础主要包含以下内容
摄像机几何:摄像机几何的意义在于用数学描述摄像机是如何将三维场景映射为二维图像
摄像机标定:摄像机标定给出了如何从图像中估计摄像机的相关参数,有了这些参数就可以计算三位场景到二维图像的映射
单视图测量:主要介绍空间中的几何元素与摄像机拍摄的图像的几何元素之间的关联关系,在有些场合中利用这些关联关系就能重构出场景的三维结构
三维重建基础与极几何:主要讨论同一个场景的双视图之间的几何关系
双目立体视觉系统:在上一章的基础上,本章介绍机器人视觉中常用的双目立体视觉系统的构建以及相关理论
多视图几何:介绍如何从多幅图像中恢复场景的三维结构
1.摄像机几何
1.1 针孔摄像机模型
常规的针孔摄像机模型如下

1.2 近轴折射模型
加入透镜后,形成近轴折射模型如下

1.3 像平面&像素平面
上述两种模型实现的都是三维世界到像平面的映射,实际上的图像是存储在像素平面上的,因此需要实现像平面到像素平面的转换,主要解决坐标中心偏移和单位不一致两个问题

1.4 齐次坐标
现在,我们已经实现了空间点P到像素点P’的映射,但是这种映射变换是非线性的,因此引入齐次坐标

1.5 坐标轴偏斜
最后考虑像素坐标轴的偏斜后可以得到最终空间点P到像素点P’的映射关系

1.6 世界坐标系&摄像机坐标系
前面所述空间点到像素点的映射是在以摄像机坐标原点的摄像机坐标系下,实际上更多时候是以世界坐标系的视角进行描述。引入世界坐标系后,仅需考虑如何将世界坐标系转换到摄像机坐标系即可

2.摄像机标定
摄像机标定先求解投影矩阵,进而求解相机的内外参数
2.1 求解投影矩阵

2.2 求解内外参数

3.单视图测量
从单张视图恢复三维场景的应用场景极少,只有在特定的情况下才能使用

3.1 常见2D变换
二维空间上的点主要有以下四种常见的变换方式,可以映射为二维空间上的另一个点

可以看出,欧式变换是相似变换的特例,相似变换是仿射变换的特例,仿射变换是透视变换的特例;
上述四种变换同样适用于三维空间上的点映射为二维空间上的点;
3.2 2D平面
3.2.1 基本概念

3.2.2 无穷远点/线

3.2.3 透视变换
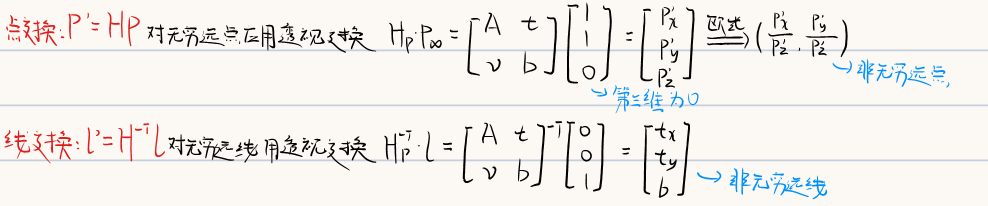
可以看到,二维空间中的无穷远点和无穷远线经过透视变换后成为了非无穷远点和非无穷远线(二维到二维)。实际上,三维空间中到二维空间中的透视变换同样有这样的效果
3.3 3D空间
3.3.1 基本概念

3.3.2 影消点&影消线

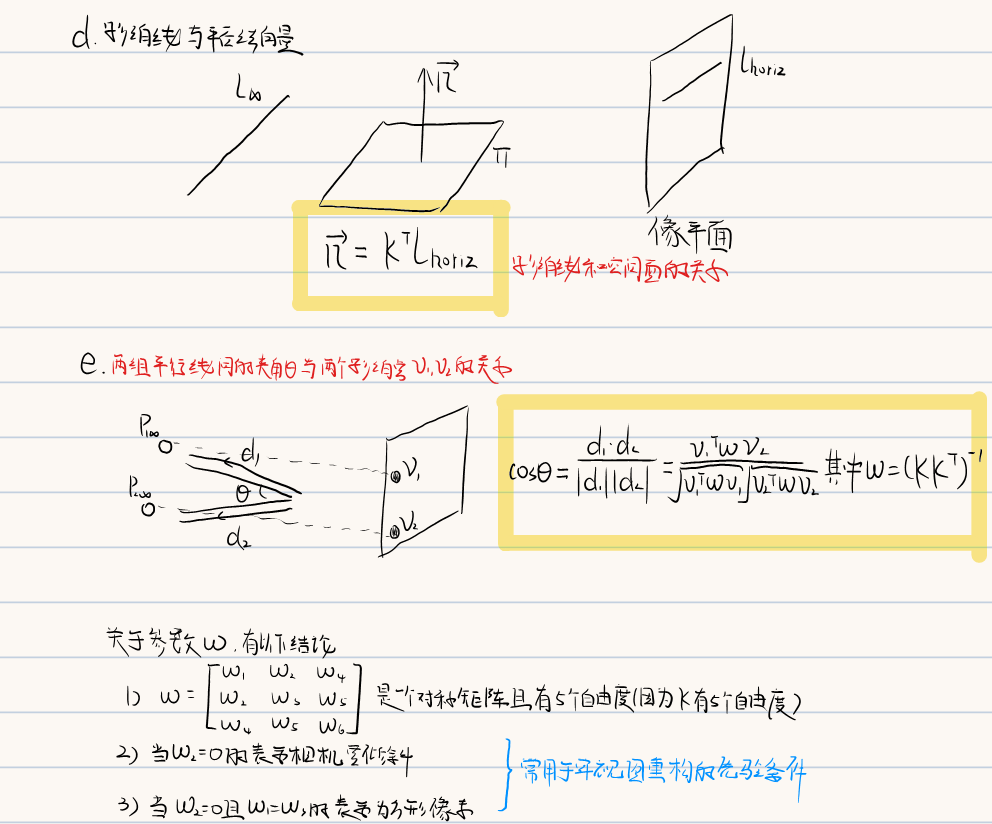
4.三维重建基础
使用单视图从2D到3D的映射具有歧义性

本章开始将介绍更加常用的三维重建方法也就是多视图重建,本章主要介绍多视图重建中的一些理论基础。因为多视图可以由两视图推广得出,因此下面常用两视图进行讲解说明。
4.1 三角化
三角化是指,已知两个相机的内参数K和K’以及两个像素点p和p’,同时相机O2到O1的旋转平移变换已知。可以知道三维点P一定是两条映射光线的交点,即
$$
P=l*l’
$$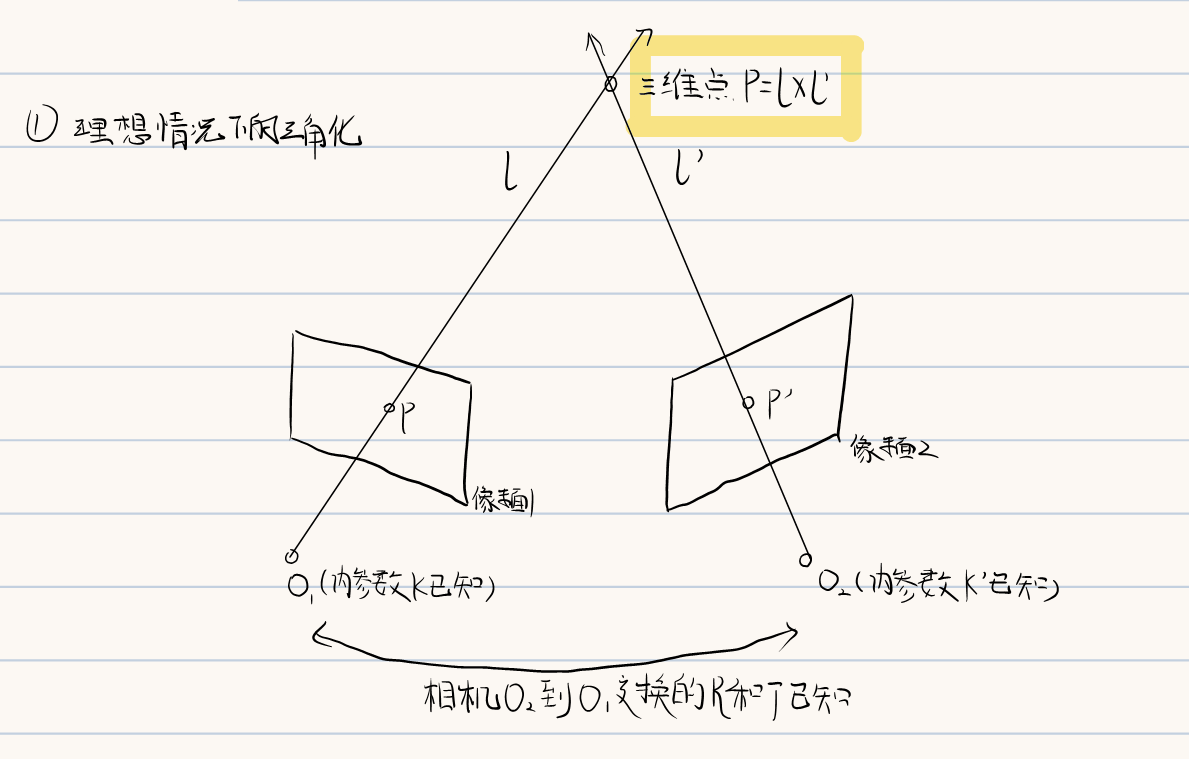
实际情况下,因为存在噪声故两直线通常不相交,因此将上述问题建模为数学问题
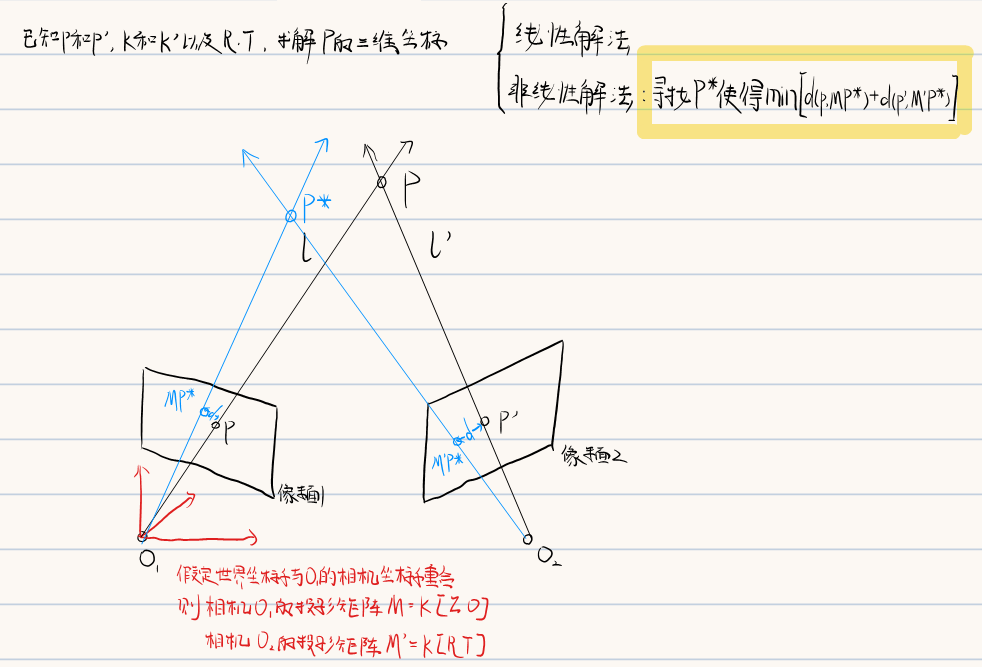
4.2 极几何
在进行三角化操作之前,需要保证某些参数是已知的,即三角化之前需要进行如下两个前置操作:
- 摄像机几何:获取摄像机的内外参数
- 极几何:已知像素面I上的一点p,如何求解另一个像素面I’上的对应点p’
极几何定理:像素点p的对应点p’一定在极线l’上
- 极几何就是约束两个对应点之间的关系(但并不能具体求出对应点,后面会介绍相关求解方法)
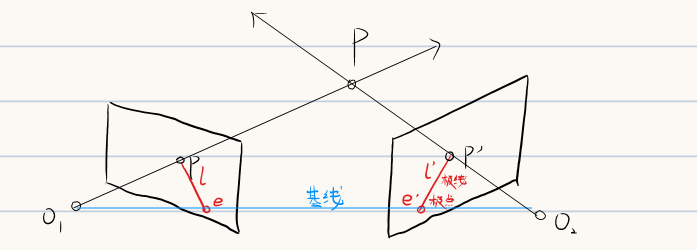
如何用代数描述两个点之间的极几何关系?这就引出下面的本质矩阵和基础矩阵的概念
4.2.1 本质矩阵
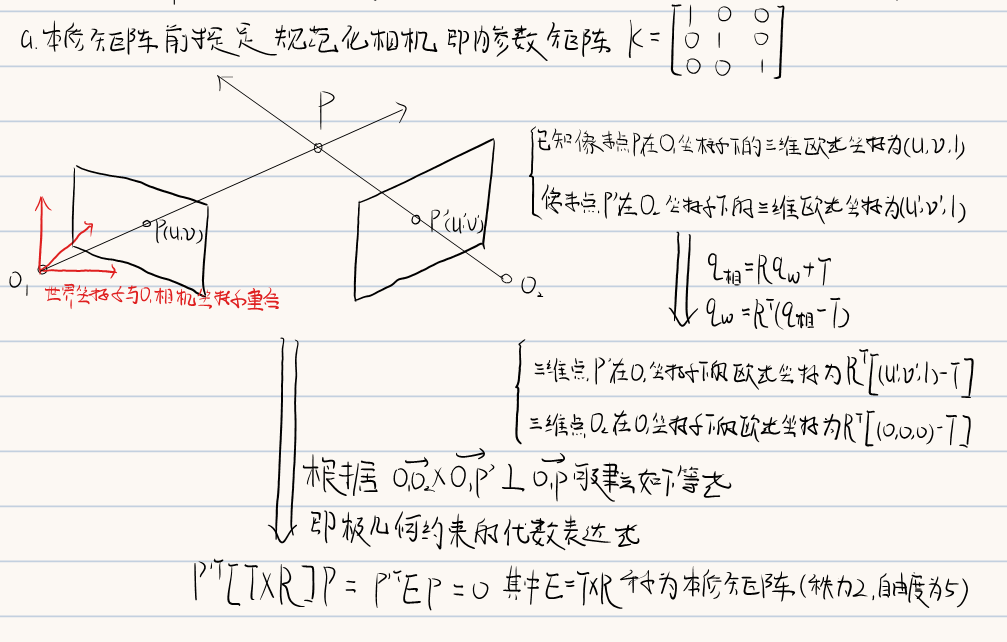
4.2.2 基础矩阵

关于使用八点算法进行基础矩阵估计,可以参考链接:三维重建-4-4.基础矩阵估计_哔哩哔哩_bilibili;
5.双目立体视觉系统
双目立体视觉系统是一种特殊的多视图几何系统,这种重建系统模拟人的视觉系统进行构建,更一般的说就是两视图为平行视图的视觉系统
5.1 平行视图下的极几何

根据极几何可以知道平行视图下p和p’的对应关系,即p的对应点p’在扫描线上,进一步的,借助相关匹配法或归一化相关匹配即可定位p的对应点p’,具体执行参考链接:三维重建-5-3平行视图的对应点搜索_哔哩哔哩_bilibili;
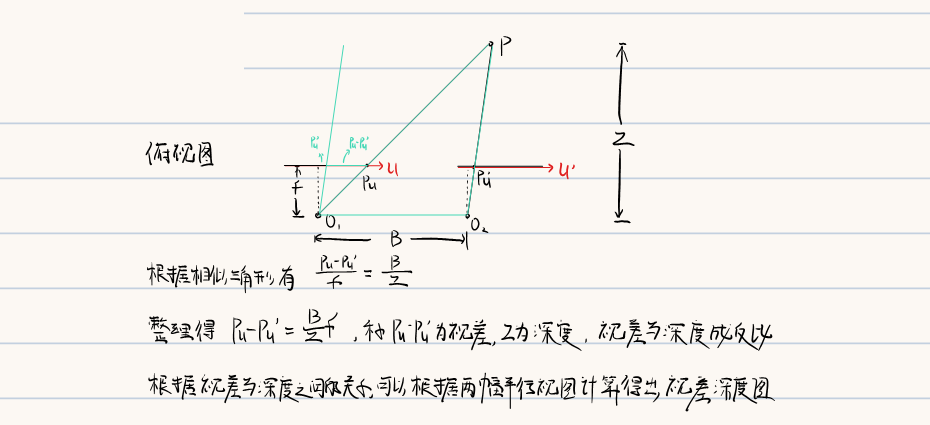
5.2 平行视图下的三角化
5.3 图像校正
实际重构的过程中,构建的两视图往往并不是真正的平行视图,此时需要借助图像校正将双目系统中的不平行的两个像素面矫正为“平行”
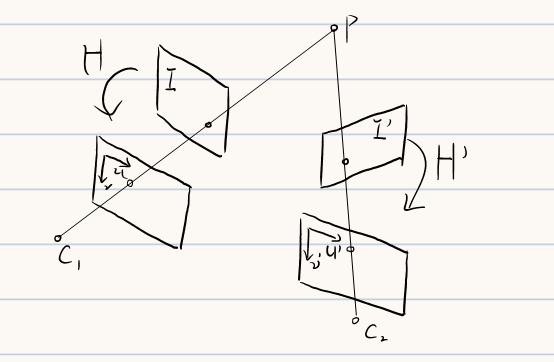
图像校正过程主要分为以下五个步骤

6.多视图几何
多视图几何主要应用于运动恢复结构,即通过三维场景的多张图像恢复出三维结构信息以及每张图片对应的摄像机参数
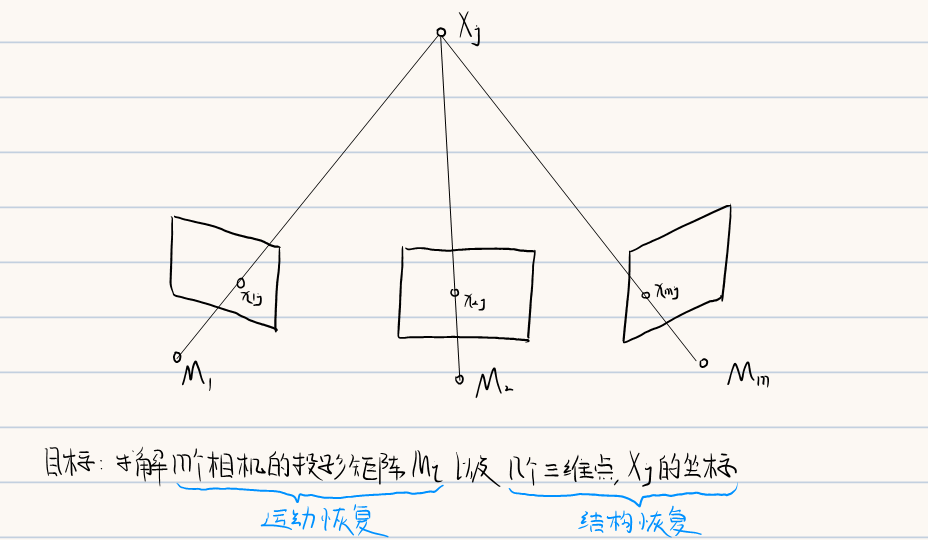
多视图几何包含了两视图的情况,且相较于上一节介绍的比较特殊的平行视图而言,运动恢复结构更加通用,主要分为以下三种典型任务:
- 欧式结构恢复:适用于扫地机器人或无人驾驶
- 仿射结构恢复:适用于待重构物体离摄像机较远且其深度变化不大的情况
- 透视结构恢复:适用范围最广,比如利用互联网下载的图片进行三维场景的恢复
下面还是以两视图的情况作介绍,可以拓展到多视图的情况
6.1 欧式结构恢复
欧式结构恢复的前提是摄像机的内参数已知而外参数未知,即内参数Ki已知,因此需要恢复的投影矩阵M的问题变为求解外参数Ri和Ti的问题
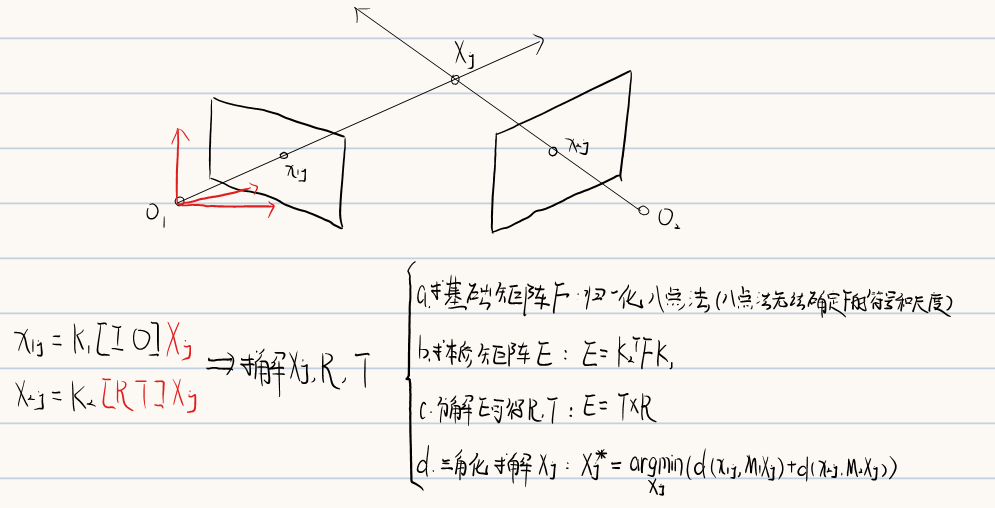
6.1.1 本质矩阵分解

6.2 仿射结构恢复
仿射相机作为透视相机的一个特例,因其参数更少因此相对透视结构恢复更易求解
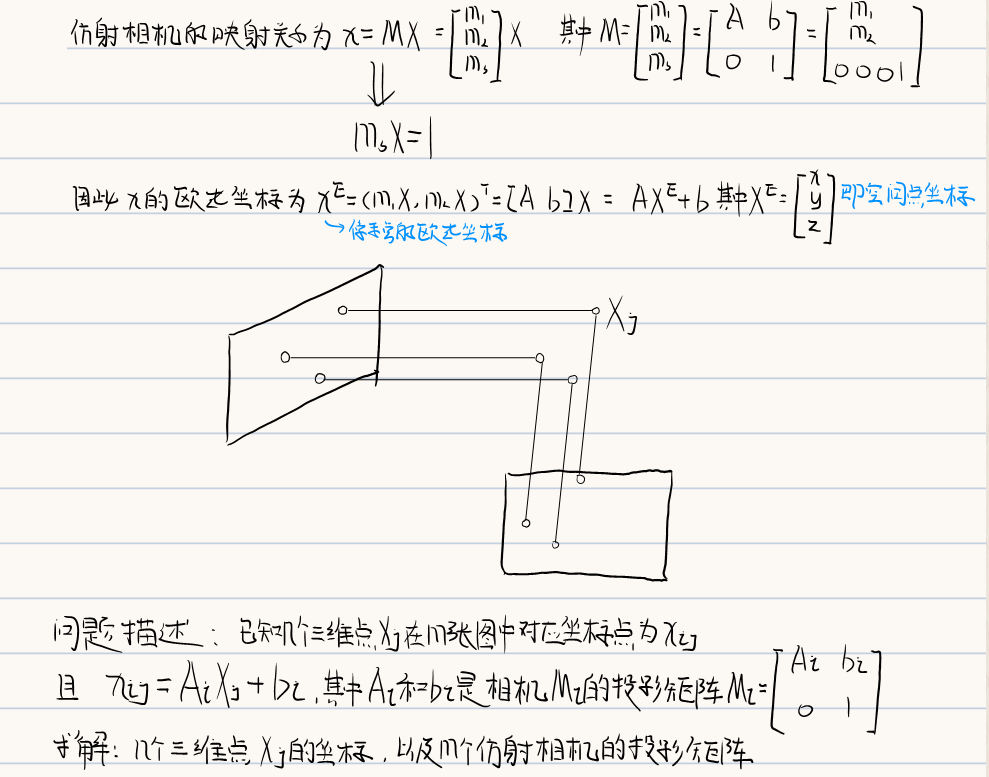
6.2.1 因式分解法
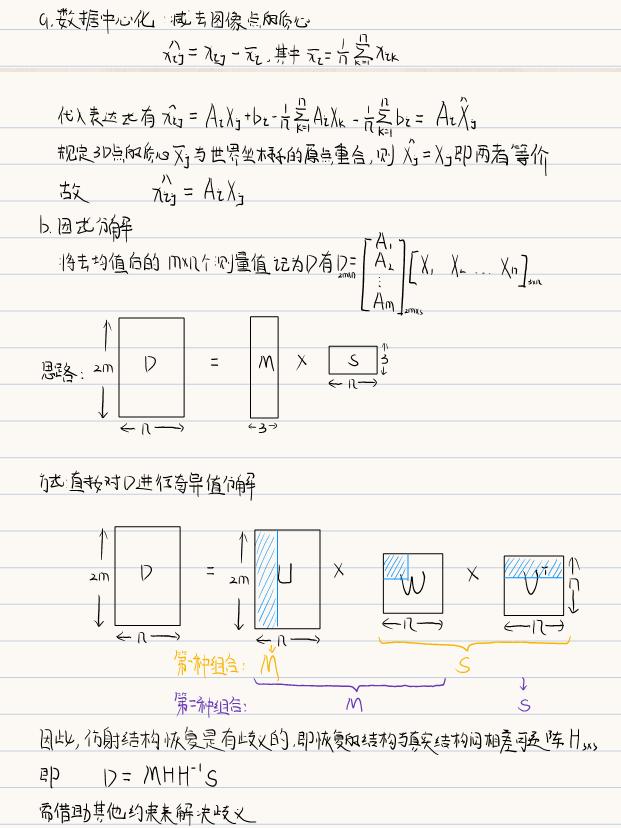
6.3 透视结构恢复

透视结构恢复的常规方法有三种:
- 代数法:适用于两视图的情况,可以借助增量法拓展到多视图的情况。缺点是会出现误差积累;
- 因式分解法:前提是假定所有的点都是可见的,因此存在遮挡或建立对应点失败的情况下不能使用该方法;
- 捆绑调整法:捆绑调整可以有效的克服前面两者的问题,但是因为是非线性最小化的思想,因此求解可能较慢。常常将代数法或因式分解法的结果作为捆绑调整法的初始解,结合使用;
6.3.1 代数法

二、三维重建应用
1.前置知识点
视频链接(直接56:39开始):计算机视觉之三维重建(深入浅出SfM与SLAM核心算法)—— 7.多视图几何(下)_哔哩哔哩_bilibili;
关于三维重建,前面的基础篇已经介绍了很多前置知识点,这里额外补充两个之后会用到的
1.1 PnP问题
PnP问题直观来说就是在已知摄像机内参数K,像素点a,b,c的二维像素点坐标以及其对应点A,B,C的三维世界坐标的情况下,求解摄像机的外参数R和T
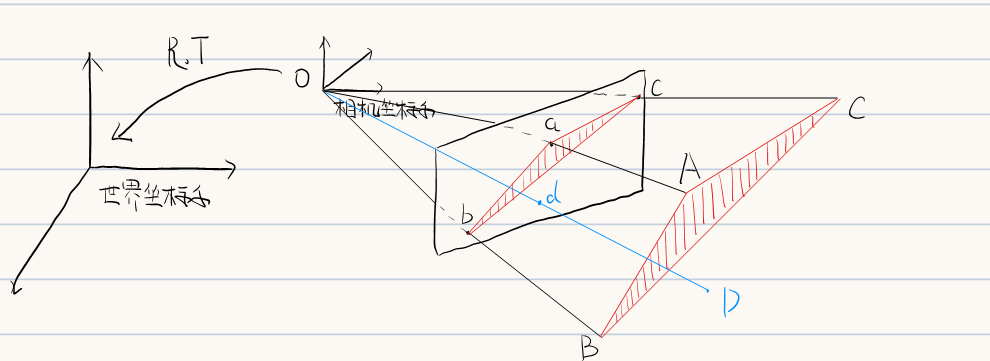
基本求解思路分为两步:
- 求解A,B,C三点在当前摄像机坐标系下的坐标;
- 通过摄像机坐标系和世界坐标系的坐标对应关系求解摄像机坐标系相对于世界坐标系的旋转R和平移T
$$
Xc=[R|T]Xw
$$
具体求解步骤如下:

1.2 RANSAC
RANSAC的详细介绍参考链接:机器视觉基础 - Tintoki_blog (gintoki-jpg.github.io);
RANSAC全称随机采样一致性,是一种适用于数据受到异常值污染的情况下的模型拟合方法。最基础的应用是使用RANSAC拟合边缘直线,实际上RANSAC也可以用于拟合三维重建中的本质矩阵或基础矩阵。
在真实的三维重建系统中一定会用到RANSAC方法,否则无法得到正确的结果。
1.3 单应矩阵
单应矩阵与本质矩阵、基础矩阵一样,描述了两幅图像像点之间的对应关系。特殊之处在于其采集的三维点都来自同一个空间平面。
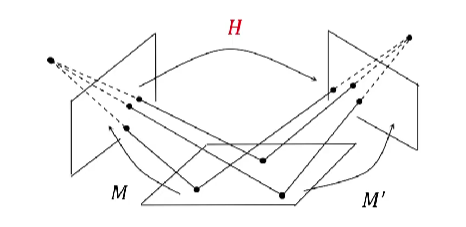
当三维点都来自同一个平面时,使用本质矩阵或基础矩阵会得到错误的结果,此时需要使用单应矩阵进行描述。
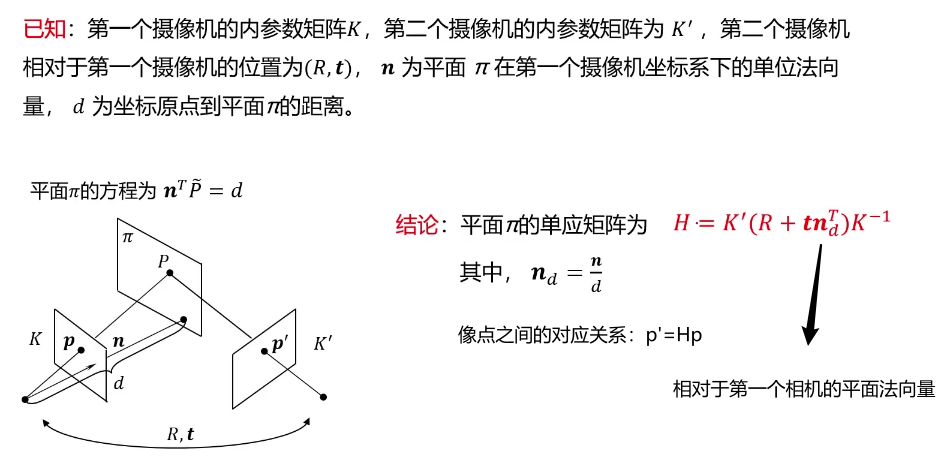
具体如何估计单应矩阵H的方法这里不介绍,感兴趣自行Google。
下面这张表格展示了本质矩阵、基础矩阵与单应矩阵之间的联系与区别

在进行三维重建系统设计时,因为无法确定三维点究竟是否位于同一个平面上,因此既考虑基础矩阵也考虑单应矩阵,最后进行投票确定具体矩阵。
1.4 词袋模型
词袋模型BoW在NL和CV领域都有提到,这里我们主要介绍词袋模型在CV领域的使用即BoVW。
词袋模型最初用于文本分类中,然后逐步引入到了图像分类任务中。在文本分类中,文本被视为一些不考虑先后顺序的单词集合。而在图像分类中,图像被视为是一些与位置无关的局部区域的集合(一袋拼图),因此这些图像中的局部区域就等同于文本中的单词。在不同的图像中,局部区域的分布是不同的(一袋“马”的拼图肯定和一袋“牛”的拼图不同)。因此,可以利用提取的局部区域的分布对图像进行识别。
注意这里的“局部区域”,一般指的是具有代表性的图像区域,也就是图像特征,一般使用SIFT提取器提取(当然直接将图像均分为局部区域也可以,但这种做法得到的拼图过多影响后续处理)
图像分类和文本分类的不同点在于,在文本分类的词袋模型算法中,字典是已存在的,不需要通过学习获得;而在图像分类中,词袋模型算法需要通过监督或非监督的学习来获得视觉词典。造成这种差异的原因是,图像中的视觉特征不像自然语言中的单词那样定义明确和被理解。因此,有必要学习一种能够有效地表示图像中特征的视觉词典。
视觉词袋(BoVW,Bag of Visual Words)模型,是“词袋”(BoW,Bag of Words)模型从自然语言处理与分析领域向图像处理与分析领域的一次自然推广。对于任意一幅图像,BoVW模型提取该图像中的基本元素,并统计该图像中这些基本元素出现的频率,用直方图的形式来表示。通常使用“图像局部特征”来类比BoW模型中的单词,如SIFT、SURF、HOG等特征,所以也被称之为视觉单词模型。
图像BoVW模型表示的直观示意图如图所示
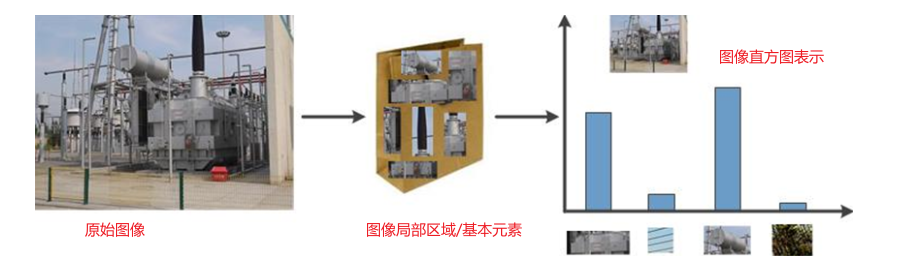
利用BoVW模型表示图像,获得图像的全局直方图表示,主要有四个关键步骤:
Step 1:图像局部特征提取(Image Local Features Extrication)。根据具体应用考虑,综合考虑特征的独特性、提取算法复杂性、效果好坏等选择特征。利用局部特征提取算法,从图像中提取局部特征。 – SIFT特征提取器
Step 2:视觉词典构造(Visual Dictionary Construction)。利用上一步得到的特征向量集,抽取其中有代表性的向量,作为单词,形成视觉词典。一般是从图像库中选取一部分来自不同场景或类别的图像来组成训练图像集,并提取其局部特征,然后对训练图像的所有局部特征向量通过适当的去冗余处理得到一些有代表性的特征向量,将其定义为视觉单词。通常所采用的处理方法是对训练图像的所有局部特征向量进行聚类分析,将聚类中心定义为视觉单词。所有视觉单词组成视觉词典,用于图像的直方图表示。 – K-means聚类
Step 3:特征向量量化(Feature Vector Quantization)。BoVW模型采用向量量化技术实现,向量量化结果是将图像的局部特征向量量化为视觉单词中与其距离最相似的视觉单词。向量量化过程实际上是一个搜索过程,通常采用最近邻搜索算法,搜索出与图像局部特征向量最为匹配的视觉单词。 – KNN最近邻聚类
Step 4:用视觉单词直方图表示图像,也称为量化编码集成(Pooling)。一幅图像的所有局部特征向量被量化后,可统计出视觉词典中每个视觉单词在该图像中出现的频数,得到一个关于视觉单词的直方图,其本质是上一步所得量化编码的全局统计结果,是按视觉单词索引顺序组成的一个数值向量(各个元素的值还可以根据一定的规则进行加权)。该向量即为图像的最终表示形式。
上述步骤很抽象,下面举一个例子来帮助理解:
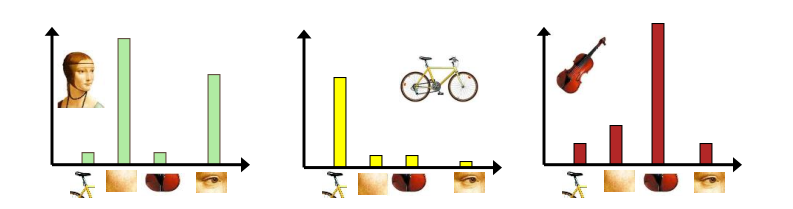
现在我们有如下三张原始图像

第一步是做局部特征提取,假设使用SIFT特征提取器提取到了如下这些特征(可以认为是拼图,我们将三张原始图像的拼图都放在一个袋子中,这就是我们的“词袋”)

第二步是视觉词典构造,也就是从上述那么多特征中选取k个单词来构成视觉词典,这里的k由人为规定(一般需要先验知识)。使用K-means聚类算法将词袋中的拼图聚为k个类,k个类别中心的拼图就是k个单词(假设我们令k=4)

第三步和第四步通常合并进行,即对词袋中的每个拼图都使用最近邻算法,寻找与其最近的在视觉词典中的单词(我们认为这两张图像属于同一个单词),找到之后对直方图中该单词的频数+1。因为我们有三张原始图像,所以对应有三个直方图,每个直方图的横轴为视觉词典中的单词,纵轴为该单词出现的频数,因此对原始三张图像的直方图表示如下
1.5 图像检索
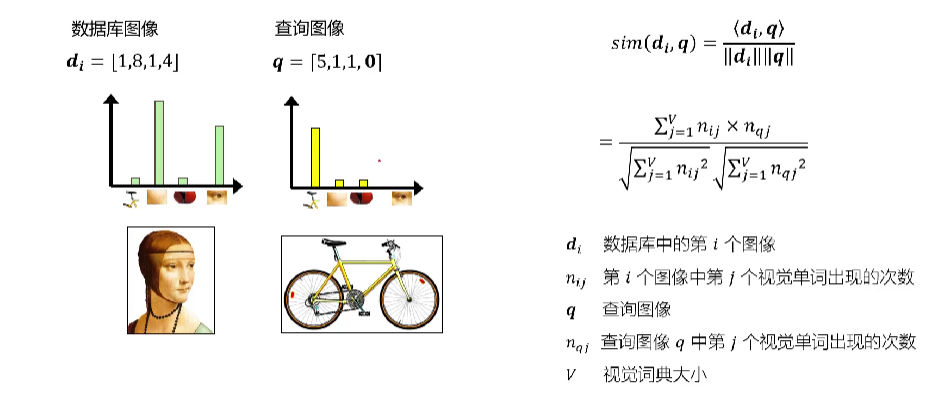
图像检索的目标是,给定一张图像,在数据库中检索,返回按照相似度进行排序后的图像序列。基于词袋模型的图像检索主要流程如下
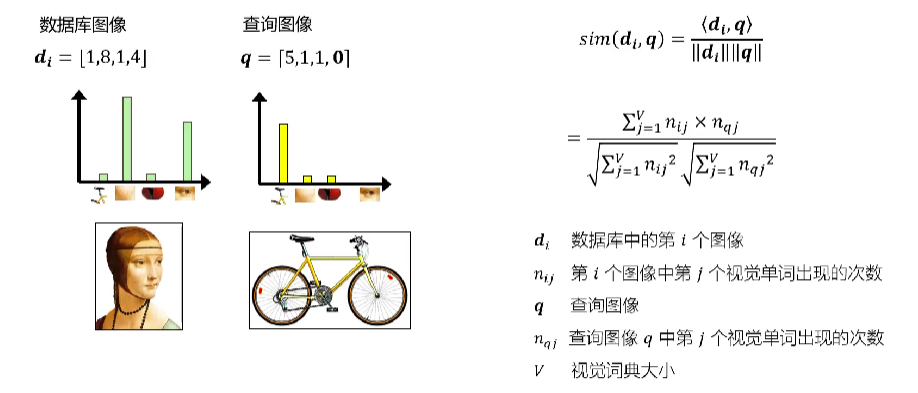
给定两个词袋向量,定义两个向量的相似性如下
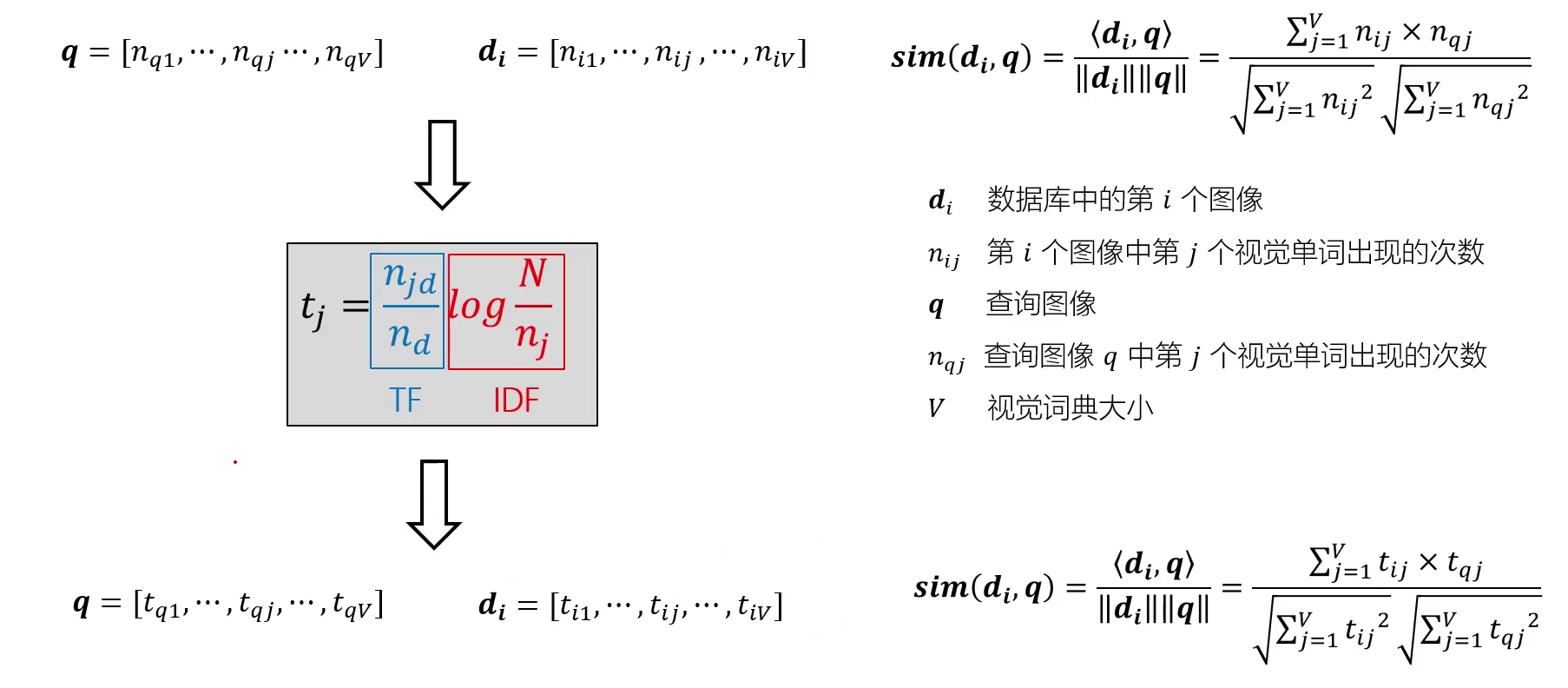
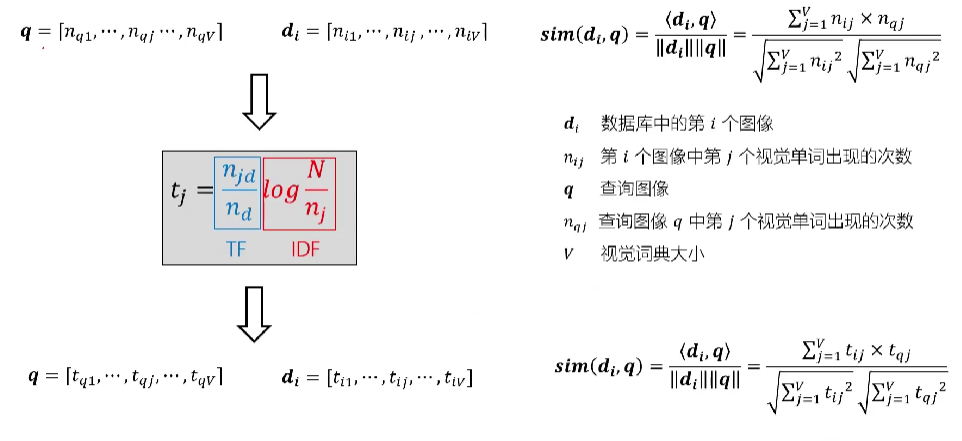
当然,直接使用词袋向量可能导致某些无意义的高频词汇“喧宾夺主”,引入TF-IDF进行优化
当数据库中的图像过多时,逐个进行比较检索将耗费大量的时间,引入倒排索引,其编号不再是图像编号而是特征编号(循环次数变为单词个数,不再随着图像的增加而增加)

综上,基于词袋模型的图像检索主要分为建库和检索两部分,在检索的最后需要使用空间验证对匹配点进行几何校正(比如“我爱你”和“你爱我”显然是不一致的)

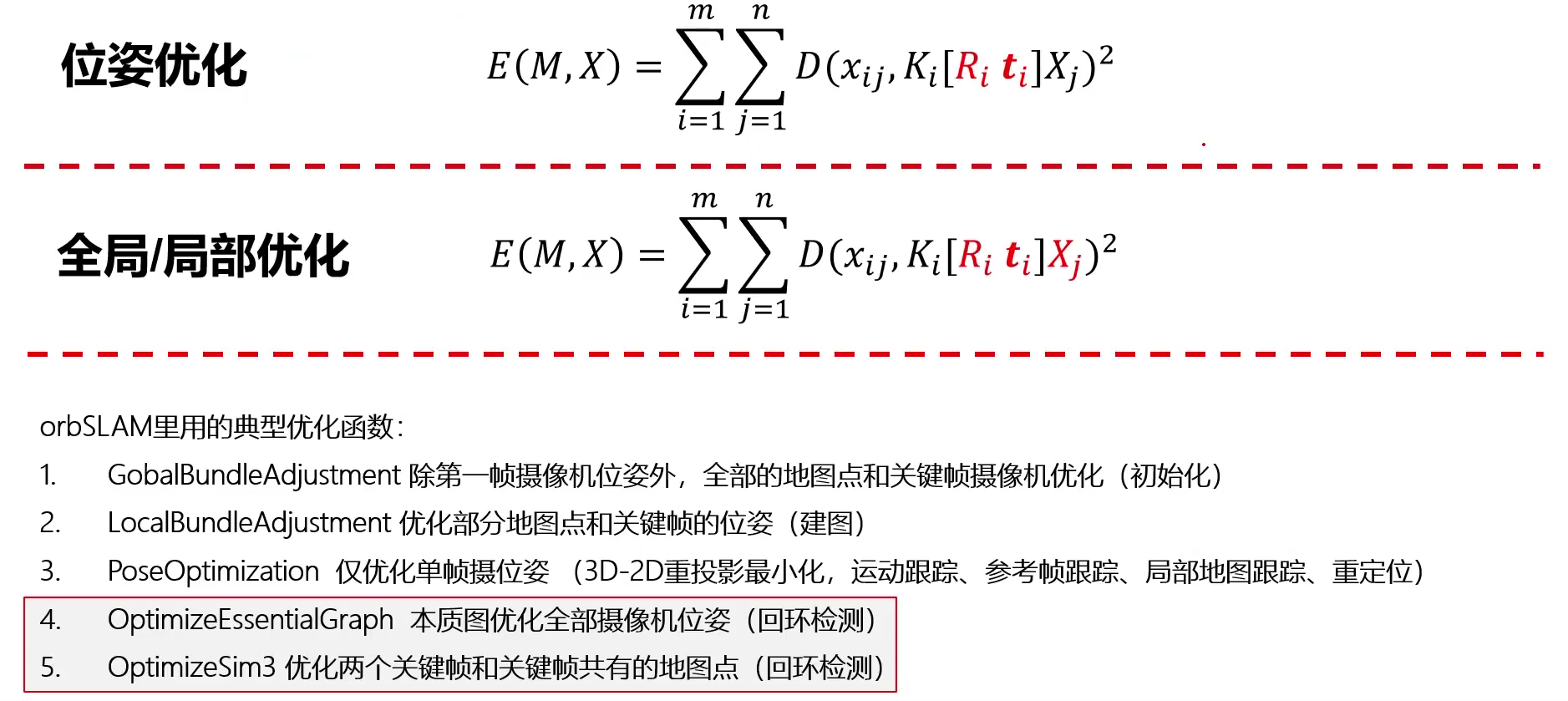
1.6 优化问题
捆绑调整(全局/局部优化)是一种常用的优化策略
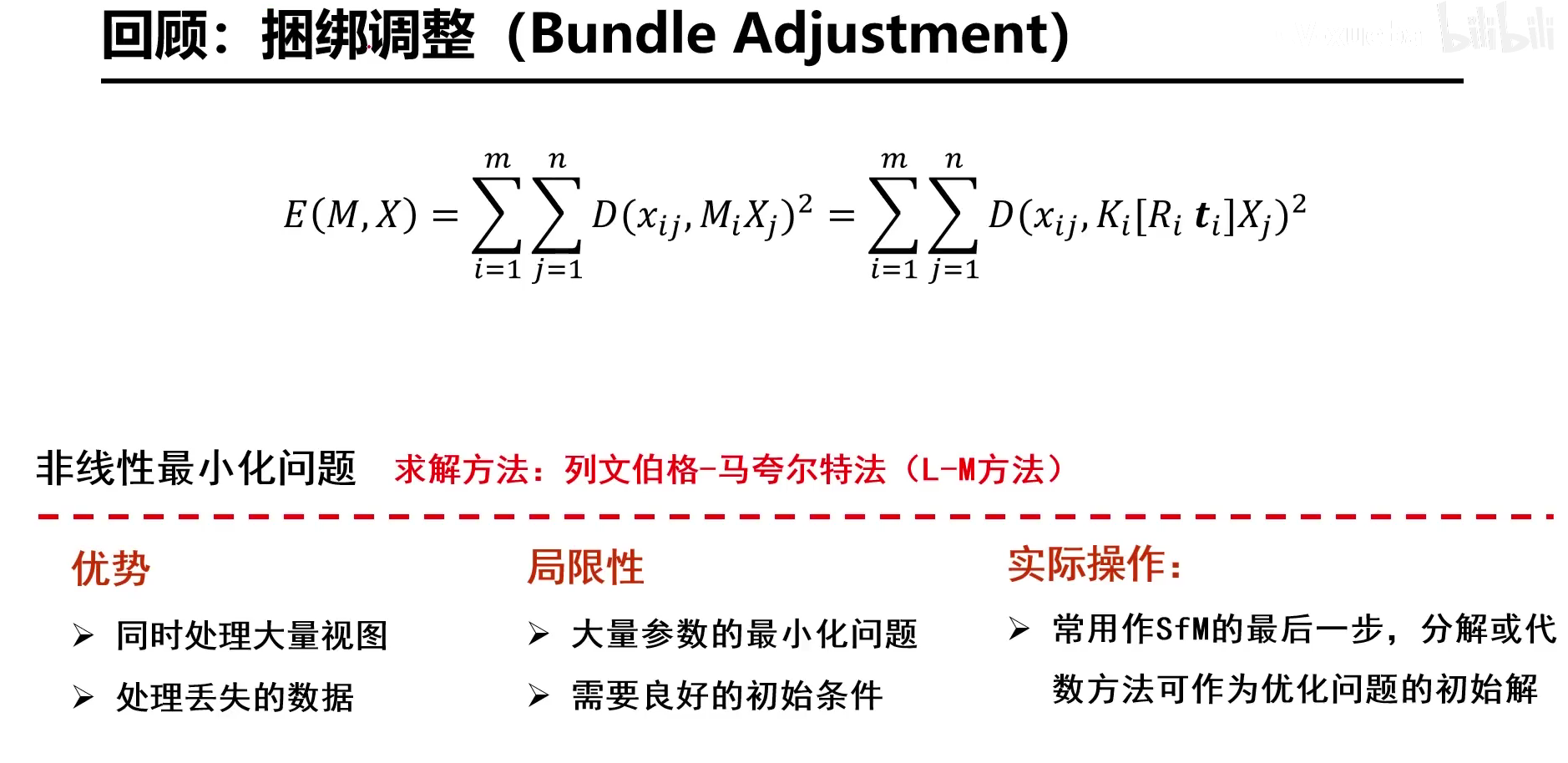
另一种优化并不优化三维点,而是只对旋转矩阵R和转移矩阵T进行优化,称为位姿优化
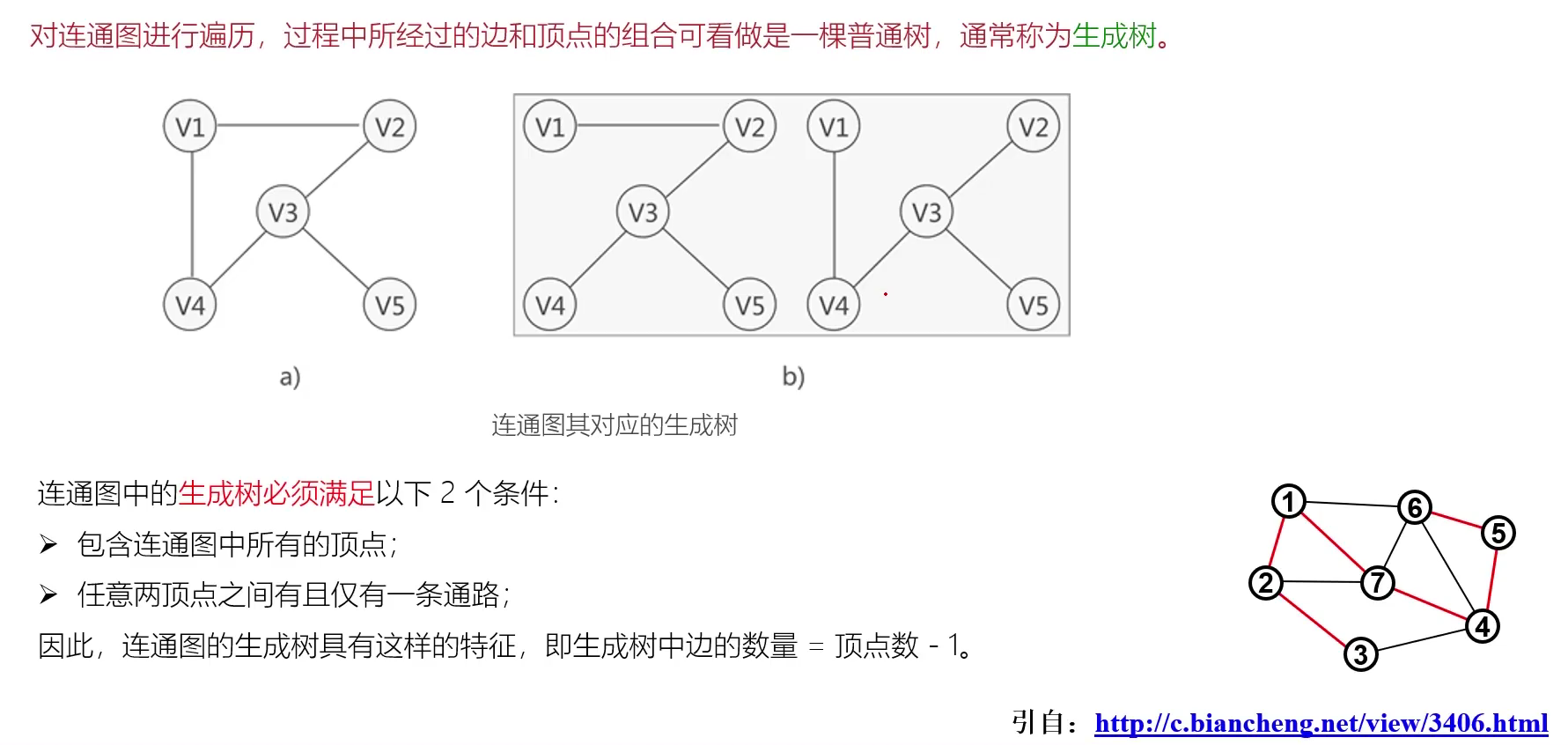
1.7 生成树
生成树的概念如下
2.SfM(运动恢复结构)系统设计
注:本节所介绍的SfM是基于欧式结构恢复,即摄像机内参数是可以获取到的
一个基本的SfM系统具有如下形式的输入和输出

回顾前面介绍过的欧式结构恢复的数学模型如下

现在面临的问题是,在设计系统时是不能确定像素点坐标xij和摄像机内参数Ki的。换句话说,整个系统应当如何获取这两个“已知”:
- 摄像机的内参数可以直接通过读取相片的EXIF信息获取
因此,对SfM系统进行建模得到的数学模型如下

2.1 双视图恢复
当重建问题为双视图的情况时,SfM系统的数学模型以及求解步骤如下

可以看到与之前介绍的欧式结构恢复的不同之处在于多了额外的对应点计算这一步骤,对应点计算又可细分为:
- 特征提取
- 特征匹配
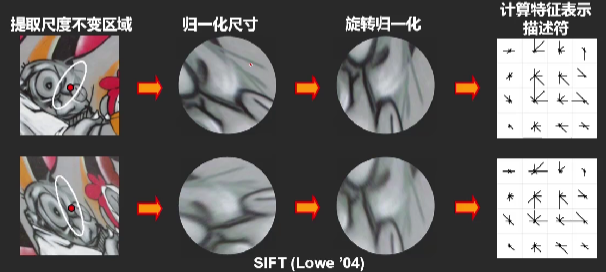
2.1.1 特征提取
SIFT特征的详细介绍参考链接:机器视觉基础 - Tintoki_blog (gintoki-jpg.github.io)。
图像特征提取就是从图像中提取SIFT特征点,之所以选取SIFT特征点是因为它具有尺度不变特性。使用SIFT特征提取器对图像提取特征点,得到的SIFT特征点是一个中心点坐标+一个尺度不变的区域。一般地,最终会将一个SIFT特征表示为一个128维的向量
2.1.2 特征匹配
假定已经从图像中提取出足够多的SIFT特征点,下一步就是匹配两张图像中对应的SIFT特征点,基本思路如下:
- 对于左图中的特征点i,在右图中寻找其匹配点。找到与i维度距离最近的特征点j
1和次近特征点j2,分别记距离为d1和d2; - 计算距离比d
1/d2,如果小于某个阈值则认为右图中的特征点j1与左图中的特征点i是一对匹配点;

对上述特征匹配做简单的解释:
- 之所以要借助阈值筛选是为了避免出现左图中的一个点对应右图中的多个相似点的情况,这种点容易导致后续恢复出错,故不进行匹配;
2.1.3 基础矩阵估计
图像特征匹配完成后,就可以利用匹配的点对基础矩阵F进行估计。但是因为图像特征匹配不能保证所有的匹配点都是正确的匹配点,因此估计基础矩阵F的时候需要借助RANSAC

注意,d)既可以选择自适应也可以选择认为规定迭代次数,需要根据具体情况进行选择
后续的步骤在[欧式结构恢复](# 6.1 欧式结构恢复)中有详细介绍,此处完全相同不赘述。综上,两视图情况下的SfM恢复的完整流程如下

2.2 多视图恢复
多视图恢复是两视图恢复的拓展,一般也被称为基于增量法的SfM系统(常见的有OpenMVG)
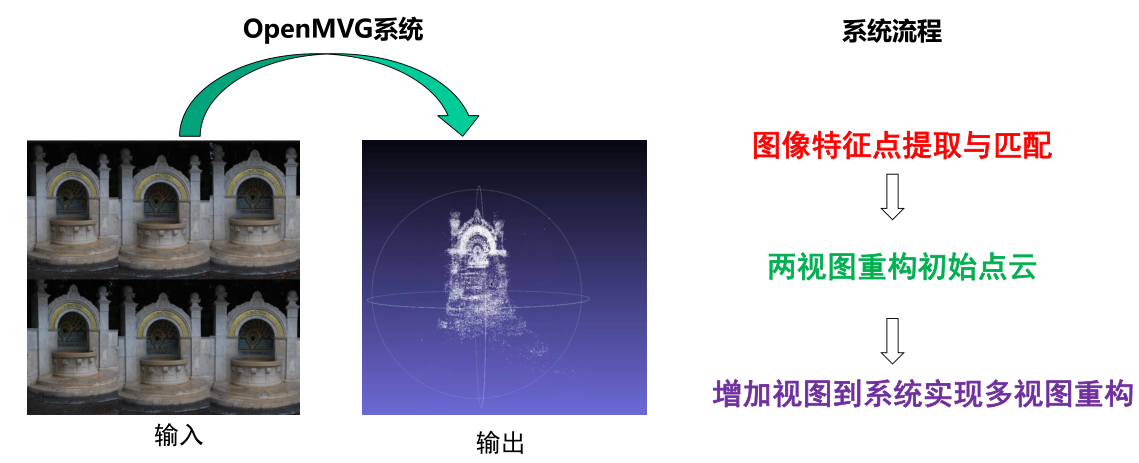
注:重建得到的三维点的点云都是以第一个摄像机为世界坐标系构建
多视图恢复主要分为两个步骤:
- 预处理
- 增量法求解SfM
2.2.1 预处理
因为此处是多视图的恢复,也就意味着图像集中有多对图像,需要两两进行特征点匹配并同时计算基础矩阵和单应矩阵

之所以基础矩阵和单应矩阵都要计算是因为未知空间三维点是否处于同一空间平面上,将基础矩阵和单应矩阵都计算出来后,利用其他点进行投票得出最终的矩阵
2.2.2 增量法求解SfM
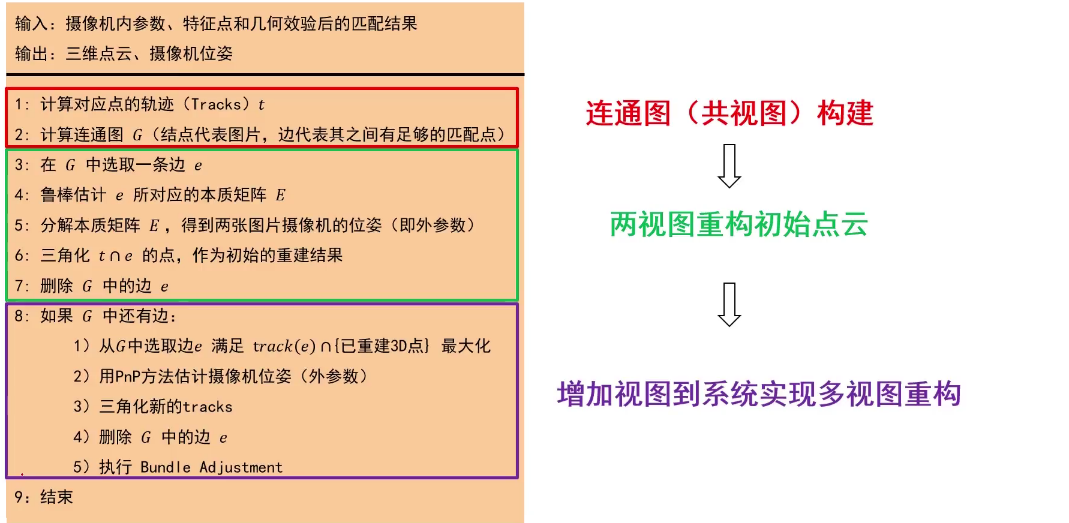
(1)连通图构建
两个图像的对应点指的是一对匹配的特征点,对应点的Tracks这个概念指的是同一个特征点在不同图像中出现的次数
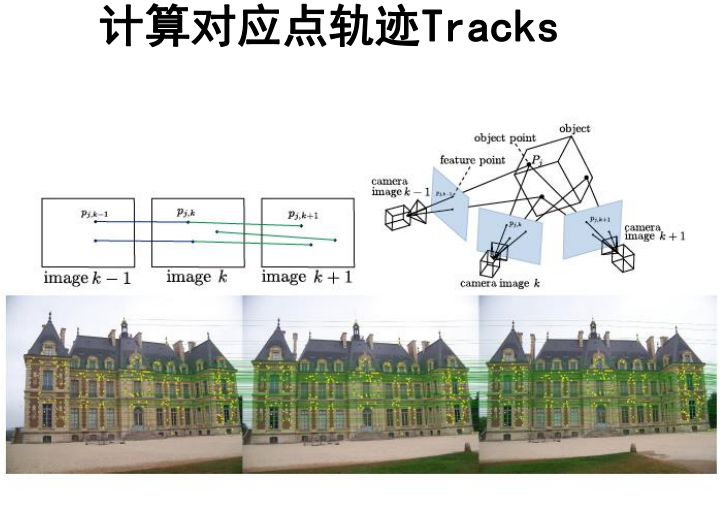
比如上图中有两个Tracks为3的对应点,有一个Tracks为2的对应点。Tracks越大表示该特征点越可靠,因此常常会设置一个阈值,低于该Tracks阈值的特征点后续将被剔除不用于重构。我们称Tracks大于阈值的对应点为t点。
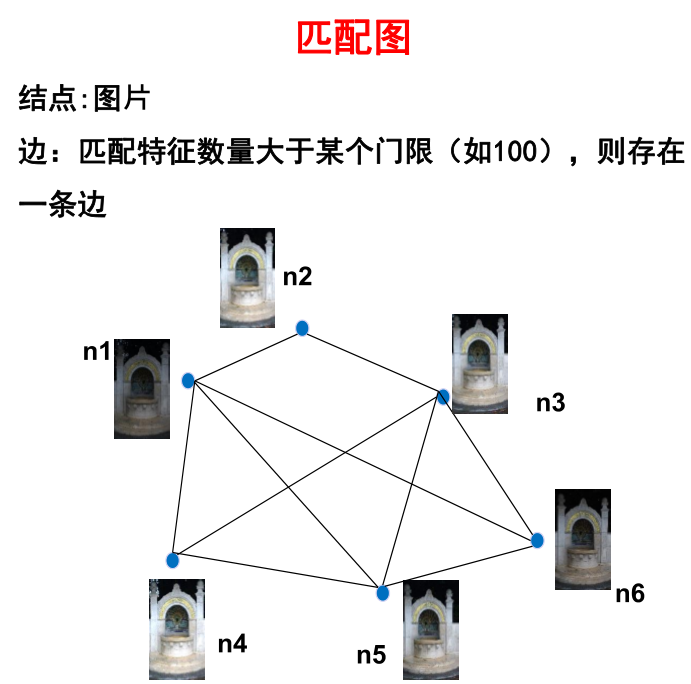
所谓连通图/匹配图指的是结点为图像集中的图像,若对应点的对数大于某个阈值则两个结点之间存在边
(2)初始点云重构
初始时,从连通图G中任意选取两个顶点(两张图像),使其满足条件“所有特征点三角化时射线夹角的中位数不大于60°不小于3°”
之所以选择这样的两个图像作为初始重建对象是因为作为后续增量重建的基础,初始图像的选择需要非常严格,前面介绍过:
- 如果两个摄像机靠得太近(基线太短),极小的偏差也容易产生较大的影响;
- 如果两个摄像机靠得太远(基线太长),容易产生被遮挡得问题;
选择了两张图像后进行两视图重构,需要注意的是并不是重构这两张图像中所有的对应点e,而只重构Tracks大于设定阈值的点t。这样做也是为了保证用于重建的点都是稳定点
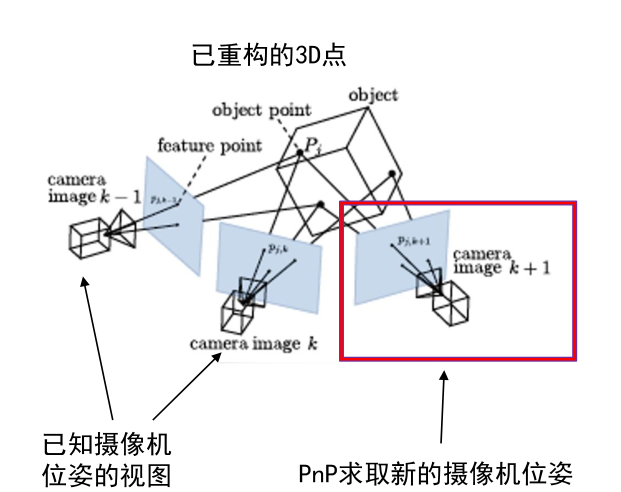
(3)多视图重构
每当完成两幅图的重建就删除这两幅图像对应的结点之间的边,然后选取新边,此处选择新边需要遵循原则:新边的t点与已重建的三维点的交集个数最大。
之所以要这样选择是因为下一步进行PnP估计摄像机外参数的时候,已知的(二维像素点,三维空间点)点对越多估计的效果就越好。
2.3 SfM系统改进
OpenMVG存在的问题是提取特征点以及建立特征点匹配需要消耗大量时间,可以有如下改进思想:
- 针对图像多、特征点多、匹配耗时长的情况,引入词袋模型以及基于词袋模型的图像检索。
引入词袋模型后,原本大量的特征点都可以被同一个单词表示,大大减少了待匹配的特征点数量。在词袋模型中,相同的单词构成一对匹配,因此进行特征点匹配的时候只需要将特征点映射为单词,转换为单词的匹配即可。基于词袋模型的匹配实际就是将两个图像转换为词典表示后,对两个图像进行相似性度量
但是,直接使用词频进行计算存在一些问题,比如一些常用的无意义词汇“的”“地”“得”频率非常高但是对于整体的表示是没有意义的,我们更倾向于选择使用那些“特殊”的单词来表示整体。因此引入基于TF-IDF的相似性度量(此处与NLP中的概念是类似的)
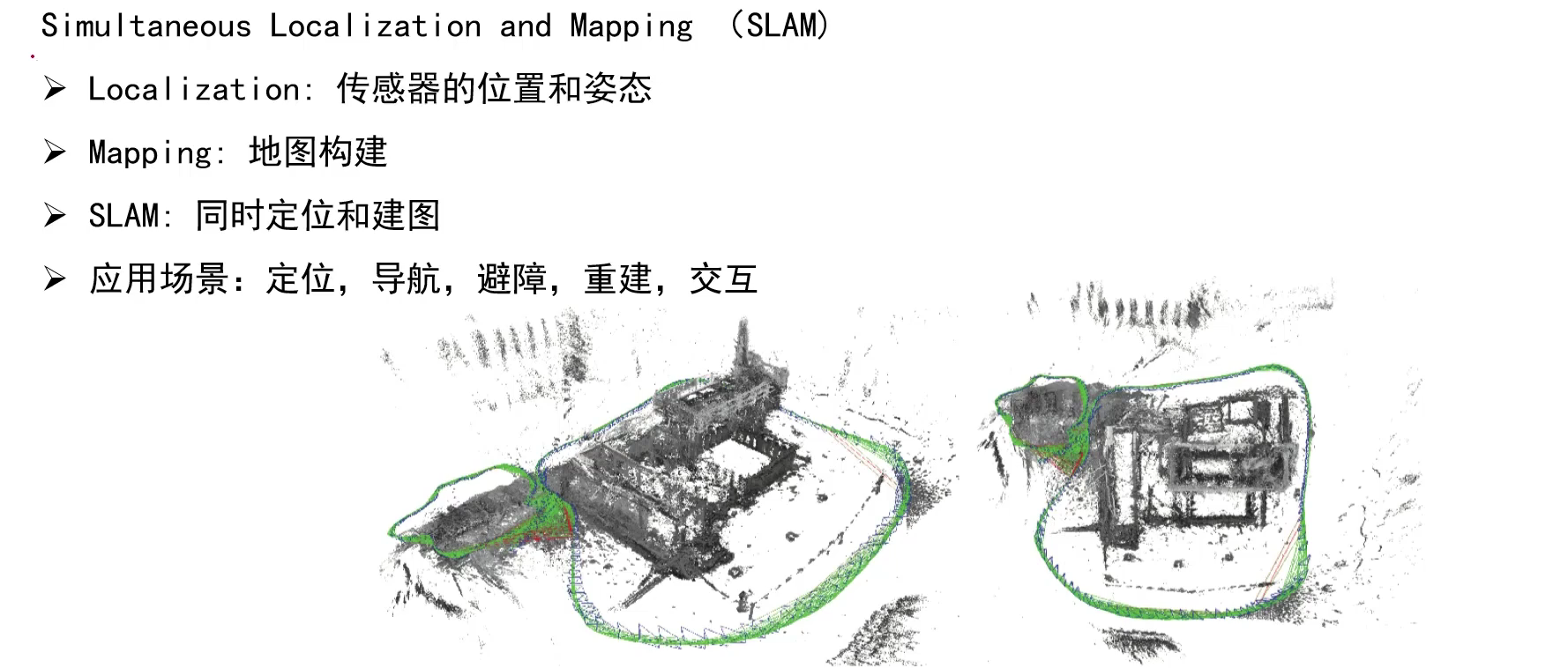
3.SLAM(同时定位与建图)系统设计
本节详细的介绍可以看高翔等著《视觉SLAM十四讲》,此处仅作听课笔记记录
3.1 SLAM介绍
定位是指机器人确定自己的位置在哪(需要实时计算),建图是指知道场景长什么样(一般预先建立)
3.2 传感器


3.3 地图

3.4 ORB-SLAM
ORN-SLAM系统的核心是同时运行着三个线程:
- 跟踪:确定当前帧的摄像机位姿(计算投影矩阵)
- 建图:完成局部地图构建(三角化构建点) – 建图只和关键帧有关,与视频帧无关(某些视频帧是没用的)
- 回环修正:为了修正累积误差,回环检测并基于回环信息修正系统漂移(校正)
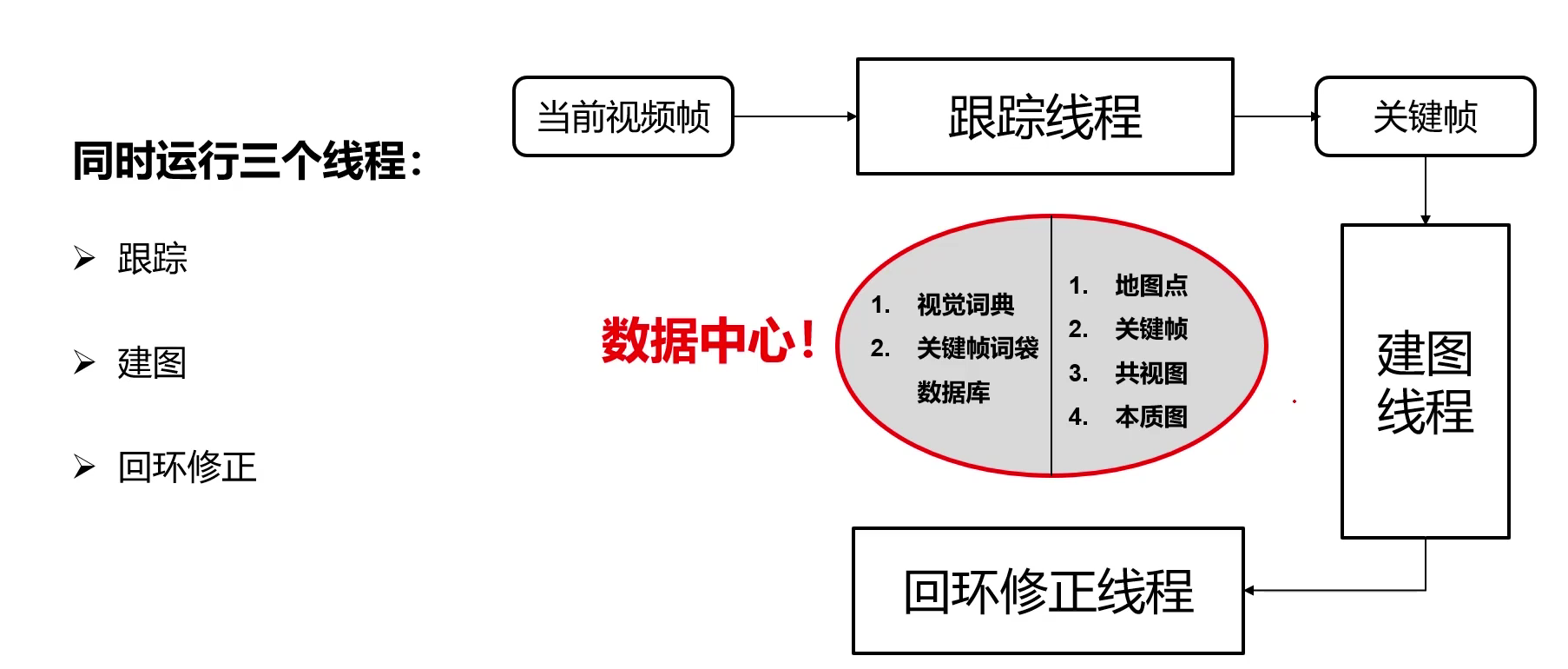
SLAM三维重建中的核心数据库包含地图点、关键帧、共视图以及本质图:
- 地图点:
- 世界坐标系下的3D坐标;
- 观测方向,即所有可以观测到该特征点的视图所产生的的观测方向均值;
- 最具表达性的ORB特征描述子;
- 该点能被观测到的最大距离与最小距离;
- 关键帧:
- 摄像机位姿;
- 内参数;
- 全部ORB特征描述符,是否有地图点对应;
- 共视图:
- 一种无向有权图,节点为关键帧,如两个节点共享的地图点数量大于阈值(至少15个)则存在一条边,其权重设置为共享地图点的个数
- 本质图:
- 共视图的子图,保留所有节点,边数量相较于共视图更少,其作用是加速回环校正的计算
- 本质图=生成树+共视图边权重超过100的边+回环边
更加具体的,整个ORB-SLAM的工作流程如下
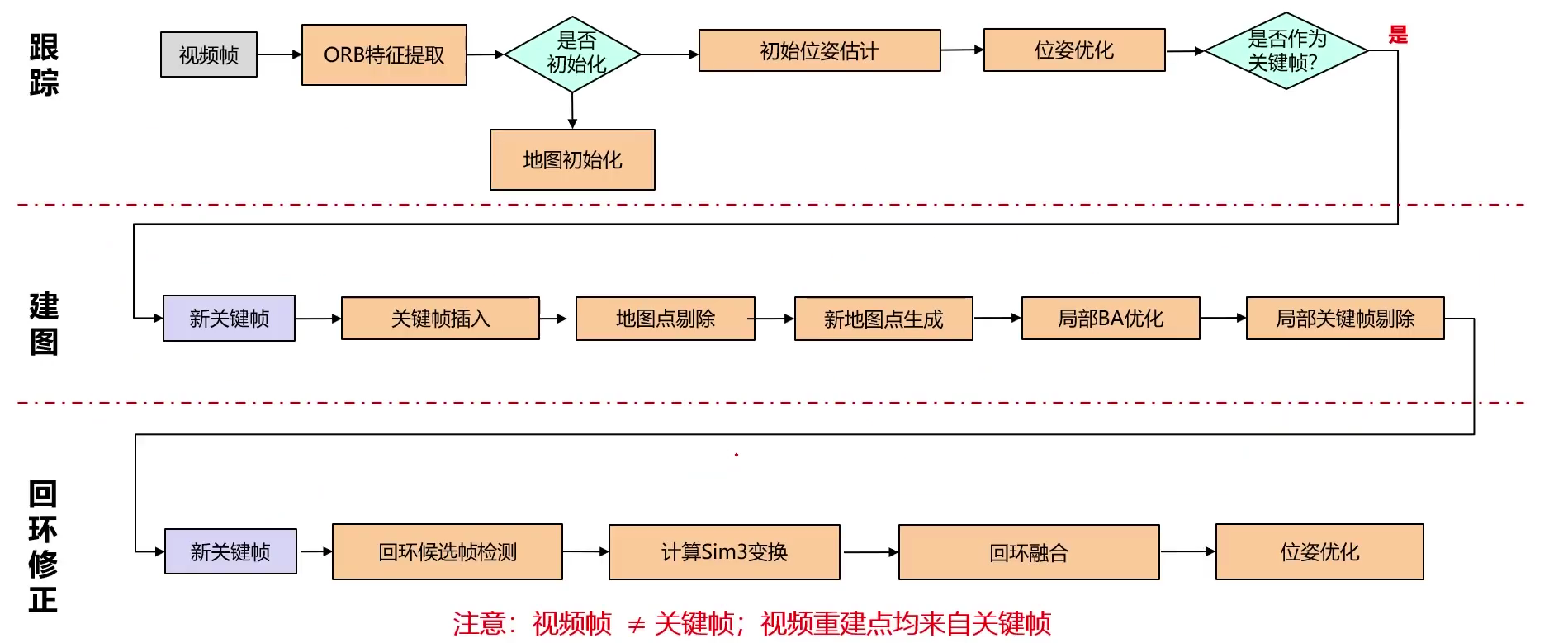
具体每个环节和细节自行查看论文,此处不做介绍